Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
[Part 1]
Welcome back! Last time I introduced the overall solution we developed to enable a news management and delivery service on MSW. In the next few posts I will dig into the details, providing more information on the design configuration and custom components we built.
Step 1: Content Consumption
The first step is to consume the news and insert this content into a SharePoint list. Microsoft has licensing arrangements with select information services to create topical RSS feeds of news from multiple sources. We then have a custom application that runs as a local Windows service on our web front ends, scheduled to run every 15 minutes and update a list with new items from each feed. This application uses configuration files to specify the data source and how we want the data inserted into the list.
The configuration file contains the following information:
-
- The address of the feed
- Producer and consumer assemblies
- Where the data should be inserted
- Arguments to add to the request
- Mappings of how to insert the data into a list
Here is a sample configuration file we created for our application to read a licensed RSS feed from Moreover and import select metadata values into designated list fields:
<?xml version="1.0"?>
<FeedConfiguration>
<Configuration>
<ConnectionString>
https://ps.moreover.com/cgi-local/page
</ConnectionString>
<ProducerAssembly>ImportToList.MSLibrary</ProducerAssembly>
<ProducerClassName>
ImportToList.MSLibrary.MoreoverProducer
</ProducerClassName>
<ConsumerAssembly>ImportToList.MSLibrary</ConsumerAssembly>
<ConsumerClassName>
ImportToList.MSLibrary.MswNewsConsumer
</ConsumerClassName>
<Server>https://localhost/Repository</Server>
<List>NewsRepository</List>
<Folder></Folder>
<LastRecordProcessed>_908019085</LastRecordProcessed>
<ItemPath>article</ItemPath>
<FolderCount>500</FolderCount>
<ArgumentList>
<Parameters>
<item name="feed">900174669</item>
<item name="client_id">msft_cib_by49</item>
<item name="o">xml001</item>
<item name="last_id"></item>
<item name="n">100</item>
</Parameters>
</ArgumentList>
<Map>
<Map>
<Map>
<Fields>
<field name="Bucket" value="Daily News" />
<field name="Vendor" value="Moreover" />
<field name="Title" xpath="headline_text" />
<field name="LongDescription" xpath="extract" />
<field name="ShortDesrciption" xpath="extract" />
<field name="VendorAssignedID" xpath="@id"
itemKey="true" />
<field name="ExternalUrl" xpath="url" />
</Fields>
</Map>
</Map>
</Map>
<NamespaceList>
<Namespaces/>
</NamespaceList>
</Configuration>
</FeedConfiguration>
The key distinction for these configuration files is the Bucket field value which can be used as a property filter for the search interface (more on this in a moment).
The list that receives these news records from the feed manager is based on a custom content type that inherits from the out-of-box type Item. Essentially we are just adding the custom fields declared in the configuration file to specify where the feed data values get written to. For illustration, the schema is provided below.
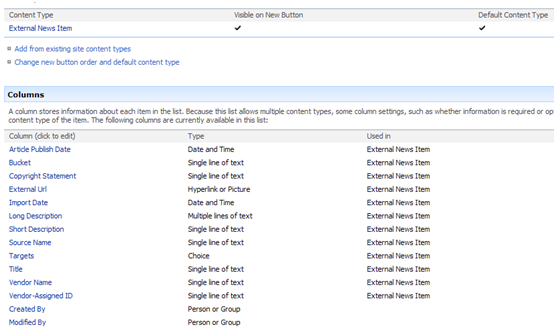
And here is a sample imported record:

Notice that we aren't capturing much data; we primarily capture metadata that includes the publish date, a brief description, the news source, and a link to the full story.
This is a standard list configured to support multiple content types and locked down to permit access to only specific SharePoint groups. This list is also configured with an out-of-box expiration policy set to delete items 15 days after the Import Date value.
Step 2: Content Discovery
Even with an expiration policy in place, the list tends to hover around 30 thousand items. To assist editors with finding items in this list to tag as news candidates, we initially configured an out-of-box advanced search interface with a scope set to only index items in this list of the custom content type. Currently this crawl is scheduled to run three times per day to ensure that when editors need to use the workbench, they can query for recent news items.
We have since updated the search experience with a custom metadata interface that can more easily expose to users the available property values for managed properties. This improved interface provides greater query flexibility and a UI that can be easily updated through a web part configuration file. Our custom solution still takes advantage of the SharePoint OM and leverages full text indexes for performance.
Here is the current interface. Notice that it exposes the values of the Bucket field as a multi-choice display, allowing editors to easily scope their searches to select feed items:

Returned results can then be tagged as candidates for subsequent editing and distribution. To do this we edited the XSLT file of the search results web part to provide a link for each search result to a custom list form:

Selecting the Tag item for publishing link pops up a custom form that allows an editor to target a story candidate for one or more pre-defined newsletters. This list of available newsletters is generated from a configuration list created at the time of solution deployment and stored in the root of the site collection. This list can be modified to support the creation or removal of targets.
Once the selections are made, this form kicks off a custom action to save the selections back to the list and copy that selected item from this source list (called NewsRepository) to another list (called PublishedNews). Although we could have managed the selected news in the same list, we elected to use two lists for the following reasons:
- List items are automatically crawled by the indexer and become part of the site search. We didn't want to expose all news to end users through search because a lot of what we pull in is irrelevant; as much as we try to filter, we still get news about the Spice Girls' latest concert plans, etc. The way we get around this is to lock down permission on the Repository so that even though the list gets indexed, search results don't contain any items from the NewsRepository for average users.
- The PublishedNews list is smaller, so we get better performance when we query against it. And as you see later, we point a lot of Content Query Web Parts at this news list!
Next Time
In the next segment of this series I'll talk about how the editors use the PublishedNews list to prepare items for distribution and display.