Graph Colouring With Simple Backtracking, Part One
As regular readers know, I'm interested in learning how to change my C# programming style to emphasize more concepts from functional programming, like use of immutable rather than mutable data structures and use of declarative control flow like LINQ queries instead of imperative control flow in the form of loops. I thought I'd solve a fairly straightforward problem using a mix of immutable and mutable, declarative and imperative styles to indicate when each is useful and appropriate.
I picked for my example the problem of colouring a map so that no two regions that share a border have the same colour. (Note that we count two regions as sharing a border if they meet along a border line; regions that meet only at a corner are allowed to be the same colour.) This is a famous problem. It is clear that on a plane or sphere, you can find a map that requires at least four colours. Take a look at a map of South America, for example; clearly Brazil, Bolivia, Paraguay and Argentina all share a border with each other and therefore require at least four colours. What is not at all clear is the fact that given any map, you can always find a colouring that requires no more than four colours; four colours is always enough on a plane or a sphere.
{kind=link}
Of course, this is of no interest whatsoever to real mapmakers, who have no shortage of colours to choose from, and who often have additional constraints. For example, if you coloured a political map of the world with only four colours then either Bolivia or Paraguay would have to be the same colour as the ocean. There are also situations in real maps where you want two things to be of the same colour, like Alaska and the lower 48 states of the United States, which could introduce additional constraints.
Even if the theoretical problem of map colouring is not germane to the practical problem of making a map of a real thing, the problem is still of both theoretical and practical interest. To solve it, we can generalize the problem from a problem about touching regions on a plane map to nodes in a graph. Make one node for each region. Any two regions which must be coloured differently from each other share an edge. If we can find a colouring that assigns colours to each node in the graph, then we have a colouring for the corresponding map. If we were trying to colour South America, for instance, we simply need to colour this graph:
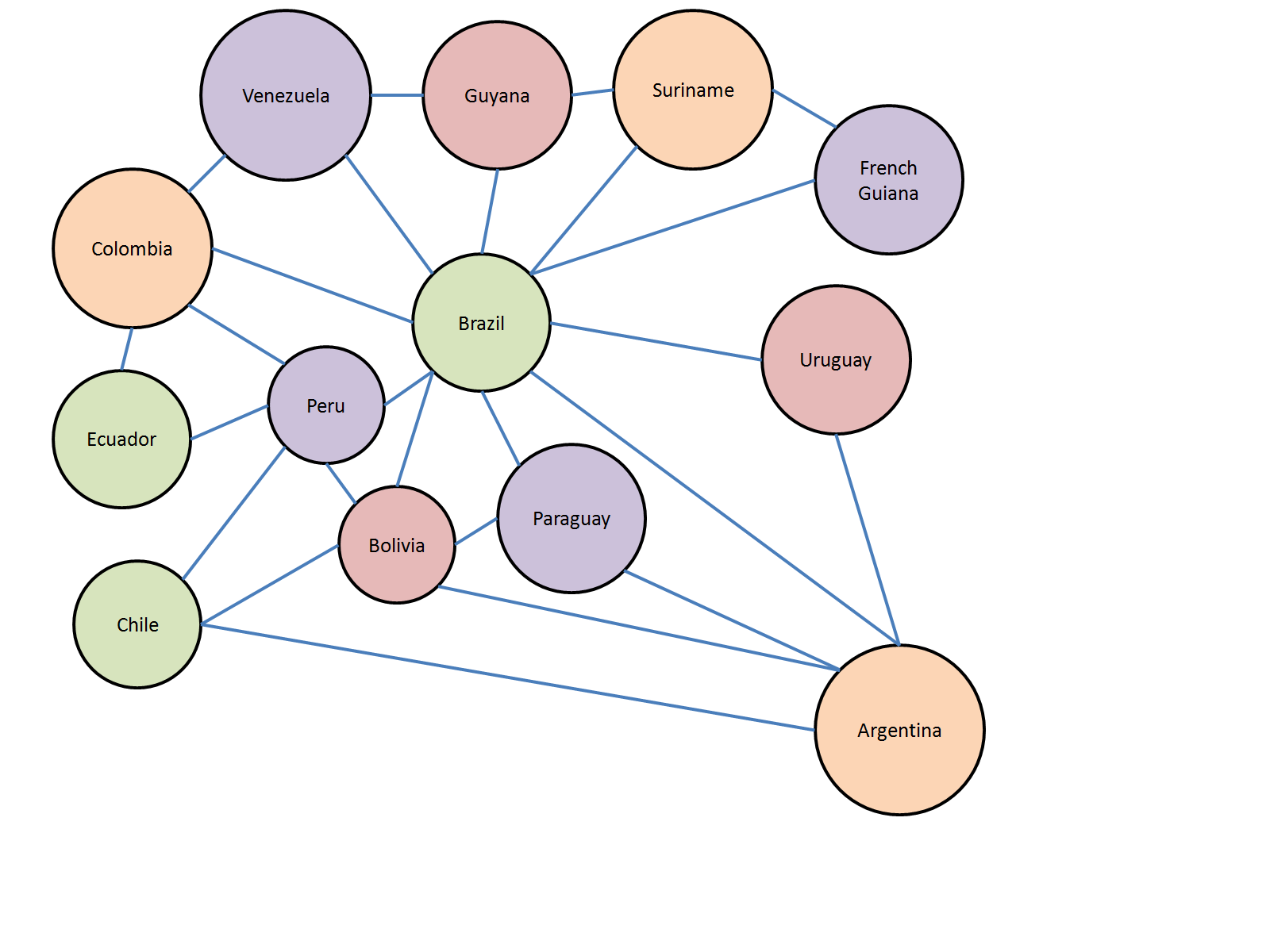
I've shown the graph with a proposed colouring that works; there are several other possibilities.
Let's start by designing a simple data structure to represent an arbitrary graph. Every design process is the result of making compromises against competing design goals, so I think it is helpful to list some of those competing goals and what tradeoffs we're considering.
There are two standard ways to represent an arbitrary graph with n nodes and e edges; either you make an n by n array of bools that says whether there is an edge between two nodes, or you make a list of size e that gives all the edges in no particular order.
The benefit of the former approach is that it is extremely easy to get a list of all the edges coming out of a given node; the down side is that it uses up a lot of space if n is large and e is small. The benefit of the latter is that it is space-efficient if the graph is sparse, but it is inefficient to answer the question "what are all the neighbours of this node?" (Tradeoff: space vs time.) In both cases, the naive approach wastes about 50% of the space if the graph is actually undirected, because an edge from A to B is also an edge from B to A.
However, for our purposes the graphs are going to be relatively small anyway, so I don't particularly care which approach we take or that we're wasting a few bytes here and there. Let's go with the former approach and say that a graph is represented internally as an n by n adjacency matrix.
Should the graph be a directed or undirected graph? For some relationships a directed graph is clearly the way to go; a family tree, for example, is clearly a directed graph. If Alice is the mother of Bob then Bob is not the mother of Alice! It seems like the concept we are trying to represent, "neighbouring regions" is inherently undirected. It's not like Brazil is a neighbour of Peru but Peru is not a neighbour of Brazil.
We could make a directed graph and build an undirected graph out of it by always adding edges in pairs, or we could build an undirected graph from the get-go, or we could use a directed graph as the base class of an undirected graph, or we could make an undirected graph and make a directed graph out of it by decorating edges with direction information if we needed to. There's all kinds of things we could do.
Suppose we do the first one: simply build a directed graph and require the user to add edges in pairs if they want an undirected graph. This makes the data structure more flexible (by being able to represent both directed and undirected graphs) and more bug-prone (because a user that wants to represent an undirected graph is responsible for maintaining the invariant themselves; any time you add redundancy to a data structure you add the potential for bugs.)
Is it actually more bug prone for our purposes? Even though the adjacency graph is logically undirected, for our purposes it is perfectly valid for the graph to actually be directed. It doesn't matter whether those edges have arrows on them or not! If somehow we represent that Brazil is a neighbour of Peru but accidentally say that Peru is not a neighbour of Brazil then we still will discover that they cannot both be green. Just knowing one direction is sufficient.
In short, we could create an undirected graph class that managed ensuring that edges always came in pairs, but for now at least we won't. (Tradeoffs: flexibility vs simplicity, complexity (of having multiple classes to represent graphs) vs imposition of responsibility upon users.)
// An immutable directed graph
internal sealed class Graph
{
// If there is an edge from A to B then neighbours[A,B] is true.
readonly private bool[,] neighbours;
readonly private int nodes;
public Graph(int nodes, IEnumerable<Tuple<int, int>> edges)
{
this.nodes = nodes;
this.neighbours = new bool[nodes, nodes];
foreach (var edge in edges)
this.neighbours[edge.Item1, edge.Item2] = true;
}
public IEnumerable<int> Neighbours(int node)
{
return
from i in Enumerable.Range(0, Size)
where this.neighbours[node, i]
select i;
}
public int Size { get { return this.nodes; } }
}
Let's go through this from top to bottom.
I've made the class sealed. This means that I do not have to consider what implementation details must be exposed so that an arbitrary class can extend this code effectively and efficiently. I do not have any scenarios in which this code needs to be extended. By the You Ain't Gonna Need It (YAGNI) principle I'm going to design the code so that it cannot be extended. Designing for safe and effective reuse via inheritance is difficult and I don't want to take on that expense if I don't have to. Nor do I want to make an implicit promise that I cannot deliver on; an unsealed class basically says to the user "go ahead and extend me, I promise I'll never break you". Implicitly taking on a commitment to preventing the brittle base class failure is not something I want to do. (Tradeoff: potential code reuse vs increased design and maintenance costs). Also, sealing is a breaking change but unsealing is not. If I seal now, I can always change my mind later. If I leave it unsealed then I cannot choose to seal it later without breaking any derived classes.
The class is internal, not public. I want this to be an implementation detail of my application, not a part of a general-purpose library. As we'll see, this decision has an effect on other implementation choices. (Tradeoff: again, potential code reuse by others vs increased design and maintenance costs)
The class name is Graph, not, say, DirectedGraph. If I ever wanted to make an UndirectedGraph class then I'd want to rename this one. But since in my application this will be the only graph class, I'm willing to have the simpler name. Note that I absolutely do not want to have the name of the class reflect its implementation details; this is not an AdjacencyMatrixGraph. I want the name to represent what it is logically, not what its implementation details are.
The class is not generic. Each node is an integer from 0 to size-1. We could have made this more complicated by allowing arbitrary data in a node; essentially making a generic "graph of T". But we can always maintain an external mapping from the integer of the node number to some other data if we like. (Tradeoff: again, flexibility vs simplicity. Also, Single Responsibility Principle: this class represents graphs; let it do one thing well rather than making it into a graph and a map from nodes to data.)
The graph internally uses an array for the adjacency matrix. We want data structures to be simple and efficient. Making a data structure that can be changed, either via mutation or by creating a new structure that incrementally re-uses parts of an old structure, adds flexibility and power but works against simplicity and efficiency. (Tradeoff: flexibility vs simplicity and efficiency) For my purposes we're going to have all the information we need to make a graph all at once, create it, and be done with it. We don't need any way to add or remove nodes from a graph and make a new graph from it. (YAGNI) I therefore feel justified in using a mutable data structure, an array, as an implementation detail here, to make what is an entirely immutable structure from the point of view of the user. If we had scenarios where graphs were being edited then I'd probably choose a different approach to make an immutable graph.
The array is inefficient; we are wasting a lot of bits here. We could use an array of BitArrays. However, that adds complexity to the implementation and greatly slows down access to the bits; it is much faster to simply dereference a bool out of a two-dimensional array than it is to do all the bit-shifting logic to get a bit out of a BitArray. Without empirical data from a profiler that showed that the memory cost in reasonable scenarios was too high, I would stick with the simple bool array rather than the more complex bit vector solution. (Tradeoffs: code simplicity vs time efficiency vs space efficiency)
We're also allocating a big two-dimensional array, which must be allocated in one monolithic block. If the number of nodes gets large, it might be difficult for the memory manager to find that much memory in a block. We could take on the additional memory expense of a BitArray solution or a ragged array solution, which would allow us to allocate n blocks of size n, rather than one block of size n by n. The former makes it much more likely that the memory manager will be able to fulfill our request, at the cost of the memory for logically "close" data being possibly spread out in memory, decreasing cache locality. (Tradeoffs: again code simplicity vs time efficiency vs space efficiency)
I redundantly store the size; we could compute the size by asking the array for its dimensions. If we were creating millions of graphs and were space-constrained then it might be reasonable to save those four bytes. But we're not. (Tradeoffs: having to maintain redundancy vs code simplicity vs space efficiency)
The fields are readonly, emphasizing that this type is immutable.
There is some redundancy in the information provided to the constructor. We could have deduced the number of nodes by taking the maximum integer found in the list of edges, instead of requiring that it be passed. Some of our options are:
(1) Iterate the sequence of edges twice, once to find the highest item, and then again to build the query. This is potentially expensive in time; we prefer to when possible build systems that only iterate a given sequence once because it could be representing a high-overhead database query. Even if the query overhead is cheap, it spends time iterating the sequence twice.
(2) copy the sequence into an in-memory list. Search the copy for the highest item, and then build the graph out of it. This way potentially doubles both memory usage and time.
(3) require that the user pass something other than an arbitrary sequence. This pushes the problem off to the user, and means that the entire sequence must be realized "eagerly" in memory, even if it could be calculated lazily.
Now, of course we know that we are going to be using n-squared memory and linear time anyway, so perhaps the memory and time concerns are not hugely relevant. But it seems reasonable that the user knows how many nodes there are in the graph ahead of time, since they're providing a list of edges, and therefore seems reasonable to require them to pass in this redundant information. (Tradeoff: efficiency vs redundancy)
We use a tuple type instead of a custom type to represent an edge. It seems reasonable to represent an edge as a pair of integers; there's no particular domain-specific semantics to an edge other than just a pair of nodes. So we'll just re-use a general-purpose data structure rather than needlessly inventing a new one that adds nothing. (Tradeoff: cheap re-use of existing code vs having semantics clearly expressed in the type system)
Note that we do not validate the data in the constructor. If the user says that the size is negative, or is enormous, or gives an edge that is out of bounds, then bad things happen like array-access-out-of-bounds exceptions. We could harden this system against ill use by reporting more specific exceptions. Or, we could assume that the user knows what they're doing and can diagnose the problem when they get an unexpected boneheaded exception. Were I designing this code for inclusing in the base class library, I absolutely positively would have all kinds of custom error detection and reporting in there; that's part of the "fit and finish" of a professional-grade library. If, on the other hand, this were an implementation detail of some analysis tool, a detail that was never publically exposed, then I'd just leave it like this and know that the maintainer of that code was responsible for using it correctly. (Tradeoffs: code complexity vs "niceness" of reporting specific out-of-bounds errors).
I've spelled "Neighbours" the British/Canadian way. (Tradeoff: correctness vs familiarity to Americans)
Notice how the constructor uses a foreach loop whereas the Neighbours code returns a query object. That's deliberate; I want to use the loop to emphasize that the loop code is a mechanism that has a side effect. A looping statement calls that out very clearly. Fetching the neighbours of a particular node, on the other hand, is more like asking a question; what's important here is the semantics, and that the code is free of side effects. The query syntax emphasizes that.
What's interesting here is that this code is utterly trivial; it does almost nothing, and yet already we've made about a dozen design decisions involving subtle tradeoffs that will impact whether a given scenario can realistically be handled by this class.
Next time: representing a set of possible colours.
Comments
Anonymous
July 12, 2010
Eric, I like the topic and I'm curious to see whereyou go with this one. One design trade-off choice you didn't mention was the use of 'Tuple<int,int>' to represent edges passed to Graph, rather than creating a separate type Edge, to do so. The trade off here is public interface clarity, vs. ease of implementation. I hate to be contradictory, but yes, I did mention that. - Eric Also, I've noticed that in creating your sealed, immutable Graph data structure, you did not make the 'nodes' and 'neighbours' members readonly. Is there a reason not to do so (some other trade-off, perhaps), or is this an oversight? That was an oversight, which I've corrected. Thanks! - EricAnonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
I reread the post and I noticed I somehow completey missed the paragraph on the choice to use Tuple. Sorry about the confusion.Anonymous
July 12, 2010
A couple of tangential questions: Your coding style in this example is more StyleCop than DevDiv. Is that deliberate? Has DevDiv changed style? Specifically, the use of the 'this.' qualifier and the ANSI bracket style. If query comprehensions imply a side-effect free operation, why aren't they limited to closing over 'final' variables?Anonymous
July 12, 2010
I like your deconstruction of the decision making process. It formalizes what I usually only know instinctively, and makes it easier for me to explain others the rationale behind the decisions I've made when writing my code, and when reviewing other's. I'd only change two things. First, I like being able to tell the difference between fields and local variables by just looking at the code, and so I'd use some kind of notation to decorate field names, be it _fieldName or m_FieldName (I use the latter) or any other consistent way, but I wouldn't enforce it on others, only suggest it. The seconds thing I'd change (and enforce were it my responsibility) is the name of the field and constructor parameter that represents the number of nodes. I'd call it 'nodeCount' rather than 'nodes', since to me 'nodes' means the actual collection of nodes, which I would expect to be an IEnumerable<Node> (which confused me when I first glanced at the constructor). Can't wait for part two!Anonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
@Allon Notice the use of the this. prefix. If the variable reads this.variablename then it's a field otherwise is a local variable. This is the code convention recommended by StyleCop. I agree with you regarding renaming the parameter "nodes" to "nodesCount" or "size" but again remember that this class was designed to be used internally so it hasn't been polished as Eric explains.Anonymous
July 12, 2010
I think I would have gone with HashSet<Tuple<T, T>> as the backing data structure. IEnumerable<T> NeighboursOf(T node) { return from edge in edges where edge.First.Equals(node) select edge.Second; } bool IsAdjacent(T node1, T node2) { return edges.Contains(new Tuple(node1, node2)); } Different set of tradeoffs, certainly, but the Neighbours and IsAdjacent methods come out just as elegant, the Graph class doesn't need to do anything in particular as regards knowing about T, but you still don't need some other class to track the mapping of int to T. Also with only slight changes you could implement ordered or unordered graphs by simply using different Edge classes instead of Tuple.Anonymous
July 12, 2010
Great post Eric; this kind of code construction knowledge is sorely lacking in the public community at large. I look forward to the rest of the series.Anonymous
July 12, 2010
I think that in this case, adjacency list would be better than adjacency matrix. Not only because it would be more memory efficient and I think clearer code, but most importantly, it has better time complexity. Thanks for an interesting article. Stuart, your implementation has to iterate over all edges to get the neighbours of each vertex, that's really wasteful. My implementation: public Graph(int nodes, IEnumerable<Tuple<int, int>> edges) { this.nodes = nodes; this.neighbours = new List<int>[nodes]; for (int i = 0; i < nodes; i++) this.neighbours[i] = new List<int>(); foreach (var edge in edges) this.neighbours[edge.Item1].Add(edge.Item2); } public IEnumerable<int> Neighbours(int node) { return neighbours[node]; }Anonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
The comment has been removedAnonymous
July 12, 2010
In the 11th paragraph, you write: "Suppose we do the first one: simply build an undirected graph and require the user to add edges in pairs if they want an undirected graph. " I think the first "undirected" should be "directed".Anonymous
July 12, 2010
Is there any reason that you used int instead of uint for the 'nodes' parameter and to represent the nodes themselves? Pros: -A user cannot pass a negative number of nodes or node by mistake -No extra work (except to type the extra u ;-) ) Cons: ?Anonymous
July 13, 2010
@Leon re: uint I can't speak for Eric, of course, but... I once developed a system in which negative values made no sense as a parameter, so rather than validating that the parameter values were non-negative, I thought it would be a great idea to just use uint instead. I quickly discovered that whenever I used those values for anything (like calling BCL methods), they had be converted to signed integers. This meant that I had to validate that the values didn't exceed the signed integer range on the top end, so I gained nothing. Also, every time the code was called, the ints that were being used (often received from BCL functions) had to be converted to uints. It didn't take long before I changed all those uints back to ints and took all that unnecessary casting out. I still have to validate that the numbers are not negative, but the code is much cleaner! Couldn't have said it better myself. You almost never need the range of a uint, and they are not CLS-compliant. The standard way to represent a small integer is with "int", even if there are values in there that are out of range. A good rule of thumb: only use "uint" for situations where you are interoperating with unmanaged code that expects uints, or where the integer in question is clearly used as a set of bits, not a number. Always try to avoid it in public interfaces. - EricAnonymous
July 13, 2010
I think this highlights one of the advantages of pair programming. Even when making nearly-trivial classes like this, you implicitly must make dozens of design decisions. If you have to stop and think about what decisions you're making, the code takes much longer to write, and you are more likely to end up making the wrong decision. If you have to ask somebody about a decision, you have to stop what you and somebody else are doing, explain the context to them, and hope they can give you a meaningful answer. With pair programming, there's always somebody there who has the full context of the situation who can give you advice on the decision. Ideally, this person has already even thought about the decision while you were typing in some other code, and has good reasons for their answer.Anonymous
July 13, 2010
I have to disagree with "There is some redundancy in the information provided to the constructor." in the general case. The highest node number found in the list of edges will not be the highest node number of the graph if the node(s) with the highest node number(s) is(are) of degree zero. (Although for representing maps it should be quite safe to assume a non-zero degree for all nodes except the case of a single node.)Anonymous
July 14, 2010
<blockquote> There is some redundancy in the information provided to the constructor. We could have deduced the number of nodes by taking the maximum integer found in the list of edges, instead of requiring that it be passed. </blockquote> I just wanted to point out that explicitly requesting the length up front is probably a good idea because it doesn't assume that everything has an edge. Not having any edges is also information. Hawaii anyone?Anonymous
July 14, 2010
@Svick That implementation will do better for sparse graphs. For dense graphs we may as well use the matrix because we can determine if an edge exists in O(1) time, rather than O(degree)Anonymous
July 14, 2010
@nick-m If you need to find out whether an edge between two vertices exists, then sure. But you don't need that in this problem, the class Graph doesn't even have something like public bool IsEdge(int node1, int node2). So, if the only thing you need is to find out the list of all neighbours of certain vertex, adjacency list is faster or as fast (in the case of a complete graph) as adjacency matrix.