CosmosDB change feed monitoring
Let's continue in the serie of the posts focused on the CosmosDB change feed. In this post we will focus on the diagnostics.
Goals
After running the change feed processor we need to be sure that:
- the documents are processed from all partitions and
- the age of the documents is within the limit and
- the costs consumed by change feed processor is under control and
- the communication between change feed processor and CosmosDB meets QoS requirements.
Let's deep dive each aspect from the bottom up.
The costs and QoS measurement
Change feed processor uses DocumentDB SDK to connect and communite with CosmosDB. It connects to two sources: document feed collection and lease collection. Just to recap:
- feed collection is the collection providing the documents for processing
- lease collection is a collection used by change feed processor in order to manage and distribute the partitions processing evenly between all change feed processors.
Change feed processor gives the developer a possibility to configure how to connect to the collections. By default it creates a DocumentClient under the hood. It also gives a possiblity to pass directly DocumentClient or IChangeFeedDocumentClient instances.
We will use last option here (document client level). Using this approach it will be possible to catch all calls made from change feed processor to document client and meter the calls, frequency, costs and reliability.
Let's define a metering reporter interface and its console implementation.
Let's create a metering decorator for IChangeFeedDocumentClient:
As you can see the change feed query has to be decorated too. Here is the decorator:
And let's put it all together:
That's all. It's possible to run it.
From our experience we used this to see if we have throttling issues when accessing lease collections, when listing the leases, updating the leases, etc. It all adds to the feed processing time so it's worth measuring it.
In addition to the monitoring, using the explicit document client give us a possiblity to fine-tune the connection policy (e.g. switching to direct TCP connection mode, open connection timeouts, etc).
Monitoring the age of the documents
This is the metric which defines how much the change feed processing lags behind. Each document has a field _ts (document level).
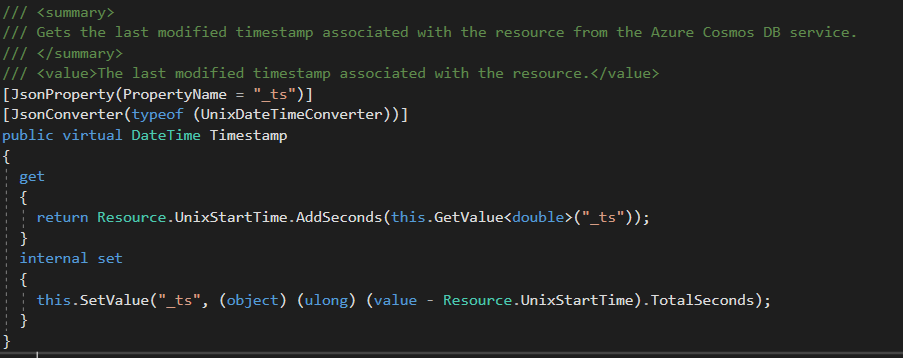
This is a system property representing epoch time (it's the number of seconds! that have elapsed since 00:00:00 (UTC), 1 January 1970) when a document was last updated (e.g. create or replace). That's enough for this measurement. Let's see it in action:
From our experience this is the one of the metrics we use to define SLA for our service where we measure e2e latency/processing time. It has one more requirement, time synchronization. So you need to ensure that the servers where the change feed processing is runnning are synchronized with closest NTP servers.
Processing the documents from all partitions are moving forward
This is the most import metric, I think. It's possible to do it on 2 levels:
- observer level
- document client level
As we saw in the first post from this series, the observer is the component which is getting the feed. Here is the interface:
We will leverage OpenAsync/CloseAsync callback methods. The observer is called once the change feed processor instance opens or closes the processing of the partition. This could happen due to reasons like:
- redistributing the partition processing load when scaling up/down the cluster or
- redistributing the partition processing load when rollout/shutdown the cluster or
- system error
Here is the complete list of the closing reasons:
It's necessary to monitoring high and constant frequency of closing the partitions because it signals an issue, especially reasons Unknown and ObserverError.
Unknow is due to internal change feed processor issues. In such case, inspect the logs (see previous post) and report the issue to https://github.com/Azure/azure-documentdb-changefeedprocessor-dotnet.
In case of observer error the issue will be in your code ;)
All other reasons signals transient issues and the system should recover from them.
At the end of the day, you need to monitor that the number of open partitions is equal to the number of all partitions in the collection and there are no closings. This ensures that the processing is working smoothly.
But that's not all, folks. It's also necessary to track that the partitions are being processed. It could happen that the partition processing is open but reading the feed per partition is stuck. Yes, we had such issues in past! So how to solve it?
There is a cheap but "undocummented" way which we will try to get into the library.
Undocummented way
Reading the partition feed is done by change feed document client and its response has a session token and feed documents. Session token is in the format <partition ID>:<LSN>. LSN is the last commited transaction number per partition.
The document has also "_lsn" which is the LSN which commited the document change (create or replace).
The whole point is to report that the reading the documents from the particular partitions occurs and that it is progressing till the end. One of the options is to report the remaining work (session LSN - document LSN).
Remaining work estimator
The previous approach was so call "undocummented". There is also other, documented approach built inside change feed processor SDK and exposed via IRemainingWorkEstimator. Let's see it:
It has a drawback. The estimator calculates estimated work for whole consumer and collection, not just per partition. So the best option is to go with the undocumented way until it is exposed in SDK. We will fix it!
This helped us to avoid incidents, especially in the early stages of integrating the change feed processor.
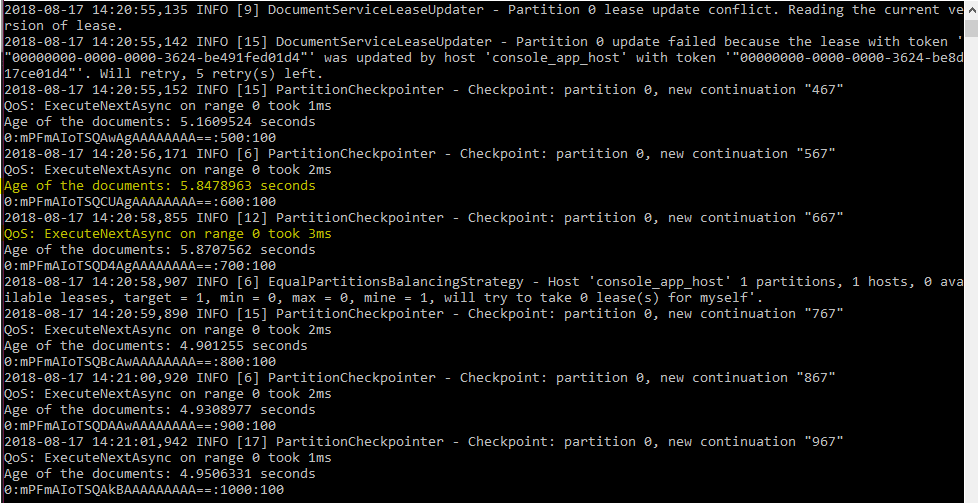
Let's put it all together. As usual, the whole code is at my github repo. After running it, the output would be:
Previous posts: