A Power BI Data Analytics Pipeline for ISVs
In this blog I set out an architecture for a data analytics pipeline that starts with an SQL Server database and ends with a Power BI dashboard. The pipeline can be fully automated so that updates to the data in the core SQL Server DB flow through the pipeline to the dashboard without human intervention – but can be monitored at each step of the way. Most of the provisioning of the pipeline components can be automated as well, making it easy for a software company to set up new customers as they come on board. The code associated with this blog is here: https://github.com/sebastus/PowerBIPipeline.
The Architecture
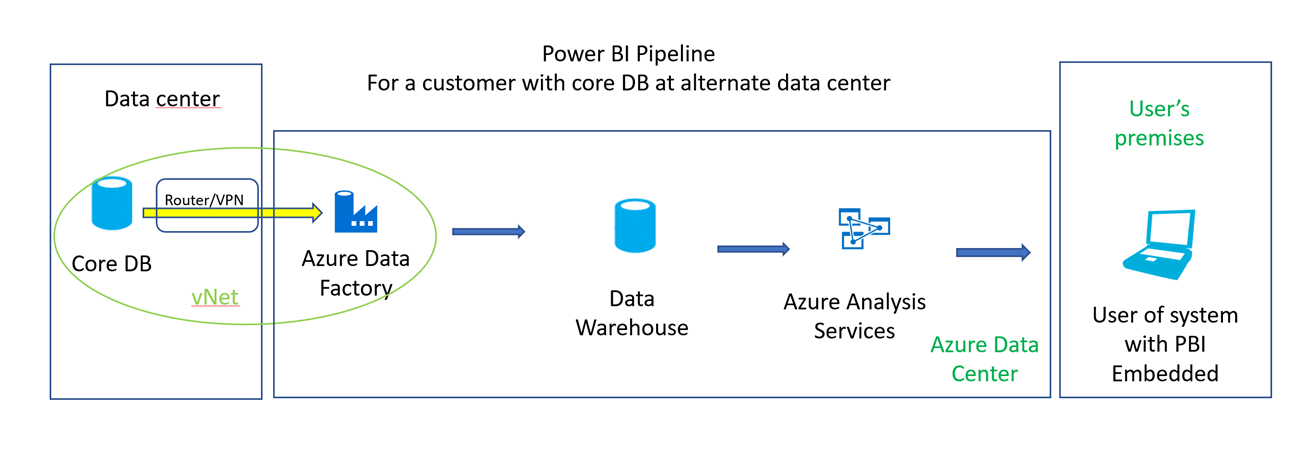
Overview
Core DB is the customer's operational database. The data warehouse isn't necessarily a large-scale system – it could simply be a SQL Server database or Azure SQL DB that fulfills the role of data warehouse. In this case that means it serves as an isolation layer between the core DB and further abstraction in the analysis services layer. Azure Data Factory hosts a SQL Server Integration Services Integration Runtime (SSIS IR). This provides worker agents that run your SSIS packages. These packages will run periodically (daily or hourly most likely) copying new and updated data to the data warehouse. The SSIS IR package also can tell the Azure Analysis Services server to process models (copies and refactors data from data warehouse to analysis services model). The PBI reports and dashboards are connected to the Analysis Services model using Direct Query.
Implementation details
All components in my test are running in the East US data center. Having everything in one place isn't possible in all locations around the world, so care must be taken to minimize traffic between the elements if they must be in different locations.
Core DB
In my test system, the Core DB is a SQL Server VM running in Azure with a copy of the AdventureWorks database installed. If the core database is not in Azure, a network link must be established. These techniques are well known. One option is a Site-to-Site VPN. Another is ExpressRoute. Even if the database is in Azure, the vNet is still required to make connectivity to the SSIS IR straightforward. The Core DB can be any database that is supported by SQL Server Integration Services.
Azure Data Factory
ADF is a managed cloud service that's built for complex hybrid extract-transform-load (ETL), extract-load-transform (ELT), and data integration projects. I used Version 2 in my test system. The major component used is an SSIS IR as part of ADF. Its job is to host the worker agents that run your ETL packages. It only needs to be up (and costing money) during those times. It can be scaled both up and out to meet speed/number/size of workload needs. One other important component in the solution is an ADF Pipeline. The ETL package details the work, i.e. specifies which data sources are input and output, says what data to copy, etc. The pipeline orchestrates the work, i.e. says when to run it, what parameters to use, etc.
How many of these are needed? I don't see any need for more than one for reasons of scalability, but if you're operating in multiple regions then one per region makes the best sense.
Data Warehouse
In my test system, the Data Warehouse is an Azure SQL Database. For a software company implementing this pipeline for a group of customers, the Azure SQL DB might be in an Elastic Pool. For a company with a terabytes or petabytes sized database, a true data warehouse solution like Azure SQL Data Warehouse might be the best fit.
You'll need one per customer for this component. They can be grouped into Elastic Pools on a per region basis, but usually Elastic Pools are allocated with other concerns (such as scale) in mind as well.
Azure Analysis Services
AAS is a fully managed platform as a service (PaaS) that provides enterprise-grade data models in the cloud. It allows you to use advanced mashup and modeling features to combine data from multiple data sources, define metrics, and secure your data in a single, trusted tabular semantic data model. Not shown in the picture but a very important element of the solution is Visual Studio. SQL Server Data Tools is an extension to Visual Studio that provides modelling of the analysis services model/database and deploying the model to AAS. If Visual Studio is not installed, selecting Install a new SQL Server Data Tools instance installs SSDT with a minimal version of Visual Studio.
Like ADF, one AAS instance per region makes the best sense, though there will be one model/database per customer.
Provisioning the pipeline
Basic provisioning of the elements in the pipeline is handled by the PowerShell files in the scripts folder of the repo. To run them, open a PowerShell command line or the PowerShell ISE and navigate to the repo's scripts folder. 'common.ps1' contains variables specific to your environment, so start by tailoring it to your needs. 'InitializeResources.ps1' executes the script system in the right order while maintaining an operating context. Run it by typing '.\InitializeResources.ps1' at the PowerShell command prompt or by loading that script into the ISE and clicking the F5 button on your keyboard.
From left to right, here are some details about provisioning that you should read before proceeding. Really. If you don't read this, you'll have to start over.
Speaking of starting over, here's a quick note about the script system. At the top of 'common.ps1' is a variable called $index. $index is appended to all globally-unique names in the scripts. I assume that I'm going to have to iterate a few times before I get it right, so I start with $index = '01' and run the scripts. When it fails, I start the delete process for the Azure resource group ('pbiRg01' for example), change $index to '02', make whatever updates I need to the common.ps1 variables or my environment and then start installing again. $index can be anything you want – it doesn't have to be numbers.
Virtual Network
The virtual network facilitates communication between the core DB and the SSIS IR cluster. Outside the context of a vNet/subnet, the IP addresses of the SSIS IR VMs aren't static, so you can't put them into the firewall or NSG rules that protect the core DB. You should put your core DB into one subnet (call it 'one') in the vNet and the SSIS IR into another (call it 'two'). Then you can create a Network Security Group (NSG) protecting subnet 'one' but allowing incoming traffic from subnet 'two'. This way, as the SSIS IR cluster scales up and down, all of the VMs in the cluster will be able to contact the core DB. Details regarding this can be found here. The 'InitializeADFandAASandPBI.ps1' script implements this correctly.
Azure Data Factory
During provisioning of ADF, the SSIS IR is created but not started. One of the parameters of SSIS IR creation is a Secure Access Signature (SAS) URI for a container in the storage account created by 'InitializeStorage.ps1'. In that container will be a couple of files from the scripts folder: 'main.cmd' and 'processASDatabase.ps1'. These files get loaded onto each of the SSIS IR VMs as they are started (each time they are started). They form a part of the ADF pipeline – making it possible for the pipeline to tell the Azure Analysis Services server to process a database.
Azure SQL Server
The provisioning scripts create only the Azure SQL Server, not the Azure SQL Database that is a customer's data warehouse. There is a separate script (NewCustomerDw.ps1) that creates the data warehouse databases because it's run once per customer. 'InitializeSQLServer.ps1' creates the Azure SQL Server and two firewall rules. One of them allows Azure services to contact the server. The other allows your local PC to contact it so you can manage the server.
Regarding server credentials: 'common.ps1' calls the PowerShell cmdlet 'Get-Credential'. This allows you to inject your password into the script system securely.
Adding a customer
There are a few assets that are required for each customer. They are:
- Core DB + network configuration allowing access to it
- Data warehouse database
- ADF pipeline configured with connection details for the core DB and the customer's data warehouse database
- Analysis services tabular model, both in Visual Studio and in AAS
Core DB / network
In my test system, the core DB is a SQL Server VM. It has no internet IP address – only a local subnet address. That subnet ('one') has a network security group rule that allows incoming traffic from subnet 'two' which contains the SSIS IR VMs.
Data warehouse database
The data warehouse database is created by 'scripts\NewCustomerDw.ps1'. That script takes as a parameter the name of the database, such as 'customerA'. It uses 'common.ps1' to establish context, so it knows the name and location of the SQL Server and so on. Part of creating the new database is importing a data tier application containing the schema of the data warehouse. Create that data tier application and put it in the 'db' folder of the repo. Call it 'dwSchema.bacpac' or fix up 'common.ps1' with the name that you decide to use.
Analysis services model
In the repo, I named the analysis services project 'aasTemplate' for a reason. You're going to need one per customer and they're all the same, at least to start with. There is no facility for stamping out copies of them but there is a way and it's documented it in another section below. The first step is to create a template using SSDT by connecting to one of the data warehouse databases, specifying the desired tables, creating relationships and whatever else needs to be there. After following the instructions to replicate the template, open the new project. Opening the project causes a new model to be created in the Azure Analysis Services instance. Find the new model in the Azure portal and copy its name. This name is value needed in the 'dbName' parameter required in the ADF pipeline. Save the project in Visual Studio – you'll need it later if you need to make changes.
ADF pipeline
The ADF pipeline has a dependency on the SSIS package exemplified by adfEtl.dtsx in the adf project located in the repo. How that asset was created is the subject of a section below.
Each customer's pipeline instance invokes this SSIS package with the appropriate parameters:
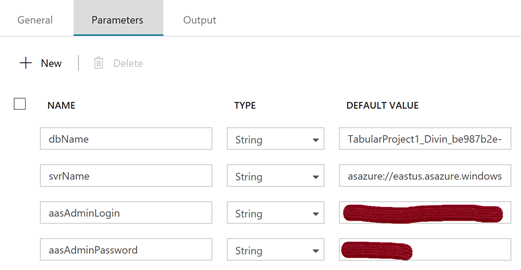
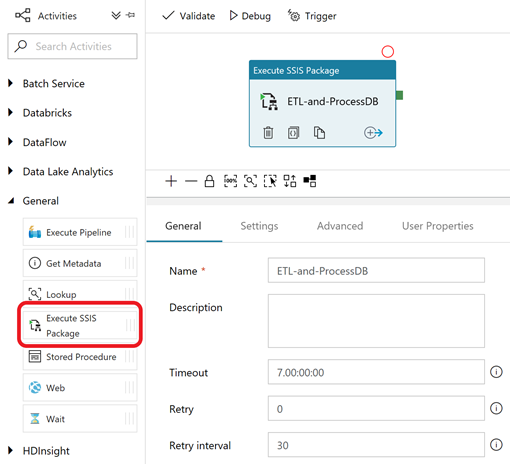
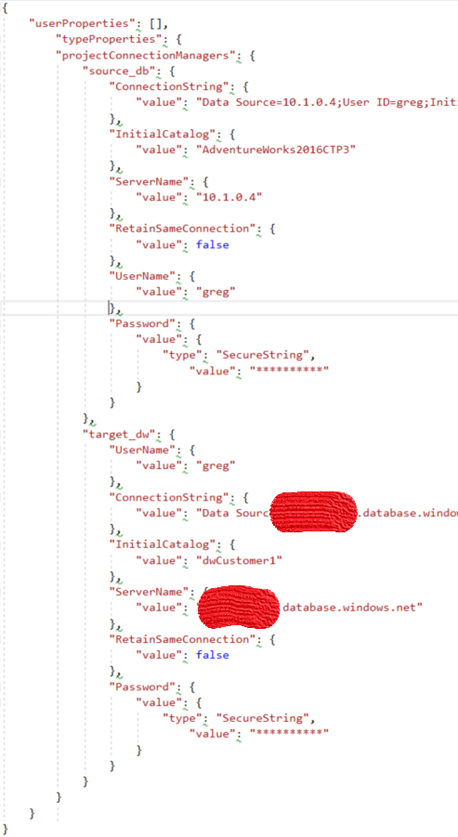
That pipeline executes an Execute SSIS Package Activity. It requires configuration as well, specifically connection details for the 'source_db' and the 'target_dw'.
General page:
Settings page:

Advanced page:

The Advanced page starts out with only typeProperties. It's the place where you need to put the 'source_db' and 'target_dw' connection details. Here's a more complete sample:
Replicating the Analysis Services Model Template
One approach to this is programmatic. The docs are here. An alternate approach is to edit a few project files in a text editor. It's a little hacky, but very quick and accurate.
NOTE: In the following, references to 'CustomerA' should match up with the name given to the data warehouse database above.
- Copy the 'aas' project folder. Rename the new folder something like 'aasCustomerA'.
- File aasTemplate.smproj
- Rename the file to something like 'aasCustomerA.smproj'.
- Change <PropertyGroup>.<Name> from 'aasTemplate' to something like 'aasCustomerA'.
- Change all instances of <PropertyGroup>.<DeploymentServerDatabase> to something like 'aasCustomerA'.
- Change all instances of <PropertyGroup>.<DeploymentServerName> to match your AAS server name.
- File Model.bim
- Change all instances of 'dwCustomerX' to something like 'dwCustomerA'. This is the data warehouse database name and must match above.
- File Model.bim_xxx.settings
- Change <ModelUserSettings>.<ServerName> to match your AAS server name.
- Change <ModelUserSettings>.<DatabaseName> to simply 'aasCustomerA'. This is the analysis services database name. It does not need to match anything.
- In Visual Studio, right-click the solution and Add, Existing Project. Select 'aasCustomerA.smproj'.
- Open Model.bim in the added project. You may have to authenticate to the AAS server.
- Process the model. This will involve authenticating to the data warehouse database. Save the solution.
- Over time, there will be more and more AAS projects – one per customer – and hopefully a lot of them.
- In the Azure Portal, take a look at your AAS server. You will see a new database/model for CustomerA. Congrats!
Creating the Process Analysis Services Model task
As each new customer is added, an SSIS Activity is created to encapsulate the parameters specific to the new customer. Some of the parameters are specified for convenience; others are needed to pass down to the PowerShell script 'processASDatabase.ps1'.
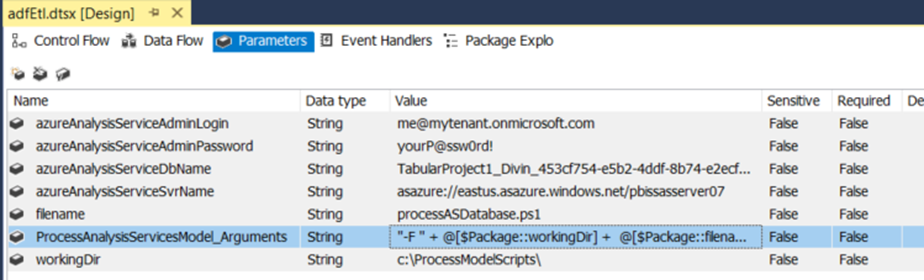
The highlighted item is built in another dialog: (building it there creates it here)
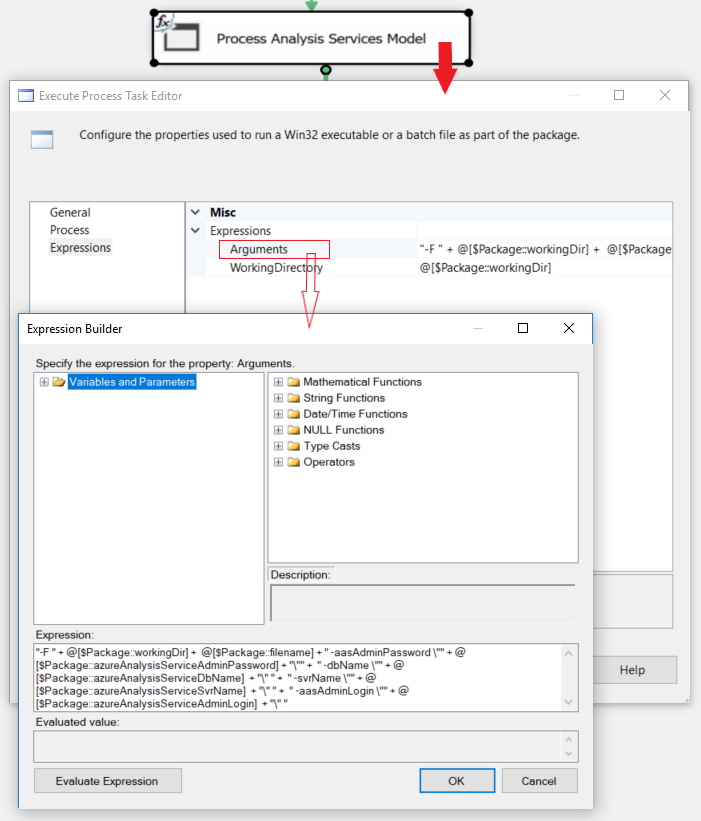
On the Process page of the Execute Process Task Editor, the Arguments and WorkingDirectory expressions are evaluated and filled in based on editing them on the Expressions page:
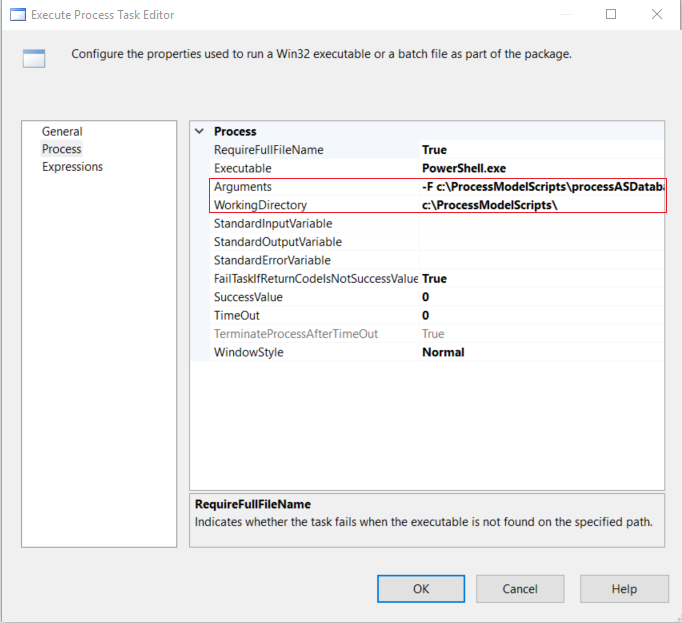
The arguments are structured so the command passes them into the PowerShell script:

Once you have this pipeline working, you can replace elements in it to better fit your circumstances. For example, maybe you want to use an Azure SQL Data Warehouse. Or you might want to use a SQL Server VM to host your SSIS and SSAS functions. And of course, you can use whatever data sources you want for the Core DB, such as Oracle or MySQL.
Cheers!