Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Hi Folks,
Let's continue with the discussion of spatial indexing form last time. If you already know a lot about spatial indexing these first few posts are going to be a lot of background---hopefully I don't make too many mistakes. :)
We're going to focus on Madison, WI, and try to answer a very simple question: which roads intersect Univerity Avenue. (You might notice that I've changed the question a little. This makes things a little easier for me to draw, but doesn't change the procedure at all.) Here's our query object as displayed in Virtual Earth:

Let's first cast this english query as SQL. Assume that we have a table Roads(id int, g geography), and that our query object (in this case, Univerisity Ave) is in a parameter @x. We can now express this as:
SELECT id
FROM Roads
WHERE g.STIntersects(@x) = 1
Without an index, we have to scan the entire Roads table. How can we break this into a primary/secondary filter? We'll start by looking at a very simple indexing scheme: the grid index. I want to emphasize that this is not what we do in SQL Server, but it does provide a good stepping stone to understand what we are doing.
A grid index does exactly what it says: it grids space. For illustration purposes, let's constrain space to that right around Madison. Here's a rough gridding of that space:
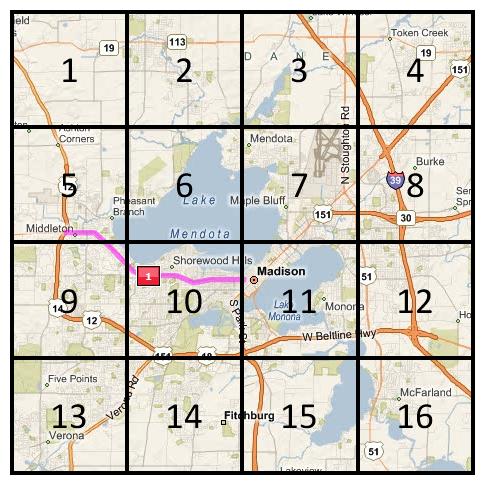
Given this gridding, we can now assign a set of numbers to each object based on the grid cells it intersects. In other words, the grid defines a table-valued function that maps a spatial object to a table of integers representing the cells. For example, if @x is our query object, then Grid(@x) = {5, 9, 10, 11}:

We get a similar result for every road in our Roads table. Furthermore, since any two roads that intersect must share a cell, we can use these cells to define a primary filter for the intersection predicate. Conceptually, this means that we can replace our original query with:
SELECT id
FROM Roads
WHERE
EXISTS (
SELECT *
FROM Grid(@x) g1 JOIN Grid(Roads.g) g2 on g1.cell = g2.cell
)
AND g.STIntersects(@x) = 1
Keep in mind that this rewrite is only a conceptual one. In practice, we aren't actually going to rewrite the SQL, rather we'll restructure our query plan internally. The SQL is only meant to illustrate what's going on underneath.
With that caveat, notice that what we've really done is simply added the EXISTS clause to the original query. Let's call that our primary filter, call the original intersection predicate the secondary filter, and examine how this EXISTS clause satisfies the three criteria for a primary filter I laid out last time:
- It may indeed produce false positives, since two objects may share a cell and not intersect. On the other hand, two objects cannot intersect without sharing a cell, so it produces no false negatives.
- This example is a bit schematic---16 cells isn't enough to give a nice tight bound around the object---so let's say we're satisfied that it dosn't produce too many false positives.
- Ah! Here's a problem: this primary filter can't possibly be fast the way I've written it. Now instead of just computing an intersection for each row of the table, we have to compute the Grid function on each element. That can't be fast.
So, we still need to make our primary filter fast. I'm sure many of you know where we're going with this, but we'll save it for next time.
Cheers,
-Isaac
[28.11.07: Edited to fix broken image link.]
Comments
Anonymous
November 27, 2007
we'll be patient with you Isaac!Anonymous
December 05, 2007
Hi Folks, Last time we talked about a simple primary filter. (See previous installments: 1 , 2 .) WeAnonymous
February 05, 2008
Hi Folks, Well, I never did complete my series of posts describing our indexing scheme. I guess I oughtAnonymous
February 05, 2008
Hi Folks, Well, I never did complete my series of posts describing our indexing scheme. I guess I oughtAnonymous
May 28, 2009
Hi Folks, This post contains no new information; it’s just a rollup of links to spatial indexing posts