Backup to Azure using TSQL (and CLR)
Hi All,
as a sample of how to use Microsoft SQL Server To Windows Azure helper library let me show you how to perform a backup to azure using the TSQL. As prerequisite, of course, you should have downloaded and installed the helper assembly (for how to do that please refer to the project documentation).
In our sample we will be using the Azure page blob. The page blob is well suited for random access allowing us to upload the backup in data chunks. It's useful since we can resend only the failing chunks instead of the whole backup. In order to use a page blob we need to define its maximum size first. In a way it acts like a sparse file: your tell the file system how big the file should be and then start putting content in it.

Of course we should put an exclusive lease on the blob. We should release the lease only when the upload procedure is complete. Failing to do so might allow readers to get a non complete copy (we all know the SQL isolation levels enough to know how bad that could be). In this sample, however, will leave that out to a later post.
So in order to upload a backup we should follow this macro-code:
- Backup to temporary storage.
- Create the page blob with maximum size = backup size.
- Split the backup in pages of reasonable size (as usual, big chunks are most efficient but a failed upload would mean more data to retransmit).
- Create a table to keep track of the uploaded chunks.
- Upload the pages verifying the outcome.
Let's get down to the code:
Backup to temp storage
This is easy:
SET NOCOUNT ON;
BACKUP DATABASE [DemoAzureCLR] TO DISK='C:\temp\DemoAzureCLR.bak' WITH INIT, COMPRESSION;
GO
Nothing fancy here.
Create the page blob with maximum size = backup size
This is much more interesting. First use a pretty CLR function that returns us the backup size.
DECLARE @size BIGINT = [Azure].GetFileSizeBytes('C:\temp\DemoAzureCLR.bak');
Now that we have the size we can call the correct [Azure] stored procedure: CreateOrReplacePageBlob:
-- Create the "sparse" page blob.
EXEC [Azure].CreateOrReplacePageBlob
'your_account',
'your_shared_key', 1,
'your_container',
'DemoAzureCLR.bak',
@size
Of course you should replace the parameters with the one of your Azure container.
Split the backup in pages of reasonable size
Now we must calculate in how many chunks we want to split the backup file. I like to upload 32KB for each call so we divide the total size by 32*1024. Note that since we round up to the nearest integer we might end up with unused space. This must be accounted during the last upload: if we upload too much data - even if zeroed - the backup would be unusable.
DECLARE @PageCount INT = CEILING(CONVERT(FLOAT, @size) / (1024.0*32.0));
Create a table to keep track of the uploaded chunks
To keep things simple we can use a simple table with an integer ID and a text field. The Chunk field identifies the chunk (page) number. Any non null string in the text field indicates that the chunk is yet to be uploaded. Since we know that the upload function will return null in case of success and a text in case of error all we have to do is to iterate between non-null rows, try to upload the corresponding chunk and then update the text field.
First the table definition:
IF EXISTS(SELECT * FROM tempdb.sys.objects WHERE name = '##progressTable')
DROP TABLE ##progressTable;
CREATE TABLE ##progressTable(ID INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, Chunk INT NOT NULL, OpStatus NVARCHAR(MAX) NULL);
Then we initialize it (rember: a null value means "chunk uploaded successfully!"):
-- Prestage the progess table
DECLARE @iCnt INT = 0;
WHILE @iCnt < @pageCount BEGIN
INSERT INTO ##progressTable(Chunk, OpStatus) VALUES(@iCnt, 'ToUpload')
SET @iCnt += 1;
END
Upload the pages verifying the outcome
All that's left to do is, for each non null row, upload the corresponding chunk:
DECLARE @pageNum INT, @ID INT;
DECLARE @len INT;
WHILE(EXISTS(SELECT * FROM ##progressTable WHERE OpStatus IS NOT NULL))
BEGIN
SELECT TOP 1 @pageNum = Chunk, @ID = ID FROM ##progressTable WHERE OpStatus IS NOT NULL;
SET @len = 1024*32;
IF ((1024*32*@pageNum)+@len)>@size
SET @len = @size -(1024*32*@pageNum);
PRINT 'Uploading page number ' + CONVERT(VARCHAR, @pageNum) + '. ' + CONVERT(VARCHAR, @len) + ' bytes to upload.';
UPDATE ##progressTable SET OpStatus = [Azure].PutPageFunction(
'your_account', 'your_shared_key', 1,
'your_container',
'DBPartition.bak',
[Azure].GetFileBlock(
'C:\temp\DBPartition.bak',
1024*32*@pageNum,
@len,
'Read'),
1024*32*@pageNum,
@len,
NULL,
NULL,
0,
NULL)
WHERE ID = @ID;
END
Note that the T-SQL UPDATE statement is very handy in this case. Note, also, that we account for the last upload: since it might not be aligned to the 32KB boundary we check to make sure to upload only the valid data.

Notice that in my sample execution the last upload should not be 32KB since the backup isn't 32KB-aligned. Our code, however, handles that:

Notice that the last chunk is smaller than the previous ones. As usual, we can query the container to find our brand new blob (using the ListBlobs TVF):
SELECT * FROM [Azure].ListBlobs(
'your_account',
'your_shared_key', 1,
'your_container',
1,1,1,1,
NULL);
Here is our backup:
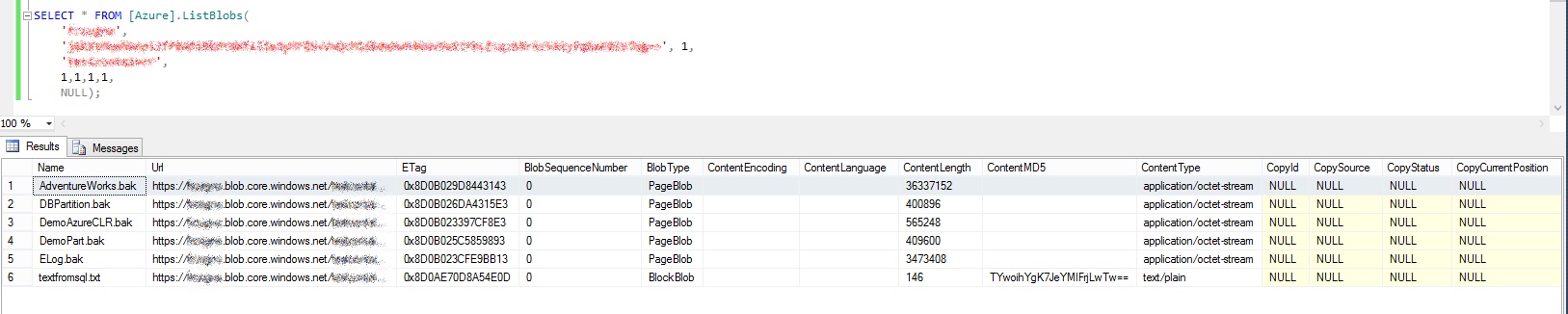
You can try to download the blob using your browser (the URI is there for a reason!) and restore it. You will find that your backup was saved to the cloud successfully.
 Last but not least, even though there is no MD5 show by the ListBlobs function each upload was MD5ed separately and checked server-side by azure. So, since every chunk is checksumed the whole file is checksumed as well :). Want to know how this is done by the library? Check the open source code in Microsoft SQL Server To Windows Azure helper library project in CodePlex.
Last but not least, even though there is no MD5 show by the ListBlobs function each upload was MD5ed separately and checked server-side by azure. So, since every chunk is checksumed the whole file is checksumed as well :). Want to know how this is done by the library? Check the open source code in Microsoft SQL Server To Windows Azure helper library project in CodePlex.
Here is the complete script for this sample:
IF EXISTS(SELECT * FROM tempdb.sys.objects WHERE name = '##progressTable')
DROP TABLE ##progressTable;
SET NOCOUNT ON;
BACKUP DATABASE [AdventureWorks] TO DISK='C:\temp\AdventureWorks.bak' WITH INIT, COMPRESSION;
GO
DECLARE @size BIGINT = [Azure].GetFileSizeBytes('C:\temp\AdventureWorks.bak');
CREATE TABLE ##progressTable(ID INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, Chunk INT NOT NULL, OpStatus NVARCHAR(MAX) NULL);
DECLARE @PageCount INT = CEILING(CONVERT(FLOAT, @size) / (1024.0*32));
PRINT CONVERT(VARCHAR, @pageCount) +' 32KB-pages to upload (total ' + CONVERT(VARCHAR, @size) + ' bytes). Added ' + CONVERT(VARCHAR,(@PageCount*1024*32) - @size) + ' bytes as padding.';
-- Prestage the progess table
DECLARE @iCnt INT = 0;
WHILE @iCnt < @pageCount BEGIN
INSERT INTO ##progressTable(Chunk, OpStatus) VALUES(@iCnt, 'ToUpload')
SET @iCnt += 1;
END
-- Create the "sparse" page blob.
EXEC [Azure].CreateOrReplacePageBlob
'your_account',
'your_shared_key', 1,
'your_container',
'AdventureWorks.bak',
@size
PRINT '"Sparse" blob created.'
DECLARE @pageNum INT, @ID INT;
DECLARE @len INT;
WHILE(EXISTS(SELECT * FROM ##progressTable WHERE OpStatus IS NOT NULL))
BEGIN
SELECT TOP 1 @pageNum = Chunk, @ID = ID FROM ##progressTable WHERE OpStatus IS NOT NULL;
SET @len = 1024*32;
IF ((1024*32*@pageNum)+@len)>@size
SET @len = @size -(1024*32*@pageNum);
PRINT 'Uploading page number ' + CONVERT(VARCHAR, @pageNum) + '. ' + CONVERT(VARCHAR, @len) + ' bytes to upload.';
UPDATE ##progressTable SET OpStatus = [Azure].PutPageFunction(
'your_account', 'your_shared_key', 1,
'your_container',
'AdventureWorks.bak',
[Azure].GetFileBlock(
'C:\temp\AdventureWorks.bak',
1024*32*@pageNum,
@len,
'Read'),
1024*32*@pageNum,
@len,
NULL,
NULL,
0,
NULL)
WHERE ID = @ID;
END
SELECT * FROM [Azure].ListBlobs(
'your_account',
'your_shared_key', 1,
'your_container',
1,1,1,1,
NULL);
Happy Coding,