[Advent Calendar 2017 Day4] 自動スケールのスケールルールについて
こちらの記事は、Qiita に掲載した Microsoft Azure Tech Advent Calendar 2017 の企画に基づき、執筆した内容となります。
カレンダーに掲載された記事の一覧は、こちらよりご確認ください。
※ この記事は 2017 年 12 月 4 日時点の内容になり、予告なく変更される場合がございます。
こんにちは。Azure サポートチームの多田です。
App Service をはじめとする Azure のいくつかのサービスではインスタンスの負荷状況に応じて、自動的にインスタンスを増やすことができる自動スケールという機能がございます。
急なアクセス数の増加などに自動的にインスタンス数を増やし、高い負荷状況に対応できます。またアクセス数が落ち着いたときは自動的にインスタンスを減らすことも可能です。
自動スケールはスケールルールの設定に基づいて実行されますが、スケールルールの各設定項目の役割が少々複雑であり、弊社サポートチームでもよくお問い合わせを受けます。今回は App Service におけるこのスケールルールの設定項目と動作についてご説明します。
自動スケールの設定
自動スケールの設定は App Service から、[スケールアウト (App Service プラン)] を選択し、[自動スケールの有効化] をクリックします。
任意の “自動スケール設定の名前” を設定し、”インスタンスの制限” にて適切なインスタンス数を入力し、[Add a rule] をクリックします。
自動スケールのスケールルールの設定項目が表示されます。
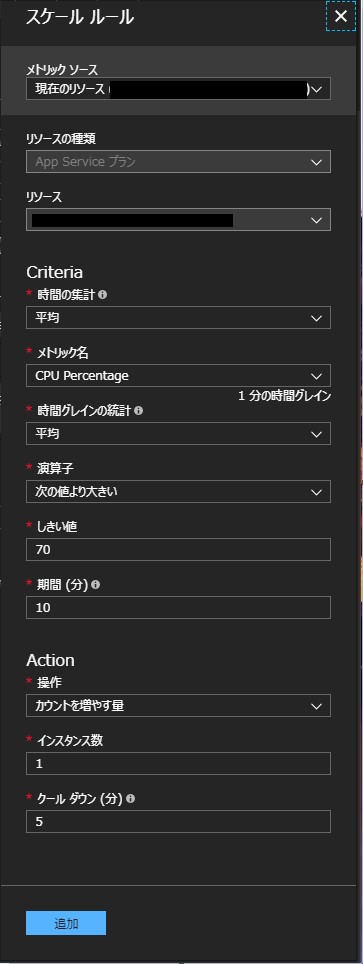
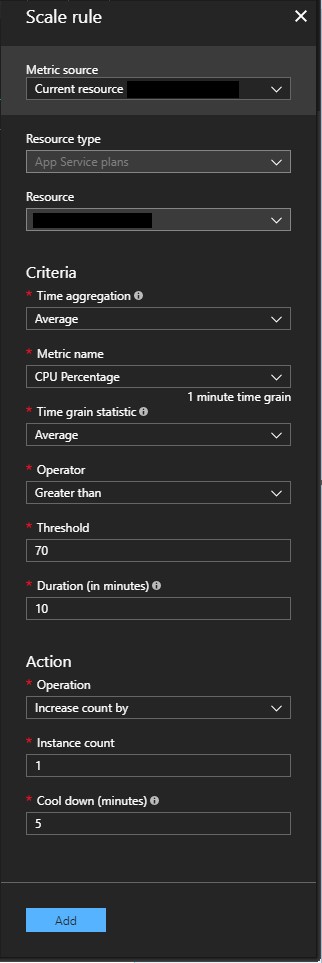
スケールルールについて
スケールルールではまず現在の App Service プランや Application Insights などのメトリックリソースを選択します。
今回は現在の App Service プランをメトリックリソースとして選択します。App Service プランのメトリックは CPU Percentage や Memory Percentage など複数のメトリックがございます。今回は CPU Percentage を前提として説明します。
スケールルールは以下の 2 段階で評価が行われます。
1) Time grain statistic (時間グレインの統計):
評価のために取得されるメトリックは、time Grain (時間グレイン) に指定された間隔ですべてのインスタンスから取得されます。このメトリックは、複数のサンプリング値を、Time grain statistic (時間グレインの統計) に指定された定義に基づいて集計し、取得されます。
例えば、time Grain (時間グレイン) が 1 分の場合、1 分間の間に一定間隔 (例えば 5 秒間隔ですが、これはメトリックによって異なります) で取得された複数のサンプリング値を集計します。Time grain statistic (時間グレインの統計) が Maximum (最大) の場合はそれらの最大値、Average (平均) の場合はそれらの平均値が取得されます。
2) Time aggregation (時間の集計):
time Grain (時間グレイン) に指定された間隔で取得されたメトリックについて、Duration (期間) の間に取得されたものを、Time aggregation (時間の集計) に指定された定義に基づいて集計します。
例えば、time Grain (時間グレイン) が 1 分、Duration (期間) が 10 分である場合、10 個のメトリックを集計してルールの評価を行います。Time aggregation (時間の集計) が Maximum (最大) の場合はそれらの最大値、Average (平均) の場合はそれらの平均値をもとに、ルールが評価されます。
このため、Time grain statistic 'Average', time grain '00:01:00', Duration '00:10:00', Time aggregation 'Maximum' という設定については、例えば以下のような動作になります。
1) CPU Percentage のサンプリング値が5 秒間隔で取得されている場合、1 分間に 12 個のサンプリング値が取得され、それらの平均値がメトリックとして取得されます。
2) 10 分の間に1) のメトリックが 10 個取得され、それらの最大値をもとに、ルールを評価します。
上記の計算のより、スケールアウト (またはスケールイン) すると判断された場合、Action の設定値に基づき、インスタンス数を増減させます。また、一度スケールアウト (またはスケールダウン) されると Cool down (クール ダウン) に指定された時間だけ待機します。待機が終わると再び計算値に基づき、インスタンス数を増減させます。
スケールルールの具体例
以下のようにスケールルールが設定されていたとします。
スケールルールの設定値
Metric name (メトリック名) : CPU Percentage
Time grain statistic (時間グレインの統計) : Average (平均)
time Grain (時間グレイン) : 1 分
Time aggregation (時間の集計) : Maximum (最大)
Duration (期間) : 5 分
Threshold (しきい値) : 70
Operator (演算子) : Greater than (次の値より大きい)
※ time Grain (時間グレイン) は Azure Portal からは直接変更できません。
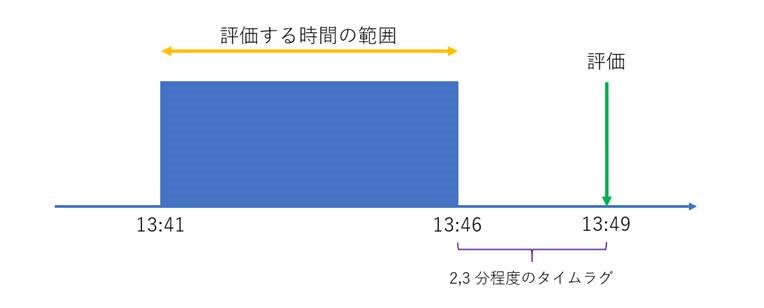
13:49 にルールを評価する場合、13:41 から 13:46 の時間の範囲の計算値によって評価されます。評価される時間の範囲は、使用されるメトリック値が出来上がるまで多少時間を要するため、2, 3 分程度のタイムラグがございます。
1) Time grain statistic (時間グレインの統計):
CPU Percentage のサンプリング値が5 秒間隔で取得される場合、1 分間に 12 個のサンプリング値が取得され、それらの平均値がメトリックとして取得されます。
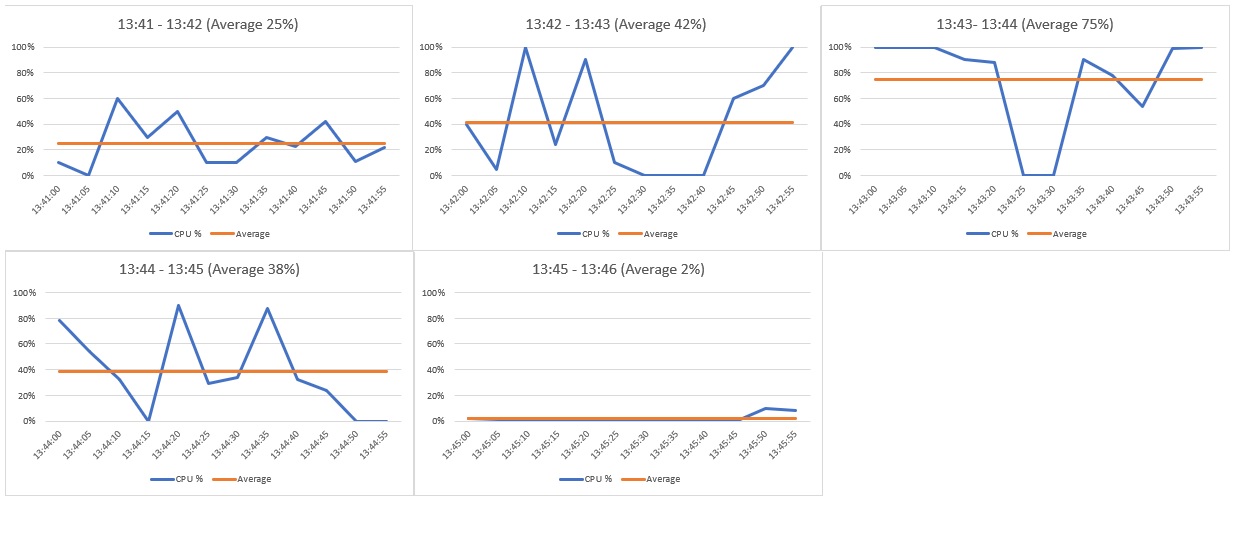
2) Time aggregation (時間の集計):
Duration (期間) が 5 分であるため、上記の 5 つ分のメトリックが取得されます。それらの最大値をもとに評価を行います。
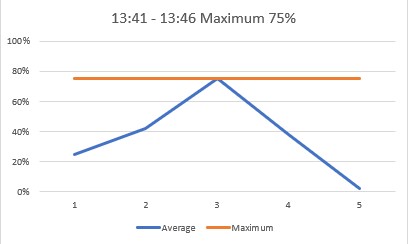
3) 評価:
上記の計算の結果、最大値が 75 になります。
Threshold (しきい値) が 70 で Operator (演算子) : Greater than (次の値より大きい) であるため、スケールアウトすると判断されます。
補足情報など
自動スケールの設定を行う場合、意図しないスケールアウト (またはスケールイン) することを防ぐため、あらかじめ以下の技術資料をご一読ください。
自動スケールのベスト プラクティス
/ja-jp/azure/monitoring-and-diagnostics/insights-autoscale-best-practices
--- 一部抜粋 ---
スケールアウトとスケールインのしきい値に十分な差を付けておくことをお勧めします。 たとえば、次の有効なルールの組み合わせについて考えてみます。
- CPU 使用率が 80 以上のときにインスタンスを 1 つ増やす
- CPU 使用率が 60 以下のときにインスタンスを 1 つ減らす
この場合、次のようになります。
- 最初に 2 つのインスタンスがあるとします。
- 全インスタンスの平均 CPU 使用率が 80 %に達すると、3 つ目のインスタンスが追加され、スケールアウトされます。
- 時間の経過と共に、CPU 使用率が 60 %に低下したとします。
- 自動スケールのスケールイン ルールにより、スケールインした場合の最終状態が推定されます。 たとえば、60 x 3 (現在のインスタンス数) = 180 / 2 (スケールインしたときの最終的なインスタンス数) = 90 % となります。 このため、次のタイミングでスケールアウトを再度実行しなければならないので、スケールインは実行されません。 代わりに、スケールインがスキップされます。
- 次回チェックされたときに、CPU 使用率が 50 %に低下していると、50 % x 3 インスタンス = 150、150 / 2 インスタンス = 75 %となり、スケールアウトのしきい値である 80 %を下回っているため、2 つのインスタンスに正常にスケールインされます。
---------------
さいごに
自動スケールの機能はスケールアウト (スケールイン) されるまでの時間の短縮など機能改善に日々力を入れています。
これからの自動スケール機能の進化にご期待ください。