Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This post is authored by Wee Hyong Tok, Principal Data Science Manager at Microsoft.
Deep Learning has fueled the emergence of many practical applications and experiences. It has played a central role in making many recent breakthroughs possible, ranging from speech recognition that's reached human parity in word recognition during conversations, to neural networks that are accelerating the creation of highly precise land cover datasets, to predicting vision impairment, regression rates and eye diseases, among others.
The Microsoft Cognitive Toolkit (CNTK) is the behind-the-scenes magic that makes it possible to train deep neural networks that address a very diverse set of needs, such as in the scenarios above. CNTK lets anyone develop and train their deep learning model at massive scale. Successful deep learning projects also require a few critical infrastructure ingredients – specifically, an infrastructure that:
- Enables teams to perform rapid experimentation.
- Scales, based on the demands of training.
- Handles the increasing load needed to serve a trained model.
Meanwhile, container technologies have been maturing, with more enterprises using containers in their IT environments. Containers are allowing organizations to simplify the development and deployment of applications in various environments (e.g. on-premises, public cloud, hybrid cloud, etc.). Various container orchestration and management technologies are now available, including Docker Swarm, Kubernetes, and Mesosphere Marathon.
This blog post is about how to use Kubernetes clusters for deep learning. Kubernetes is an open-source technology that makes it easier to automate deployment, scaling and management of containerized applications. The ability to use GPUs with Kubernetes allows the clusters to facilitate running frequent experimentations, using it for high-performing serving and auto-scaling of deep learning models, and much more. This post shows you how to use CNTK with Kubernetes on Azure, and how to perform auto-scaling of your infrastructure, as the number of requests increase.

Jumpstart to Using CNTK + Kubernetes + GPUs on Azure
Let's get started on creating an agile, customizable AI infrastructure for doing deep learning on Azure. Code used in this post is available on GitHub. The following steps will jumpstart the process of getting the Kubernetes cluster up and running, testing to make sure that the NVidia drivers are loaded correctly, and providing references to CNTK examples for training and serving the models.
- Deploy the Kubernetes Cluster using Microsoft Azure Container Service (ACS) Engine.
- Test that the NVidia drivers are loaded correctly.
- Run a CNTK Example. You can use an existing CNTK image (available at https://cntk.ai/ ), custom-build a new Docker Image (refer to sample dockerfile), or use one of the Docker images (with CNTK) that have been posted to Docker Hub.
A common question we get is whether running deep learning jobs on a Kubernetes cluster has any overheads, and, if so, what are the overheads. To explore this, we run the CNTK training using CIFAR-10 (50,000 training images and 10,000 test images) on these two configurations:
- Configuration A: Using an Azure NC6 Virtual Machine.
- Configuration B: Running a job in the Kubernetes cluster (with an Azure NC6 Virtual Machine node).
We observed an average processing rate of 1784 samples/s and 1709 samples/s for Configurations A and B, respectively.
Deploy the Kubernetes Cluster Using ACS Engine Azure Container Service (ACS) is a managed service on Azure that lets you quickly deploy a production cluster using either Kubernetes, DC/OS or Docker Swarm. Mathew Salvaris and Ilia Karmanov have written an excellent tutorial on how to deploy deep learning models on ACS, available here.
ACS Engine runs underneath the hood in ACS to help create container service deployments. ACS-Engine is an open source command-line tool that lets you quickly create the Azure Resource Manager (ARM) templates for deployments and other relevant files needed to deploy a Kubernetes cluster on Azure. The tool takes as input a cluster definition (shown in Figure 2 below) and outputs the files needed for you to provision a Kubernetes cluster successfully on Azure.
You can use this detailed walkthrough to setup your Kubernetes cluster on Azure, with the GPU drivers installed (this uses a fork of ACS Engine provided by William Buckwalter).
Note: Once this PR is merged into ACS Engine, then you will be able to use the official ACS Engine (Version 2.0) to use GPUs with Kubernetes.
Figure 1 below provides an overview of how ACS Engine can be used to create your customized Kubernetes cluster on Azure.
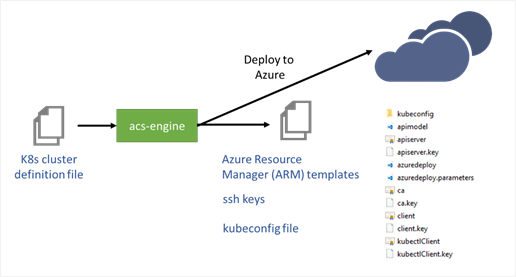
Figure 1: Using acs-engine to deploy Kubernetes cluster to Azure
Using the ARM templates, you can use the Azure CLI to deploy the Kubernetes cluster on Azure. This creates the Azure Virtual Machines (using the information specified in the cluster definition file), the virtual networks, and the storage accounts needed by the cluster. After the cluster is deployed to Azure, three virtual machines are created on Azure: VM1, VM2 and VM3. Of these, VM1 is the master node. In addition, two pools of resources are created – VM2 and VM3. VM2 is an Azure NC6 Virtual Machine (with NVidia Tesla K80) and VM3 is an Azure DS_V2 Virtual Machine. Azure provides a rich set of GPU Virtual Machines, and you should choose one that meets your needs (refer to Azure GPU Virtual Machine sizes).
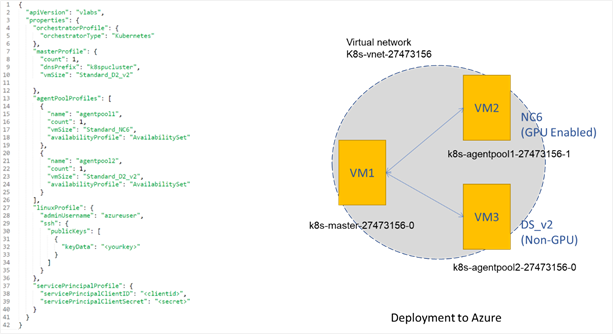
Figure 2: kubernetes.json (acs-engine cluster definition file), and Azure deployment
Code for Kurbenetes.json (shown on the left) is available here.
Ensure Nvidia Drivers are Loaded Right
If you've followed the instructions in the detailed walkthrough, you will have your Kubernetes cluster up and running on Azure. Congratulations! To verify that the cluster has been created successfully, you can run the command kubectl get nodes. Figure 3 below shows the output from running the command.
 Figure 3: Output from kubectl get nodes
Figure 3: Output from kubectl get nodes
You should verify that the Nvidia drivers are setup right, and that for the pods that run on each of the nodes, they can use the Nvidia driver. To do this, you can run the azuregpu-test job that is available here. Figure 4 below shows the job that you can run on the cluster to test if the Nvidia drivers are loaded correctly. You will notice the use of the NVidia command-line utility nvidia-smi.
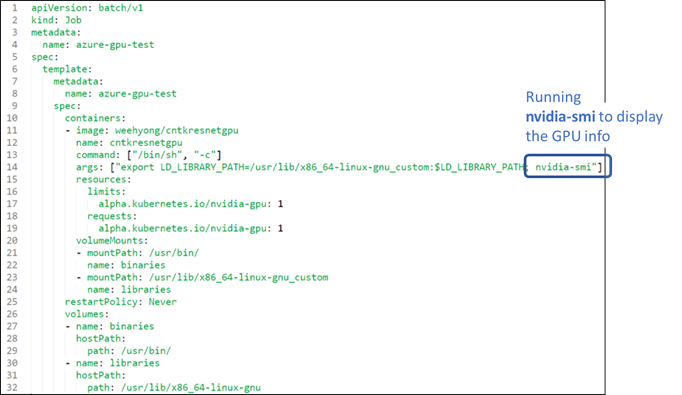
Figure 4: Azure Test GPU Job YAML.
Code is available here.
To test whether the NVidia drivers are loaded correctly in the Kubernetes cluster, following the following steps:
Run kubectl create -f azuregpu-test.yaml
Once the job is created, run the following command:
kubectl get jobs

You should see an azure-gpu-test job being created.
You can verify the name of the pods where it is running:
kubectl get pods

You should see the name of the pod. Usually it is the naming convention is the <Job Name>-<5 character identifier>
Once the job has completed, you can get the logs on the machine:
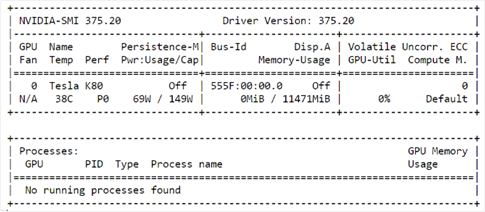
kubectl logs azure-gpu-test-83ngh
You will see the following output from the completed job. In the output, you will see that the NVidia Tesla K80 is being used for this job.
Auto Scaling Deep Learning on Azure
GPU is a key ingredient to deep learning. To optimize the use of the GPU machines that are available across your entire team, it's important to scale up to the right number of machines when needed, and scale down when machines are no longer needed (i.e. to avoid low utilization rates for extended periods of time). In addition, after the models are trained, they need to be operationalized. Depending on the number of requests that the operationalized environment needs to handle, it's important to have a backend serving infrastructure that can automatically scale based on the load of the nodes. The serving nodes must often meet specific service-level agreements (SLAs). For example, the serving infrastructure may be required to handle 1,000 requests/second. Initially, the load might be low, and hence a smaller number of pods can be used. As the load increases, to continue meeting the SLA, additional pods and nodes may be required, to keep up with the requests.
To do this, autoscaling on the Kubernetes cluster becomes really useful. Kubernetes provides both pod-level scaling (out-of-the box), and node-level scaling (which requires additional features to be installed). Kubernetes provides horizontal pod autoscaling (HPA), which automatically scales the number of pods in the cluster based on your requirements. HPA lets you specify specific node metrics (e.g. CPU %, memory %, etc.) that are tracked when determining whether new pods should be added or removed. For instance, when the CPU% of a particular node exceeds the user-defined threshold, HPA adds more pods to the cluster.
In addition, you can also add node-level scaling, where new Azure Virtual Machines are added when the number of resources available in the cluster is not sufficient to meet the expected requirements. For example, an existing Kubernetes cluster might only have 2 nodes (with GPUs). If you submit 3 Kubernetes jobs, where each specifies the requirement for a GPU (see Figure 5 below), there will not be sufficient nodes with GPU resources available. The third job that requires GPU will be in a Pending state, till node-level autoscaling kicks in and provisions a new Azure Virtual Machine with GPU. To setup node-level autoscaling for your Kubernetes cluster, refer to this detailed walkthrough by William Buchwalter.
Both HPA and node-level autoscaling can work together to give you the flexibility to autoscale the number of pods, and the number of nodes (i.e. virtual machines) as needed on Azure.
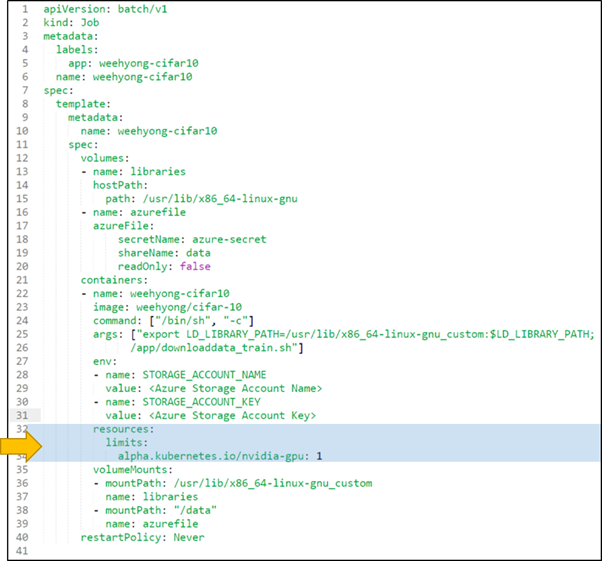 Figure 5: Kubernetes job that specifies GPU resource requirements (lines 32-34).
Figure 5: Kubernetes job that specifies GPU resource requirements (lines 32-34).
Code is available here. Dockerfile specified in the job is available here.
In Azure, node-level autoscaling on the Kubernetes cluster, shown in Figure 6 below, occurs as follows:
- When a new job gets submitted to Kubernetes, it is first placed in a Pending state.
- kube scheduler kicks in, and first determines whether there's any work to be scheduled. In this case, there is a pending item X. Three nodes (A, B and C) are available, but there are no nodes with free capacity.
- kubernetes-acs-autoscaler (which runs in a control loop) kicks in, and notices that there's a pending pod X. As there are no more available nodes that can handle that request, it provisions a new virtual machine using an Azure Deployment. When this is happening and you view the deployments running in the Azure Resource Group, you will see an active deployment that is creating the new virtual machine, connecting it to the virtual network, and informing the Kubernetes cluster that a new node D has been added.
- When the kube scheduler runs again, it will find the newly provisioned node D with free capacity. Pod X is then placed on node D.
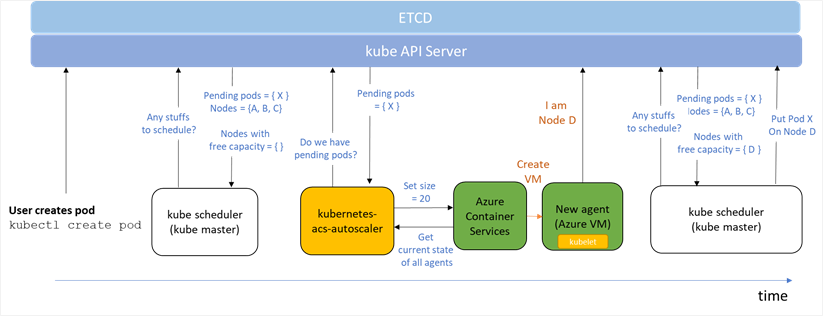
Figure 6: How Node-Level Kubernetes works on Azure.
(Credits: Based on the diagram from William Buchwalter.)
Summary
In this post, we showed you how to get started on running CNTK with Kubernetes using Azure GPU Virtual Machines. This provides a flexible and customized AI infrastructure on Azure that lets you train and serve your deep learning models at scale. You can try out the sample CNTK job/deployment on the Kubernetes cluster that you have created on Azure.
In addition to these CNTK examples for Kubernetes, William Buchwalter has developed excellent resources on running TensorFlow on Kubernetes on Azure, available here on GitHub.
If you prefer a managed service to manage the resources on your GPU clusters (i.e. instead of creating a custom Kubernetes cluster), you should check out Azure Batch AI Training and Azure Batch Shipyard.
We would love to hear from you – if you have thoughts or feedback on this post, please do share them via the comments section at the bottom of this page.
Wee Hyong
@weehyong
References
- Azure Container Service Engine (acs-engine) Kubernetes walkthrough.
- Creating a Kubernetes cluster with GPU support on Azure for Machine Learning.
- Autoscaling a Kubernetes cluster created with acs-engine on Azure.
- Sample CNTK Docker images used in the article.
Acknowledgments
I would like to thank Mathew Salvaris, Ilia Karmanov, William Buchwalter, Rita Zhang and Kaarthik Sivashanmugam for reviewing this article. In addition, the detailed walkthrough by Mathew, Ilia and William on doing deep learning on ACS and Kubernetes were super useful as well.