March Madness - My First Azure ML Experience
This post is by Adam Garland, Senior Software Engineer on the Office Core Platform at Microsoft.
The Azure ML team recently hosted an internal March Madness competition to showcase their service. Besides just plain fun, the purpose of the competition was to increase internal awareness of the tool and to uncover any usability or other bottlenecks.
Machine learning has always been appealing to me since I have a passion for big data. With a desire to learn more about ML, the March Madness contest was a great way to jump right in and I can’t believe how easy the Azure ML Studio made that experience. This was my first experience with Azure ML and really my first experience with any ML tools. Over the course of two weeks, I was able to go from no ML experience to creating a winning ML model.
To get started I navigated to https://azure.microsoft.com/ml and signed in. I started with the first of the five tutorial videos, "Getting Started." This gave me an overall view of the Studio, the different parts, and how to create an experiment. From that point I wanted to start with an existing sample experiment. I picked an experiment that predicted when people would survive a particular disaster given a set of information about that person. I figured that was the closest to predicting whether a team would win or lose based on a different set of data and that it would give me a basic idea of what type of ML algorithm to use.
Using the example and the Azure ML Studio it took me less than a couple hours to create my workspace, import some basic data, drag in a training model, and have my first example experiment up and running. Next I switched the example dataset over to the basic set of historical tournament data provided to us. This only took a few minutes. Watching the tutorial videos, I knew the basics of importing data, and hence it was just a matter of dragging in the new dataset, connecting the data to the existing model and deleting the old data set. Having walked through the survival example I knew that I needed to change the column that was going to be predicted by making it the "Label." I made the necessary changes and ran the model.
The question was, was the model any good? At first I really did not know how to even evaluate my model. But that was another area that Azure ML made this experience easy. Using the Evaluate Model module the Studio presented me with a lot of information about my model, like the Accuracy, F1 scores, and the area under the curve (AUC). With that list of information, and a couple of searches on Bing, as a ML novice I was able learn in a few minutes how to evaluate my model in a way that was easy to accomplish and easy to understand. But, at this point, with the limited set of data, my first model was not very good.
From that point on I spent some time finding more historical data to help start making my model more accurate and increasing its AUC. I scoured the web and downloaded the results data for years’ worth of game results. For about an hour I spent time coalescing the data and averaging out all the results based on team and year, in Excel. I was more comfortable working in Excel at the time, but having worked with the Studio for some more I realize this is definitely something that could have been done right in the experiment using some of the Statistical Function modules.
Once I had the “extra” data, all the necessary tools were there to join the data into the model. Initially there was difficulty on the joins due to different team name abbreviations which I solved with a mapping table. With the experiment setup and the historical data available, from that point on I spent an hour or two each night over the next week improving my model. I had a sense of what features I wanted to use in my model so I wanted to try a couple different ML trainers. To do that I was able to copy and paste the entire model and have two models side by side. I had noticed the Evaluate Model module had two imports so I connected the copied version of the model to the right side, chose a different training model, and ran the experiment. Inputting two models into the evaluator made it easy to compare them side by side. Each time I found a training model that improved my experiment I saved a new copy of my experiment and changed the other side of the model. After doing a dozen or so iterations on my model I finally settled in on the Two Class Decision Jungle which was giving me the best baseline AUC of all the learners.
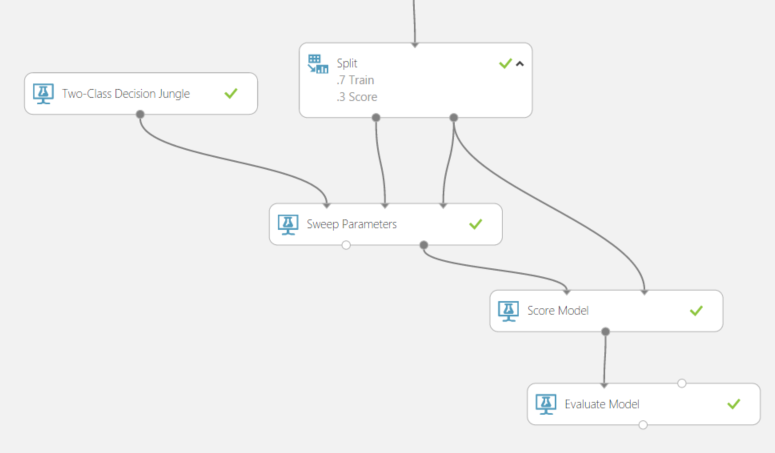
After settling in on a learner, I needed to choose some parameters. In similar fashion I started to compare the results of two experiments with different sets of parameters for the Decision Jungle. The number of parameter options were much more than the number of learners. This was taking a lot more time then comparing learnings. Doing some more research I came across the Sweep Parameters feature – another Azure ML feature that simplified my experience. The screenshot below shows how easy it was to setup the workflow – all of the logic above was data curation and joining of data from various sources:
With this year’s new twist of providing the Web Service as the submission that was a simple three click process, Create Scoring Experiment, Run, and Publish Web Service. The only hiccup was that it took about an hour to determine where to place the import of the data to join up with the historical data to make the predictions. Done and Done.
Overall it was a great experience.
Adam
Comments
- Anonymous
May 10, 2015
I stopped reading when I saw the buzzwords "big data". - Anonymous
May 13, 2015
Well, did all that statistics work tell you that Duke was going to win this year or not? Or did it tell you Ketucky was going to win? ...like the majority of the world, including a variety of big-name stats crunchers, mistakenly thought? I read the entire article to see if this software could overcome the prevalent Kentucky college basketball fallacy. The stats that this year's Kentucky team produced overwhelmingly suggested that they would win the championship. But as great as they were, there was something off about them as a team; too young and inexperienced or maybe too much individual star power for effective teamwork when teamwork was vital? It sounds like the software is a pleasure to work with. But I was really interested to see what it could really do as far as this statistical conundrum in the mad world of college basketball. Thanks for the interesting article anyway.