Riding the Big Data Tiger
This post is authored by Omid Afnan, Principal Group Program Manager at Microsoft. Omid's talk, "Go Big (with Data Lake Architecture) or Go Home!" will be featured at the Microsoft Machine Learning & Data Science Summit on September 26-27 in Atlanta.
I've had the pleasure (and pains) of working in big data for years, first building the platforms used by Microsoft's own online services, including our Bing search engine, and, more recently, expanding that work to build a service that our enterprise and developer customers can use as well.
The journey we went through on the Bing team to build a powerful and usable big data platform was tough, but I learned a lot from it. Making a platform such as this as powerful as possible is a natural instinct for all hardcore geeks such as myself. But the bigger insight for me has been that taking something complex like a data lake service and making that super easy to use is several times more impactful from a customer standpoint.
When I talk to developers, architects or IT managers today, although they're excited about trying or adopting new technologies such as Hadoop and Spark, many are less sure about how to get started, or where to get the right skills to help their organizations succeed, or how to get to this new holy grail from where they happen to find themselves today.
Azure Data Lake, U-SQL, and our Visual Studio tooling were all built with this in mind, i.e. the notion that teams have lots of existing investments – in SQL, data warehousing, general purpose languages, etc. – and that they need help in successfully moving to / integrating with the new world of big data.
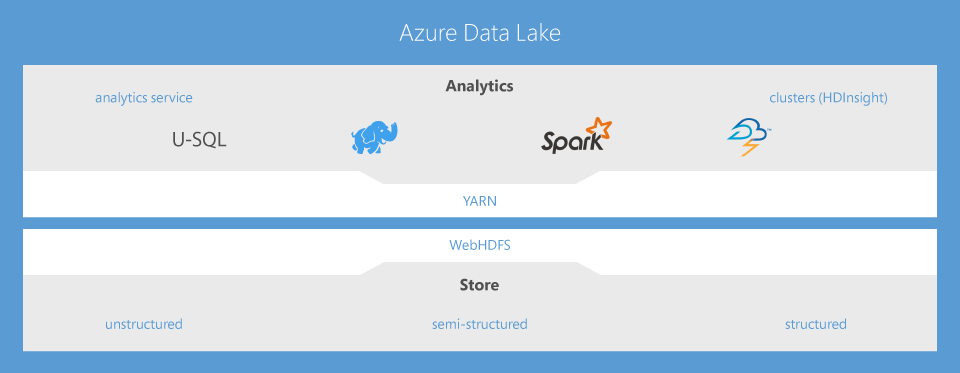
A big part of big data is collecting raw data and cooking it into intermediate datasets that can function as a "data platform" that can then power the exploration and reporting processes that ultimately lead to desired business insights. Our approach is to make the concepts and code behind the curation of a data platform easy by modeling them on things people already know. That's why U-SQL puts the power of massively distributed computations behind a familiar SQL + C# language that most enterprise coders can pick up quickly.
I've spent a fair bit of time with folks who run these big data pipelines, and there are lots of lessons to share. At the Microsoft Data Science Summit in Atlanta I will share some of the scenarios that Microsoft's customers in energy, retail, and technology have solved with big data, and I will provide some patterns for how to get your big data projects going alongside existing IT environments. I'm also looking forward to learning from what seasoned big data practitioners among you have to share with me and with my colleagues at Microsoft.
At the end of the day, our goal is to make big data additive and complementary to what business teams and IT groups are already using. And the tools we provide also have a simple goal: Make the experience of coding a program that runs on a 1,000 cores and 100 PB as easy as coding for your desktop machine.