Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This post is authored by Xibin Gao, Data Scientist, Wei Guo, Data Scientist, Brad Severtson, Senior Content Developer, and Debraj GuhaThakurta, Senior Data Scientist Lead, at Microsoft
What is TDSP
Improving the efficiency of developing and deploying data science solutions requires an efficient process to complement the data platforms and data science tools that you use. Many enterprise data science teams today face challenges pertaining to standardization, collaboration and the use of appropriate DevOps practices when developing and deploying their advanced analytics solutions.
We developed and released the Team Data Science Process (TDSP), an open GitHub project, to address these very challenges. TDSP is currently helping numerous data science teams in Microsoft and at other organizations to standardize their data science projects, adopt collaborative development and DevOps practices. TDSP was first released at Ignite in September 2016.
In this blog post, we provide an overview of recent developments involving TDSP, including recent releases and how its adoption has gone since our first public release.
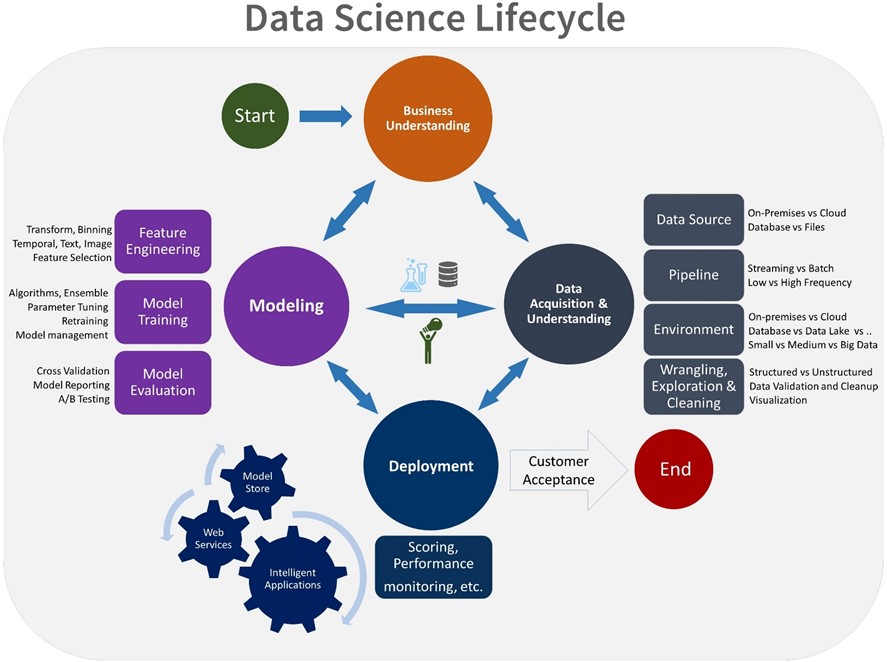
Recent Releases
Since our 2016 launch, we've made the following updates to TDSP:
Standardized Data Exploration and Reporting: IDEAR in Microsoft ML Server and Python
Standardization of data science projects and their artifacts is an important goal and deliverable of TDSP. With that objective, the TDSP team released the IDEAR (Interactive Data Exploration and Reporting) utility in R in September 2016. IDEAR helps you to generate a standardized report for the data exploration/understanding phase of the TDSP lifecycle (see image above). Since then, we've released additional versions of IDEAR for Python 3 which can be run on a client machine or on Azure Notebook Services, and for Microsoft Machine Learning Server (formerly called Microsoft R Server, or MRS) for big data. These also include several new features related to analysis of missing data, clusters with mixed data types, etc. Here's the link to the GitHub repository for IDEAR and also AMAR, our R utility for Automated Modeling and Reporting.
End to End Spark v2.0 Walkthrough
To facilitate the development and deployment of end-to-end data science solutions, we've previously published many walkthroughs following the TDSP lifecycle and using a variety of Microsoft data platforms and analytics tools including Azure Machine Learning, HDInsight Spark, Azure Data Lake and Azure SQL Data Warehouse. Microsoft Azure released Spark 2.0 on HDInsight (Linux) as a service in September 2016. To jumpstart the use of Spark 2.0 on HDInsight for data science and machine learning, we released an end-to-end data science walkthrough using pySpark and MLlib. Here's a link to the related GitHub repository.
End to End SQL Server Tutorial with Python
SQL Server 2017 with machine learning services was released earlier this year.It allows Python scripts to run within SQL Server or to be embedded in SQL scripts and be deployed as stored procedures. Data scientists can combine the power of SQL and Python and build end-to-end machine learning solutions with much greater ease. We released a Python walkthrough that demonstrates how to build machine learning solutions in SQL Server 2017 following the TDSP lifecycle.
Instantiating the TDSP Template in Azure Machine Learning
Up until now, it has not been possible to instantiate the TDSP structure and templates directly within a data science tool. We've now enabled instantiation of project structure and templates within Azure Machine Learning, providing the benefits of standardization to data science teams that are using Azure Machine Learning.
TDSP Adoption
TDSP has been adopted by many data science teams within Microsoft and externally by several other organizations. For instance, Microsoft Consulting Services and other similarly mature data science teams within our large data science community are currently using TDSP to execute and deliver their advanced analytics projects. Also, organizations, such as, BlueGranite and New Signature are actively using TDSP to deliver analytics solutions and workshops to their customers.
Based on our customers' experiences, one of the things we've discovered is that organizations looking to standardize on TDSP may need to take a step-wise approach towards adopting its various practices and components. Some features, such as the standardized project structure, document templates and artifacts, as well as version control can be adopted in earlier stages. Also, organizations starting with TDSP-provided templates and artifacts may want to customize certain aspects to ensure they fit the nature of the projects in their organization (for instance, scoping templates for a specific business vertical). TDSP provides the standardization and collaboration guidelines, structure and templates as a foundation, which can be adopted easily with appropriate customization and staging by different organizations, based on the maturity of their data science teams and nature of their projects.
We would love to hear your feedback on how TDSP can be further enhanced for your evolving needs in this space – you can send us your feedback and comments via the GitHub issues page for TDSP or in the comments section below.
Xibin, Wei, Brad and Debraj
Comments
- Anonymous
October 09, 2017
I'm looking for some best practices or example to structure the Azure Resource Groups for managing shared analytics and storage infrastructure. I have opened an issue with details at https://github.com/Azure/Microsoft-TDSP/issues/7. Please suggest.