Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This is the third post in a three-part series by guest blogger, Adrian Rosebrock. Adrian writes at PyImageSearch.com about computer vision and deep learning using Python. He recently finished authoring a new book on deep learning for computer vision and image recognition.
Introduction
In the final part in this series, I want to address a question I received from Mason, a PyImageSearch reader, soon after I published the first post in the series:
Adrian,
I noticed that you said tested all of the code for your new deep learning book on the Microsoft Data Science Virtual Machine (DSVM). Does that include the chapters on training networks on the ImageNet dataset as well? I work at a university and we're allocating our budget for both physical hardware in the lab and cloud-based GPU instances. Could you share your experience training large networks on the DSVM? Thanks.
- Mason
Mason poses a great question – is it possible, or even advisable, to use cloud-based solutions such as the Microsoft DSVM to train state-of-the-art neural networks on large datasets?
Most deep learning practitioners are familiar with the "Hello, World" equivalents on the MNIST and CIFAR-10 datasets. These examples are excellent to get started as they require minimal (if any) investment in GPUs.
But when you start working with very large datasets, there are a lot of aspects to consider, including:
- Network latency and time to upload/download a large, 100 – 250 GB+ dataset.
- I/O throughput on the actual hardware in the cloud.
- Speed of the CPU to handle both 1) pre-processing and data augmentation, and 2) moving data on and off the GPU.
- The GPUs themselves, including their model and specs.
To address Mason's question, I'll be spending the rest of this post discussing how I trained SqueezeNet on the ImageNet dataset and evaluated the training performance 1) in the Azure cloud, and 2) compared to my local deep learning box.
ImageNet and the ILSVRC Challenge

ImageNet is a project aimed at labeling and categorizing images into its 22,000 categories based on a defined set of words and phrases. At the time of this writing, there are over 14 million images in the ImageNet project.
In the context of computer vision and deep learning, whenever you hear people talking about ImageNet, they are likely referring to the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
The goal of the image classification track in the challenge is to train a model that can correctly classify an image into 1,000 separate object categories, some of which are considered fine-grained classification and others which are not.
Images inside the ImageNet dataset were gathered by compiling previous datasets and scraping popular online websites. These images were then manually labeled, annotated, and tagged. An example collage of these images can be found in the figure at the top of this section (image credit).
Since 2012, the leaderboard of the ILSVRC challenge has been dominated by deep learning-based approaches (image credit):
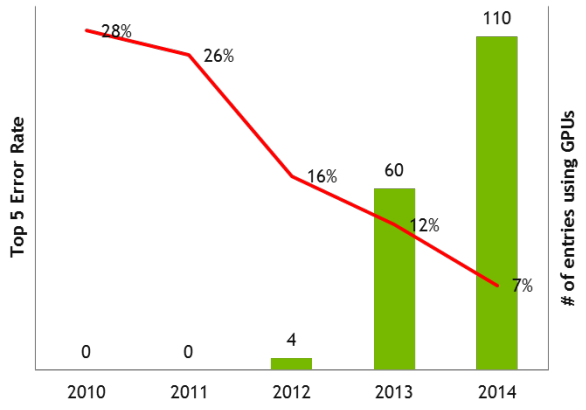
Models are trained on the ~1.2 million training images with another 50,000 images for validation (50 images per class) and 100,000 images for testing (100 images per class). To alleviate the need to submit results on the testing set to the ImageNet evaluation server, I created my own testing set by sampling 50,000 images from the training set, thereby allowing me to (easily) evaluate locally.
Implementing SqueezeNet
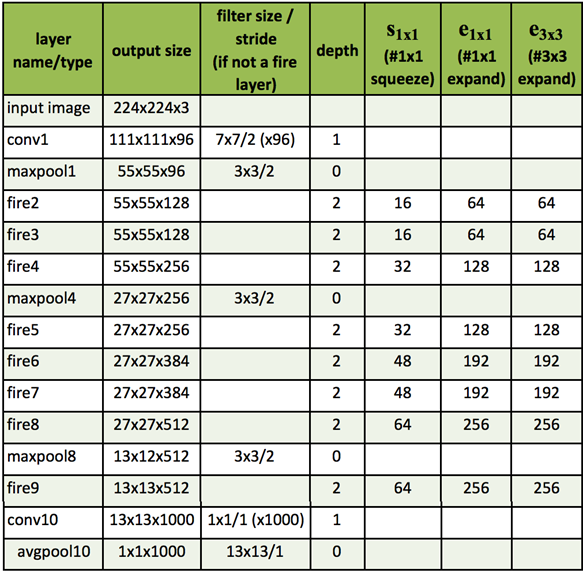
When using the Microsoft Azure cloud, the Ubuntu DSVM I used utilized both the NVIDIA Tesla K80 GPU and NVIDIA V100. Both the K80 and V100 are more than powerful enough for working with large datasets. The network latency was also minimal, comparable to other cloud-based deep learning solutions. I was able to 1) download the ImageNet dataset directly from the ImageNet.org site as well as 2) upload a local copy from my personal network within a few days' time.
The architecture I implemented (using MXNet) comes from Iandola et al.'s 2016 paper, SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
I choose to use SqueezeNet for a few reasons:
- I had a local machine already training SqueezeNet on ImageNet for a separate project, enabling me to easily compare results.
- SqueezeNet is one of my personal favorite architectures.
- The resulting model size (< 5MB without quantization) is more readily used in production environments where new models need to be deployed over resource constrained networks or devices.
While SqueezeNet certainly does not compare to the accuracy of DenseNet or ResNet, it has many interesting properties from a deep learning practitioner standpoint (small model size, low memory footprint, computationally efficient, easier to deploy, etc.). My implementation of SqueezeNet can be found in the GitHub repo associated with this post.
Training SqueezeNet
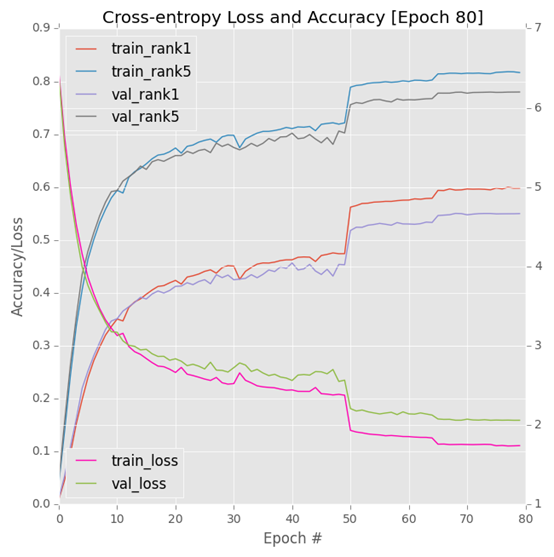
I trained SqueezeNet on a DSVM GPU instance with an NVIDIA K80 GPU. Each epoch was taking ~140 minutes. I allowed the network to train for a total of 80 epochs, which was ~1 week on a single GPU. Using multiple K80 GPUs can easily reduce training time to 1-3 days depending on the number of GPUs utilized.
After I ran the initial K80 test, Microsoft graciously allowed me to re-run the experiment on their recently released NVIDIA V100 GPU instances on Azure.
I was blown away by the performance.
Compared to the K80 (140 minutes per epoch), the V100 was completing a single epoch in only 28 minutes, a reduction in training time of 80%! SGD was used to train the network with an initial learning rate of 1e-2 (I found the Iandola et al. recommendation of 4e-2 to be far too large for stable training). Learning rates were lowered by an order of magnitude at epochs 50, 65, and 75, respectively.
Evaluating SqueezeNet
The final step was to evaluate SqueezeNet on my testing set:
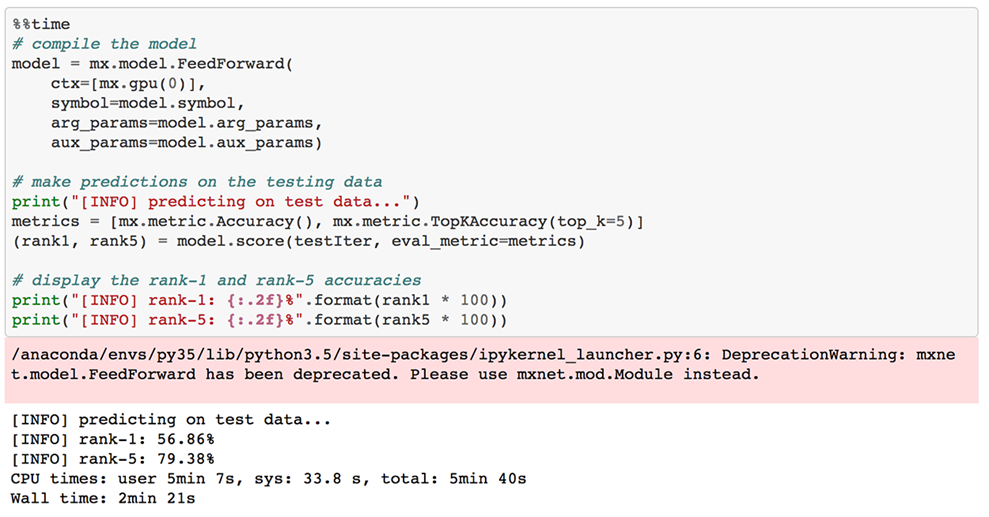


Overall, I obtained 56.86% rank-1 and 79.38% rank-1 and rank-5 accuracy, respectively.
These results are consistent with the Iandola et al. results and comparable to AlexNet-level results as well.
While SqueezeNet does not obtain as high accuracy as DenseNet or ResNet networks on the ILSVRC challenge, it does have a significantly lower model footprint, making it easier to deploy and utilize on network/resource constrained devices such as mobile devices, self-driving cars, etc.
You can find my SqueezeNet implementation, testing script, and model file on the GitHub page associated with this post.
Conclusion
In this post I discussed how the Microsoft Data Science Virtual Machine can be used to train state-of-the-art neural networks on large (1.2+ million) image datasets. To evaluate this claim, I implemented the SqueezeNet architecture by Iandola et al. using the MXNet library and then trained it on the ImageNet dataset.
Compared to my local Titan X GPU (~146.05 minutes per epoch, on average using a single GPU) the Tesla K80 averaged ~145.01 minutes per epoch.
The V100 blew both out of the water, reducing training time by 80% (28-minute epochs).
By adding additional GPUs to your Ubuntu DSVM, you could obtain a quasi-linear speedup in training as well. In general, I enjoy working with cloud-based deep learning solutions when they are done correctly – Microsoft's Ubuntu DSVM is one of them. Being able to create a base instance, work with it, break it (either accidentally or on purpose), shut it down, and boot up a new one within a few minutes is a huge timesaver and productivity boost for any deep learning practitioner or team. If you're working with large datasets and do not want to handle physical hardware (due to lack of space, excess heat, cost of cooling, noise, etc.), I would highly encourage you to try the Ubuntu DSVM.
You can learn more about the DSVM and spin up your first instance by clicking here.
If you're interested in other articles I have written here at the Microsoft Machine Learning blog, you can find them below:
- Deep Learning & Computer Vision in the Microsoft Azure Cloud
- 22 Minutes to 2nd Place in a Kaggle Competition, with Deep Learning & Azure
And finally, if you're interested in replicating the results of state-of-the-art deep learning publications, be sure to take a look at my book and self-study program, Deep Learning for Computer Vision with Python — I've personally gone through each and every code example to ensure it works out of the box on the Ubuntu DSVM.
Adrian
Twitter: @PyImageSearch | LinkedIn: Adrian Rosebrock