Server Side Speech Recognition
Last week I learned something, well I learned many things but one that was particularly interesting. Lets say you wanted to do server side speech recognition but you don't want the transport to be SIP. This obviously eliminates using UCMA 2.0 as by default it will rely on OCS and therefore SIP. Well I learned that this isn't entirely true, you can actually use the Microsoft.Speech assembly that comes with the UCMA 2.0 SDK outside a UCMA application. This has been staring me in the face and it didn't ever cross my mind to do it.
What kind of scenario does this open? One example improved desktop experience. Well SAPI is the obvious first choice when creating a desktop application, but the SAPI experience is really dependant on the OS. IE: TTS voices are different from XP to Vista. The benefit to having a server side solution you can control the experience of the end user has.
While looking to build something there are some problems to overcome, for me building a simple sample solution, two main problems stick out.
1.) Streaming Audio - I don't really want to pass around and process WAV files. You could but the experience wouldn't be as nice as you couldn't do immediate speech recognition.
2.) As I won't be using System.Speech or SAPI, I am going to have to access hardware resources such as the microphone and speakers.
For streaming audio there are alot of different options, but being a big fan of WCF, this is first avenue I looked at and sure enough you can stream content to/from WCF. Is there anything WCF can't do!
https://msdn.microsoft.com/en-us/library/ms731913.aspx
Next access microphone and speakers via .NET, I don't want to write low level code I want something down and dirty. I found a very cool CodePlex project, NAudio. It abstracts a lot of the audio APIs into a single, easy to use API. This will work perfectly for my client side application.
https://www.codeplex.com/naudio
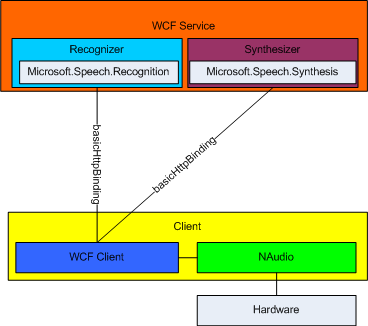
Here is a simple diagram of what I am building, and actually very close to having something running.
Note: If this was something which I was planning to actually put in a production environment, I'd separate the Synthesizer and Recognizer. These will be independent calls and would benefit from being on their own servers.
Code Sample will be available soon, hoping to have it up on MSDN samples by November 16th.
Comments
- Anonymous
November 25, 2014
So the code sample never was ready?