Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
As our group’s file systems expert, I see most of the common problems associated with the use/misuse of NTFS compression. Before you check the “Compress contents to save disk space” checkbox, it might be good to understand how this affects the happy little bits, bytes, & nibbles running around on the disk.
Often backup applications receive ERROR_DISK_FULL errors attempting to back up compressed files and this causes quite a bit of confusion when there are still several gigabytes of free space on the drive. Other issues may also occur when copying compressed files. The goal of this blog is to give the reader a more thorough understanding of what really happens when you compress NTFS files.
Compression Units…
NTFS uses a parameter called the “compression unit” to define the granularity and alignment of compressed byte ranges within a data stream. The size of the compression unit is based entirely on NTFS cluster size (refer to the table below for details). In the descriptions below, the abbreviation "CU" is used to describe a Compression Unit and/or its size.
The default size of the CU is 16 clusters, although the actual size of the CU really depends on the cluster size of the disk. Below is a chart showing the CU sizes that correspond to each of the valid NTFS cluster sizes.
| Cluster Size | Compression Unit | Compression Unit (hex bytes) |
| 512 Bytes | 8 KB | 0x2000 |
| 1 KB | 16 KB | 0x4000 |
| 2 KB | 32 KB | 0x8000 |
| 4 KB | 64 KB | 0x10000 |
| 8 KB | 64 KB | 0x10000 |
| 16 KB | 64 KB | 0x10000 |
| 32 KB | 64 KB | 0x10000 |
| 64 KB | 64 KB | 0x10000 |
Native NTFS compression does not function on volumes where the cluster size is greater than 4KB, but sparse file compression can still be used.
NTFS Sparse Files…
The Sparse Files features of NTFS allow applications to create very large files consisting mostly of zeroed ranges without actually allocating LCNs (logical clusters) for the zeroed ranges.
For the code-heads in the audience, this can be done by calling DeviceIoControl with the FSCTL_SET_SPARSE IO control code as shown below.
BOOL SetSparse(HANDLE hFile)
{
DWORD Bytes;
return DeviceIoControl(hFile, FSCTL_SET_SPARSE, NULL, 0, NULL, 0, &Bytes, NULL);
}
To specify a zeroed range, your application must then call the DeviceIoControl with the FSCTL_SET_ZERO_DATA IO control code.
BOOL ZeroRange(HANDLE hFile, LARGE_INTEGER RangeStart, LONGLONG RangeLength)
{
FILE_ZERO_DATA_INFORMATION FileZeroData;
DWORD Bytes;
FileZeroData.FileOffset.QuadPart = RangeStart.QuadPart;
FileZeroData.BeyondFinalZero.QuadPart = RangeStart.QuadPart + RangeLength + 1;
return DeviceIoControl( hFile,
FSCTL_SET_ZERO_DATA,
&FileZeroData,
sizeof(FILE_ZERO_DATA_INFORMATION),
NULL,
0,
&Bytes,
NULL);
}
Because sparse files don't actually allocate space for zeroed ranges, a sparse file can be larger than the parent volume. To do this, NTFS creates a placeholder VCN (virtual cluster number) range with no logical clusters mapped to them.
Any attempt to access a “sparsed” range would result in NTFS returning a buffer full of zeroes. Accessing an allocated range would result in a normal read of the allocated range. When data is written to a sparse file, an allocated range is created which is exactly aligned with the compression unit boundaries containing the byte(s) written. Refer to the example below. If a single byte write occurs for virtual cluster number VCN 0x3a, then all of Compression Unit 3 (VCN 0x30 - 0x3f) would become an allocated LCN (logical cluster number) range. The allocated LCN range would be filled with zeroes and the single byte would be written to the appropriate byte offset within the target LCN.
[...] - ALLOCATED
(,,,) - Compressed
{ } - Sparse (or free) range
/ 00000000000000000000000000000000000000000000000000000000000000000000000000000000
VCN 00000000000000001111111111111111222222222222222233333333333333334444444444444444
\ 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef
CU0 CU1 CU2 CU3 CU4
|++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++|
{ }[..............]{ }
Extents {
VCN = 0x0 LEN = 0x30 CU0 - CU2
VCN = 0x30 LEN = 0x10: LCN = 0x2a21f CU3
VCN = 0x10 LEN = 0x10 CU4
}
Below is a screen shot of a 2GB file that was created using the sparse file API’s.
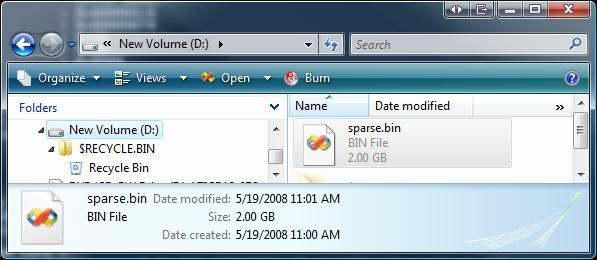
Notice that this volume is only 76.9 MB, yet it has a 2 GB file in the root folder.
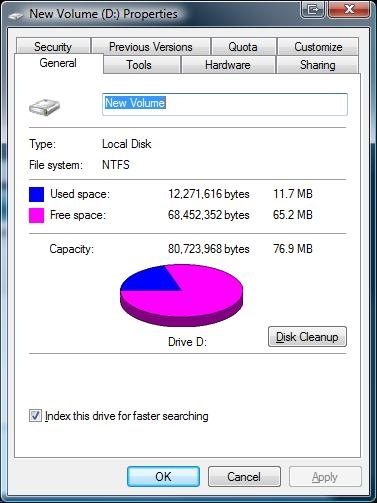
If we attempt to duplicate this sparse file with the COPY command, it fails. This is because COPY doesn’t know how to duplicate the sparse attributes on the file, so it attempts to create a real 2GB file in the root of D:. This can occur in production when attempting to move a large database file from one volume to another. If you have a database application that uses sparse attributes, then it is a good practice to use the database software’s backup / restore features when moving the database to a different volume.
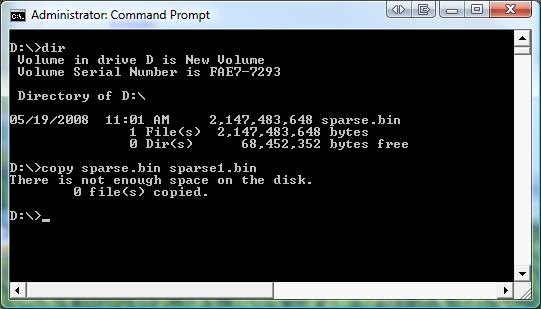
Now let’s look at the file’s properties with the COMPACT utility. Notice that the file shows up as compressed, and it has a huge compression ratio.
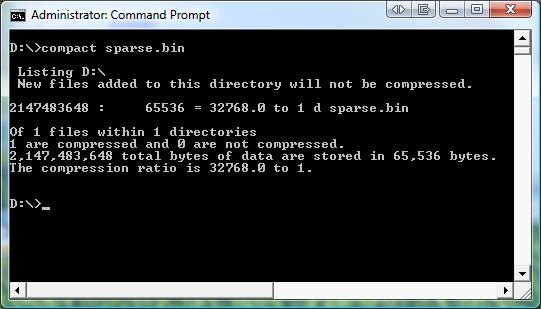
If you go back and look at the file properties from EXPLORER, you will notice that there is no compression checkbox (or any other indication that the file is compressed). This is because the shell does not check for the sparse bit on the file.
In short, use caution when moving sparse files from one location to another. Applications tell the file system the offsets of zeroed ranges, so you should always leave the management of sparse files to the application that created them. Moving or copying the sparse files manually may cause unexpected results.
NTFS Compression…
Now that we have discussed sparse files, we will move on to conventional NTFS compression.
NTFS compresses files by dividing the data stream into CU’s (this is similar to how sparse files work). When the stream contents are created or changed, each CU in the data stream is compressed individually. If the compression results in a reduction by one or more clusters, the compressed unit will be written to disk in its compressed format. Then a sparse VCN range is tacked to the end of the compressed VCN range for alignment purposes (as shown in the example below). If the data does not compress enough to reduce the size by one cluster, then the entire CU is written to disk in its uncompressed form.
This design makes random access very fast since only one CU needs to be decompressed in order to access any single VCN in the file. Unfortunately, large sequential access will be relatively slower since decompression of many CU’s is required to do sequential operations (such as backups).
In the example below, the compressed file consists of six sets of mapping pairs (encoded file extents). Three allocated ranges co-exist with three sparse ranges. The purpose of the sparse ranges is to maintain VCN alignment on compression unit boundaries. This prevents NTFS from having to decompress the entire file if a user wants to read a small byte range within the file. The first compression unit (CU0) is compressed by 12.5% (which makes the allocated range smaller by 2 VCNs). An additional free VCN range is added to the file extents to act as a placeholder for the freed LCNs at the tail of the CU. The second allocated compression unit (CU1) is similar to the first except that the CU compressed by roughly 50%.
NTFS was unable to compress CU2 and CU3, but part of CU4 was compressible by 69%. For this reason, CU2 & CU3 are left uncompressed while CU4 is compressed from VCNs 0x40 to 0x44. Thus, CU2, CU3, and CU4 are a single run, but the run contains a mixture of compressed & uncompressed VCNs.
NOTE: Each set of brackets represents a contiguous run of allocated or free space. One set of NTFS mapping pairs describes each set of brackets.
[...] - ALLOCATED
(,,,) - Compressed
{ } - Sparse (or free) range
/ 00000000000000000000000000000000000000000000000000000000000000000000000000000000
VCN 00000000000000001111111111111111222222222222222233333333333333334444444444444444
\ 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef
CU0 CU1 CU2 CU3 CU4
|++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++|
(,,,,,,,,,,,,){}(,,,,,,){ }[...............................,,,,){ }
Extents {
VCN = 0x0 LEN = 0xe : LCN = 0x29e32d CU0
VCN = 0xe LEN = 0x2 CU0
VCN = 0x10 LEN = 0x8 : LCN = 0x2a291f CU1
VCN = 0x18 LEN = 0x8 CU1
VCN = 0x20 LEN = 0x25 : LCN = 0x39dd49 CU2 - CU4
VCN = 0x45 LEN = 0xb CU4
}
Now we come to the part where we describe limitations of this design. Below are some examples of what happens when things go wrong while reading / writing compressed files.
Disk full error during a backup read operation or file copy…
- NTFS determines which compression unit is being accessed.
- The compression unit’s entire allocated range is read.
- If the unit is not compressed, then we skip to step 5. Otherwise, NTFS would attempt to reserve (but not allocate) the space required to write the decompressed CU back to disk. If insufficient free space exists on the disk, then the application might get an ERROR_DISK_FULL during the read.
- The CU would be decompressed in memory.
- The decompressed byte range would be mapped into cache and returned to the requesting application.
- If part of the CU is altered in cache…
- The reserved disk space from step 3 would become allocated space.
- The CU contents would be compressed and flushed back to the newly allocated region (the LCN location will usually not change).
- Any recoverable disk space within the CU would be freed.
Failure to copy a large file to a compressed folder…
This is the most common problem seen with compression, and currently the solution is to educate users about limitations. NTFS compression creates approximately one file fragment for every 16 clusters of data. Because the max cluster size allowed for standard compression is 4K, the largest compression unit allowed is 64KB. In order to compress a 100 GB file into 64KB sections, you could potentially end up with 1,638,400 fragments. Encoding 1,638,400 fragments becomes problematic for the file system and can cause a failure to create the compressed file. On Vista and later, the file copy will fail with STATUS_FILE_SYSTEM_LIMITATION. On earlier releases, the status code would be STATUS_INSUFFICIENT_RESOURCES. If possible, avoid using compression on files that are large, or critical to system performance.
I received feedback from the NTFS Principal Development Lead about this blog. Fortunately, most of the feedback was good, but he asked that I add a maximum size recommendation. According to our development team’s research, 50-60 GB is a “reasonable size” for a compressed file on a volume with a 4KB cluster size. This “reasonable size” goes down sharply for volumes with smaller cluster sizes.
Compressing .VHD (Virtual Hard Disk) files causes slow virtual machine performance…
A popular hammer company received a call from a customer complaining “It sure hurts when I hit my thumb with your hammers!” Likewise, if you compress .VHD files, it is going to be a painful experience, so please compress responsibly.
Best Regards,
Dennis Middleton “The NTFS Doctor”
Comments
Anonymous
July 07, 2008
The comment has been removedAnonymous
August 30, 2008
So suppose I am writing a file to disk (or modify data from a "CU") -- at what point does NT try to recompress the the data to try to save space? Each time the data would be written from a "CU"-size multiple from memory to the physical disk? [That is absolutely correct.]Anonymous
March 07, 2009
The comment has been removedAnonymous
September 02, 2012
The comment has been removedAnonymous
October 21, 2012
The comment has been removed