DNS Intrusion Detection in Office 365
In Office 365, we are committed to protecting our customer's data. We implement and exercise industry leading security practices to ensure that customer's data is safe. Intrusion detection is one such security practice which ensures that we are notified about any anomalous activity or behavior on our servers or in our network. We monitor and investigate notifications from our intrusion detection system for signs of adversary activities against our service, with the goal to prevent the adversary from gaining unauthorized access to customer data.
The Domain Name System, or DNS, is used in computer networks to translate domain names to IP addresses which are used by computers to communicate with each other. DNS exists in almost every computer network; it communicates with external networks and is extremely difficult to lock down since it was designed to be an open protocol. An adversary may find that DNS is an attractive mechanism for performing malicious activities like network reconnaissance, malware downloads, or communication with their command and control servers, or data transfers out of a network. Consequently, it is critical that we monitor our network for these activities to protect our customer's data.
This post discusses adversary techniques that abuse the DNS protocol to gain unauthorized access in computer networks and monitoring strategies for detecting such techniques.
What to Detect
Adversary and penetration-test tools may abuse DNS using techniques in the table below to achieve the following goals.
- Network footprinting
An adversary may attempt to obtain information about a target network by misusing DNS. Specific techniques involving DNS (see table below) may be used to learn about domain names, computer names and IP addresses in a target network. This information can be used to build a footprint or graph of the network.
- Credential theft
An adversary may create a malicious domain name that resembles a legitimate domain name and use it in phishing campaigns to steal credentials.
- Malware installation
An adversary may attempt to install malware on computers in a target network by directing requests to malicious domains or IP addresses. This may be done by hijacking DNS queries and responding with malicious IP addresses. The goal of malware installation can also be achieved by directing requests to phishing domains.
- Command and Control (C2) communication
If an adversary manages to gain foothold inside a target network, he or she may abuse DNS to communicate with a C2 server. This typically involves making periodic DNS queries from a computer in the target network for a domain controlled by the adversary. The responses contain encoded messages that may be used to perform unauthorized actions in the target network.
- Data theft
Like C2 communication, an adversary may abuse DNS to transfer data from a computer in a target network to a C2 server. This may be performed by tunneling other protocols like FTP, SSH through DNS queries and responses. This typically involves making multiple DNS queries from a compromised computer to a domain owned by the adversary. DNS tunneling can also be used for executing commands and transferring malware into the target network.
- Evading detection
An adversary may use advanced techniques to evade detection of the malicious DNS traffic and make it hard for defenders to learn about the malicious domain or nameserver.
See the references section for links to posts that discuss some of these above topics in greater detail.
This tables summarizes the goals, techniques and DNS activity generated from the techniques.
| Adversary Goals | Adversary Techniques | DNS Activity (Indicators) |
|---|---|---|
| Network foot printing |
|
|
| Credential theft, Malware installation |
|
|
| Command and control (C2) communication |
|
|
| Malware installation, Data theft |
|
|
| Evading detection |
|
|
The indicators listed in the above table helped us create the list of detections for the adversary techniques. Here is the summarized list of detections.
- Detect anomalous DNS query types and volume
- Detect DNS traffic from anomalous processes or to anomalous DNS servers
- Detect anomalous volume of failed DNS queries
- Detect anomalous distinct IP address resolved for a domain
- Detect phishing domains, domains with high entropy and random words
- Detect anomalous entries in DNS hosts file
- Detect cache poisoning via DNS responses
- Detect DNS beaconing to anomalous domains
- Detect long and random labels in subdomains and large subdomain count
- Detect esoteric domains i.e. domains that only some of our servers are resolving
How to Detect
We analyzed the flow of DNS traffic in our service and observed that there was no single spot in the service where we could monitor and achieve all our goals of detecting malicious activity, reporting actionable information and monitoring reliably and in a highly performant manner.
To overcome this, we designed a solution that incorporates three monitoring strategies. Each strategy captures essential and unique details about DNS traffic in our network. The strategies also have some overlap so that all the details can be pieced together to create an end to end picture of the activity.
We use host based monitoring via Windows ETW data for each of these strategies. The post Hidden Treasure: Intrusion Detection with ETW discusses the details of using Windows ETW for security monitoring.
Monitoring Strategies
Let's dive into the monitoring strategies that we have implemented.
- Monitor DNS resolutions on every endpoint
In this strategy, we collect every DNS resolution performed by the standard DNS resolver on each endpoint (or DNS client). The data is obtained from the Microsoft-Windows-DNS-Client ETW trace.
- Monitor Netflow (IP) traffic to outbound DNS port 53
In this strategy, we collect Netflow data for outbound port 53 from every server. Our Netflow data is aggregated network metadata from packet headers (IP Address, domain, port, protocol, bytes and process). The data is obtained from the Microsoft-Windows-Kernel-Network ETW trace.
- Monitor DNS data on internal DNS servers (Dnsflow)
In this strategy, we aggregate and collect data from DNS queries and responses flowing through the DNS servers in our network. We call this Dnsflow monitoring. Some of the information collected is aggregated query count, query types, query and response bytes, subdomains, client and nameserver IP addresses. The data is obtained from the Microsoft-Windows-DnsServer ETW trace.
Here is a summary of the pros and cons of each of the monitoring strategies.
| Monitoring Strategy | Pros | Cons |
|---|---|---|
| Monitor DNS resolutions on every endpoint |
|
|
| Monitor Netflow (IP) traffic to outbound DNS port 53 |
|
|
| Monitor DNS resolutions on service's internal DNS servers (Dnsflow) |
|
|
Performance and Reliability
Since each strategy involves host based monitoring, it is critical that the data collection, handling and logging is highly performant. We achieve this by filtering, aggregating where data volume is high, and closely monitoring the resource usage on an ongoing basis. We also detect significant changes to the data volumes handled which can affect resource utilization of our monitoring pipeline.
The overlap across monitoring strategies ensures that there aren’t any blind spots in our monitoring. Also, the overlap across the strategies adds redundancy and increases the resiliency of the overall solution to monitoring failures on a few servers.
How to Make Results Actionable
We have implemented DNS detections so that the anomaly reports include actionable information like the user name, process name, computer name, anomalous domain name and nameserver IP address involved in the anomalous activity. This helps us make the most informed decision about the anomaly.
Here’s an overview of how we do this.
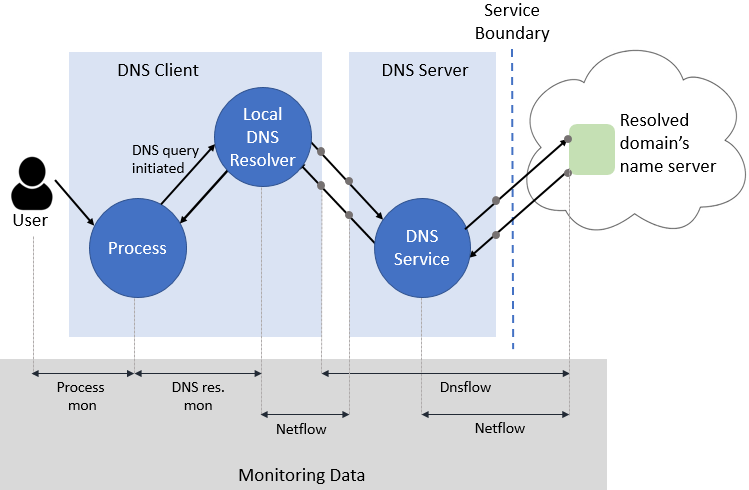
The above picture shows the flow of DNS through our network and the monitoring data related to the activity. The monitoring data is collected on the endpoints and processed so that detections can consume the data from all the monitoring modules (Netflow, Dnsflow, etc.).
When we detect DNS anomalies, we work to get all the entities related to the activity – from the user to the nameserver IP address. The above picture shows how the monitoring data contains information about the entities. Here is the relevant information from each monitoring module.
- Process monitoring (details of this not discussed in this post) – user, process
- DNS resolution monitoring – DNS query and response, process
- Netflow monitoring – process, remote IP address and port, count of bytes transferred
- Dnsflow monitoring – DNS query and response, client and nameserver IP address
We join the intermediate results from each anomaly detection with the above data to create a more complete picture about DNS anomalies. Furthermore, our triage pipeline clusters the DNS detection results with results from other detections. The clustering approach is discussed in the post Defending Office 365 with Graph Analytics. This helps us reason about the DNS anomaly in context of other anomalies related to a machine or a domain.
The above methodology leaves us with very few results that need detailed investigation and helps us clearly identify red team activities. We are using the DNS monitoring data not only to detect DNS anomalies but also to add context to results of existing anomaly detections.
References
- Security Information for DNS
- Detecting DNS Tunneling
- Maliciously Abusing Implementation Flaws in DNS
- That’ll never work–we don’t allow port 53 out
- Know Your Enemy: Fast-Flux Service Networks
- DNS Hacking (Beginner to Advanced)
Comments
- Anonymous
April 19, 2017
Good afternoon,Really useful blog. Please note that the table on detection methods is currently unfinished and instead repeats the previous table.- Anonymous
April 19, 2017
Thanks Andy! It's fixed now.
- Anonymous