Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
I have been answering questions on two of the most misunderstood ‘SQL Server Urban Legends’ frequently again so I decided to make a post about them.
· SQL Server Uses One Thread Per Data File
· A Disk Queue Length greater than 2 indicates an I/O bottleneck
SQL Server Uses One Thread Per Data File
The Legend grew from the following SQL Server behavior - “When SQL Server is creating a database file (.mdf, .ndf, .ldf) it writes zero’s to all bytes in the file and stamps the appropriate allocation structures. SQL Server can use a thread per file when creating a database.” This is a true statement but leaves room for interpretation so allow me to clarify with the following examples.
The true behavior is that for each UNIQUE disk drive specified a thread is used to initialize the database files. The number of threads is capped by a reasonable pool limit around one half of the total worker thread limit.
create database …. name = c:\MyFile1.mdf, name=c:\MyFile1.ndf
The SQL Server would use a single worker to create this database initializing MyFile1.mdf and then MyFile2.ndf.
create database …. name = c:\MyFile1.mdf, name=D:\MyFile1.ndf
The SQL Server would use two workers to create this database one thread initializing MyFile1.mdf and the other MyFile2.ndf because different drives have been specified. SQL Server makes the assumption that different drives have the possibility of unique I/O paths.
This information has been taken out of context and propagated incorrectly as SQL Server has a thread per database file so adding more files to a database can increase I/O performance. Adding more files and properly aligning them with storage can increase the I/O performance for a variety of reasons but achieving new I/O threads per file is NOT one of them. SQL Server I/O is all about I/O response time. You can have a variety of I/O configurations as long as the response times are acceptable.
The SQL Server 2005 – Instant File Initialization – feature significantly reduces the impact of database creation because zero’s don’t have to be stamped in all bytes of a database file, only the log files. This reduces the gain from using multiple threads during database creation.
SQL Server 2005 and Newer
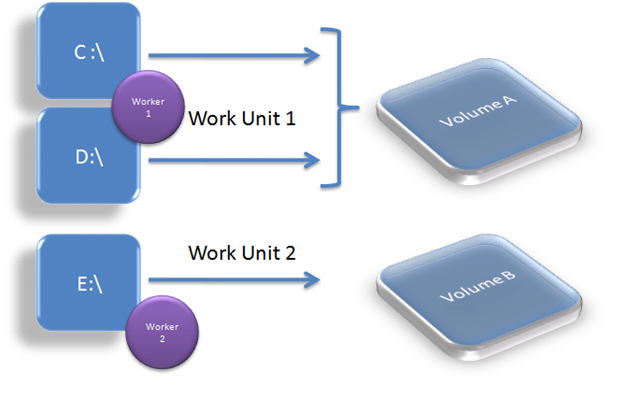
Actions such as create and drop database assign a work unit number based on the volume identity. This means each file specified in the create/drop database statement gets assigned a work unit number.
The APIs GetVolumePathName and GetVolumeNameForMountPoint are used to obtain the identity of the volume. Only when these APIs return an error do we revert to the drive identifier behavior, making the assumption that different drive letters are associated with unique volumes. A background worker is created to handle each unique work unit.
The following illustration the drives C and D are using Volume A and E used Volume B. C and D will be assigned to Work Unit 1 and processed by Worker 1 while E will be assigned to Work Unit 2 and be processed by Worker 2.
The Truth
SQL Server uses asynchronous I/O allowing any worker to issue an I/O requests regardless of the number and size of the database files or what scheduler is involved. In fact, some may remember SQL Server 6.5 and previous versions had the sp_configure option ‘max async I/O’ that was commonly set to 255 and was removed when SQL Server 7.0 released.
SQL Server controls the async I/O depth with a set of FCBIoRequest structures. These structures hold the I/O request information, including the OVERLAPPED structure. There is a single pool of these structures for the entire instance of SQL Server. For SQL Server 6.5 the maximum number of these structures was controlled with the configuration option.
Starting with SQL Server 7.0 the number of these structures is only limited by available memory. It is actually a bit more complicated than just can a new FCBIoRequest be allocated. SQL Server has basic throttles for lazy writer, checkpoint, read ahead and other activities. This means that the practical limit is ((# of workers) * (action practical limit)). For example, the practical limit for checkpoint is generically no more than 100 outstanding I/O requests a any point in time and less if the target response time is not being honored.
Tempdb
The immediate question I get is – “What about all the KB articles on tempdb, a file for scheduler and such?” This is again a misinterpretation of the legend as tempdb tuning is all about the allocation activity, not a number of threads per file (no such thing). Workers use tempdb like any other database, any worker can issue I/O to and from tempdb as needed.
Tempdb is the database with the highest level of create and drop actions and under high stress the allocation pages, syscolumns and sysobjects can become bottlenecks. SQL Server 2005 reduces contention with the ‘cached temp table’ feature and allocation contention skip ahead actions.
When multiple workers are attempting to create or drop objects in tempdb you can decrease the bottleneck by having
· As many files in tempdb as schedulers
· All files sizes are equal
· Uniform allocations enabled (-T1118)
By configuring in this way each new allocation occurs in round-robin fashion across the files and only on uniform extents. SQL Server only allows a single worker to be active on each scheduler at any point in time so if every ‘running’ worker is attempting tempdb allocations they will logically partition to a separate file in tempdb, reducing the allocation contentions.
I/O Affinity
I/O affinity is the ability to dedicate a scheduler to the processing of I/O requests. This muddied the water as you can imagine adding to the legend.
I/O affinity does not understand database or database specifics. It is only a queuing mechanism for issuing and completing I/O. A worker determines it needs to perform an I/O and does all the basic work. The I/O affinity hook is just before the worker issues the actual ReadFile or WriteFile call. Instead of issuing the I/O the worker puts the I/O request on a queue. The queue is serviced by the dedicated scheduler instead.
A Disk Queue Length greater than 2 indicates an I/O bottleneck
A statement was published many years ago that sustained disk queue length greater than 2 is an indication of an I/O bottleneck. This statement is still true if the application is not designed to handle the situation. SQL Server is designed to push disk queue lengths above 2 when it is appropriate.
SQL Server uses async I/O to help maximize resource usage. SQL Server understands that it can hand off an I/O request to the I/O subsystem and continue with other activity. Let’s look an example of this.
SQL Server checkpoint posts up to 100 I/O requests and monitors the I/O response time in order to properly throttle checkpoint impact. When the I/O response time exceeds the target the number of I/Os is throttled. The disk queue length can easily exceed 2 and not be an indication of a subsystem problem. SQL Server is attempting to maximize the I/O channel.
SQL Server does read ahead or tempdb spooling actions. The workers seldom directly wait for the I/O to complete. Instead the workers continue on with other actives taking advantage of CPU processing power instead of waiting for the I/O response. You would not want SQL Server to read a page, add it to a sort, and write the sort page during a large sort. Instead SQL Server will post the sort I/O in motion and return to the next read page and continue sorting. The sort operations track the outstanding I/Os and check completion status at later intervals.
The next time someone looks at the disk counters on the system and states the disk queue length is above 2 and this is a problem take a minute to look at other data points. The key for SQL Server is the I/O response times. Start by looking at the Average Disk Seconds Per Transfer for the same I/O path. Then look at the SQL Server sysprocesses and waitstats for buffer based I/O wait information. You want to see evidence from SQL Server that the disk queue length is related to an I/O bottleneck. Don’t just take the depth of 2 at face value.
- Bob Dorr
June 6, 2007 - Additional Content and Clarrification
Thought it appropriate to add an email chain I had with our developers as a supplement to this blog entry as I think it helps clarify a few more things.
The question was:
Subject: RE: Splitting Data across datafiles
I know from experience that restoring a database into multiple files is substantially faster than into one big one. Kalen’s statement seems contradictory to yours.
From Inside SQL Server 2000 (Kalen Delaney):
Why Use Multiple Files?
You might wonder what the reason would be for creating a database on multiple files located on one physical drive. There’s no performance benefit in doing so, but it gives you added flexibility in two important ways.
From: Robert Dorr
Subject: RE: Splitting Data across data files
When I say the ‘variety of reasons’ one example would be that more than one file could be aligned with different I/O paths so the I/O load can be serviced better by more than a single I/O path. My point was that it has nothing to do with the number of threads per database files (as SQL does not have this concept in mainline operations) but everything to do with I/O bandwidth as any worker can post a read or write to be serviced. SQL can drive a very heavy workload and the more you can reasonably split up the work load to keep the I/O path from becoming saturated the better.
There are other things that come into play here as well. For example partitioned view plans are currently generated to target different partitions with secondary workers when the plan is run in parallel. So again, separating the I/O path to a reasonable degree has the possibility of increasing performance. Again, the I/O bandwidth is the key to the performance.
The statement from Kalen is correct and does not conflict with mine but is complementary. When we create a database we assign a worker per drive to create the database. So database creation won’t be any faster if you create 2 files on the same drive vs a single larger file on the drive. If you create 2 files on different drives then 2 workers do the creation so the database may be created faster due to parallel work streams. Her flexibility statements are valid.
Note: Much of zeroing activity during database, data file creation can be mitigated with the SQL Server 2005 Instant File Initialization feature.
Microsoft has seen that tempdb is an exception to the common rules here. Tempdb can be a high contention point for internal tracking structures. It is often better to create multiple files for tempdb so the internal latching and other activities achieve better separation (per file) so all the workers don’t cause a resource contention on a single tempdb file. This type of contention would be extremely rare to see on a user database and I have not seen that issue in a user database.
Restore and Backup are a bit different than common database I/O operations. Specifically, each ‘stripe’ of the backup can receive its own worker to perform the I/O operations. So if I issue “backup database XYZ to disk = ‘c:\temp\file1.bak’, disk = ‘c:\temp\file1.bak’ “ 2 workers are used, one assigned to each output location. The design is such so that we can optimize serial file streaming and support tape mechanisms as well. The I/O from the database is still done async. Let me elaborate a bit more.
This is a simplified view but I think it helps. When backup starts it determines the size and number of backup I/O buffers. These buffers are placed on a free list. It then creates the output workers which wait on the used list. The main worker (the one handling the T-SQL backup command) pulls buffers from the free list and starts issuing reads on the database. As the reads complete the buffers are placed in the used list. The buffers are pulled from the used list, written to the backup media and placed back on the free list. This list exchange continues until the backup is complete.
Restore is basically the reverse of the Backup logic. The one difference with restore is that it could have to create/zero init the database files and we are back to “is it faster to create a single file or multiple files?” To tell you the true I had not studied how we create the database files during a restore so I broke out the debugger and I have outlined the high level details below.
· Each file is created/opened by the original T-SQL command worker, one file after the other in a loop. This is lightweight because it is just a CreateFile call (open the file). The real work occurs when the zero’ing of the actual contents takes place.
· For each file that needs zero initialized (log files, data files with variance in size on disk from the backup media, new files, ….) we don’t do the same logic as we do for create database and use a worker per drive. We can use a worker per file. This may be why restore to a single file vs multiple files (adding up to the same size) on the same drive show performance differences.
· The main T-SQL command worker than loops over all the files and makes sure the allocation pages are properly stamped.
· Then the restore activity takes place using workers and the lists as previously described.
So if the I/O path is sufficient I would be hard pressed to say anything but what Kalen states in terms of common database I/O performance that multiple files should not generically improve performance. As you state and I found it may matter when doing a restore as multiple workers may be able to use available bandwidth better to zero the contents of database files.
- Bob Dorr
Comments
Anonymous
February 21, 2007
Bob, When you say "unique disk drive", what does this mean for mountpoints? And a second question, when you talk about NUMA there is 1 I/O thread per NUMA node. Do I understand correctly when I say that the "real" I/O in SQL Server is done by a single thread (or as many as there are NUMA nodes) while the workers just post async I/O requests for this thread to handle? Kind regards, Wesley BackelantAnonymous
February 26, 2007
The unique disk disk logic that I have looked at in the code was the drive letter. I have not looked at mount point logic. I assume a unique mount point would work like a unique disk letter. For NUMA the IO works the same as non-NUMA installations. Each worker will issue its own I/O. What you are thinking of is that each node has a lazy writer thread to monitor and handle LW activity for the node. When checkpoint executes it assigns the I/Os to the LW associated with the NUMA node.Anonymous
March 01, 2007
Thanks for the explanation. I'm a bit confused because the documentation states the I/O thread and the lazy writer thread separately. "The benefits of soft-NUMA include reducing I/O and lazy writer bottlenecks on computers with many CPUs and no hardware NUMA. There is a single I/O thread and a single lazy writer thread for each NUMA node."Anonymous
April 23, 2007
Bob, Another article that speaks about one thread per file is this: http://www.microsoft.com/technet/prodtechnol/sql/70/reskit/part2/sqc01.mspx?mfr=true It says: "Whenever a data object (table) is accessed sequentially, a separate thread is created for each file in parallel. Therefore, a tablescan for a table that is assigned to a filegroup with four files uses four separate threads to read the data in parallel." [RDORR] This is part of the problem with the myth. It does not work this way. If you have a partitioned view it is possible that a worker could be assigned to each partition and you get something like this. Again, that would be no different than a parallel query using multiple workers to scan the data. They each post I/O request for the pages they need. No seperate threads are created.Anonymous
August 14, 2007
• For most user databases (this is explicitly not including TempDB) there is no performance advantage in multiple files or multiple file groups unless each file is on a separate IO path. The only exception would be the highly unusual case of a user database with many object drops and/or creates per second, which might benefit from multiple files. There can be a manageability benefit from multiple files/filegroups. • None of this changes just because with table partitioning you have each partition on a separate file group. (Yes, there are now multiple files, but it’s because of the partitioning, not directly as a performance gain).Anonymous
August 14, 2007
This statement in the below article is incorrect for user databases (though it is still true for tempdb). The real advantage of multiple files is managability and spreading files over multiple IO paths (controllers, LUNs, etc.). Physical Database Storage Design http://www.microsoft.com/technet/prodtechnol/sql/2005/physdbstor.mspx "The number of data files within a single filegroup should equal to the number of CPU cores."Anonymous
November 12, 2007
There has been much discussion on the usefulness of disk queue length as an indicator of a disk I/O bottleneck.Anonymous
November 15, 2007
If you attended SQLBits you may have seen my SQL Myths session. One of the myths I didn't cover was thatAnonymous
November 21, 2007
Published: June 5, 2007 Writer: Mike Ruthruff Contributors: Michael Thomassy, Prem Mehra Technical ReviewersAnonymous
December 15, 2007
Usualmente eu leio alguns blogs de SQL Server e certa vez eu me deparei com um artigo muito legal e detalhado,Anonymous
December 15, 2007
Usualmente eu leio alguns blogs de SQL Server e certa vez eu me deparei com um artigo muito legal e detalhado,Anonymous
December 15, 2007
Usualmente eu leio alguns blogs de SQL Server e certa vez eu me deparei com um artigo muito legal e detalhadoAnonymous
December 16, 2007
公開日 : 2007 年 6 月 5 日 執筆者 : Mike Ruthruff 執筆協力者 : Michael Thomassy、Prem Mehra テクニカル レビュー担当者 : Robert DorrAnonymous
January 14, 2008
The comment has been removedAnonymous
January 28, 2008
发布日期 : 2007 年 6 月 5 日 作者 : Mike Ruthruff 投稿人 : Michael Thomassy, Prem Mehra 技术评论家 : Robert Dorr, StuartAnonymous
February 13, 2008
In the prior post , we discussed the major causes for each type of fragmentation, which followed postsAnonymous
August 02, 2008
function showDiv(post, lingua) { if (document.getElementById) { // DOM3 = IE5, NS6 document.getElementById(postAnonymous
November 14, 2008
The comment has been removedAnonymous
July 27, 2011
The comment has been removed