Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
故障转移集群(Failover Cluster)是实现SQL Server高可用性解决方案之一。一个集群通常由多台服务器组成,每台服务器称为一个节点。通过使用冗余节点来减少宕机时间,为客户关键业务的高可用性提供了有力的保障。与以前版本相比,SQL Server 2008故障转移集群做了很大改进,不但简化了安装和维护,而且提供了新功能减少系统维护时的宕机时间,比如循环升级、循环打补丁等。本文将简述一下SQL Server 2008故障转移集群的基本结构和原理。
SQL Server 2008支持本地集群,即所有节点都在同一个子网内,通常位于同一个物理地点;如果节点跨越不同区域,则必须把所有的节点都配置到同一个VLAN中,所以在上层的集群看起来还是同一个子网内。一个典型的故障转移集群的架构如图1所示。
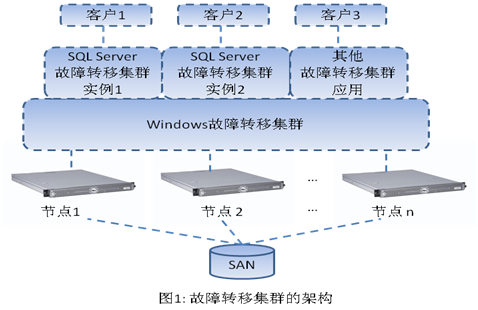
首先要指出的是,SQL Server故障转移集群有两个核心层次,一个是Windows层,一个是SQL Server层。Windows故障转移集群是一个平台,提供了与应用无关的故障转移的基本功能,比如节点之间心跳检测、故障转移策略管理等。在其上可以构建很多故障转移集群的具体应用,而SQL Server故障转移集群正是其中之一(其他故障转移集群的应用还有很多,比如邮件服务器、文件服务器、打印服务器等)。因此,安装SQL Server故障转移集群前,必须要先把所用的节点加入到同一个Windows故障转移集群中。向现有的集群中增加新节点也是如此。SQL Server 2008故障转移集群推荐安装在Windows Server 2008上,因为该版操作系统大大简化了Windows故障转移集群的管理维护。
和独立的SQL Server一样,SQL Server的故障转移集群也支持多实例。每一个SQL Server故障转移集群的实例都有一个虚拟的网络名字,客户通过该名字访问集群数据库就和访问一台物理的数据库服务器一样。所以虽然集群内部有很多节点,但客户是感觉不到的。正常运行时,只有一个节点上的SQL Server实例进程在运行,此节点称为活动节点(Active Node),而所有其他节点则称为被动节点(Passive Node)。集群的虚拟网络名字总是映射到当前活动节点的IP上。
和独立的SQL Server不同的是,SQL Server故障转移集群的数据不能存储在本地磁盘上,而必须存储在共享的SAN(Storage Area Network)上。实际上SAN是在Windows故障转移集群中配置,然后分配给SQL Server故障转移集群的实例使用的(在安装时指定)。通常SAN总是被当前的活动节点独占使用的,从而避免了多节点同时访问可能造成的数据损坏。
故障转移有两种形式,一种是由管理员发起的,一般是在对当前活动节点进行系统维护之前先把整个集群转移到其他节点上;另一种是系统检测到故障时自动进行的故障转移。故障转移过程如图2所示。Windows故障转移集群会首先停止当前活动节点上的SQL Server实例进程,然后根据该实例的故障转移策略选择一个新的节点,最后在此新节点上启动SQL Server的实例进程,同时获得对SAN的独占访问权。这个节点就成为了新的活动节点,虚拟网络名字也随之映射到此新节点上,从而保证客户应用还能正常连接数据库。由于数据都是存储在共享的SAN上的,在故障转移过程中并不需要数据复制。宕机时间只发生在故障转移时短暂的瞬间,即旧的活动节点的实例进程被停止后,到新的活动节点的实例进程正常工作之前。当然,故障转移之前的客户连接都会被中断,所有未完成的事务都会被回滚,并且故障转移完成之后,客户端需要重新连接数据库。

那么在系统自动触发的故障转移中,系统是如何检测故障及采取措施呢?这就需要探讨一下故障的检测和转移策略。
故障的种类多种多样。如前所述,Windows故障转移集群为集群应用提供了底层服务,与之对应,一些底层的故障,比如网络故障、磁盘故障等,也是由它来检测的。而每个SQL Server集群实例自身的故障(比如拒绝客户端连接、无响应等)则是由一个为SQL Server定制的集群资源来检测的,称为“SQL Server资源”,其任务就是定期去查询数据库的状态。具体来说有两种查询:一个是“LooksAlive”,另一个是“IsAlive”。前者是一个轻量查询,缺省配置下每5秒钟检查一下SQL Server服务的状态,并不去连接数据库,所以对数据库的影响很小,查询次数也比较多;而后者是要连接到数据库中去执行一下SQL语句“SELECT @@SERVERNAME”判断是否能返回正确的结果,对数据库的影响较大,尤其是系统繁忙时,所以只在每60秒钟,或者“LooksAlive”查询失败时才会去执行一次。
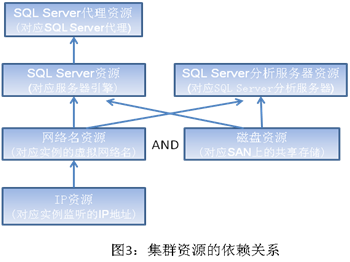
故障发生时,默认的转移策略就已经能满足很多用户的需求了。当然,用户还可以随时根据自己的特殊需求,用Windows集群管理器(Failover Cluster Manager)对集群实例内的每个资源单独配置不同的策略。同时,同一集群实例内的资源之间会通过特定的依赖关系(如图3所示)而互相影响。如果出故障资源变成“失败”状态从而导致其上层资源的依赖关系不能成立,则该上层资源也会变成“失败”状态;如果要转移到新节点,则同实例内部的所有其他资源都会跟着转移。
集群内部的状态信息都会同时记载到集群日志和Windows事件浏览器中,所以一旦集群发生了异常,总可以通过研究这些信息了解系统状态变化的全过程。
您可以参考以下链接获得Windows和SQL Server故障转移集群更详细的信息:
- Windows Server 2008 Failover Clustering
https://www.microsoft.com/Windowsserver2008/en/us/failover-clustering-main.aspx - SQL Server 2008 Failover Clustering
https://msdn.microsoft.com/en-us/library/ms189134.aspx
李凌伟
SQL Server引擎测试工程师