Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
マイクロソフトの植田です。
今回はDMV(Dynamic Management View: 動的管理ビュー)を利用したインデックスの管理に関する話題を紹介したいと思います。
https://blogs.msdn.com/sqlcat/archive/2005/12/12/502735.aspx
注:下記内容に関する詳細の確認をご希望される場合は上記のブログを参照いただけますようお願いします。
本ドキュメントは以下の方を対象としております。
l 開発者、テストエンジニア、データベース・アドミニストレータ
l データベース、および、Microsoft SQL Serverについて基本的な知識をお持ちの方
SQL Server 2005におけるインデックス有効性の評価、および、管理
質問:SQL Server 2005はどのようにインデックスの評価、および、管理を支援してくれるのでしょうか。
1. どうすれば作成したインデックスが有効であることがわかりますか?それらのインデックスはどのように使われているのでしょうか?
2. 使用されていないテーブルやインデックスが存在していないでしょうか?
3. インデックスのメリットに対するメンテナンス・コストはどの程度でしょうか?
4. インデックス競合やホットスポットは発生していないでしょうか?
5. インデックスを増やすことによって(または減らすことによって)効果を得ることができるでしょうか?
回答:
SQL Server 2005 の動的管理ビュー(Dynamic Management View: DMV)はサーバの状態変化に関する情報、典型的な例としては多数のセッション、多数のトランザクション、および、多数の要求に対する情報など、を知る上でとても重要です。DMVはSQL Server 2000では利用できなかったレベルの内部状態に関する情報を提供します。つまり、状態検知、メモリおよびプロセスのチューニング、そして監視のためにDMVを利用することができます。SQL ServerのエンジンはDMVの詳細なリソースの状態履歴を記録し、それらの情報は「SELECT」文で参照できます。ただし、それらの情報はディスクには書き込まれないため、DMVはSQL Serverを起動させた時から現在までの動作状態を示します。
インデックスはテーブル・スキャンに代わるデータ取得方法を提供します、そして、DMVにはインデックスの使用状態を示すカウンターがあるため、私たちはインデックスのコスト対メリットを比較することができます。この比較にはインデックスを最新の状態に保つためのメンテナンス・コスト対、インデックスを使用した場合に読み込みから得られるメリット(例:テーブル・スキャンの代わりにインデックス・スキャンが使用される)の比較が含まれます。「UPDATE」または「DELETE」処理には、読み込み処理、まずその行が更新の条件を満たすかどうかの問い合わせ処理、と書き込み処理、その行が条件を満たす場合に初めて行われる処理、が含まれることに気をつけてください。「INSERT」処理では書き込み処理だけが全てのインデックスにおいて行われます。結果的に、「INSERT」中心の負荷では、書き込み処理の方が読み込み処理よりも格段に多くなります。更新中心(「UPDATE」および「DELETE」)の負荷では、読み込み処理と書き込み処理は、「レコードが見つからない」ケースはそれほど多くないと考えると、一般的に近い数になります。また、読み込み中心の負荷では、読み込み処理数は書き込み処理数より格段に多くなります。外部キーなどの参照制約がある場合は参照一貫性が維持されることを確かめるために、追加の読み込み処理(「INSERT」や「UPDATE」や「DELETE」の場合)が発生します。
(1)どうすれば作成したインデックスが有効であることがわかりますか?それらのインデックスはどのように使われているのでしょうか?
まず始めに、インデックスが有効かどうか判断します。DDLはオブジェクト(インデックスのような)を作るために使用されます。そしてシステム・カタログを更新します。インデックスを作成することはインデックスの「使用」を構成するものではありません、それ故、インデックスDMVはインデックスが実際に使用されるまでそのDMVを更新しません。あるインデックスが「SELECT」、「INSERT」、「UPDATE」、または、「DELETE」SQL文で使用されると、その使用がsys.dm_db_index_usage_statsに反映されます。もし代表的な業務を走らせていたのであれば、全ての有効なインデックスがsys.dm_db_index_usage_statsに記録されているでしょう。従って、sys.dm_db_index_usage_stats上に見当たらないインデックスはその業務において(SQL Serverが起動してから)使用されていないものと言えます。使用されていないインデックスは以下のようにして調べることができます:
(2)使用されていないテーブルやインデックスが存在していないでしょうか?
------ unused tables & indexes. Tables have index_id’s of either 0 = Heap table or 1 = Clustered Index
Declare @dbid int
Select @dbid = db_id('Northwind')
Select objectname=object_name(i.object_id)
, indexname=i.name, i.index_id
from sys.indexes i, sys.objects o
where objectproperty(o.object_id,'IsUserTable') = 1
and i.index_id NOT IN (select s.index_id
from sys.dm_db_index_usage_stats s
where s.object_id=i.object_id and
i.index_id=s.index_id and
database_id = @dbid )
and o.object_id = i.object_id
order by objectname,i.index_id,indexname asc
めったに使われないインデックスもよく使われるインデックスと同様にsys.dm_db_index_usage_statsに現れます。めったに使われないインデックスを見つけるためには、user_seeks列や、user_scans列やuser_updates列などに着目してください。
--- rarely used indexes appear first
declare @dbid int
select @dbid = db_id()
select objectname=object_name(s.object_id)
, s.object_id, indexname=i.name, i.index_id
, user_seeks, user_scans, user_lookups, user_updates
from sys.dm_db_index_usage_stats s,
sys.indexes i
where database_id = @dbid
and objectproperty(s.object_id,'IsUserTable') = 1
and i.object_id = s.object_id
and i.index_id = s.index_id
order by (user_seeks + user_scans + user_lookups + user_updates) asc
(3)インデックスの利点に対するメンテナンス・コストはどの程度でしょうか?
もし、頻繁に更新されるテーブルがあり、めったに使われないインデックスを持っていた場合、そのインデックスのメンテナンス・コストはインデックス利用のメリットを上回ります。このコストとメリットの比較は、テーブル値関数sys.dm_db_index_operational_statsを以下のように使用して行うことが出来ます。
--- sys.dm_db_index_operational_stats
declare @dbid int
select @dbid = db_id()
select objectname=object_name(s.object_id)
, indexname=i.name, i.index_id
, reads=range_scan_count + singleton_lookup_count
, 'leaf_writes'=leaf_insert_count+leaf_update_count+ leaf_delete_count
, 'leaf_page_splits' = leaf_allocation_count
, 'nonleaf_writes'=nonleaf_insert_count + nonleaf_update_count + nonleaf_delete_count
, 'nonleaf_page_splits' = nonleaf_allocation_count
from sys.dm_db_index_operational_stats(@dbid,NULL,NULL,NULL) s,
sys.indexes i
where objectproperty(s.object_id,'IsUserTable') = 1
and i.object_id = s.object_id
and i.index_id = s.index_id
order by reads desc, leaf_writes, nonleaf_writes
--- sys.dm_db_index_usage_stats
select objectname=object_name(s.object_id)
, indexname=i.name, i.index_id
,reads=user_seeks + user_scans + user_lookups
,writes = user_updates
from sys.dm_db_index_usage_stats s,
sys.indexes i
where objectproperty(s.object_id,'IsUserTable') = 1
and s.object_id = i.object_id
and i.index_id = s.index_id
and s.database_id = @dbid
order by reads desc
go
sys.dm_db_index_usage_statsとsys.dm_db_index_operational_statsの違いは以下の通りです。sys.dm_db_index_usage_statsは全てのアクセスを1としてカウントするのに対して、sys.dm_db_index_operational_statsは処理や、ページ数、行数に応じてカウントします。
(4)インデックス競合やホットスポットは発生していないでしょうか?
インデックス競合(例えば、ロック待ち)はsys.dm_db_index_operational_statsによって調べることが出来ます。row_lock_countやrow_lock_wait_count、row_lock_wait_in_ms、page_lock_count、page_lock_wait_count、page_lock_wait_in_ms、page_latch_wait_count、page_latch_wait_in_ms、pageio_latch_wait_count、pageio_latch_wait_in_msなどは、待ちが発生しているかどうかという観点で、ロック待ちやラッチ競合を詳細に示します。以下のようにして待ち数と比較することにより、ブロッキングや、ロック待ちの平均を決めることができます:
declare @dbid int
select @dbid = db_id()
Select dbid=database_id, objectname=object_name(s.object_id)
, indexname=i.name, i.index_id --, partition_number
, row_lock_count, row_lock_wait_count
, [block %]=cast (100.0 * row_lock_wait_count / (1 + row_lock_count) as numeric(15,2))
, row_lock_wait_in_ms
, [avg row lock waits in ms]=cast (1.0 * row_lock_wait_in_ms / (1 + row_lock_wait_count) as numeric(15,2))
from sys.dm_db_index_operational_stats (@dbid, NULL, NULL, NULL) s, sys.indexes i
where objectproperty(s.object_id,'IsUserTable') = 1
and i.object_id = s.object_id
and i.index_id = s.index_id
order by row_lock_wait_count desc
以下のクエリ結果は[Order Details]テーブル中のインデックス「OrdersOrder_Details」の待ちを示しています。ブロッキングが発生しているのは全体の時間の2%未満ですが、それらが発生している時は、ブロックされている時間の平均は15.7秒です。

SQL Server Profilerの[Blocked process report]を使ってこのロック待ちを追跡して見るのは重要かもしれません。”sp_configure ‘Blocked Process Threshold’,15”ステートメントを使ってブロックされたプロセス閾値を15秒に設定することができます。この設定により、15秒以上のブロッキングをキャプチャすることができます。
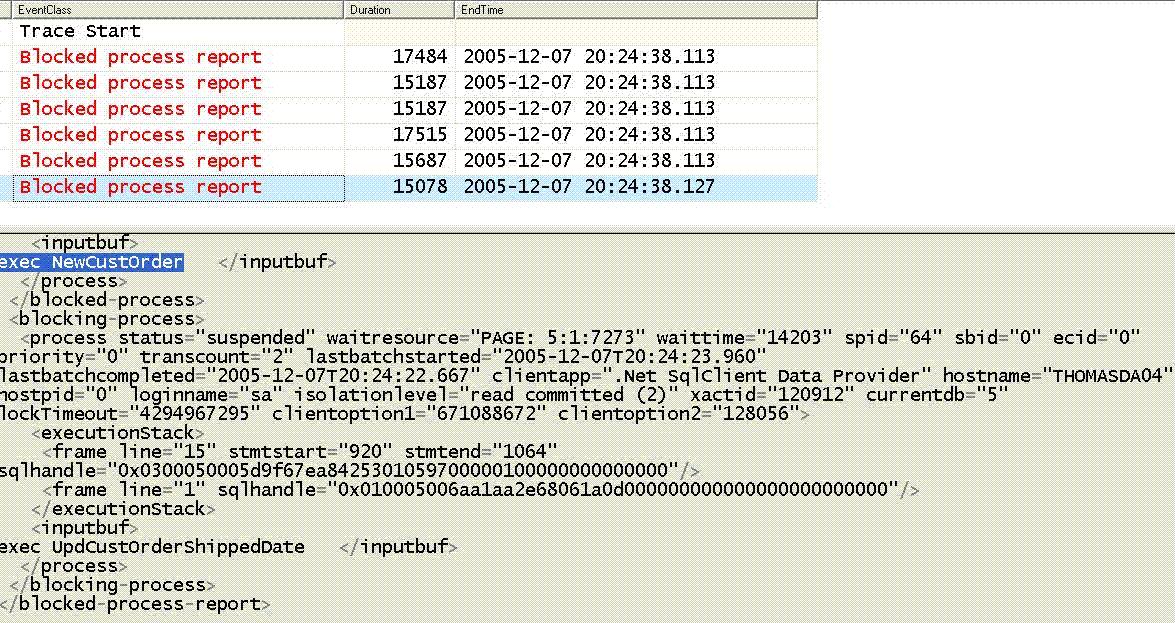
Profilerのトレースはブロックされたプロセスとブロックしているプロセスを含みます。長時間のブロッキングをトレースする利点は、ブロックされている状態、および、ブロックしている状態の詳細をトレースファイルに保存し、そのブロッキングが消えた後でゆっくりと調べることが出来る点です。時系列で、ブロッキングの主な原因を見ることができます。今回のケースではブロックされているストアドプロシージャはNewCustOrderです。ブロックしているストアドプロシージャはUpdCustOrderShippedDateです。
Profilerの[Blocked process report]によるレポート(警告)がストアドプロシージャの場合、実際にストアドプロシージャ内のどのステートメントがブロックされているかを調べることは出来ません。このような場合は以下を使用すると、ストアドプロシージャ内で実際にブロックされているステートメントをリアルタイムで取得することができます。
create proc sp_block_info
as
select t1.resource_type as [lock type]
,db_name(resource_database_id) as [database]
,t1.resource_associated_entity_id as [blk object]
,t1.request_mode as [lock req]
-- lock requested
,t1.request_session_id as [waiter sid]
-- spid of waiter
,t2.wait_duration_ms as [wait time]
,(select text from sys.dm_exec_requests as r
-- get sql for waiter
cross apply sys.dm_exec_sql_text(r.sql_handle)
where r.session_id = t1.request_session_id) as waiter_batch
,(select substring(qt.text,r.statement_start_offset/2,
(case when r.statement_end_offset = -1
then len(convert(nvarchar(max), qt.text)) * 2
else r.statement_end_offset
end - r.statement_start_offset)/2)
from sys.dm_exec_requests as r
cross apply sys.dm_exec_sql_text(r.sql_handle) as qt
where r.session_id = t1.request_session_id) as waiter_stmt
-- statement blocked
,t2.blocking_session_id as [blocker sid]
-- spid of blocker
,(select text from sys.sysprocesses as p
-- get sql for blocker
cross apply sys.dm_exec_sql_text(p.sql_handle)
where p.spid = t2.blocking_session_id) as blocker_stmt
from
sys.dm_tran_locks as t1,
sys.dm_os_waiting_tasks as t2
where
t1.lock_owner_address = t2.resource_address
go
exec sp_block_info
(5)インデックスを増やすことによって(または減らすことによって)効果を得ることができるでしょうか?
インデックスがメンテナンス・コストと、読み込み時のメリットという両面を持っていることを考えると、全体的なインデックス・コストとメリットの関係は、読み込みと書き込みを比較することによって決めることができます。インデックスを読むことでテーブル・スキャンを回避できますが、更新時には断続的にメンテナンスを行う必要があります。インデックスが使用されていない、または、使用頻度が低いなど周辺の問題を見つけることは容易ですが、最終的な解析においてインデックスのコスト対メリットの問題はいく分込み入った議論となります。その理由は読み込みと書き込みの数は業務負荷と頻度に大きく依存するからです。加えて、非常に重要な業務においては質的な要素が読み込みと書き込みの数を重要度で上回ることがあります、例えば月ごとの報告や四半期ごとのVPレポートなどではメンテナンス・コストが最も重要な問題ではなくなります。
全てのインデックスに対する書き込みは「INSERT」として処理されますが、それに伴って読み込みが発生することはありません(参照制約が無い限り)。「SELECT」文のほかに、「UPDATE」および「DELETE」の際は読み込み処理が発生し、もし条件を満たす行がある場合は書き込み処理が発生します。OLTP業務ではたくさんの小さなトランザクションが発生し、「SELECT」、「INSERT」、「UPDATE」、および、「DELETE」処理を頻繁に組み合わせています。データ・ウェアハウスにおける処理は、集中的な書き込みが行われるバッチ処理と、その後に引き続いて行われるオンラインの読み込み処理に分けられます。
SQL文 |
読み込み |
書き込み |
SELECT |
発生 |
発生しない |
INSERT |
発生しない |
全てのインデックスにおいて発生 |
UPDATE |
発生 |
条件を満たした行において発生 |
DELETE |
発生 |
条件を満たした行において発生 |
一般的に、トランザクション数の多いOLTPでは、多くのトランザクション・スループットは多くのインデックスのメンテナンス・コストを伴い、ブロッキングの可能性を持っているので、インデックスを必要最小限にしておくことが望ましいです。対照的に、データ・ウェアハウスの業務においては、更新処理が発生するバッチ・ウィンドウの間だけインデックスのメンテナンス・コストを支払えば済みます。このように、データ・ウェアハウスでは多くのインデックスを作ることによりオンライン・ユーザによる読み込み中心の処理に対してインデックスから利益を受ける傾向が強いです。
結論として、SQL Server 2005の重要な新しい機能として動的管理ビュー(DMV)があります。DMVはSQL Server 2000では利用できなかったレベルのシステムの内部情報を提供し、状態検知、メモリおよびプロセルのチューニング、そして状態監視のために使用できます。DMVは、インデックスの利用状況、メンテナンス・コスト対メリットの関係、および、ホットスポットなどの実運用上の質問に対して回答を得るのに有効です。最後に、DMVは「SELECT」文で参照できますが、ディスク上に保存されているわけではありません。したがってDMVはSQL Serverが最後に立ち上がってから現在までのサーバ状態変化の集計を示します。
コミュニティにおけるマイクロソフト社員による発言やコメントは、マイクロソフトの正式な見解またはコメントではありません。