Query_hash и Query_plan_hash, что в этих числах? Часть вторая.
Добрый день коллеги.
Мы продолжаем разговор о использовании query_hash и query_plan_hash для оптимизации использования процедурного кэша и уменьшения нагрузки на процессор. В предыдущем блоге мы выполнили постановку задачи и вышли на использование этих свойств запроса (https://blogs.technet.com/b/sqlruteam/archive/2014/11/09/sql_5f00_server_5f00_query_5f00_hash_5f00_and_5f00_query_5f00_plan_5f00_hash_5f00_part_5f00_1.aspx).
Для более глубокого понимания описываемых свойств рассмотрим упрощенную архитектуру системы компиляции запросов (кода Transact-SQL).
Ниже приведена блок-схема. Для упрощения часть ее компонентов пропущена.
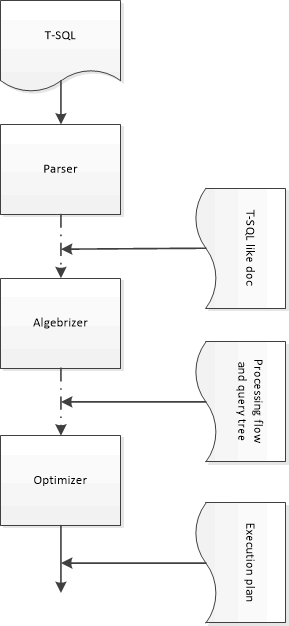
Последовательность превращения кода, написанного на Transact-SQL, в план выполнения следующая.
1. Текст запроса (функция, триггер, хранимая процедура) попадает на вход Parser-а. Задача которого проста - выполнить синтаксический контроль введенного текста и нормализацию текста (удалить ненужные пробелы и форматировать во внутренний (нормальный) формат. На этом этапе из кода запроса рассчитывается sql_handle (внутренний идентификатор однозначно идентифицирующий этот код). sql_handle рассчитывается исходя из исходного (ненормализованного) текста запроса и поэтому такой же запрос, но с дополнительным символом "пробел" или оператором GO в одном и том же тексте, будет трактоваться как новый запрос, и для него будет рассчитан свой sql_handle, и создана еще одна запись в процедурном кэше.
Ниже приведены два абсолютно одинаковых запроса, отличающиеся наличием лишнего символа "пробел". Обратите внимание на то, что sql_handle у них разные, а вот query_hash и query_paln_hash одинаковы.
select *
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
where FirstName= 'Michael'
go
select *
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
where FirstName= 'Michael'

2. Нормализованный текст запроса попадает на Algebrizer. Его задача - превратить все ваши "измышления" на языке T-SQL в дерево разбора (Bound Tree), описывающее алгоритм выполнения запроса (кстати для View на этом все и заканчивается и дальнейшая обработка (оптимизация) не производится). Также, на данном этапе производится извлечение из кода запроса литералов. Цель этой операции - обеспечить возможность использования Auto Parameterization (Автопараметризации) для уменьшения количества планов выполнения. Ниже приведенные запросы будут иметь разные sql_handle (поскольку побайтово тексты запросов разные), но одинаковые query_hash и query_plan_hash поскольку дерево разбора и алгоритмы их выполнения одинаковы.
select *
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
where pp.BusinessEntityID = 274
go
select *
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
where pp.BusinessEntityID = 275
3. На этапе оптимизации решаются более сложные задачи.
Первая из них - это отыскание тривиального плана. Часть запросов достаточно просты и нет необходимости их оптимизировать, например, простейшие операторы INSERT, UPDATE, DELETE, SELECT не использующие никаких условий (предикатов). Для таких запросов хранятся готовые планы выполнения.
Вторая задача - это стандартизация. Это сложная задача по приведению разных конструкций, дающих один и тот же результат, к одной стандартной конструкции. На этом этапе сервер преобразует код T-SQL в некоторые стандартные (предварительно заготовленные разработчиками) формы деревьев, для того чтобы уменьшить возможное количество кандидатов на планы выполнения.
Например:
- соединение таблиц через оператор JOIN ... ON это одно и то же, что соединение через запятую и оператор WHERE,
- использование операторов WHERE ... BETWEEN ... AND ... дает тот же результат, что и операторы WHERE ... >=... и ...<=,
- использование оператор WHERE ... IN(....) дает тот же результат, что и операторы WHERE ... OR ...
- и т.д.
select *
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
where FirstName= 'Michael'
go
select *
from [Person].[Person] pp, [Sales].[SalesPerson] ssp
where pp.BusinessEntityID=ssp.BusinessEntityID and FirstName= 'Michael'

Обратите внимание, что несмотря на то, что тексты запросов абсолютно разные, query_hash (структуры деревьев разбора) также разные, а query_plan_hash одинаковы, благодаря встроенному "интеллекту" оптимизатора, "понимающему", что (по алгоритму выполнения) это один и тот же запрос.
Еще пример с операторами DISTINCT и GROUP BY.
select distinct FirstName
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
go
select FirstName
from [Person].[Person] pp
inner join [Sales].[SalesPerson] ssp
on pp.BusinessEntityID=ssp.BusinessEntityID
group by FirstName

Есть еще ряд задач решаемых в ходе оптимизации, но для их описания необходима целая серия статей.
Итак мы рассмотрели принципы работы системы компиляции запросов и связь их с query_hash и query_plan_hash. В следующих статьях мы сформулируем ряд рекомендаций по оптимизации использования процедурного кэша на основе полученных знаний.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)