Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In-Memory OLTP Indexes
In-Memory OLTP technology, available in Azure SQL Database and SQL Server, can significantly help you in improving the performance of applications that require high throughput and low latency online transaction processing, high volume concurrent data ingestion (Internet of Things - IoT), high volume data load and transformation ( Extract Transform Load - ETL ) or transient data management ( Caching and Session State, Temp Db Object Replacement ). Note that In-Memory OLTP technology may not necessarily be suitable for every application scenario that exists and hence it is important to know when to best leverage it in your application. For more information on best scenarios to leverage this technology we suggest you to read: Usage Scenarios for In-Memory OLTP.
In-Memory OLTP technology performs well not just because your data resides in memory. In fact, the hot data pages of disk-based tables in SQL Server are also cached in memory. In-Memory OLTP truly shines because the memory-optimized data access mechanism uses lock and latch-free algorithms along with multi-version optimistic concurrency control (MVCC) to avoid contention and blocking during data access. The data access layer is optimized for rapid access in memory. Complementary to these optimizations in the engine, the indexing mechanism that you use for your memory-optimized table, continues to be of paramount importance. There are some key considerations to keep in mind when choosing and configuring an index on a memory-optimized table. Choosing the right type of index and configuring it accurately, will enable you to take full advantage of these optimizations in the engine and attain optimal query performance.
The primary focus of this blog (Part 1) is to highlight the memory-optimized indexes and covers the following: -
- A quick feature update on memory-optimized indexes.
- A quick recap of memory-optimized indexes and their characteristics.
- Key differences between the two types of memory-optimized indexes.
- Choosing the right index type for your memory-optimized table.
This blog post does not cover the theoretical concept of memory-optimized indexes. For that, we recommend you read Indexes for Memory-Optimized tables.
In the follow-up blog post (Part 2), we will focus on applying the recommendations and principles from this blog (Part 1) in practice and go over in detail the troubleshooting steps you can take to detect, mitigate and fine tune your memory-optimized index to achieve optimal query performance.
Quick feature update on In-Memory OLTP
Starting SQL Server 2016, it is now possible to: -
- Add a memory-optimized index after creating the memory-optimized table. See ALTER TABLE
- Create memory-optimized indexes on NULLABLE columns.
- Use non-BIN2 collations for n(var)char columns in the index key.
- Use Query Data Store to monitor and analyze performance of queries to your memory-optimized tables.
- Issue parallel table and index scans.
- Support for table scans using the in-memory heap containing the base data rows. They often perform better than a full index scan when there is no sort-order requirement.
Starting SQL Server 2017 it is now possible to: -
- Create as many indexes on a memory-optimized table as allowed on disk based tables. Maximum 8 indexes limit on memory-optimized tables has been removed.
All the above enhancements are also available on Azure SQL Database.
Quick recap of Memory-Optimized indexes
In this section, we will go over the types of indexes you can use with memory-optimized tables and some of their characteristics.
Nonclustered Index
A Nonclustered index essentially is similar in principle to a disk-based Nonclustered index. A Nonclustered index should typically be, the go to index for your memory-optimized table. You can use a Nonclustered index to do range lookups using inequality operators (e.g., <,>, etc.), do ordered scans by using the ORDER BY clause and do point lookups by using the equality operator (=) in your query. You can also create multiple Nonclustered indexes on a memory-optimized table and even on the same key column(s). For more information, we recommend you read Nonclustered indexes.
Nonclustered Index characteristics:
- Duplicate key values - Having a lot of identical values in your index key column (i.e., duplicates) may hamper indexing performance. A Nonclustered index however, can generally handle duplicate index key values well if the average number of duplicates in the key column is < 100x.
- Leading key column - It is also possible to write queries that only touch a subset of the leading key columns. So, if you have a Nonclustered index on column ‘A’ and ‘B’, it is possible to query using just key column ‘A’ since that is the leading key column.
- Unidirectional - Index scans should only be done in the direction that aligns with the ORDER specified when the Nonclustered index was created. Default order applied is ASCENDING.
- Size – The size of the index is essentially: (size-of-key) x (row count).
Hash Index
A Hash index uses the hashing algorithm to map the index key columns to hash buckets. The hash table makes looking up the exact key value a constant time operation and thus helps you further optimize your point lookup query performance. A hash index can be used to do point lookups using only the equality operator (‘=’). Inequality based seeks are not supported. With a hash index you must configure the number of hash buckets at create time. Guidance on how to configure the bucket count for a hash index is discussed later in the blog. For the conceptual understanding of a Hash index we recommend that you read Hash Indexes for Memory-Optimized tables.
Hash Index characteristics:
- Duplicate key values – Hash indexes are sensitive to duplicate index key column values and you may notice significant performance degradation as the number of duplicates increase.
- Subset search - It is important that all the key columns on which the point lookup is performed is part of the index. Otherwise the query engine will revert to doing a full table scan.
- Ordering – Key values stored in a Hash index cannot be ordered by definition. There is no ordering applied to the keys stored in the Hash index.
- Size – The size is determined at index creation/rebuild time. It will be (8 bytes) * (bucket count). The sizing amounts to a relatively small footprint for most use-cases.
Columnstore Index
A Columnstore index allows storing, retrieving and manipulating data for operational analytics using the columnar data format. The data is physically stored in column-wise data format instead of the regular row based format. Columnstore allows you to run performant real-time analytics on an OLTP workload. In-memory OLTP tables support creation of Columnstore indexes. For detailed information, we recommend that you read Columnstore Indexes Overview.
Columnstore index characteristics:
- Size - The Columnstore index is essentially in effect, a secondary physical copy of the table, in columnar data format. The original row-oriented memory-optimized physical structure remains as for OLTP operations.
- Durability - Unlike Hash and Nonclustered indexes, Columnstore indexes are logged. They retain a copy on disk and aren’t recreated on startup. This aids database recovery time.
If you do not fully understand at this point, the index characteristics mentioned above - do not worry. We will be covering them in the sections below, in detail. For this blog, we will scope our discussion to just Nonclustered and Hash indexes.
Memory-optimized index v/s Disk based index – key differences
The table below gives a concise summary of the key functional and behavioural differences between a memory-optimized and a disk-based index: -
| Characteristic/Behaviour | Memory-Optimized Index | Disk-based/Regular Index |
| On-disk representation | None. Solely resides in-memory. | Significant on-disk footprint. |
| Rebuild indexes on SQL Server or database restart | Yes. Since there is no on-disk representation. No – for Columnstore index. | No. |
| Covering | Always covering, i.e., all columns are always included. | You need to specify which column you want to include alongside the index key columns. And if required columns are not included in the index, SQL Server performs a bookmark lookup into the heap or clustered index. |
| INSERT/UPDATE/DELETE operations | Index changes relating to inserts/updates/deletes are not logged. For instance, when a SQL UPDATE statement modifies data in a memory-optimized table, the corresponding changes to the indexes will not be written to the log. | Index changes relating to inserts/updates/deletes are written to the transaction log. |
| Fragmentation | No fixed pages, so fragmentation does not occur. You do not need to perform maintenance with memory-optimized indexes (besides Columnstore). Hash indexes are static. With Nonclustered indexes, there is no fragmentation within the pages, since pages are variable in size and are always fully packed – there is no empty space in the pages, no fill factor involved. Some fragmentation between the pages can still occur, if new versions of pages are written to different areas of memory. But the impact on performance is generally less than with disk-based tables, since the pages are all memory-resident, and are directly addressed through memory pointers. Essentially Nonclustered index is self-maintaining. | Uses fixed pages, so fragmentation can occur and needs to be de-fragmented by rebuilding or reorganizing indexes regularly. |
Choosing between a Hash and a Nonclustered Memory-Optimized index
In this section, you will learn some guidelines on how to choose between a Nonclustered and a Hash index for your memory-optimized table.
Nonclustered Index
When starting out with a new memory-optimized table or when replacing a disk based table with a memory-optimized table, typically we recommend using a Nonclustered index. Because Nonclustered indexes support range scans, ordered scans, point lookups and generally cover all the use cases, to begin with, a Nonclustered index should typically be the default go-to index for your memory optimized table. When unsure of which index to pick in a certain situation, always pick a Nonclustered index.
UNIDIRECTIONAL
Memory-optimized nonclustered indexes are unidirectional. What this means is that if your query requires a certain sort-order, through the ORDER BY statement, you need to make sure that the index definition is also aligned to that same sort-order.
For e.g., Consider a table ‘TestTbl’ with 99K rows and columns c1, c2 etc. Assume that you create a Nonclustered index on c1 – your index key column, with the ASCENDING order:
--Add a nonclustered index with ASCENDING order
ALTER TABLE [dbo].[TestTbl]
ADD INDEX ix_nc_c1_TestTbl_asc
NONCLUSTERED (c1 ASC)
GO
Now, consider a query, that does a lookup using the inequality operator and then attempts to sort the results in a DESCENDING order:
--Sample query seeking records in DESCENDING order.
SELECT *
FROM [dbo].[c1]
WHERE c1 < 3.10
ORDER BY c1 DESC
GO
Because the index was created with ASCENDING order and the query seeks data in DESCENDING order this is called a reverse-sort order seek. In this case, the query engine will have to perform a table scan and then sort the result set. Not to mention this will severely impact your query performance. If you intend to have queries that require sort-order in both directions, then, it is recommended that you create two Nonclustered indexes; one in either direction. In the case mentioned above, you should create a Nonclustered index with DESC order specified to align to the direction of the seek.
Note: If you don’t explicitly specify the sort order when creating the Nonclustered index, it defaults to: ASCENDING.
DUPLICATE KEY VALUES
Nonclustered indexes are also very useful because they can handle a considerable amount of duplicate index key column values. Sometimes, in the practical-world, it is difficult to avoid duplicate values in index key columns. In such cases, calculating the duplication ratio will help you understand the extent of duplication in the index key column. As a guideline, if the ratio of the total number of index key values in the index column to the total number of distinct key values in that column is > 10, then it makes sense to use a Nonclustered index. For e.g., Let’s consider the same example of ‘TestTbl’ with 99K rows. Assume that c1 is the candidate key column which has a fair number of duplicates and that c2 is unique. To calculate the duplication ratio mentioned above, you can simply use a query like this:
DECLARE @totalKeyValues float(8) = 0.0, @distinctKeyValues float(8) = 0.0;
SELECT @totalKeyValues = COUNT (*) FROM [dbo].[TestTbl];
SELECT @distinctKeyValues = COUNT(*) FROM (SELECT DISTINCT c1 FROM [dbo].[TestTbl]) as d;
-- If ratio >= 10.0, use a nonclustered, not a Hash index.
SELECT CAST((@totalKeyValues / @distinctKeyValues) as float) as [Total_To_Unique_Ratio];
GO
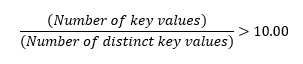
Typically, if the ratio is >10 and <=100, the Nonclustered index will perform well. Though, keep in mind that, overall duplicates, are sub-optimal for indexing performance. It is a good practice to get rid of the duplicity from the index key columns when possible. An increase in the average number of duplicates in the index key column increase, puts a strain on the Garbage Collector (GC). The GC on average, must walk a longer length of duplicate chains for every DML operation. This will burn more CPU cycles and you may notice a higher CPU utilization, especially when you have a concurrent DML workload ongoing.
Uniquifying the Index
For e.g., Let’s say you run the query above to get the duplication ratio and discover that the ratio on c1 is higher than 100, which means that there is a very high number of duplicates on average in c1. What should you do in that case?
Well, as we said earlier, since column c2 is unique, you can use a combination of c1 and c2 as the index key columns for the Nonclustered index. A combination of c1 and c2 will uniquely identify the key values and your problem of duplicity goes away. This is what you would call “Uniquifying” an index and doing so will help narrow down the seek scope in the bw-tree much faster when looking for the index key.
Note: When using a lot of columns as index keys for your Nonclustered index, you may notice a higher memory consumption and it may also impact overall DML performance - a tradeoff to be aware of.
Hash index
To further optimize your queries that do point lookups on your memory-optimized table using an equality operator (=), consider using a Hash index. Hash indexes also optimize insert operations and aid database recovery time. As mentioned earlier, a Hash index uses a hash table internally to keep track of the index keys. The hashing function uses all the key(s) specified at the index creation time to create a mapping between the index key column(s) and the corresponding hash bucket. Hence, it is important that you specify all the index key columns that are part of the hash index, during the lookup in your query.
As with any hashing technique, collisions will occur. A hash collision occurs when two or more index keys map to the same hash bucket. In general, having a limited number of collisions is expected and is fine. It is only when the number of collisions become excessive, it may noticeably begin to impact your query performance. Your aim should be to keep the number of collisions as low as possible. You may experience a higher number of collisions either because: -
- There are many duplicate index key column values in the table and/or
- The number of hash buckets for your Hash index are under provisioned.
Note: The built-in hash function results in a distribution of index keys over hash buckets close to the Poisson distribution: if the bucket count equals the index key count, a third of the buckets will be empty, a third will have one value, a third will have two values, and a handful will have more than two values.
With a large number of hash collisions, to locate an individual row in the bucket, the seek operation on average, would need to walk half the chain of rows that hash to the corresponding bucket. Therefore, higher the number of collisions, slower will be the index seek and your query lookup performance. You may also notice a higher CPU utilization because of the additional overhead of collision handling and the strain it puts on the Garbage Collector (GC). To summarize, there are three important factors that directly impact your Hash index key lookup performance:
- BUCKET_COUNT
- Duplicate Key Values
- Subset of Hash Index Key Columns
BUCKET_COUNT
The BUCKET_COUNT is crucial to achieving optimal Hash index performance and you should consider the following factors when configuring it:
- The total number of index key column values.
- The ratio of the total number of unique to duplicate index key column values.
- The projected future growth of the table.
OVERESTIMATION: If you have a higher number of buckets compared to the total number of index keys in your table, the likelihood of collisions occurring is low. Also, a larger bucket count gives you growth headroom, so you can accommodate more data in the table in the future (as your business grows) without having to worry about running out of buckets or having to reconfigure your index.
UNDERESTIMATION: If the number of buckets configured is lower than the total number of key values, then, you will have more collisions and even distinct key values would have to share the bucket. This may significantly impact your query performance.
Should you OVERESTIMATE OR UNDERESTIMATE? Ideally, you want your: Bucket count = (1 to 2) x (number of unique key values in your memory-optimized table). In cases where it’s harder to predict the number of unique key values, we recommend that its always better to OVERESTIMATE. The performance of a Hash index is good in general if: (Bucket count) ≤ 10 x (number of key values) .
For e.g., Consider the example table ‘TestTbl’ with 99K rows and columns c1, c2, etc. Assume that you often do point lookups on these columns and hence you want to optimize by creating a Hash index on them. The columns c1 and c2 (your index key columns) have about 70K distinct values. Since you have 99K rows, a good reasonable bucket count would be 128K. This also gives you a small headroom for future growth. The number of buckets would be just under [2x] the number of unique values (70K). To configure a Hash index with this bucket count you can:
ALTER TABLE [dbo].[TestTbl]
ADD INDEX ix_hash_c1c2_TestTbl
HASH (c1, c2) WITH (BUCKET_COUNT = 128000)
GO
If you do indeed, expect a much larger growth soon, you can also pick something like 1024K as your bucket count. Then simply rebuild your Hash index by:
ALTER TABLE [dbo].[TestTbl]
ALTER INDEX ix_hash_c1c2_TestTbl
REBUILD WITH (BUCKET_COUNT=1024000)
GO
Caveat: Since each bucket consumes 8 bytes, with overestimation your Hash index will have a larger memory footprint. The BUCKET_COUNT will always automatically round up to the next power of 2.
DUPLICATE KEY VALUES
As mentioned earlier, a table with a lot of duplicate values in the index key column is going to have sub-optimal Hash index lookup performance due to the frequent hash collisions. Hence, it is important to evaluate the number of duplicates you have in the index key column. As a guideline, if the ratio of the total number of index key values in the index column to the total number of distinct key values is < 10 then it makes sense to use a Hash index. If the ratio is more than 10x use a Nonclustered index.

For e.g., To calculate the ratio mentioned above for our sample ‘TestTbl’ with columns c1, c2, etc. you can simply do this:
DECLARE @totalKeyValues float(8) = 0.0, @distinctKeyValues float(8) = 0.0;
SELECT @totalKeyValues = COUNT (*) FROM [dbo].[TestTbl];
SELECT @distinctKeyValues = COUNT(*) FROM (SELECT DISTINCT c1 FROM [dbo].[TestTbl]) as d;
-- If ratio >= 10.0, use a nonclustered, not a Hash index.
SELECT CAST((@totalKeyValues / @distinctKeyValues) as float) as [Total_To_Unique_Ratio];
GO
Caveat: If you have a very high number of duplicates, then you might notice a higher CPU consumption because of the overhead of collision handling.
SUBSET OF HASH INDEX KEY COLUMNS
Hash indexes use all the key columns to compute the hash value which is then used to map the index key to the corresponding hash bucket. Hence, it is imperative that when doing a point lookup, you specify all the key columns that are part of the Hash index.
For e.g., Consider the table ‘TestTbl’ with Hash index columns c1 and c2. The Hash index is created on the composite of c1 and c2.
ALTER TABLE [dbo].[TestTbl]
ADD INDEX ix_hash_c1c2_TestTbl
HASH (c1, c2) WITH (BUCKET_COUNT = 128000)
GO
Imagine that you do a point lookup using the equality operator in your query, but you only specify one of the key columns (say column c1).
--Querying on subset of the Hash index key columns.
SELECT *
FROM [dbo].[TestTbl]
WHERE c1 = 99
GO
In this case, the Hash index can’t do an index seek because it cannot compute the hash value that maps to the corresponding hash bucket. This is because the hash value is generated by using the composite of c1 and c2 and without both being present in the query lookup, it must now revert to doing a full table scan. Needless to mention, as the table grows, the query performance will degrade further.
Recommendation summary for choosing the right type of memory-optimized index
| Scenario | Optimal Index Choice | Sub-Optimal Index Choice | Do Not Use |
| Migrating a disk based table to memory-optimized table | Nonclustered Index should typically be the default choice. There are very few cases where a Hash Index might be useful. When unsure always use a Nonclustered Index to begin with. | - | - |
| Full index scans (Retrieve all rows in the table) | Hash index scans are generally faster than a full Nonclustered index scan, unless the bucket count is much greater than 10x the number of index keys in the table. | - | - |
| Equality seek (Point lookups using equality ‘=’) | Hash Index | Nonclustered Index | - |
| Inequality Seek (Using inequality and range predicates <, >, <=, >=, BETWEEN) | Nonclustered Index | - | Hash Index |
| Point and range lookups on a key column | Hash + Nonclustered Index | - | - |
| Ordered scan (ORDER BY) | Nonclustered Index | - | Hash Index |
Summary
In this blog post we gave you an update on what’s new with In-Memory OLTP. We then highlighted the differences between a memory-optimized index v/s a disk-based index and touched upon some of the key characteristics of memory-optimized indexes. Finally, we shared some key recommendations and some important factors to consider when choosing an index for your memory-optimized table and configuring it. We hope that the topics discussed above, help you better understand and leverage memory-optimized indexes more efficiently in your application and achieve optimal query performance.
In the following blog post (Part 2), we will take the learnings from this blog and apply them in practice. We will also go over some of the common issues that you may encounter with memory-optimized indexes and some troubleshooting steps on how to detect and identify performance issues. Finally, we will share some guidelines on how to best mitigate, monitor and achieve optimal query performance with memory-optimized indexes. Part 2 Index troubleshooting blog is now live.
Comments
- Anonymous
November 02, 2017
Great.I hope Sample for it, like AdventureWorks on GitHub for testing each index and performance.I want to test these by the samples on SQL Server 2017 Express.- Anonymous
November 14, 2017
Hi Yoshihiro, Thanks. In-Memory OLTP is available on SQL Server 2016 SP1 (or later), any edition. For SQL Server 2014 and SQL Server 2016 RTM (pre-SP1) you need Enterprise, Developer, or Evaluation edition. More info here: https://docs.microsoft.com/en-us/sql/relational-databases/in-memory-oltp/requirements-for-using-memory-optimized-tables.In part 2 of the blog you will see that you won't need a special sample database or script setup to work through the examples. We just use the WideWorldImporters database for demonstrating troubleshooting techniques etc.
- Anonymous
- Anonymous
November 02, 2017
The comment has been removed - Anonymous
November 06, 2017
Thanks for sharing this great article.- Anonymous
November 14, 2017
Thank you. Part 2 of this blog series is also live now.
- Anonymous