Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Introduction
In the previous blog post In-Memory OLTP Indexes – Part 1: Recommendations, we gave you an update on the latest features of In-Memory OLTP technology. We also summarized the key characteristics of memory-optimized indexes and shared some guidelines and recommendations on how to best choose and configure an index for your memory-optimized table. At this point, if you haven’t read through the previous blog post, we strongly recommend you do so. In this blog post we continue onwards; take the learnings from the previous blog (Part 1) and using some sample examples, apply them in practice. The learnings from this blog post (Part 2) will be particularly useful if you are experiencing query performance issues with memory-optimized tables; either after migration from disk-based tables or in general, with your production workload leveraging memory-optimized tables.
To summarize this blog post covers the following:
- Common mistakes and pitfalls to avoid when working with memory-optimized indexes.
- Best practices to follow when configuring your memory-optimized indexes for optimal performance.
- Troubleshooting and Mitigating your query performance issues with memory-optimized indexes.
- Monitoring your query performance with memory-optimized indexes.
Troubleshooting query performance when using memory-optimized indexes
In this section, we will describe some of the common query performance issues that you may encounter when using a memory-optimized index. Using some sample examples, we will show you how to detect, troubleshoot and mitigate such issues and attain optimal query performance. For the ease of use and accessibility, we will use the new SQL Server sample database “WideWorldImporters”. Before proceeding further, we recommend that you download the sample database and set it up on your database server. In this blog, we will primarily be working with the following two memory-optimized tables:
- [Warehouse].[VehicleTemperatures]
- [Warehouse].[ColdRoomTemperatures]
Troubleshooting Tools
SSMS
SSMS is a great tool to view the internals of the query execution and interact with other objects in your database. For this exercise we will leverage both the estimated and actual query plans to troubleshoot. You can download the latest-greatest version of SSMS here. To view the query execution plans in SSMS you can either use:
- User Interface
- Estimated Plan: Open Query Menu -> Display Estimated Execution Plan.
- Actual Plan: Open Query Menu -> Include Actual Execution Plan.
- Keyboard shortcuts
- Estimated Plan: Ctrl + L
- Actual Plan: Ctrl + M
- T-SQL:
- Enable Show-plan - SET SHOWPLAN_XML ON
- <Execute your query>
- Disable Show-plan – SET SHOWPLAN_XML OFF
Native v/s Interop Procedures
One thing to note here is that the Actual Query Plan is only available for an Interop procedure and not for a Natively Compiled stored procedure. For the latter, you can monitor the performance by using Estimated Query Plans, Extended events and/or DMVs.
Query Store
Query store (available in SQL Server 2016 or higher and in Azure SQL DB) is particularly useful in troubleshooting and debugging poorly performing queries, quickly diagnosing query performance regressions and tracking queries for close monitoring. For your database, you can access the Query Store in SSMS as shown below:
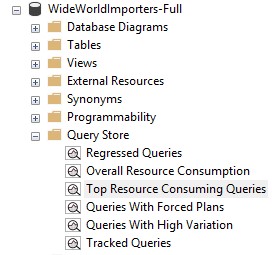
Note that, to make use of the Query Store, you will have to enable it by:
ALTER DATABASE WideWorldImporters SET QUERY_STORE = ON;
Especially interesting in the migration scenario (i.e., when you migrate a disk-based table to a memory-optimized table), is the “Tracked Queries” feature. This feature is also very handy to keep track of queries that have been notorious in the past and/or need close monitoring. For troubleshooting queries that seem to impact resource consumption on your server, you can also use the “Top Resource Consuming Queries” feature. In cases, where you alter the memory-optimized index on a table, to check whether the alteration impacts your query, you can also use the “Regressed Queries” feature.
Dynamic Management Views (DMVs)
Dynamic Management Views (DMVs), that expose useful information about memory-optimized indexes and query execution stats can also be leveraged in certain scenarios to aid troubleshooting. The In-Memory OLTP engine internally maintains statistics about the memory-optimized indexes and their operations. The sys.dm_db_xtp_index_stats DMV can be used to retrieve key stats about the index usage on your memory-optimized table in certain situations:
SELECT ix.index_id, ix.name, scans_started, rows_returned
FROM sys.dm_db_xtp_index_stats ixs JOIN sys.indexes ix ON ix.object_id=ixs.object_id AND ix.index_id=ixs.index_id
WHERE ix.object_id = object_id('<Table_Name>)
GO
In addition to the one mentioned above, there are some other interesting DMVs you can use to troubleshoot memory-optimized indexes in general:
While working through the examples below, it is important to execute the cleanup step between them otherwise you might see mismatching behaviour when examining the query execution behaviour. The cleanup after every example is indicated by [CLEANUP STEP].
Nonclustered Index Troubleshooting
Nonclustered Indexes are very versatile and can be used to do range scans using inequality operators (e.g., <,>), ordered scans by using the ORDER BY clause and point lookups by using the equality operator (=) in your query. You can add a Nonclustered index to a memory-optimized table either at table creation time or by altering the table:
CREATE TABLE <TableName>
(<ColumnName> INT NOT NULL, PRIMARY KEY NONCLUSTERED (<ColumnName>))
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
ALTER TABLE <TableName>
ADD INDEX <IndexName>
NONCLUSTERED (<ColumnName(s)> <ASC/DESC>)
GO
As summarized in the blog post Part 1, Nonclustered indexes:
- Are unidirectional.
- Can handle duplicate key values better than Hash Indexes.
- Allows lookup using a subset of leading key columns.
Issue #1: Reverse sort order query
Since Nonclustered indexes are unidirectional, it is important to consider the ordering while creating them. Let’s look at this with an example. Consider a NonClustered index with “ASCENDING” ordering specified on the ‘Temperature’ key column on this table and the two queries below: -
--Add a nonclustered index with ASCENDING order
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
ADD INDEX ix_nc_asc_Temp_ColdRoomTemp
NONCLUSTERED (Temperature ASC)
GO
[1]
--Sample query seeking records in DESCENDING order.
SELECT ColdRoomSensorNumber, RecordedWhen, ValidFrom, ValidTo, Temperature
FROM [Warehouse].[ColdRoomTemperatures]
WHERE Temperature < 3.10
ORDER BY Temperature DESC
GO
[2]
--Sample query implicitly implying ordering.
SELECT MAX(Temperature) AS MaxTemp
FROM Warehouse.ColdRoomTemperatures
WHERE Temperature < 3.10
GO
Detection
Let us execute query [1] and inspect the query execution plan.
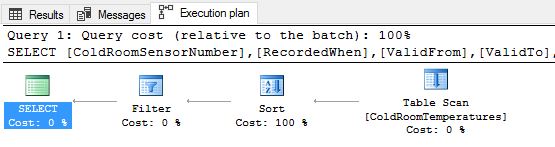
As expected we see that the engine internally had to do a table scan (because we are seeking data in the opposite direction) and then SORT the result set based on what was specified in the query. As you see in the query plan above, the SORT operation is the costliest operation in this case and the one that most impacts your query performance.
Before we execute query [2], lets insert some rows into the [ColdRoomTemperatures] table:
--Insert about 4 million rows in the table to demonstrate the effect of MAX on a Nonclustered index.
INSERT Warehouse.ColdRoomTemperatures(ColdRoomSensorNumber, RecordedWhen, Temperature) SELECT ColdRoomSensorNumber, RecordedWhen, Temperature FROM Warehouse.ColdRoomTemperatures
GO 20
Let us now execute query [2] and inspect the query execution plan.
There are some interesting observations to be made here. If you hover over the Index Seek graphic in SSMS, you will see that an inequality seek is used, illustrating that an inequality seek can be used no matter the direction of the index. In such cases, the engine simply starts scanning the index from the beginning until value 3.10 is reached. If the index were the other way around, the query engine would simply seek on 3.10, and then scan until the end of the index. The plan also shows Parallelism is being used, and if you hover over the Index Seek section of the Actual Plan you can see that a large number of rows or 'actual number' of rows, are being scanned (1049K in my case). This illustrates the fact that ascending indexes cannot be used to optimize the performance of MAX aggregate functions. If you were to use MIN or an index with DESC order, the behaviour would be quite different, as we will see a bit later.
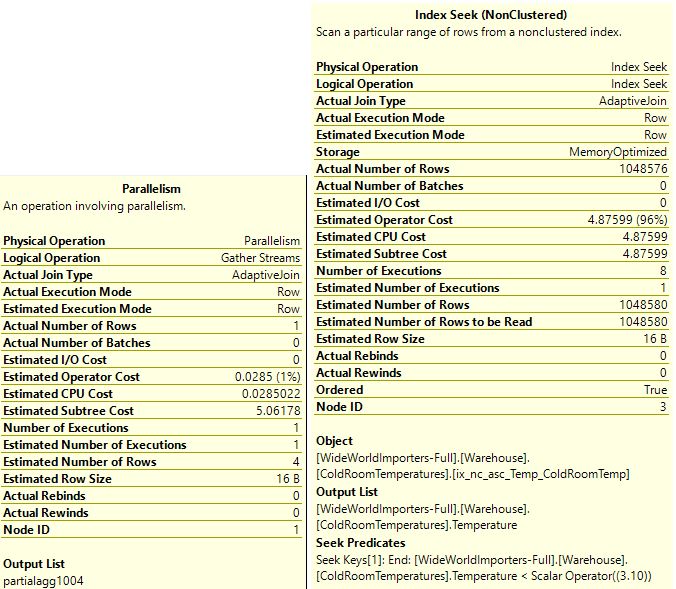
As you can see, the alignment of the direction of the index and the seek should match for optimal performance. Another, useful way to detect if there are index scans occurring more frequently than index seeks is to use the sys.dm_db_xtp_index_stats DMV. You can use the following query:
SELECT ix.index_id, ix.name, scans_started, rows_returned
FROM sys.dm_db_xtp_index_stats ixs JOIN sys.indexes ix ON ix.object_id=ixs.object_id AND ix.index_id=ixs.index_id
WHERE ix.object_id = object_id('Warehouse.ColdRoomTemperatures')
GO
Executing the query above, we get the following output:

We see that the DMV shows the scans and rows returned for the Nonclustered index we initially added. As evident from the results, the rows_returned are far greater than the scans_started; indicating that your query scans a large part of the index.
Note: Another sneaky case where you may not realize that the direction of sort-order plays a role is merge join: In some scenarios, the query optimizer would pick a merge join if there is an index with the right sort-order, but if there is no such index, it will pick nested-loops or a hash. This is of course much harder to troubleshoot, especially since merge joins are not that common to begin with.
Mitigation
To mitigate such an issue, we either align the index direction to the direction of the data retrieval either by: -
- Adding another Nonclustered Index matching the desired ORDER.
- Drop and recreate the index to match the ORDER.
In this case we simply add another index aligned in the same direction as the data retrieval and run the queries again.
--Add a nonclustered index aligned to the direction of the sample query [1].
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
ADD INDEX ix_nc_desc_Temp_ColdRoomTemp
NONCLUSTERED (Temperature DESC)
GO
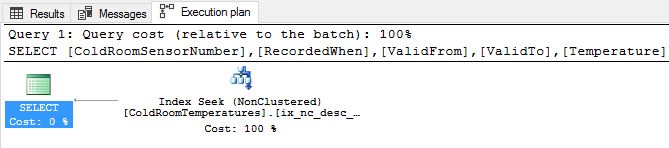
Voila! The query execution plan above shows that we got rid of the costliest operation (SORT) from before. The execution engine simply does an index seek for the predicate and walks down the chain. Now let us execute query [2] and observe the execution plan.

Firstly, you notice that the “Parallelism” has disappeared and the Index Seek now only scans 1 row (see Actual Number of Rows).
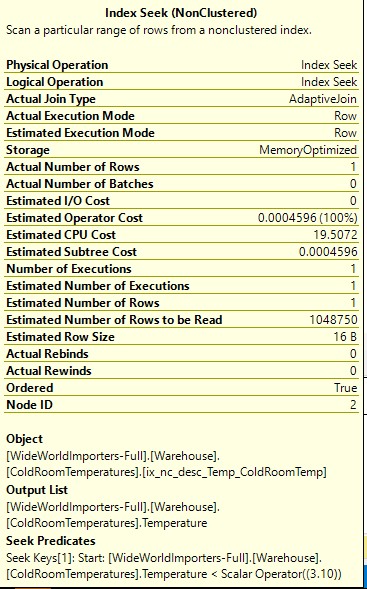
You can run the following query to remove the extra rows that we added to the table:
--[CLEANUP STEP]
DELETE FROM [Warehouse].[ColdRoomTemperatures] WHERE ColdRoomTemperatureID > 3654740
GO
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
DROP INDEX [ix_nc_desc_Temp_ColdRoomTemp]
GO
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
DROP INDEX [ix_nc_asc_Temp_ColdRoomTemp]
GO
Issue #2: Duplicate Index Key Values
A Nonclustered index can handle duplicate index key values to a certain extent. From the previous blog, you learned that a Nonclustered index can perform well if the average number of duplicates is < 100x. However, duplicate key values in general, affect the overall efficiency of an indexing mechanism. Additionally, if you have a lot of duplicates and there is a concurrent DML activity on-going; then the garbage collector (GC) will also be heavily impacted. This is because the GC, must walk the duplicate chains with every update/delete and as the number of duplicates increase the chain potentially becomes longer. One observed side effect of this is higher CPU utilization. Let’s look at this with an example: -
--Sample query.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData
FROM [Warehouse].[VehicleTemperatures]
WHERE ChillerSensorNumber = 2
GO
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_nc_ChillerSensorNumber_VehicleTemperatures
NONCLUSTERED (ChillerSensorNumber)
GO
Detection
We chose this column for the table as an example because the column contains a lot of duplicates. There could be cases where, you may have created a Nonclustered index on a column in the past and at that point in time, the number of duplicates in the key column wasn't remarkably high. After a while though, the number of duplicates in that column may have increased and you start to notice that your query execution seems to be slower than before. To get this kind of historical trend view, you can leverage Query Store’s “Top Resource Consuming Queries” feature. So, let us assume that you notice this query showing up in the Top Resource Consuming Queries section of Query Store and you want to debug this further. To that, in this case, you should consider evaluating the index key columns for duplicates. Let’s calculate by calculating the ratio of total number of index key values to the total number of unique key values:
--Ratio of total key values to the total number of duplicates.
DECLARE @allValues float(8) = 0.0, @uniqueVals float(8) = 0.0;
SELECT @allValues = COUNT(*) FROM [Warehouse].[VehicleTemperatures]
SELECT @uniqueVals = COUNT(*) FROM
(SELECT DISTINCT ChillerSensorNumber
FROM [Warehouse].[VehicleTemperatures] ) as d
-- If the duplication ratio is > 10.0 and < 100.00, use a Nonclustered index.
SELECT CAST((@allValues / @uniqueVals) as float) as [Total_To_Unique_Ratio]
GO
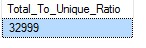
From the value above, it is quite evident that the column has too many duplicates (>100x) and with concurrent DML activity, the GC will be burdened and increase CPU utilization. The increased CPU utilization can start impacting your queries.
Mitigation
Recall that in the previous blog (Part 1) we learned that if the average number of duplicates is too high for a Nonclustered index then, for optimal performance, you should ‘uniquify’ the index key column. To reiterate, uniquifying means that you pair the column which has a lot of duplicates with a column that has unique data such as a primary key or unique key column on your table. Uniquifying the index will help narrow down the seek scope in the bw-tree much faster when looking for the index key and thus speed up the seek operation.
In this case, a NonClustered index on just the ‘ChillerSensorNumber’ is not enough. It would be optimal to create an index on two key columns, the ‘ChillerSensorNumber’ and the primary key column ‘VehicleTemperatureID’ thus uniquifying the index as a whole:
--Add a uniquified nonclustered index
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_nc_ChillerSensorNumberAndVehicleTempId_VehicleTemperatures
NONCLUSTERED (ChillerSensorNumber, VehicleTemperatureID)
GO
Tip: While uniquifying the index make sure that the lookup column(s) follow first before the others. This is because, searching using subset of keys is allowed only if they are the leading key columns.
In the example above, if you create a Nonclustered index on (VehicleTemperatureID, ChillerSensorNumber) you will notice a table scan because the lookup in the query is done on ‘ChillerSensorNumber’ which is not the leading key column. You should be creating the Nonclustered index this way: (ChillerSensorNumber, VehicleTemperatureID) instead. Let’s create the index, execute the query again and inspect the actual execution plan:
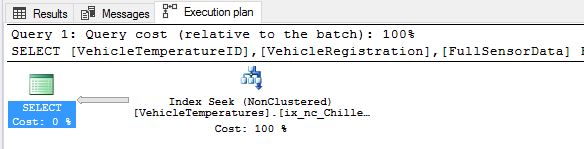
As expected, we are doing Index seeks indeed and this will help you also lower the impact on GC and reduce your overall CPU utilization.
Caveat: Adding more columns to the NonClustered index can sometimes impact DML performance and hence we recommend testing out the new “uniquified” index under production load and compare the performance profiles and CPU consumption.
--[CLEANUP STEP]
--Drop the indexes
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_nc_ChillerSensorNumber_VehicleTemperatures]
GO
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_nc_ChillerSensorNumberAndVehicleTempId_VehicleTemperatures]
GO
Hash Index Troubleshooting
Hash index is extremely useful for doing an index seek using the equality operator (inequality operators are not supported). The underlying hashing mechanism makes looking up values a constant time operation. Hash indexes are also particularly good for optimizing inserts and they generally improve database recovery times. You can add a hash index to your memory-optimized table by:
CREATE TABLE <TableName>
(
INDEX <hash_index_name> HASH (<index_key_column>) WITH (BUCKET_COUNT = <number_of_buckets>)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
ALTER TABLE <TableName>
ADD INDEX <IndexName>
HASH (<ColumnName(s)>) WITH (BUCKET_COUNT = <number_of_buckets>)
GO
As summarized in the blog post (Part 1) Hash indexes:
- Are very suitable for optimizing point lookup operations and insert operations.
- Can be sensitive to duplicate key values (> 10x).
- Don’t support ordered and range scans.
- Don’t support lookups using just a subset of the index keys.
Issue #3: Search using subset of index keys
Hash Indexes do not support doing point lookups on a subset of the hash index key columns in your query. As explained in the previous blog (Part 1), the hashing function uses all the index keys to compute a hash value which in turn determines what bucket that index key set maps to. Hence, if you were to leave out even just one of the index key columns from your query then the hashing function can no longer compute the hash value. The query engine reverts to doing a full table scan. This can often cause significant performance degradation.
Let’s illustrate this with an example: -
--Subset querying with hash index.
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
ADD INDEX ix_hash_ColdRoomSensorNumberAndTemp UNIQUE
HASH (ColdRoomSensorNumber, Temperature) WITH (BUCKET_COUNT = 10)
GO
--Querying on subset of the hash index key columns.
SELECT ColdRoomSensorNumber, RecordedWhen, ValidFrom, ValidTo
FROM [Warehouse].[ColdRoomTemperatures]
WHERE Temperature = 4.70
GO
Detection 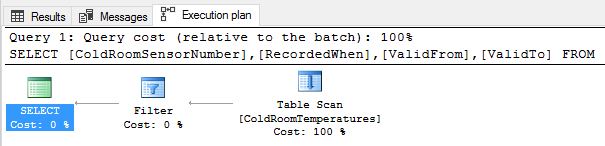
Let’s inspect the query execution plan above. We see a “Table Scan” instead of what we would ideally expect – an Index Seek. Table scans are bad for query performance because the engine is literally scanning the entire table, and as your table grows bigger the impact will be higher. The reason for table scan is that the index cannot just use the lookup column value of ‘Temperature’ to generate the mapping between the lookup value and the hash bucket that the corresponding row maps to. This is the subset key search problem.
Mitigation
Once you figure out that the performance degradation is because of the subset search, the fix is straightforward. There are several options: -
- Either include all the key columns in the query.
- Create another hash index on just that specific key column (‘Temperature’).
- If you suspect the other key column (‘ColdRoomSensorNumber’) to no longer be of interest for point lookups, simply drop and re-create the hash index with just the ‘Temperature’ column.
In the example below, we go for option [2].
--Mitigate by creating another index on just the required key column.
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
ADD INDEX ix_hash_ColdRoomTemp UNIQUE
HASH (Temperature) WITH (BUCKET_COUNT = 10)
GO
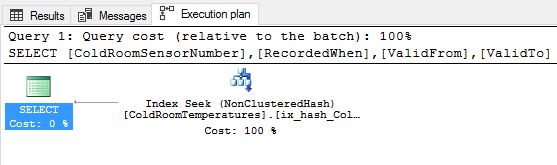
--[CLEANUP STEP]
--Drop the indexes
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
DROP INDEX [ix_hash_ColdRoomSensorNumberAndTemp]
GO
ALTER TABLE [Warehouse].[ColdRoomTemperatures]
DROP INDEX [ix_hash_ColdRoomTemp]
GO
Index #4: Duplicate index key values
A Hash index is more sensitive to duplicate key values than a Nonclustered index. Hence when creating a hash index on a specific key column(s), it is imperative that you evaluate the amount of duplicate index key column values first.
Assume that we create a hash index on the ‘ChillerSensorNumber’ column simply because you have a query that does an index seek with an equality operator on it. Let’s illustrate this with an example: -
--Query doing a point lookup.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData
FROM [Warehouse].[VehicleTemperatures]
WHERE ChillerSensorNumber = 2
GO
--Adding a hash index on a column which contains a lot of duplicates.
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_hash_ChillerSensorNumber
HASH (ChillerSensorNumber) WITH (BUCKET_COUNT = 3)
GO
Detection
Let’s analyze the column ‘ChillerSensorNumber’ further. The column is NON-NULL and only has two values 1 and 2. The total number of rows in the ‘VehicleTemperatures’ table is: 65998. So, there are going to be a lot of duplicate values in this column. Let’s calculate the duplication ratio here using:
--Ratio of total key values to the total number of duplicates.
DECLARE @allValues float(8) = 0.0, @uniqueVals float(8) = 0.0;
SELECT @allValues = COUNT(*) FROM [Warehouse].[VehicleTemperatures] ;
SELECT @uniqueVals = COUNT(*) FROM
(SELECT DISTINCT ChillerSensorNumber
FROM [Warehouse].[VehicleTemperatures] ) as d;
-- If the duplication ratio is > 10.0 and < 100.00, use a Nonclustered index.
SELECT CAST((@allValues / @uniqueVals) as float) as [Total_To_Unique_Ratio];
GO
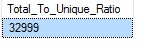
For a hash index, you can also leverage the DMV ‘sys.dm_db_xtp_hash_index_stats’ DMV to view the index stats which provides useful hints:
SELECT hs.object_id, object_name(hs.object_id) AS 'object name', i.name AS 'index name', hs.*
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i ON hs.object_id=i.object_id AND hs.index_id=i.index_id
GO
 As you can see above, the average chain length in this hash index is almost half the total number of rows in the table. Only two buckets are being utilized here and as the table grows bigger the performance will degrade further. Longer the bucket chains, longer it will take for the query engine to walk them to locate the corresponding rows. The idea is to have a larger number of buckets and more importantly a wider distribution of the index keys for constant time lookup.
As you can see above, the average chain length in this hash index is almost half the total number of rows in the table. Only two buckets are being utilized here and as the table grows bigger the performance will degrade further. Longer the bucket chains, longer it will take for the query engine to walk them to locate the corresponding rows. The idea is to have a larger number of buckets and more importantly a wider distribution of the index keys for constant time lookup.
Mitigation
We discussed earlier that, for the column to be fit for a hash index, the ratio should be < 10, which is certainly not the case here. Your next option would be to consider creating a Nonclustered index on the same column. However, for a Nonclustered index, the duplication ratio generally must be > 10 and < 100, which again, is not the case here. So, what do we do in cases where the number of duplicates is too high, and we want to create a Nonclustered index?
Correct. We uniquify the index. In this case, the fix would be to:
- Drop the existing Hash index.
- Create a new NonClustered index on this column but uniquify the NonClustered key column by combining it with a primary key [VehicleTemperatureId] in this case – also make sure that the ordering of key columns is correct since the lookup for a Nonclustered index only supports a subset of leading key columns.
--Drop the unfit hash index.
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX ix_hash_ChillerSensorNumber
GO
--Add the uniquified nonclustered index, with the correct leading column ordering.
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_nc_ChillerSensorNumberAndVehicleTempId
NONCLUSTERED (ChillerSensorNumber, VehicleTemperatureID)
GO
Let’s re-run the query and make sure everything looks okay:
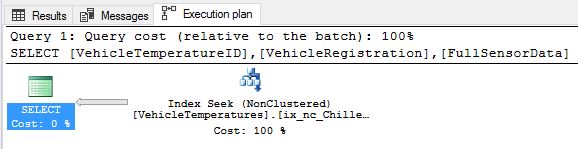
We are doing Index Seeks as expected and the duplication problem has been accounted for.
--[CLEANUP STEP]
--Drop the index
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_nc_ChillerSensorNumberAndVehicleTempId]
GO
Index #5: Range lookups with hash index
Using a Hash index to do a range lookup is not supported. The hash index at the time of creation is configured with a fixed set of buckets and using the hashing function the hash index places each index key column value mapped to a certain hash bucket. However, there is no sense of ordering to the way the keys are stored. This means that a hash index can’t look up a range of values requested efficiently because the query engine can’t possibly tell if it has retrieved all the records in the given query (because there is no ordering). It must scan the whole table and look at all the keys to make sure that all the values that satisfy the range are returned to the user.
Let’s illustrate this with an example below:
--Create a hash index on the 'Temperature' column.
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_hash_Temperature_VehicleTemperatures
HASH (Temperature) WITH (BUCKET_COUNT = 100000)
GO
--Sample query doing a range lookup.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData, ChillerSensorNumber
FROM [Warehouse].[VehicleTemperatures]
WHERE Temperature BETWEEN 3.50 AND 3.90
GO
Detection 
Inspecting the execution plan, we notice that the query engine has reverted to doing table scans because there is no applicable index for such an operation. You may encounter an issue like this either because: -
- The hash index was chosen incorrectly to begin with.
- The reason why the index was created originally is obsolete now – for e.g., this query used to do point lookups.
- Both point lookups and range lookups are done on this key column and that a Nonclustered index is missing.
Mitigation
We can mitigate this by either: -
- Dropping the hash index and creating a Nonclustered index.
- Add a Nonclustered index on the same key column in addition to the Hash Index (in case you have queries that also do point lookups on this key column).
In this case we will simply create a new Nonclustered Index on the ‘Temperature’ key column.
--Add a Nonclustered index
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_nc_Temperature_VehicleTemperatures
NONCLUSTERED (Temperature)
GO
Let’s run the query again and inspect the query plan below: -
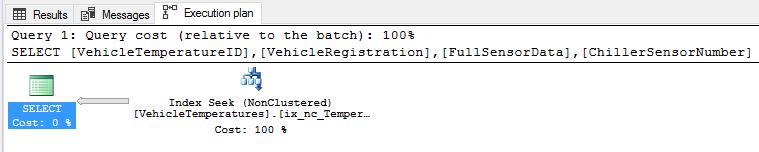
Success! Rightly so the table scan has disappeared, and the query engine is back to performing an index seek for the given query.
--[CLEANUP STEP]
--Drop the indexes
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_hash_Temperature_VehicleTemperatures]
GO
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_nc_Temperature_VehicleTemperatures]
GO
Nonclustered and Hash Index in conjunction
Often you may encounter a scenario where you have queries that need to do both a point and a range lookup on the same key column(s). In such cases, it is indeed possible to create both a hash and a Nonclustered index on the same key column. Let’s walk through an example: -
Assume that you have these two queries that lookup records based on the ‘RecordedWhen’ key column. One does a range lookup on it and the other a point lookup. Let us execute these two in order and view the execution plans.
[1]
--Sample query doing a range lookup.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData, RecordedWhen
FROM [Warehouse].[VehicleTemperatures]
WHERE RecordedWhen BETWEEN '2016-01-01 07:24:42.0000000' AND '2016-01-01 07:44:41.0000000'
ORDER BY RecordedWhen ASC
GO

[2]
--Sample query doing a point lookup.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData, RecordedWhen
FROM [Warehouse].[VehicleTemperatures]
WHERE RecordedWhen = '2016-01-01 07:24:42.0000000'
GO
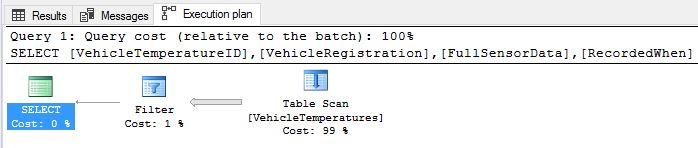
Executing these queries above and inspecting the query plan you will notice that both the queries are currently doing a table scan. Table scan is bad for query performance because the lookup requires scanning the entire base table. As your table grows, it will take longer to scan your table and your query performance will deteriorate further. It is obvious at this point that an index is required. Since a Nonclustered index supports both point and range lookups, let’s start with that. Mind you, in the real world, you should also evaluate the number of duplicates in the “RecordedWhen” column. Also, recall that, if the average number of duplicates in the index key column is >10x and < 100x, a Nonclustered index is generally fine. If the average number of duplicates are higher, then you might want to consider “Uniquifying” the Nonclustered index.
Below, we create a Nonclustered index on the ‘RecordedWhen’ column with the correct ORDER specified because our range lookup seeks records in ASCENDING order in query [1].
--Add a nonclustered index with ASCENDING order.
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_nc_RecordedWhen_Asc
NONCLUSTERED (RecordedWhen ASC)
GO
Let us execute queries [1] and [2] again and inspect the corresponding execution plans.
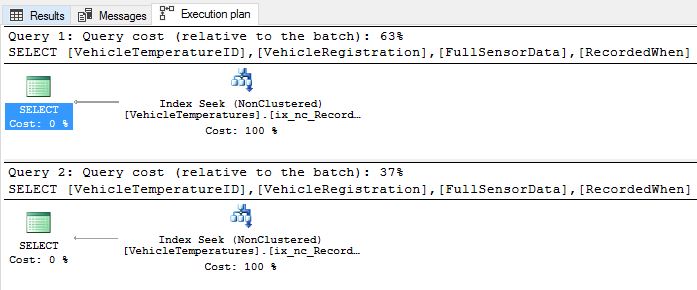
Excellent! As expected we got rid of the table scans and instead the query execution engine now perform index seeks, leveraging the Nonclustered index, we configured above. This should greatly improve the query performance compared to table scans.
Since query [2] does a point lookup, you can further optimize the query performance by using a hash index. Before we do so, let’s first analyze the key column ‘RecordedWhen’ on which the lookup is performed, a bit more to verify whether it makes sense to create a hash index on it.
Evaluating Duplicates:
--Ratio of total key values to the total number of duplicates.
DECLARE @allValues float(8) = 0.0, @uniqueVals float(8) = 0.0;
SELECT @allValues = COUNT(*) FROM [Warehouse].[VehicleTemperatures] ;
SELECT @uniqueVals = COUNT(*) FROM
(SELECT DISTINCT RecordedWhen
FROM [Warehouse].[VehicleTemperatures] ) as rct;
-- If (All / Unique) >= 10.0, use a nonclustered index, not a hash.
SELECT CAST((@allValues / @uniqueVals) as float) as [Total_To_Unique_Ratio];
GO
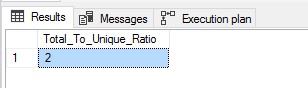
Based on our learnings from the previous blog and this, we know that with a ratio of < 10, the column is indeed, fit for a hash index. Let’s configure the hash index for the column keeping this in mind.
Bucket Count:
Let us evaluate a reasonable BUCKET_COUNT for this column. The table has 65998 records. Also assume that there is also going to be business growth in the future. With that in mind, let us leave some headroom for new duplicates that might be entered in this column in the future. Typically, we can set the BUCKET_COUNT as:
BUCKET_COUNT = 2 x (Total number of key columns) = 2 x 65998 = 131996. We can round this off to 140000 for convenience.
Next, to demonstrate the advantage of optimizing point lookup operation using a Hash index when applicable over a Nonclustered Index, let’s wrap query [2] in a loop.
[3]
--Query below executes a point lookup 50 times and measures the execution time.
DECLARE @I TINYINT;
DECLARE @startExecution DATETIME;
DECLARE @endExecution DATETIME;
SET @I = 50;
SET @startExecution = GETDATE();
WHILE @I > 0
BEGIN
SET @I-=1;
--Sample query doing a point lookup.
SELECT VehicleTemperatureID, VehicleRegistration, FullSensorData, RecordedWhen
FROM [Warehouse].[VehicleTemperatures]
WHERE RecordedWhen = '2016-01-01 07:24:42.0000000'
END
SET @endExecution = GETDATE();
SELECT DATEDIFF(millisecond,@startExecution,@endExecution) AS elapsed_time_in_ms
GO
Executing query [3] with a Nonclustered index took about 17820ms on my machine.
Now drop the Nonclustered index:
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_nc_RecordedWhen_Asc]
GO
Next, create a new Hash index with the bucket count we settled on above:
--Add a hash index with the appropriate BUCKET_COUNT.
ALTER TABLE [Warehouse].[VehicleTemperatures]
ADD INDEX ix_hash_RecordedWhen
HASH (RecordedWhen) WITH (BUCKET_COUNT=140000)
GO
Executing query [3] again this time with a Hash index, I observed 16024ms on my machine. So, Hash index was about 10% faster than a Nonclustered index for a point lookup on the ‘RecordedWhen’ column. As the amount of data increases, the performance of the Hash index over a Nonclustered index in this case, will get better.
Note: You may not observe a difference on your machine. As advised above, you can try this out with a larger number of iterations or an even larger bucket count.
So, it is clear from above that optimizing with a Hash index is a good idea when applicable. Another good practice to follow once you create a Hash index, is to check the hash index stats. You can do that by:
SELECT hs.object_id, object_name(hs.object_id) AS 'object name', i.name AS 'index name', hs.*
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i ON hs.object_id=i.object_id AND hs.index_id=i.index_id
GO
 From above we see that the hash index average chain length is short and there are a good number of empty hash buckets for future growth. These are signs of a well configured hash index with ample room for future growth.
From above we see that the hash index average chain length is short and there are a good number of empty hash buckets for future growth. These are signs of a well configured hash index with ample room for future growth.
--[CLEANUP STEP]
--Drop the index
ALTER TABLE [Warehouse].[VehicleTemperatures]
DROP INDEX [ix_hash_RecordedWhen]
GO
Monitoring your query performance
You can attain substantial performance gains over disk based tables when using memory-optimized tables if you use the right set of indexes and configure those indexes correctly. Note that applications in the practical world change depending on changing business requirements and so do your queries. That is why, over time, you may notice a degradation in query performance with your memory-optimized table(s) and some of the common reasons why you may notice such performance degradations are listed below: -
- Stale Index – With changing application requirements, your queries change and so often, the indexes that were configured in accordance to those queries also need to be updated. For example:
- A hash index was added on a key column because you had queries that did point lookups using equality operator on that column. However, those queries have been altered now and instead do a range lookup or perhaps an ordered scan on the same key column.
- For a Nonclustered index, the query that used to retrieve data aligned to the ORDER specified at the time of Nonclustered index creation is no longer applicable.
- Incorrect Index - The index was chosen incorrectly to begin with or configured incorrectly.
- Index Reconfiguration – Your choice of index was correct at the time of choosing however the number of duplicates in the index key column have increased significantly from the time of index creation. In such cases, for a Nonclustered index you might have to consider “Uniquifying” the index and for a Hash index consider reconfiguring the bucket count or perhaps switch to a Nonclustered index.
Evidently from above, as a good practice you should monitor your queries and the health of your indexes in general to catch any regressions and fix them pro-actively. In SQL Server, there are several ways to keep tabs on your query performance and your indexes in general, to make sure your queries are always performing optimally.
Monitoring using query store
Starting SQL Server 2016 and in Azure SQL Database you can now very efficiently monitor the performance of your queries to memory-optimized tables using Query Store.
When transitioning from disk-based to memory-optimized tables we highly recommend turning on Query Store for the database before you do so. That way you can get a baseline of as to how your queries are currently performing with disk based tables. You can then go about converting your disk based table to a memory-optimized table. Your queries that hit this table can be tracked by using the “Tracked Queries” feature of Query Store. Once your table is memory-optimized, we recommend checking the “Top Resource Consuming Queries” feature. The report should show you queries that are consuming a high amount of resources. And tracked queries can give you an idea of how the behaviour of your query has altered from the past.
Once you migrate your table from disk-based to memory-optimized, chances are, you are going to keep tuning your index configuration until you attain the most optimal performance. Keeping that in mind, we recommend you to check out the “Regressed Queries” feature of Query Store for your queries that hit the memory-optimized table. This will come in especially handy and will help you catch any regressions early on.
Tip: You can use several Query Store views to dig out more information about your queries. For e.g., You can use queries such as the one mentioned below, to locate your queries with the longest average execution time within the last 1 hour:
SELECT TOP 10 rs.avg_duration, qt.query_sql_text, q.query_id,
qt.query_text_id, p.plan_id, GETUTCDATE() AS CurrentUTCTime,
rs.last_execution_time
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE rs.last_execution_time > DATEADD(hour, -1, GETUTCDATE())
ORDER BY rs.avg_duration DESC
GO
You can find more such sample queries to get useful information out of Query Store here.
Monitoring using dynamic management views (DMVs) and stored procedures
If your application is based on releases prior to SQL Server 2016, you won’t have Query Store at your disposal. However, you can utilize DMVs to monitor the query performance. To begin with, you can start with: sys.dm_exec_query_stats. This DMV provides an aggregated view of performance statistics for the cached query plans and information at the query level noting important statistics such as the number of reads, writes, execution time etc.
For your queries that are wrapped inside Natively Compiled stored procedures, you can enable statistics collection using the sys.sp_xtp_control_proc_exec_stats . You can also use, sys.dm_exec_procedure_stats to monitor performance at the procedure level . To enable query level statistics for your natively compiled stored procedures you can use sys.sp_xtp_control_query_exec_stats and use sys.dm_exec_query_stats for general monitoring.
Monitoring using Extended Events (or X-Events)
You can leverage Extended Events to monitor your queries to memory-optimized tables, like the way you would for traditional disk-based tables. If you are leveraging Natively Compiled stored procedures, you can create an XEvent session on “sp_statement_completed” and add a filter for the [object_id] that corresponds to the natively compiled stored procedure.
For Interop stored procedures, there is no difference between the queries that do and queries that do not touch memory-optimized tables. You would use “sql_statement_completed” with ad hoc query statements, and “sp_statement_completed” for statements wrapped inside the stored procedures.
For more information, we recommend you to read: Monitoring Performance of Natively Compiled Stored Procedures
Conclusion
To summarize, you've seen how the query performance problems caused by a sub-optimal index configuration or by choosing the wrong index type can be identified, troubleshooted and resolved. You've also seen how you can monitor your query performance and pro-actively fix any regressions. We sincerely hope that the guidelines and techniques described in the blog post series (Part 1 and Part 2) goes some way into helping you identify the right indexing scheme for your memory-optimized table, configure them optimally, detect and troubleshoot query performance issues and achieve optimal performance. Query performance tuning is always an iterative process. We recommend that you try, test, deploy, monitor and repeat until the desired query performance with memory-optimized tables is achieved.
As a next step, we encourage you to read through some of the relevant articles below to further gain additional understanding of the topics covered in Part 1 & 2 of this blog post.
- Planning adoption of In-Memory OLTP
- Nonclustered Indexes
- Hash Indexes
- Natively Compiled Stored Procedures
- Monitoring Performance of Natively Compiled Stored Procedures
- Memory-optimized Dynamic Management Views
- Query Store
- Query Store in Azure SQL DB
Comments
- Anonymous
November 15, 2017
Thanks very much for a great post. Only one point that I wanted to clarify regarding the note about the direction of the sort-order having a role in merge joins. This will only be relevant for interop, because at this point in time, native modules only supported nested loop joins. - Anonymous
November 15, 2017
nice.I hope this tips by auto tuning by create/drop these index, and Query advisors.