Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
For SQL Server 2017 and Azure SQL Database, the Microsoft Query Processing team is introducing a new set of adaptive query processing improvements to help fix performance issues that are due to inaccurate cardinality estimates. Improvements in the adaptive query processing space include batch mode memory grant feedback, batch mode adaptive joins, and interleaved execution. In this post, we’ll introduce batch mode adaptive joins.
We have seen numerous cases where providing a specific join hint solved query performance issues for our customers. However, the drawback of adding a hint is that we remove join algorithm decisions from the optimizer for that statement. While fixing a short-term issue, the hard-coded hint may not be the optimal decision as data distributions shift over time.
Another scenario is where we do not know up front what the optimal join should be, for example, with a parameter sensitive query where a low or high number of rows may flow through the plan based on the actual parameter value.
With these scenarios in mind, the Query Processing team introduced the ability to sense a bad join choice in a plan and then dynamically switch to a better join strategy during execution.
The batch mode adaptive joins feature enables the choice of a hash join or nested loop join method to be deferred until the after the first input has been scanned. We introduce a new Adaptive Join operator. This operator defines a threshold that will be used to decide when we will switch to a nested loop plan.
Note: To see the new Adaptive Join operator - download SQL Server Management Studio - 17.0.
How it works at a high level:
- If the row count of the build join input is small enough that a nested loop join would be more optimal than a hash join, we will switch to a nested loop algorithm.
- If the build join input exceeds a specific row count threshold, no switch occurs and we will continue with a hash join.
The following query is used to illustrate an adaptive join example:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
The query returns 336 rows. Enabling Live Query Statistics we see the following plan:
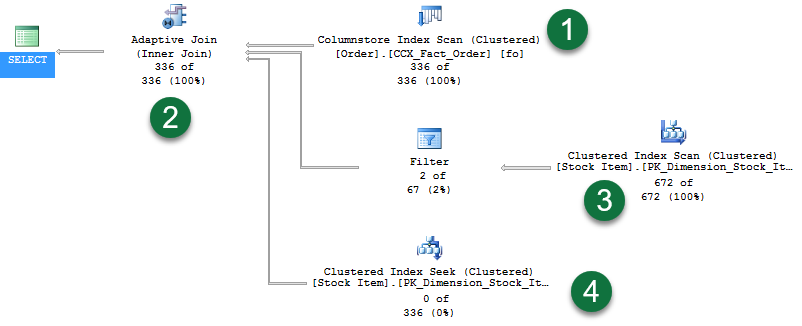
Walking through the noteworthy areas:
- We have a Columnstore Index Scan used to provide rows for the hash join build phase.
- We have the new Adaptive Join operator. This operator defines a threshold that will be used to decide when we will switch to a nested loop plan. For our example, the threshold is 78 rows. Anything with >= 78 rows will use a hash join. If less than the threshold, we’ll use a nested loop join.
- Since we return 336 rows, we are exceeding the threshold and so the second branch represents the probe phase of a standard hash join operation. Notice that Live Query Statistics shows rows flowing through the operators – in this case “672 of 672”.
- And the last branch is our Clustered Index Seek for use by the nested loop join had the threshold not been exceeded. Notice that we see “0 of 336” rows displayed (the branch is unused).
Now let’s contrast the plan with the same query, but this time for a Quantity value that only has one row in the table:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
The query returns one row. Enabling Live Query Statistics we see the following plan:
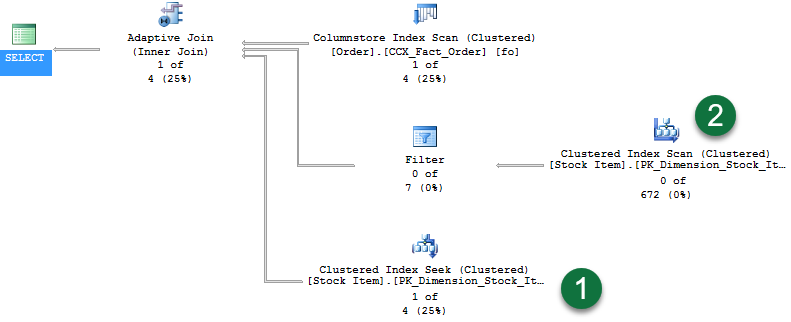
Walking through the noteworthy areas:
- With one row returned, you see the Clustered Index Seek now has rows flowing through it.
- And since we did not continue with the hash join build phase, you’ll see zero rows flowing through the second branch.
How do I enable batch mode adaptive joins?
To have your workloads automatically eligible for this improvement, enable compatibility level 140 for the database in SQL Server 2017 CTP 2.0 or greater. This improvement will also be surfacing in Azure SQL Database.
What statements are eligible for batch mode adaptive joins?
A few conditions make a logical join eligible for a batch mode adaptive join:
- The database compatibility level is 140
- The join is eligible to be executed both by an indexed nested loop join or a hash join physical algorithm
- The hash join uses batch mode – either through the presence of a Columnstore index in the query overall or a Columnstore indexed table being referenced directly by the join
- The generated alternative solutions of the nested loop join and hash join should have the same first child (outer reference)
If an adaptive join switches to a nested loop operation, do we have to rescan the join input?
No. The nested loop operation will use the rows already read by the hash join build.
What determines the adaptive join threshold?
We look at estimated rows and the cost of a hash join vs. nested loop join alternative and find an intersection where the cost of a nested loop exceeds the hash join alternative. This threshold cost is translated into a row count threshold value.
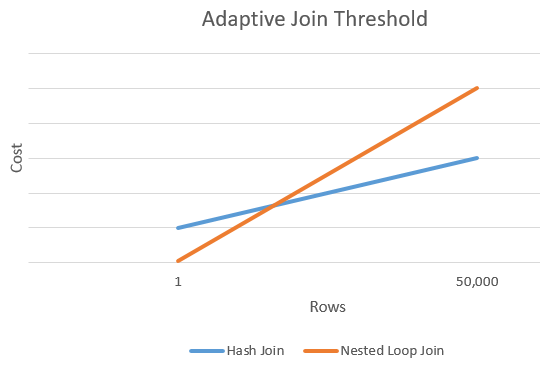
The prior chart shows an intersection between the cost of a hash join vs. the cost of a nested loop join alternative. At this intersection point, we determine the threshold.
What performance improvements can we expect to see?
Performance gains occur for workloads where, prior to adaptive joins being available, the optimizer chooses the wrong join type due to cardinality misestimates. For example, one of our customers saw a 20% improvement with one of the candidate workloads. And for one of our internal Microsoft customers, they saw the following results:
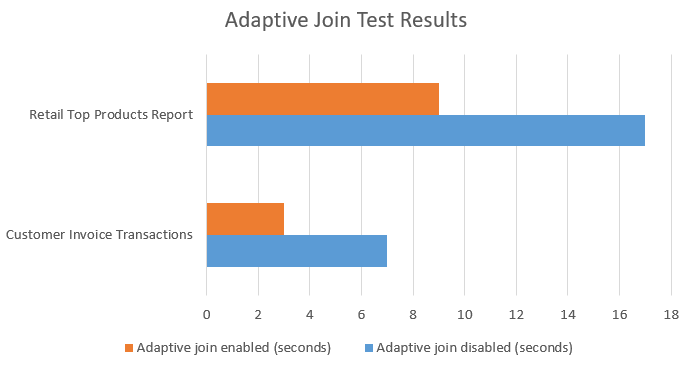
Workloads with big oscillations between small and large input Columnstore index scans joined to other tables will benefit the most from this improvement.
Any overhead of using batch mode adaptive joins?
Adaptive joins will introduce a higher memory requirement than an index nested loop join equivalent plan. The additional memory will be requested as if the nested loop was a hash join. With that additional cost comes flexibility for scenarios where row counts may fluctuate in the build input.
How do batch mode adaptive joins work for consecutive executions once the plan is cached?
Batch mode adaptive joins will work for the initial execution of a statement, and once compiled, consecutive executions will remain adaptive based on the compiled adaptive join threshold and the runtime rows flowing through the build phase of the Columnstore Index Scan.
How can I track when batch mode adaptive joins are used?
As shown earlier, you will see the new Adaptive Join operator in the plan and the following new attributes:
| Plan attribute | Description |
| AdaptiveThresholdRows | Shows the threshold use to switch from a hash join to nested loop join. |
| EstimatedJoinType | What we think the join type will be. |
| ActualJoinType * | In an actual plan, shows what join algorithm was ultimately chosen based on the threshold. |
* Arriving post-CTP 2.0.
What does the estimated plan show?
We will show the adaptive join plan shape, along with a defined adaptive join threshold and estimated join type.
Will Query Store capture and be able to force a batch mode adaptive join plan?
Yes.
Will you be expanding the scope of batch mode adaptive joins to include row mode?
This first version supports batch mode execution, however we are exploring row mode as a future possibility as well.
Thanks for reading, and stay tuned for more blog posts regarding the adaptive query processing feature family!
Comments
- Anonymous
April 20, 2017
Good stuff!What about join threshold? how it is calculated? Finding the right threshold will be the key point.- Anonymous
April 21, 2017
The comment has been removed
- Anonymous
- Anonymous
April 21, 2017
Sounds great! 2 questions though- Will there be extended events and performance counters to track it? - And how expensive/cheap is compared to OPTION(RECOMPILE)?Thanks.- Anonymous
April 21, 2017
The comment has been removed
- Anonymous
- Anonymous
April 22, 2017
The comment has been removed- Anonymous
April 23, 2017
The comment has been removed- Anonymous
April 23, 2017
The comment has been removed
- Anonymous
- Anonymous
- Anonymous
May 02, 2017
The comment has been removed- Anonymous
May 08, 2017
Hi Sateesh,Looks like this is a SSMS 17 issue that will be resolved in the next update (SSMS 17 connected to older versions).Thanks for the heads-up,Joe
- Anonymous