Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
For SQL Server vNext and Azure SQL Database, the Microsoft Query Processing team is introducing a new set of adaptive query processing improvements to help fix performance issues that are due to poor cardinality estimates. Improvements in the adaptive query processing space include batch mode memory grant feedback, batch mode adaptive joins, and interleaved execution. In this post, we’ll introduce interleaved execution.
SQL Server has historically used a unidirectional “pipeline” for optimizing and executing queries. During optimization, the cardinality estimation process is responsible for providing row count estimates for operators in order to derive estimated costs. The estimated costs help determine which plan gets selected for use in execution. If cardinality estimates are incorrect, we will still end up using the original plan despite the poor original assumptions.
Interleaved execution changes the unidirectional boundary between the optimization and execution phases for a single-query execution and enables plans to adapt based on the revised estimates. During optimization if we encounter a candidate for interleaved execution, which for this first version will be multi-statement table valued functions (MSTVFs) , we will pause optimization, execute the applicable subtree, capture accurate cardinality estimates and then resume optimization for downstream operations.

While many DBAs are aware of the negative effects of MSTVFs, we know that their usage is still widespread. MSTVFs have a fixed cardinality guess of “100” in SQL Server 2014 and SQL Server 2016, and “1” for earlier versions. Interleaved execution will help workload performance issues that are due to these fixed cardinality estimates associated with multi-statement table valued functions.
The following is a subset of an overall execution plan that shows the impact of fixed cardinality estimates from MSTVFs (below shows Live Query Statistics output, so you can see the actual row flow vs. estimated rows):
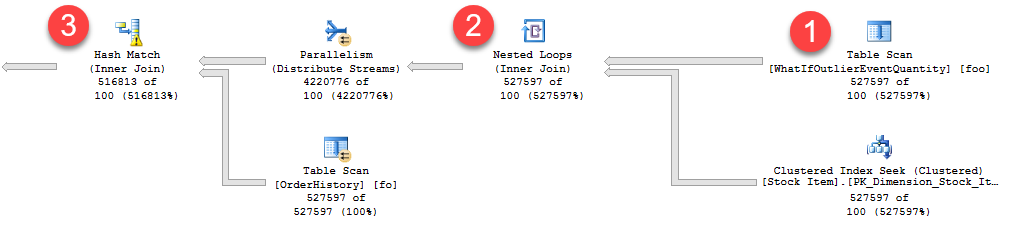
Three noteworthy areas in the plan are numbered 1 through 3:
- We have a MSTVF Table Scan that has a fixed estimate of 100 rows. But for this example, there are 527,592 flowing through this MSTVF Table Scan as seen in Live Query Statistics via the “527597 of 100” actual of estimated – so our fixed estimate is significantly skewed.
- For the Nested Loops operation, we’re still assuming only 100 rows are flowing through the outer reference. Given the high number of rows actually being returned by the MSTVF, we’re likely better off with a different join algorithm altogether.
- For the Hash Match operation, notice the small warning symbol, which in this case is indicating a spill to disk.
Now contrast the prior plan with the actual plan generated with interleaved execution enabled:
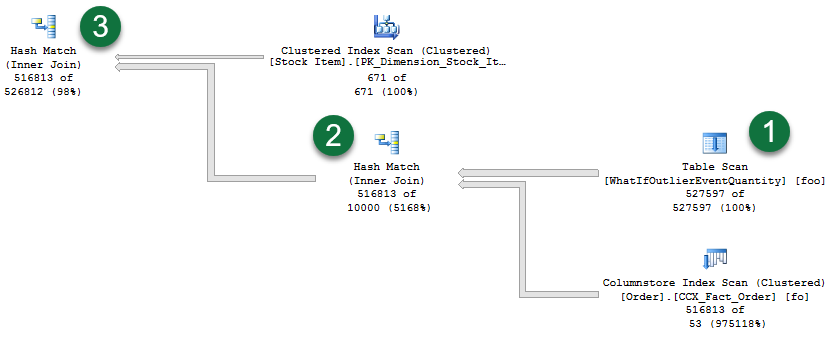
Three noteworthy areas in the plan are numbered 1 through 3:
- Notice that the MSTVF table scan now reflects an accurate cardinality estimate. Also notice the re-ordering of this table scan and the other operations.
- And regarding join algorithms, we have switched from a Nested Loop operation to a Hash Match operation instead, which is more optimal given the large number of rows involved.
- Also notice that we no longer have spill-warnings, as we’re granting more memory based on the true row count flowing from the MSTVF table scan.
What makes a query eligible for interleaved execution?
For the first version of interleaved execution, MSTVF referencing statements must be read-only and not part of a data modification operation. Also, the MSTVFs will not be eligible for interleaved execution if they are used on the inside of a CROSS APPLY.
How do I enable interleaved execution?
To have your workloads automatically eligible for this improvement, enable compatibility level 140 for the database in SQL Server 2017 CTP 2.0 or greater and in SQL Azure Database.
What performance improvements can we expect to see?
This depends on your workload characteristics – however we have seen the greatest improvements for scenarios where MSTVFs output many rows that then flow to other operations (for example, joins to other tables or sort operations).
In one example, we worked with a financial services company that used two MSTVF-referencing queries and they saw the following improvements:
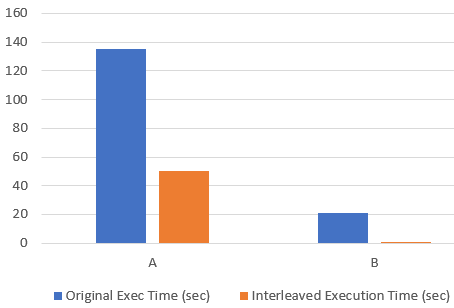
For MSTVF “A”, the original query ran in 135 seconds and the plan with interleaved execution enabled ran in 50 seconds. For MSTVF “B”, the original query ran in 21 seconds and the plan with interleaved execution enabled ran in 1 second.
A special thanks to Arun Sirpal, the Senior Database Administrator who conducted this testing and worked with our team during private preview!
In general, the higher the skew between the estimated vs. actual number of rows, coupled with the number of downstream plan operations, the greater the performance impact.
What is the overhead?
The overhead should be minimal-to-none. MSTVFs were already being materialized prior to the introduction of interleaved execution, however the difference is that now we’re now allowing deferred optimization and are then leveraging the cardinality estimate of the materialized row set.
What could go wrong?
As with any plan affecting changes, it is possible that some plans could change such that with a better cardinality estimate we get a worse plan. Mitigation can include reverting the compatibility level or using Query Store to force the non-regressed version of the plan.
How does interleaved execution work for consecutive executions?
Once an interleaved execution plan is cached, the plan with the revised estimates on the first execution is used for consecutive executions without re-instantiating interleaved execution.
How can I track when interleaved execution is used?
You can see usage attributes in the actual query execution plan:
| Plan attribute | Description |
| ContainsInterleavedExecutionCandidates | Applying to the QueryPlan node, when “true”, it means the plan contains interleaved execution candidates. |
| IsInterleavedExecuted | The attribute is inside the RuntimeInformation element under the RelOp for the TVF node. When “true”, it means the operation was materialized as part of an interleaved execution operation. |
You can also track interleaved execution occurrences via the following XEvents:
| XEvent | Description |
| interleaved_exec_status | This event fires when interleaved execution is occurring. |
| interleaved_exec_stats_update | This event describes the cardinality estimates updated by interleaved execution. |
| Interleaved_exec_disabled_reason | This event fires when a query with a possible candidate for interleaved execution does not actually get interleaved execution. |
What does the estimated plan show?
A query must be executed in order to allow interleaved execution to revise MSTVF cardinality estimates. However, the estimated execution plan will still show when there are interleaved execution candidates via the ContainsInterleavedExecutionCandidates attribute.
What if the plan is manually cleared or automatically evicted from cache?
Upon query execution, there will be a fresh compilation that uses interleaved execution.
Will this improvement work if I use OPTION (RECOMPILE)?
Yes. A statement using OPTION(RECOMPILE) will create a new plan using interleaved execution and not cache it.
Will Query Store capture and be able to force an interleaved execution plan?
Yes. The plan will be the version that has corrected cardinality estimates based on initial execution.
Will you be expanding the scope of interleaved execution in a future version beyond MSTVFs?
Yes. We are looking at expanding to additional problematic estimation areas.
Thanks for reading, and stay tuned for more blog posts regarding the adaptive query processing feature family!
Comments
- Anonymous
April 22, 2017
Any reason ,these features not being there in sqlserver- Anonymous
April 23, 2017
Hi John,These features are surfaced in SQL Server 2017 and eventually Azure SQL Database.- Anonymous
April 23, 2017
I am Sorry,I meant to say,SQLServer not sqlserver vnext (which I assume is 2017).I assume normal SQLServer(say SQL 2016) and vnext are entirely different and will have different release cycles .- Anonymous
April 24, 2017
Hi John,Correct - these features will be available in SQL Server 2017 and later. No plans for backward porting to 2016.Thanks,Joe- Anonymous
April 25, 2017
Thank you
- Anonymous
- Anonymous
- Anonymous
April 24, 2017
Joseph,Does this mean that these features will actually surface in SQL Server 2017 before Azure SQL Databases?- Anonymous
April 24, 2017
The comment has been removed
- Anonymous
- Anonymous
- Anonymous