Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Last year SQL Server 2017 and Azure SQL Database introduced query processing improvements that adapt optimization strategies to your application workload’s runtime conditions. These improvements included: batch mode adaptive joins, batch mode memory grant feedback, and interleaved execution for multi-statement table valued functions.
In SQL Server 2019 preview, we are further expanding query processing capabilities with several new features under the Intelligent Query Processing (QP) feature family. In this blog post we’ll discuss Scalar T-SQL UDF Inlining, one of these Intelligent QP features that is now available in public preview with SQL Server 2019 CTP 2.1.
T-SQL UDFs are an elegant way to achieve code reuse and modularity across SQL queries. Some computations (such as complex business rules) are easier to express in imperative UDF form. UDFs help in building up complex logic without requiring expertise in writing complex SQL queries. Despite these benefits, their inferior performance discourages or even prohibits their use in many situations.
The goal of the Scalar UDF inlining feature is to improve performance of queries that invoke scalar UDFs, where UDF execution is the main bottleneck.
Why are scalar UDFs slow today?
Years ago, when scalar UDFs were introduced1 , they opened a way for users to express business logic using familiar constructs such as variable assignments, IF-ELSE branching, loops etc. Consider the following scalar UDF that, given a customer key, determines the service category for that customer. It arrives at the category by first computing the total price of all orders placed by the customer using a SQL query, and then uses an IF-ELSE logic to decide the category based on the total price.
CREATE OR ALTER FUNCTION dbo.customer_category(@ckey INT)
RETURNS CHAR(10) AS
BEGIN
DECLARE @total_price DECIMAL(18,2);
DECLARE @category CHAR(10);
SELECT @total_price = SUM(O_TOTALPRICE) FROM ORDERS WHERE O_CUSTKEY = @ckey;
IF @total_price < 500000
SET @category = 'REGULAR';
ELSE IF @total_price < 1000000
SET @category = 'GOLD';
ELSE
SET @category = 'PLATINUM';
RETURN @category;
END
This is very handy as a UDF because it can now be used in multiple queries, and if the threshold values need to be updated, or a new category needs to be added, the change must be made only in the UDF. Now, consider a simple query that invokes this UDF.
-- Q1:
SELECT C_NAME, dbo.customer_category(C_CUSTKEY) FROM CUSTOMER;
The execution plan for this query in SQL Server 2017 (compatibility level 140 and earlier) is as follows:
As the plan shows, SQL Server adopts a simple strategy here: for every tuple in the CUSTOMER table, invoke the UDF and output the results. This strategy is quite naïve and inefficient. Such queries end up performing badly due to the following reasons.
- Iterative invocation: UDFs are invoked in an iterative manner, once per qualifying tuple. This incurs additional costs of repeated context switching due to function invocation. Especially, UDFs that execute SQL queries in their body are severely affected.
- Lack of costing: During optimization, only relational operators are costed, while scalar operators are not. Prior to the introduction of scalar UDFs, other scalar operators were generally cheap and did not require costing. A small CPU cost added for a scalar operation was enough.
- Interpreted execution: UDFs are evaluated as a batch of statements, executed statement-by-statement. Note that each statement itself is compiled, and the compiled plan is cached. Although this caching strategy saves some time as it avoids recompilations, each statement executes in isolation. No cross-statement optimizations are carried out.
- Serial execution: SQL Server does not use intra-query parallelism in queries that invoke UDFs. There are several reasons for this, and it might be a good topic for another blog post.
What changes with the new Scalar UDF inlining feature?
With this new feature, scalar UDFs are transformed into scalar expressions or scalar subqueries which are substituted in the calling query in place of the UDF operator. These expressions and subqueries are then optimized. As a result, the query plan will no longer have a user-defined function operator, but its effects will be observed in the plan, like views or inline TVFs. To understand this better, let’s first consider a simple example.
-- Q2 (Query with no UDF):
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (L_EXTENDEDPRICE *(1 - L_DISCOUNT))
FROM LINEITEM INNER JOIN ORDERS ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
This query computes the sum of discounted prices for line items and presents the results grouped by the shipping date and shipping priority. The expression L_EXTENDEDPRICE *(1 - L_DISCOUNT) is the formula for the discounted price for a given line item. It makes sense to create a function that computes it so that it could be used wherever discounted price needs to be computed.
-- Scalar UDF to encapsulate the computation of discounted price
CREATE FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2) AS
BEGIN
RETURN @price * (1 - @discount);
END
Now, we can modify query Q2 to use this UDF as follows:
-- Q3 (Query with UDF):
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM INNER JOIN ORDERS ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
Due to the reasons outlined earlier, Q3 performs poorly as compared to Q2. Now, with scalar UDF inlining, SQL Server substitutes the scalar expression directly into the query, and thereby overcomes the limitations of UDF evaluation. The results of running this query2 are shown in the below table:
Query: |
Q2 (No UDF) | Q3 without inlining | Q3 with inlining |
| Execution Time: | 1.6 seconds | 29 minutes 11 seconds | 1.6 seconds |
As we can see, Q3 without inlining is prohibitively slow compared to Q2. But with scalar UDF inlining, the performance of Q3 is on par with Q2, with almost no overheads at all! We get all the benefits of UDFs, without compromising on query performance. Moreover, observe that there were no modifications made to the query or the UDF; it just runs faster!
What about more complex, multi-statement scalar UDFs?
With scalar UDF inlining, SQL Server can now inline multi-statement UDFs also. Let us consider the function dbo.customer_category and query Q1 given above to understand how this works. For query Q1, the query plan with the UDF inlined looks as below.
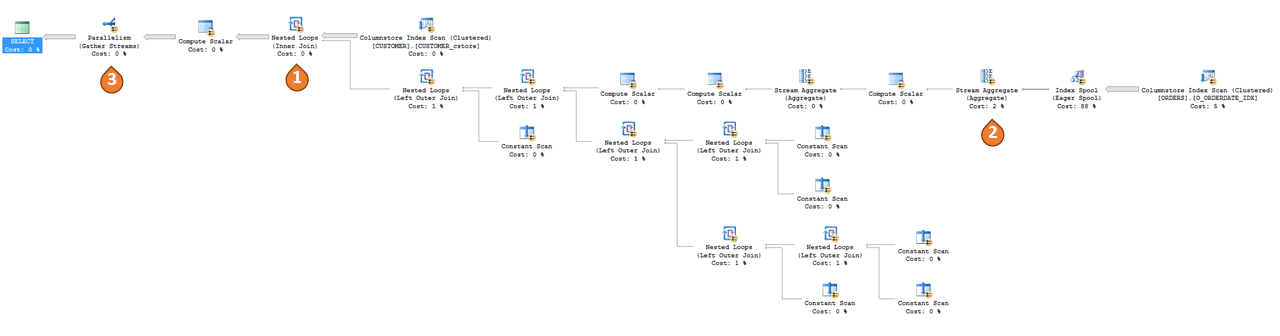
Here are some key observations from the above plan:
- SQL Server has inferred the implicit join between CUSTOMER and ORDERS and made that explicit via a Join operator.
- SQL Server has also inferred the implicit GROUP BY O_CUSTKEY on ORDERS and has used the Index Spool and Stream Aggregate to implement it.
- SQL Server is using parallelism across all operators.
Depending upon the complexity of the logic in the UDF, the resulting query plan might also get bigger and more complex. As we can see, the operations inside the UDF are now no longer a black box, and hence the query optimizer is able to cost and optimize those operations. Also, since the UDF is no longer in the plan, iterative UDF invocation is replaced by a plan that avoids function call overhead.
What are the advantages of scalar UDF inlining?
As described above, scalar UDF inlining enables users to use scalar UDFs without worrying about the performance overheads. Thereby, this encourages users to build modular, reusable applications.
In addition to resulting in set-oriented, parallel plans for queries with UDFs, this feature has another advantage. Since scalar UDFs are no longer interpreted (i.e. executed statement-by-statement), it enables optimizations such as dead code elimination, constant folding and constant propagation. Depending upon the UDF, these techniques might lead to simpler, more efficient query plans.
What kind of scalar UDFs are inlineable?
A fairly broad set of scalar UDFs are inlineable currently. There are a few limitations such as the T-SQL constructs allowed in the UDF. Please refer to this page for a complete description of "inlineability" of scalar UDFs.
How do I know if my scalar UDF is inlineable?
The sys.sql_modules catalog view includes a property called “is_inlineable”, which indicates whether a UDF is inlineable or not. A value of 1 indicates that it is inlineable, and 0 indicates otherwise. This property will also have a value of 1 for inline table-valued functions, since they are inlineable by definition.
When is scalar UDF inlining beneficial? And when is it not?
As mentioned earlier, this feature is most beneficial when UDF execution is the main bottleneck in a query. If the bottleneck is elsewhere, there may not be any benefits. For instance, if a scalar UDF is invoked only a few times in the query, then inlining might not lead to any gains. There could be a few other scenarios where inlining might not be beneficial. Inlining can be turned off for such UDFs using the INLINE=OFF option in the CREATE/ALTER FUNCTION statement.
I’d like to test this new feature. How do I get started?
This feature is enabled by default under database compatibility level 150. To enable the public preview of scalar UDF inlining in SQL Server 2019 CTP 2.1, enable database compatibility level 150 for the database you are connected to when executing the query:
USE [master];
GO
ALTER DATABASE [DatabaseName] SET COMPATIBILITY_LEVEL = 150;
GO
I’d like to know more about this feature. Where can I find more details?
More information about this feature can be found in this page. We will be updating this space with more links to documentation and examples as they become available. The underlying techniques that describe how this feature works are described in a recent research publication titled "Froid: Optimization of Imperative programs in a Relational Database".
Where can I provide feedback?
If you have feedback on this feature or other features in the Intelligent QP feature family, please email us at IntelligentQP@microsoft.com.
Footnotes:
- Scalar UDFs have been around for a while in SQL Server, at least since SQL Server 2000!
- These numbers are based on a TPC-H 10GB CCI dataset, running on a machine with dual processor (12 core), 96GB RAM, backed by SSD. The numbers include compilation and execution time with a cold procedure cache and buffer pool. The default configuration was used, and no other indexes were created.
Comments
- Anonymous
November 08, 2018
Amazing new feature but the non-ansi joins in your examples make me very sad.- Anonymous
November 09, 2018
We have now fixed the examples to use ANSI-style joins. Thank you.
- Anonymous
- Anonymous
January 22, 2019
This improvement in SQL Server will make a tremendous difference in both T-SQL code modularization and performance. To overcome the current limitation of T-SQL UDFs, we have developed a proprietary Clr-Library which is harder to maintain and strictly less transparent.