Composite Projects and Schema Compare
Several questions have been raised on the forum regarding use of composite projects. This post discusses composite projects in general and then describes a technique you can use with Schema Compare for synchronizing composite projects with changes that have been made to the database.
Composite Projects 101
SSDT can combine a database project with one or more referenced database projects or dacpacs to describe a single composite database schema. Using a composite project allows a large database to be broken down into more manageable chunks, allows different people or teams to have responsibility for different parts of the overall schema, and enables reuse of database object definitions in multiple databases.
Scenarios might include a central team defining a set of common types, tables and procedures that are released to other teams as a dacpac for inclusion in other databases. Or an extended version of a database could be defined that adds extra test procedures and other objects to enable the referenced database to be tested – the extended test project is deployed while you are testing, and the referenced main database project is deployed otherwise.
First, some composition basics. Schemas are composed by adding Database References to projects or dacpacs you wish to compose into another project. A referenced project/dacpac can describe a fragment of schema that you want to compose or a complete database definition.
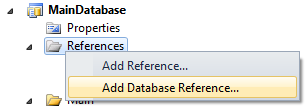
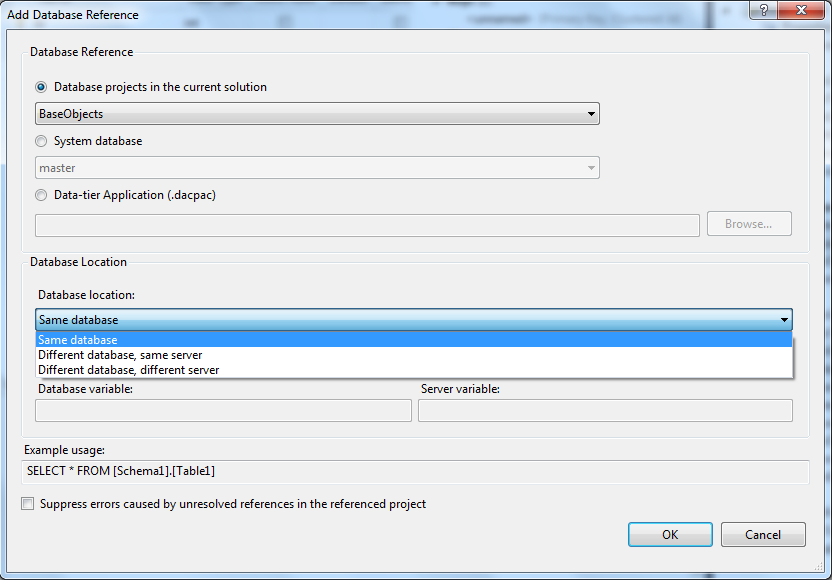
To compose projects and dacpacs into a single database the references must be defined as 'Same database' references on the Add Database Reference dialog (below).
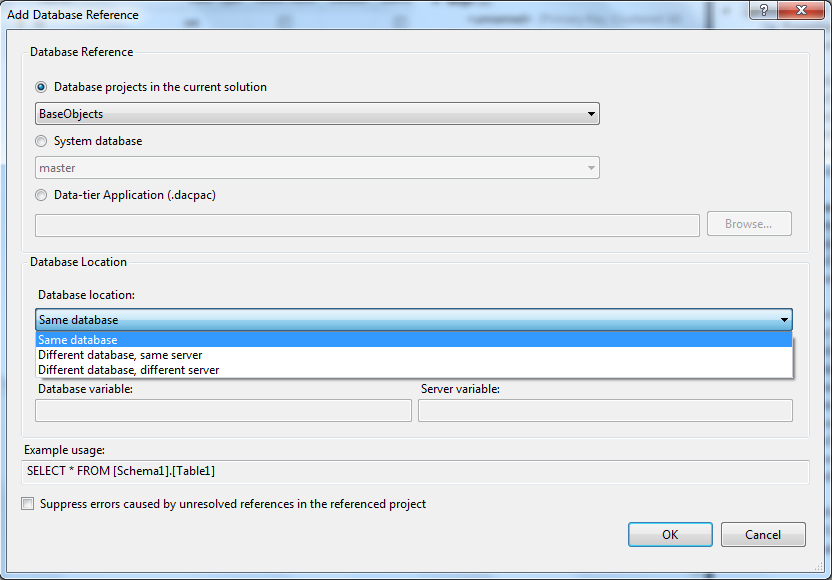
References must be strictly hierarchical with no circular dependencies. A referenced dacpac can be built from a project or extracted from a database. The hierarchy of references can be arbitrarily deep, although you need to add references in each project to all its lower-level projects or dacpacs, whether directly or indirectly composed.
In the sample CompositeDb solution shown below you can see several levels of composition. First a BaseObjects project and a peer CommonUtilities project are composed into the MainDatabase project. Then the TestDatabase, composes MainDatabase and introduces some additional objects for testing purposes. You can see how TestDatabase references BaseObjects and CommonUtilities as well as the MainDatabase project.
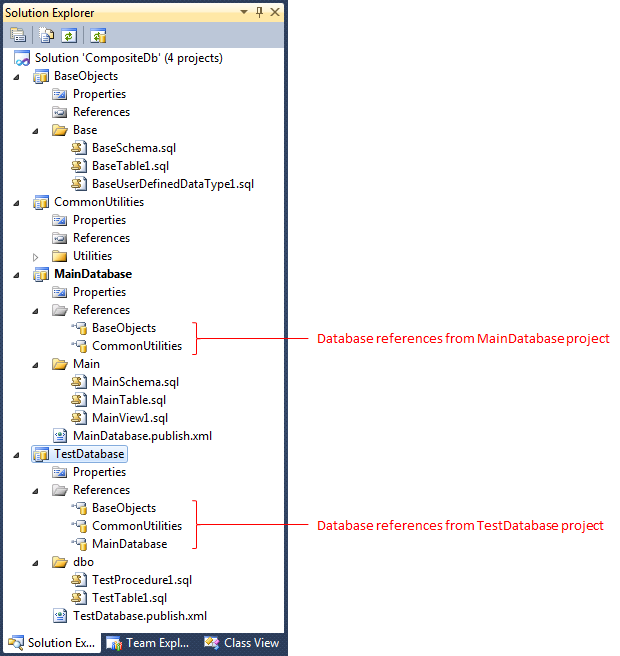
Not visible in the screen shot is that the references to BaseObjects from the TestDatabase and MainDatabase projects are to the dacpac generated from the BaseObjects project. Why reference the dacpac instead of the project? Well, if the referenced schema is large and doesn’t change frequently, then referencing the dacpac allows you to exclude the project that builds it from the normal build. Doing that means the dacpac is not recreated and resolved with every build or clean which can save a worthwhile amount of time. And of course, the dacpac could have been provided by another team working from another solution, or could have been extracted from a database in which case you would likely reference it at some appropriate share.
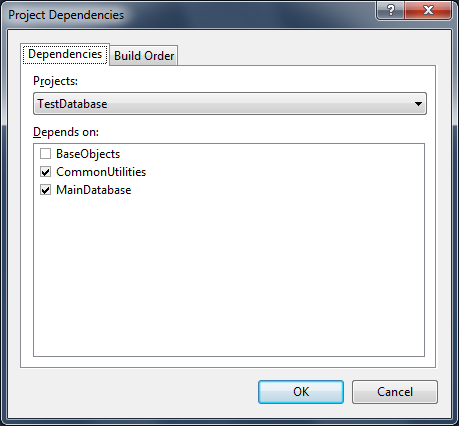
The project dependencies and build order can also be inspected using the Project Dependencies dialog accessed from any project in the solution. In the screenshot below you can see how the dependency on the BaseObjects dacpac does not get translated into a project dependency. Of course if you take a dependency on a dacpac then you need to ensure it is rebuilt or refreshed from its source whenever the source is changed before rebuilding projects that reference it.
In each of the projects I defined discrete SQL schemas in which the objects are defined and used the convention of grouping objects in schema-specific folders – Base in the BaseObjects project, Utilities in CommonUtilities, and Main in the Main project. Using schemas like this isn't required but it's going to be useful in a moment when we use Schema Compare, it helps me organize the overall composite project structure, and would work well if I want to give different groups responsibility for different part s of the database definition.
Once you have set up the database references in this manner you can refer to objects defined in a referenced project or dacpac as if they are defined locally, and get full Intellisense support. So in TestDatabase, for example, TestProcedure1 has full visibility to any object in MainDatabase, including objects supplied by BaseObjects or CommonUtilities.
To deploy a composite project you must set the Include composite objects option on the project you're deploying from.
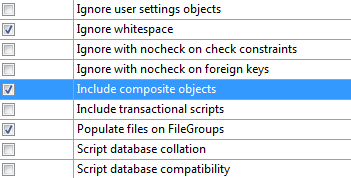
This is available as an Advanced option in Publish and on the Debug properties tab, and as a general option in Schema Compare. Note that in Schema Compare the option only affects publishing to a target database. Without this option set the source project will be deployed without the referenced projects or dacpacs. If you deploy to an existing database and forget to set this option but have set options to delete objects in the target that are not in the source, you risk deleting important content from the database. Schema Compare will highlight such delete actions very clearly, but it will be less obvious in Publish and will happen silently in Debug/Deploy. Be careful!
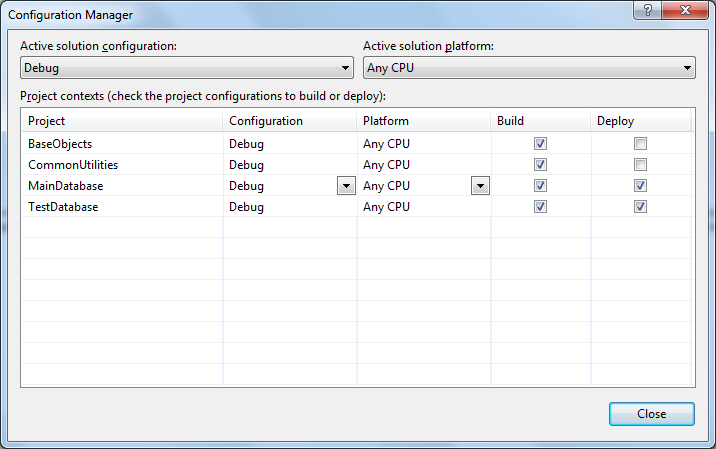
If you are referencing other projects in the same solution you can disable their automatic deployment on Debug/Deploy (F5/Ctrl+ F5) with the Build > Configuration Manager dialog. In this dialog you can uncheck Deploy for each project that you don’t intend to be deployed as a free-standing database. Below you can see I have configured my solution to independently deploy the MainDatabase and TestDatabase projects but not the lower-level components.
Using Schema Compare with Composite Projects
Like Publish or Debug Deploy, Schema Compare can be used to deploy the composition to the target database. A single resolved model is created from the composition which is then compared to the database and differences presented in the results grid. While that is straightforward it’s a little trickier when working in reverse, i.e. if you need to update the projects from the database. The difficulty is that if Schema Compare targeted a resolved composite model it would be unclear where (i.e. into which project) new objects should be added. At this time Schema Compare does not resolve composite projects when they are the target, so you have to compare the database to each project in turn. However, when you compare the database to a project that is describes just a part of it Schema Compare will try to add all the other objects which is not what you want. So how do we fix that?
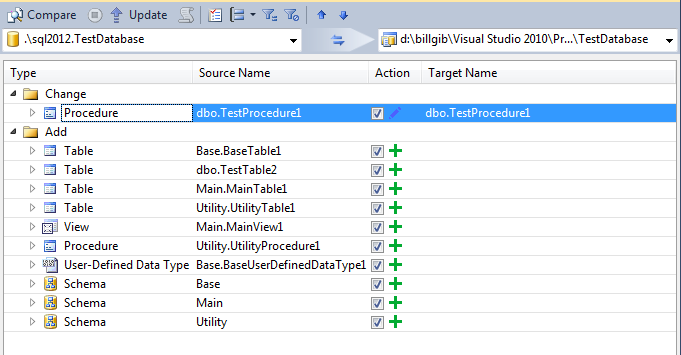
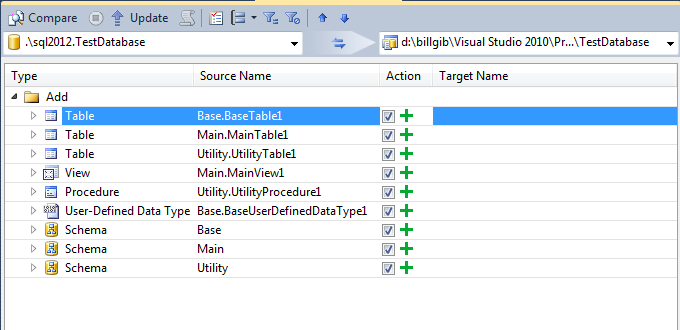
First, let’s take a look at the problem. The screen shot below shows the Schema Compare results after comparing my TestDatabase with its corresponding TestDatabase project. In this case I have added a new table and changed a test procedure. While the change shows up clearly, the table being added (TestTable2) is lost in the noise. Schema Compare wants to add all the objects defined in my other projects to the TestDatabase. If I were to accept the default actions each of the projects in the composition would end up containing a full definition of the database.
{kind=link}
{kind=link}
{kind=link}
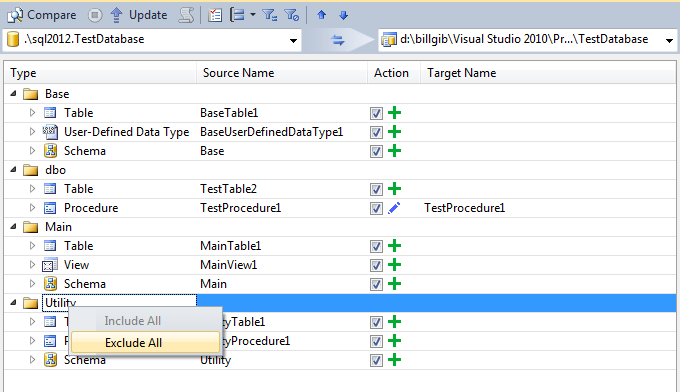
While Schema Compare lets me exclude objects from the update, how do I quickly identify the right objects to exclude and do this repeatedly and reliably? Now we will see the benefit of organizing objects in each component into discrete schemas. If I group the Schema Compare results by schema (below) objects that belong to schemas defined in the other database projects are easily seen. This quickly highlights the candidate actions to apply to the TestDatabase project (in this case the change and add of objects in the dbo schema). And with the objects organized into groups like this it’s a simple matter to exclude all members of a group using the context menu option on the group (also shown below).
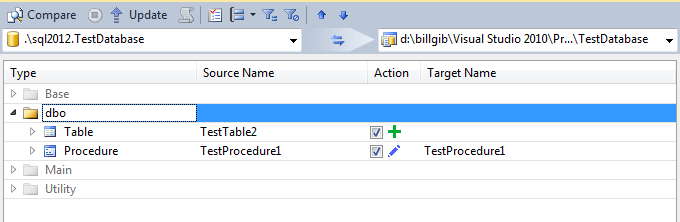
With the extraneous objects excluded and their schemas collapsed (below) you can concentrate on the changes that apply to the test project and decide which of these you want to take.
Having set up the Schema Comparison like this you can save the comparison definition as an .scmp file and include it in the target project. The saved scmp file includes the source and target schema designation, the options used, and importantly, the list of exclusions. You will need to do the same for each project in the composition, and remember to update and save these files periodically as objects are added to projects or dacpac in the composition. Double-clicking on the scmp file in each project will now open a pre-configured Schema Compare which can be used whenever you need to bring in changes from the database to that project.