Distribuição de dados no SQL Server e o algoritmo Proportional Fill
Há algumas semanas eu tive a oportunidade de palestrar no Webcast do Grupo SQL Maniacs, do meu amigo Vitor Fava.
Nessa oportunidade falei sobre um tema muito interessante, porém pouco falado em eventos e até mesmo em posts técnicos: A Distribuição de dados no SQL Server.
Se você tem interesse em entender como isso funciona na prática, convido você a assistir esse webcast no link: https://www.youtube.com/watch?v=XXbVLzfKwsQ
Lá, inclusive, você pode ver uma DEMO que cobre alguns pontos que vou destacar neste post.
Vou tentar resumir um pouco o que falei nessa ocasião.
Como todos os profissionais que trabalham com o SQL Server e outros bancos de dados relacionais sabem, uma das responsabilidades do sistema gerenciador de banco de dados (SGDB) é manter e gerenciar os dados em memória. Porém, apesar desses dados serem utilizados em memória, os mesmos devem persistir em disco, o que garante alguns dos atributos que todos os bancos de dados relacionais devem respeitar, entre eles a Durabilidade. O SQL Server basicamente usa dois tipos de arquivo para este propósito, o arquivo de Transaction Log, que possui a extensão .ldf, e o arquivos de dados, que possuem a extensão .mdf, para o arquivo primário, e .ndf para os arquivos que foram criados posteriormente, ou seja, os arquivos secundários. Nesse primeiro momento não vou me atentar ao arquivo de log, já que ele possui uma estrutura bem diferente dos arquivos de dados e é utilizado para outros propósitos, como a recoverabilidade dos dados em caso de falhas e por algumas features. Vamos focar aqui nos arquivos de dados, os .mdf e .ndf.
No SQL Server, algo que faz parte da arquitetura de arquivos é o que chamamos de Filegroup (FG), ou Grupo de arquivos. Ele basicamente é utilizado para agrupar os arquivos de forma "lógica". Do ponto de vista físico não há nenhuma mudança, porém o Filegroup é utilizado para alocação dos dados e administração dos arquivos.
Quando criamos um objeto, por exemplo uma tabela, não podemos simplesmente especificar em qual arquivo físico (.mdf ou .ndf) esta tabela será armazenada, porém podemos definir em qual Filegroup ela residirá, no momento da criação da mesma, como você pode ver na imagem abaixo. Uma vez em determinado Filegroup esta tabela poderia alocar dados em qualquer dos arquivos que fazem parte deste mesmo FG.
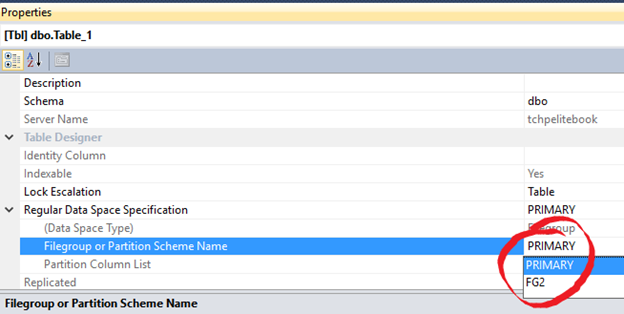
Se você trabalha com SQL Server, você já percebeu que um Filegroup é automaticamente gerado durante a criação de um banco de dados. Este é o Filegroup primário e o arquivo de dados primário (.mdf) é o único arquivo pertencente a este FG inicialmente. Neste arquivo até então não há dados de usuário e é por isso que muitos DBAs, como uma boa prática, as vezes criam um novo filegroup e novos arquivos de dados alocados neste novo FG para a alocação de dados de usuário. Dessa forma seu FG primário estaria sendo utilizado apenas para armazenar dados de sistema.
Infelizmente não tive tempo de explicar, durante o webcast, como a alocação de dados funciona de forma detalhada, e na verdade pretendo fazer um post específico para falar sobre esse assunto, mas para resumir, podemos dizer que o SQL Server utiliza mapas de alocação para alocar dados, dessa forma o SQL pode encontrar de forma "rápida" quais extents/páginas estão disponíveis para novas alocações e o percentual de espaço disponível nessas páginas. Mas como eu disse, vamos falar sobre GAM, SGAM, PFS e IAM em uma próxima oportunidade.
Cada arquivo de dados possui suas próprias páginas de sistema e mapas de alocação. Por exemplo: O arquivo1.ndf possui mapas de alocação distintos do arquivo2.ndf, se ambos os arquivos pertencem ao mesmo Filegroup o SQL Server pode distribuir os dados do objeto que foi criado neste filegroup entre esses dois arquivos e ter como benefício o fato de ter mais mapas de alocação sendo utilizados paralelamente. Num banco de dados de usuário é muito raro ver problemas de desempenho causados por contenção nessas páginas de sistema, já que a alocação de novos objetos não é tão constante a ponto de causar isso. Por outro lado, um banco de dados que conhecemos muito bem, o tempdb, é utilizado não só quando criamos novos objetos temporários, mas durante outras operações, por isso não é raro casos em que por se ter apenas um arquivo de dados (.mdf) para o tempdb, essa contenção, por causa do acesso frequente a esses mapas de alocação, comece a gerar problemas de performance. Esse é um dos principais motivos para a recomendação de se criar mais arquivos de dados para o banco de dados tempdb, para evitar essa possível contenção dos mapas de alocação.
Bem, voltando aos bancos de dados de usuário. Vamos usar um objeto como exemplo, para falar um pouco mais sobre a distribuição dos dados.
Imagine que você criou a Tabela1.
Quando o SQL Server vai fazer alocação de dados nesta tabela, se a mesmo foi criada em um Filegroup em que há mais de um arquivo, os dados podem ser distribuídos entre eles.
Como então o SQL Server decide a quantidade de dados que será alocada em cada arquivo? Aqui entre em cena um algorítmo que é responsável por fazer essa distribuição: O Proportional Fill.
O Proportional Fill é utilizado para que todos os arquivos que pertençam a um mesmo filegroup cheguem ao seu limite, ou seja, termine o seu espaço disponível, "aproximadamente", ao mesmo tempo. É aproximadamente mesmo, porque dependendo da diferença de espaço disponível entre os arquivos, obviamente pode ser que um dos arquivos encha primeiro. A questão aqui é que se a distribuição é Proporcional, isso significa que o SQL Server irá distribuir os dados baseados em alguma métrica.
Qual é esta métrica? É algo bem simples e lógico, na verdade: O percentual de espaço disponível em cada arquivo.
Para ficar mais fácil de entender, vamos imaginar o seguinte cenário.
Você tem a Tabela1 alocada no Filegroup1. O Filegroup1 possui os arquivos: arquivo1.ndf, arquivo2.ndf, arquivo3.ndf e arquivo4.ndf.
Se os arquivos possuem um percentual diferente de espaço disponível entre eles, a distribuição proporcional irá fazer com que mais dados sejam alocados no arquivo com mais espaço disponível. Obviamente, isso não significa que os outros arquivos não irão "receber" dados, mas eles irão receber proporcionalmente menos alocações.
Aqui está a quantidade de espaço disponível em cada arquivo:
Arquivo de Dados |
Espaço Disponível |
Arquivo1.ndf |
100 Mb |
Arquivo2.ndf |
200 Mb |
Arquivo3.ndf |
50 Mb |
Arquivo4.ndf |
400 Mb |
Nesse cenário, o SQL Server faria um cáculo para determinar a proporção em que os dados devem ser distribuídos. Seria algo mais ou menos assim:
A soma do espaço disponível significa 100% do espaço.
Ou Seja: 100Mb + 200Mb + 50Mb + 400Mb = 750Mb.
750Mb = 100%.
Quanto cada arquivo representa sobre o total de espaço disponível?
Utilizando o arquivo1.ndf como exemplo:
Arquivo1.ndf = 100Mb.
(100/750)*100 = 13-14%.
Ou seja, o arquivo1.ndf deveria receber em torno de 14% dos novos dados alocados, assim como o Arquivo2.ndf receberia em torno de 26%, Arquivo3.ndf 6% e o Arquivo4.ndf 54%, já que ele é o arquivo com mais espaço disponível.
É claro que esses números começam a sofrer mudanças conforme as alocações forem feitas e, isso diretamente afeta o percentual de dados alocados em cada arquivo. Mas a idéia é que o SQL Server distribua os dados de forma proporcional para garantir aquilo que mencionei no início da explicação sobre o Proportional Fill: Que todos os arquivos cheguem ao seu fim, “aproximadamente” ao mesmo tempo.
Agora que você entendeu como funciona o Proportional Fill, a pergunta é: Há vantagens em se ter alocações distribuídas entre diversos arquivo? Sem dúvida, primeiramente estamos otimizando a utilização dos arquivos do ponto de vista de espaço disponível e, apesar de esses dados serem proporcionalmente distribuídos, eu estaria quebrando as alocações entre diversos arquivos. Se cada um deles estiver em um disco diferente, isso poderia até gerar uma certa medida de performance.
Ótimo! Mas você não concorda que se eu conseguir fazer uma distribuição mais equitativa, ou seja, uma distribuição por igual entre os arquivos, eu não teria um desempenho ainda melhor?
Bem, se todos os arquivos estiverem no mesmo disco, pra ser sincero, tanto faz, já que estaria compartilhando spindles ou seja, a mesma capacidade/velocidade de leitura/escrita do disco entre todos os arquivos. E lembre-se, apesar de eu ter mais mapas de alocação que podem ser utilizados em paralelo, bancos de usuário raramente apresentam problemas de contenção nessas páginas.
Agora, imagine cada um desses arquivos em um disco separado, ou melhor, o que realmente importa, eu tenha spindles diferentes pra cada arquivo. Sem dúvida os ganhos de desempenho poderiam ser bem interessantes.
Qual então seria a resposta para garantir uma distribuição equitativa?
Eu sei o que você pensou e, está correto! Garantir que todos os arquivos de dados deste filegroup possuam o mesmo percentual de espaço disponível.
Para isso eu preciso, primeiro, durante a criação do banco de dados, garantir o mesmo tamanho inicial dos meus arquivos de dados. Segundo, que as configurações de Autogrowth, ou seja, de auto-crescimento, de todos os arquivos pertencentes àquele filegroup sejam idênticas.
O que? Um PFE falando sobre auto-crescimento? Ok ok, eu sei que você está pensando: “Bem, mas não acho que eu deveria habilitar a opção de autogrowth, já que isso é um processo custoso. O SQL tem que preencher o espaço alocado no disco com zeros (0) e isso poderia afetar minhas transações durante esse período”. Isso é verdade, apesar de podermos otimizar este processo utilizando o instant file initialization que, por exemplo, poderia reduzir o tempo de alocação de “lixo” no espaço alocado em disco, uma boa prática é realizar crescimentos dos seus bancos de dados de forma manual em um horário mais conveniente. Porém, nós sabemos que há empresas que simplesmente não conseguem fazer isso. Se seu footprint, ou seja, a quantidade de ambientes SQL que você administra é grande, você simplesmente vai optar pelo auto-crescimento e aqui sim minha recomendação é utilizar opções que podem transformar essa tarefa em algo mais otimizado (ou menos custoso), como configurar o crescimento em Mb ao invés de % e ter o Instant File Initialization habilitado (aqui vai mais um assunto pra outro post).
A questão é, garantindo que as configurações de auto-crescimento sejam idênticas entre seus arquivos, nos dá a certeza de que seus arquivos sempre terão o mesmo percentual de espaço disponível entre eles, e isso garante com que a distribuição dos dados para seus objetos sejam equitativa.
No exemplo que eu utilizei anteriormente, se os 4 aquivos possuissem 200Mb de espaço disponível, o SQL Server simplesmente distribuiria 25% do total de dados alocados em cada um dos arquivos. Coloque cada um desses arquivos em um disco diferente, sim, você teria mais desempenho.
Há apenas um único detalhe a ser destacado com relação autogrowth. O evento de auto-crescimento em si é round-robin.
Como assim Thiago? Isso mesmo. Se você encheu seus arquivos - aqui um detalhe importante, o auto-grow só ocorre após TODOS os arquivos daquele determinado FIlegroup terem chegado ao seu limite - o evento de auto-crescimento, por padrão, não ocorre simultaneamente em todos os arquivos. O SQL Server "aleatoriamente" escolhe um dos arquivos pertencentes a aquele Filegroup e dispara o evento de auto-crescimento. A partir daí você passa a utilizar apenas um dos arquivos para TODAS as alocações, já que os outros arquivos possuem 0% de espaço disponível. Este arquivo que cresceu chegou ao seu limite? O SQL Server dispara o auto-crescimento para o próximo arquivo, e assim por diante, até que todos os arquivos já tenham crescido e aí, esse ciclo se repete. Isso não é um problema, este é um comportamente esperado e é assim que o algoritmo funciona.
Ou seja, baseado no que vimos até agora, você pode até tirar algumas vantagens em se ter uma distribuição equitativa entre vários arquivos, porém, quando TODOS os arquivos de um determinado Filegroup chegam ao seu limite, por causa do evento de auto-crescimento utilizar um algoritmo round-robin, você pode simplesmente deixar de ver esse comportamento de distribuição das alocações em vários arquivos.
É claro que cada caso é um caso, talvez no seu cenário você nem queira fazer uso do Proportional Fill para distribuir seus dados entre diversos arquivos. Mas, vamos dizer que você queira. Nesse caso há uma forma de garantir que o evento de auto-crescimento ocorra simultaneamente em todos os arquivos, o que, consequentemente, garantiria que você continue a usar o Proportional Fill e, em um ambiente em que os arquivos possuam o mesmo percentual de espaço disponível e configurações de autogrowth idênticas, uma distribuição de dados mais equitativa entre os arquivos deste Filegroup.
Aqui entra em cena a Trace Flag 1117. Eu costumo dizer que Trace Flags são como Cheat Codes. Se você quer mudar algum comportamento padrão do SQL, você pode fazer uso delas, porém fica aqui um ponto de atenção: Todas elas devem ser cuidadosamente avaliadas antes de serem habilitadas.
Essa Trace Flag, ou TF, é bem interessante por sinal. Para o banco de dados Tempdb, ela é praticamente “mandatória”, afinal para eu garantir que não vou ter aqueles problemas de contenção nos mapas de alocação eu preciso garantir que todos os arquivos de dados do tempdb estejam sendo usados, e isso só é possível se todos tiverem espaço disponível. Esse é um dos motivos que levaram a Microsoft a transformar a TF1117 para o banco de dados tempdb em um comportamento padrão, a partir da versão 2016, ou seja, você não precisa habilitar essa TF por causa do tempdb, apenas se você quiser ter o mesmo comportamente para bancos de usuário, que é exatamente o que estamos falando aqui.
Habilitando essa TF, toda vez que o evento de auto-crescimento ocorre ele expande todos os arquivos de um determinado filegroup, simultaneamente.
Como todo TF, ou a maioria, varia muito a aplicabilidade em bancos de usuário. O TF 1117 é um deles.
Então resumindo essa parte: nós temos este algoritmo, que falamos aqui, o Proportional Fill, que é utilizado para garantir que todos os arquivos de um determinado FG cheguem ao seu limite "aproximadamente" ao mesmo tempo (FULL). A questão é, chegamos no limite de TODOS os arquivos, a distribuição dos dados deixa de ser proporcional e passa a utilizar apenas um dos arquivos, já que o event auto-grow é RR (round-robin), como eu já mencionei.
Mais uma vez, do ponto de vista de desempenho, distribuir os dados entre diversos arquivos que estão no mesmo disco, não faria muita diferença. A contenção de mapas de alocação em banco de dados de usuário é rara, por isso, a questão aqui são os benefícios de se compartilhar spindles, ou seja, a capacidade de IO dos discos, considerando que você possa alocar cada um desses arquivos em um discos distinto.
Habilitar essa TF e utilizar o Proportional Fill se aplica ao meu cenário?
Talvez.
Lembre-se de que temos funcionalidades muito bacanas que podem te ajudar do ponto de vista de performance e também distribuir os dados entre diversos arquivos e discos, como as Tabelas Particionadas, que inclusive fazem uso dos Filegroups para fazer isso acontecer. Contudo, em cenários que você simplesmente não pode utilizar determinadas soluções como essa, abusar do Proportional FIll não seria nenhum pecado.
Apenas para citar um exemplo de aplicabilidade. Eu visitei um cliente aqui nos EUA onde um determinado ambiente tinha apenas um FG com diversos (muitos mesmo) arquivos de dados, distribuídos entre vários discos, e o banco já possuia aproximadamente 20TB de dados. Infelizmente neste cenário havia alguns problemas de design e acredito que 80% das minhas recomendações foram nesse sentido. Mas a dúvida do cliente era: Como eu posso distribuir melhor meus dados entre esses vários arquivos? Como garantir uma distribuição mais equitativa entre eles?
Infelizmente não teria como eu simplesmente fazer um DROP e CREATE de todas as tabelas. A menos que você opte por utilizar Tabelas Particionadas, o que não foi o caso desse cliente, seria impossível redistribuir esses dados. Porém os índices poderiam ser redistribuídos, afinal o REBUILD iria movimentar minhas páginas de índices de qualquer jeito, e aí dependendo de quanto espaço eu tenho disponível em cada arquivo, o SQL Server poderia redistribuir esses dados. E foi assim que fizemos a redistribuição dos dados entre os arquivos, para que pudessemos garantir um % de espaço disponível mais parecido entre os arquivos e utilizar uma distribuição mais equitativa no caso de novas alocações.
Não foi fácil, mas a idéia nesse caso foi brincar com o Proportional Fill. Aumentando o % de espaço disponível nos arquivos (alterando o tamanho inicial deles) que ele queria que mais dados fossem alocados. Após alguns Rebuilds nos índices isso ocorreu. Para as tabelas Heap, simplesmente criamos um índice clustered para fazer a mágica. Se ele resolveu o problem de design dele? Não. Mas o algoritmo Proportional Fill ajudou a resolver algo que para este cliente era um problema. Hoje ele tem um ambiente mais previsível e reportou um maior desempenho, inclusive, já que ele tem uma distribuição de dados equitativa entre vários arquivos que estão em discos distintos.
Deixando um pouco de lado o Proportional Fill e falando novamente do TF 1117. A grande questão é realmente o que você espera do seu ambiente.
Não vou aqui advogar a favor ou contra utilizar essa TF.
A questão é: Você quer manter as distribuições entre mais de um arquivo de um determinado FG, habilite, simples assim. Ok, não é legal manter o auto-grow automático. Concordo plenamente, apesar de eu ter mencionado uma forma mais "suave" de se fazer (Instant File Initialization + crescimento em MB). Mas garanto uma coisa, há sim índicios claros de aumento de desempenho nas alocação dos dados em ambientes que possuem um cenário de distribuição por igual entre diversos arquivos, desde que pertencentes a um mesmo FG e, mais uma vez, desde que os spindles, ou seja, a capacidade de leitura e escrita dos discos sejam distintas, já que diferente do tempdb, não necessariamente temos um grande benefício em ter vários arquivos simplesmente focando na redução da contenção de mapas de alocação/PFS em bancos de usuário.
Dica final e um disclaimer sobre meu post:
Nunca mude configurações como essa sem antes testar e garantir que isso é o melhor para seu ambiente produtivo.
No final do post você econtra um link para alguns scripts que você pode utilizar para testar o Proportional FIll. O primeiro arquivo é uma demonstração de como seria a distribuição proporcional, quando temos arquivos com % de espaço disponível diferentes entre eles. O segundo mostra como, garantindo o mesmo espaço disponível, faz com que o SQL Server mantenha uma distribuição equitativa. Veja também como ocorre o evento de auto-crescimento, antes e após habilitar o TF1117. Se preferir ver a DEMO, ao invés de você mesmo testar, no webcast que citei no início do artigo eu utilizo esses scripts para a minha demonstração.
Boa sorte na administração dos seus dados!
Thiago Caserta.
LINK PARA DOWNLOAD DOS SCRIPTS: https://1drv.ms/1LzoOUR