Rethinking Enterprise Storage – Accelerating and Broadening Disaster Recovery Protection
Recently, Microsoft published a book titled Rethinking Enterprise Storage – A Hybrid Cloud Model – the book takes a close look at an innovative infrastructure storage architecture called hybrid cloud storage.
Last week we published experts from Chapter 2. This week we provide excerpts from Chapter 3, Accelerating and Broadening Disaster Recovery Protection.
Disaster recovery is front and center in IT thinking, and we encourage you download the book so that you can gain more insight into the manner in which StorSimple assists you in this important area. Over the next several weeks on this blog, we will continue to publish excerpts from each chapter of this book via a series of posts. We think this is valuable information for all IT professionals, from executives responsible for determining IT strategies to administrators who manage systems and storage. We would love to hear from you and we encourage your comments, questions and suggestions.
As you read this material, we also want to remind you that the Microsoft StorSimple 8000 series provides to customers innovative and game-changing hybrid cloud storage architecture and it is quickly becoming a standard for many global corporations who are deploying hybrid cloud storage. You can learn more about the StorSimple 8000 series here: https://www.microsoft.com/storsimple
Here are the chapters we will excerpt in this blog series:
Chapter 1 Rethinking enterprise storage
Chapter 2 Leapfrogging backup with cloud snapshots
Chapter 3 Accelerating and broadening disaster recover protection
Chapter 4 Taming the capacity monster
Chapter 5 Archiving data with the hybrid cloud
Chapter 6 Putting all the pieces together
Chapter 7 Imagining the possibilities with hybrid cloud storage
That’s a Wrap! Summary and glossary of terms for hybrid cloud storage
So, without further ado, here are some excerpts from Chapter 2 of Rethinking Enterprise Storage – A Hybrid Cloud Model
Chapter 3 Accelerating and Broadening Disaster Recovery Protection
This chapter begins by examining the requirements for DR, including recovery planning and testing before discussing remote replication. The Microsoft hybrid cloud storage (HCS) solution was introduced as a new, more flexible, and simpler approach to solving DR problems by virtue of being designed with the hybrid data management model.
Minimizing business interruptions
The goal of disaster preparation is to reduce disruptions to business operations. The ultimate goal is to avoid any downtime whatsoever. This can happen when the IT team has adequate time to prepare for an oncoming disaster and possesses the technology to shift production operations to an unaffected secondary site. For example, a company in the path of a hurricane may be able to execute a smooth transition of certain key applications from the primary site to a secondary site in a different geography before the storm arrives. Unfortunately, the disruption caused by disasters is usually unavoidable and unpredictable. That’s when simple designs, reliable technologies, and practiced processes are most valuable.
Recovery metrics: Recovery time and recovery point
There are two metrics used to measure the effectiveness of disaster recovery: recovery time and recovery point. Recovery time is equated with downtime after a disaster and expresses how long it takes to get systems back online after a disaster. Recovery point is equated with data loss and expresses the point in the past when new data written to storage was not copied by the data protection system. For instance, if the last successful backup started at 1:00 AM the previous night, then 1:00 AM would be the presumed recovery point.
A good visualization for a recovery time and recovery point is the timeline shown in Figure 3-1. The disaster occurs at the spot marked by the X. The time it takes to get the applications running again at a future time is the recovery time. The time in the past when the last data protection operation copied data is the recovery point.

FIGURE 3-1 The timeline of a recovery includes the disaster, recovery point, and recovery time.
The timeline shown in Figure 3-1 will likely have different dimensions and scales depending on the importance of the application. The IT team sets recovery point objectives (RPOs) and recovery time objectives (RTOs) for applications based on their importance to the organization and the data protection technology they are using for recovery. The highest priority applications typically are protected by technologies providing the shortest RPOs and RTOs while the lowest priority applications are protected by tape backup technology, which provides the longest RPOs and RTOs.
Unpredictable RPOs and RTOs with tape
The problems encountered when recovering from tape were discussed in the section “Restoring from tape” in Chapter 2. IT teams struggle with setting RPOs and RTOs when tape is the data protection technology used for restoring data. RTOs established with tape are usually based on a best case scenario, something that rarely happens with tape DR scenarios. RPOs usually assume that backups finish successfully—an assumption that is, unfortunately, too often wrong. Considering the nature of backup failures and tape rotation mechanisms, IT teams can discover the actual recovery point changes from one day to one or two weeks in the past. That starts a completely different set of involved and thorny management problems.
In general, having overly aggressive RPOs and RTOs for tape restores sets expectations for the organization that might not be realistic, creating additional pressure on the IT team that may contribute to errors that lengthen the recovery process.
Disaster recovery with the Microsoft HCS solution
IT teams are looking for DR solutions that are less expensive and more comprehensive than remote replication and more reliable and faster than tape. Using cloud storage for data protection can be a solution, but slow download speeds must be overcome to achieve RTOs that can compete with tape.
The intelligent hybrid data management system in the Microsoft HCS solution combines excellent RPOs and RTOs with cost-competitive Microsoft Azure Storage, without adding to data growth problems. It is an excellent example of how using cloud resources to manage the IT infrastructure can improve existing data center practices.
The concept of DR with the Microsoft HCS solution is simple: fingerprints that were uploaded by cloud snapshots to Microsoft Azure Storage are downloaded again during a recovery process that is driven by a CiS system at a recovery site. Figure 3-2 illustrates the data flow for recovering data with the Microsoft HCS solution.
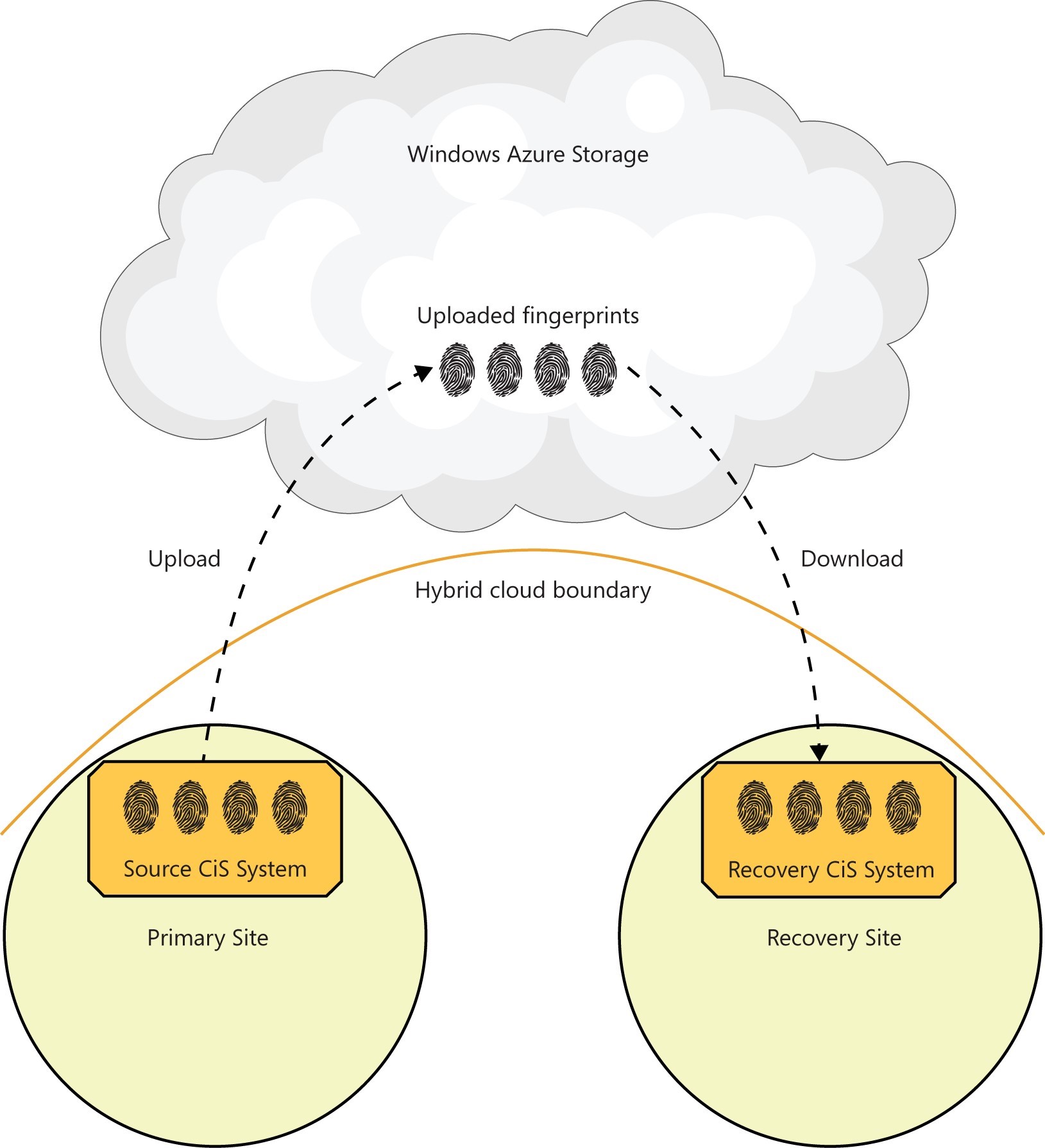
FIGURE 3-2 The data flow for recovering data with the Microsoft HCS solution.
Introducing the metadata map
The section titled “Looking beyond disaster protection” in Chapter 2 described the hybrid data management system of fingerprints, pointers and cloud snapshots that spans on-premises and Microsoft Azure Storage. One of the key elements of this system is the metadata map, a special object containing the pointers to all the fingerprints stored in the cloud. Every cloud snapshot operation uploads an updated version of the metadata map as a discrete, stored object. When the process ends, the Microsoft Azure Storage bucket (cloud storage container) has an updated collection of fingerprints and a new metadata map with pointers to the locations of all fingerprints in the bucket. An individual metadata map consumes less than 0.3 percent of the capacity consumed by fingerprints.
Disaster recovery operations begin by selecting a cloud snapshot date and time and downloading the metadata map from its bucket to a recovery CiS system. When the map is loaded, servers and VMs at the recovery site can mount the storage volumes that had previously been on a source CiS system, and then users and applications can browse and open files. The fingerprints from the source CiS system are still on the other side of the hybrid cloud boundary, but can now be accessed and downloaded in a way that is similar to a remote file share.
Figure 3-3 shows the relationship between Microsoft Azure Storage, source and recovery CiS systems, and illustrates how the metadata map is uploaded, stored, and downloaded.
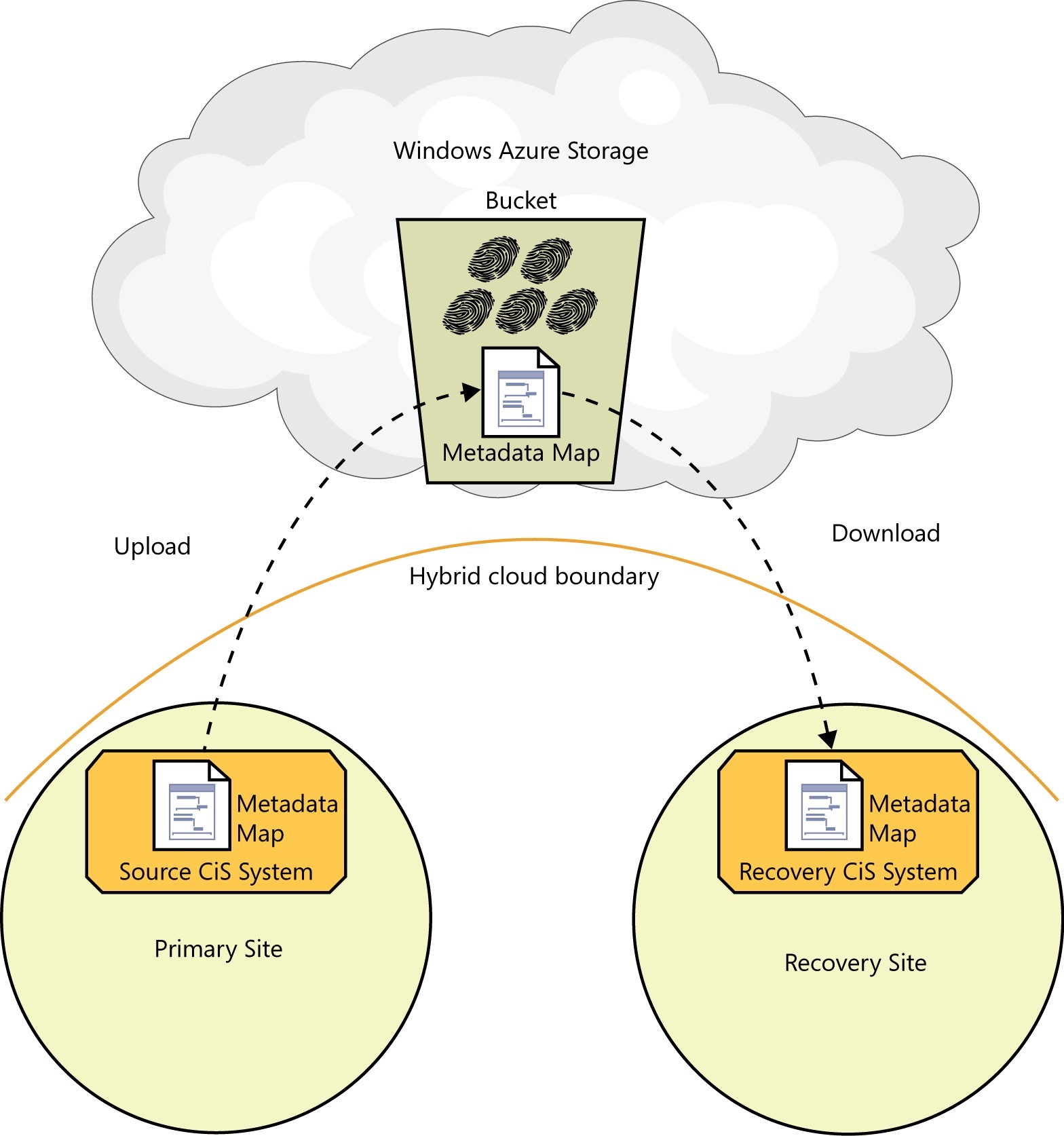
FIGURE 3-3 The metadata map that was uploaded by the source CiS system and stored in the Microsoft Azure Storage bucket is downloaded by the recovery CiS system.