Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
このポストは、4 月 24 日に投稿された Azure Data Factory update: Simplified Sample deployment の翻訳です。
Azure Data Factory チームでは、皆様からのフィードバックに基づいて Azure Data Factory サービスを継続的に改善しています。本日、Azure 管理ポータルに新たな機能を追加し、数回のクリックで Data Factory にユースケース ベースのサンプルをデプロイできるようにしました。デプロイにかかる時間は 5 分以内となっています。
これにより、Data Factory の学習をより簡単に、より実践的に行っていただけるようになれば幸いです。このサンプルは標準パイプラインとして Data Factory にデプロイされるため、ソースを ADF エディター (英語) に表示してしくみを確認し、必要に応じて編集、カスタマイズすることができます。
サンプルのデプロイ方法は、以下の動画でご確認いただけます。

サンプルの起動
- こちらのチュートリアルの手順に従って新しい Data Factory を作成するか、既存の Data Factory を使用します。
- [DATA FACTORY] ブレードの [Sample pipelines] タイルをクリックします (以下のスクリーンショットを参照)。

図 1 – Data Factory のランディング ページのサンプル セクション
サンプルの選択
[Sample pipelines] ブレードに、Data Factory にデプロイ可能なサンプルの一覧が表示されます。この例では、[Customer Profiling] サンプルを選択します。このサンプルは、あるゲーム会社が Azure Data Factory を活用して Azure HDInsight での半構造化ゲーム ログの処理を運用化し、顧客の好み、使用に関する行動、マーケティング キャンペーンの効果を分析する方法を示したものです。現在は次のリリースの準備を進めており、数週間のうちには同様の新しいサンプルを提供できる予定です。追加してほしいサンプルがある場合には、[Suggest a sample] をクリックしてサンプルをご提案ください。
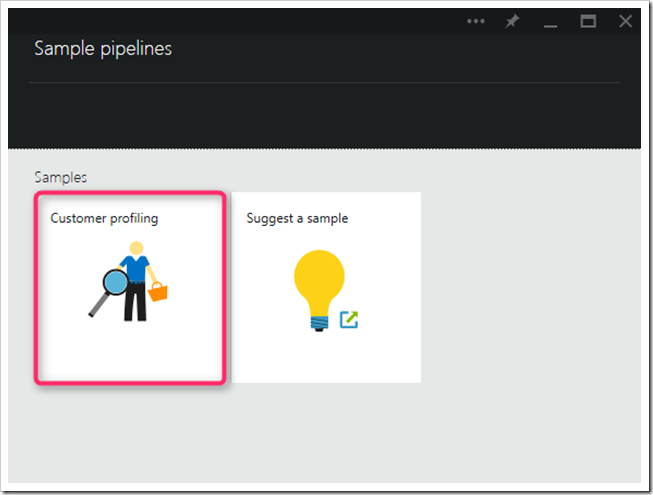
図 2 – サンプルの選択画面
ストレージ リソースの選択
- [Sample pipelines] ページで [Customer Profiling] をクリックすると、このサンプルの [SAMPLE PIPELINE] ブレードが表示されます。このブレードに表示されるサンプルの説明を確認して、サンプルの詳細と、サンプルをデプロイした場合に実行される処理について理解してください。
- サンプルをデプロイする前に、まずサンプルの構成パラメーターの値を指定する必要があります。ブレード ビューには、アクティブなサブスクリプションに含まれる既存のすべての Azure Storage と Azure SQL Server/Database が表示されます。ドロップダウン リストから、このサンプルで使用する適切な Storage アカウントと Server/Database の組み合わせを選択します。既存の Azure Storage アカウントまたは Azure SQL Database が存在しない場合は、[Create new] リンクを使用して Azure Storage または Azure SQL Database の作成フローを開始し、リソースを作成してから、Azure Data Factory のサンプル デプロイ ワークフローを再開します。
- [Create] ボタンをクリックして、サンプルを作成またはデプロイします。
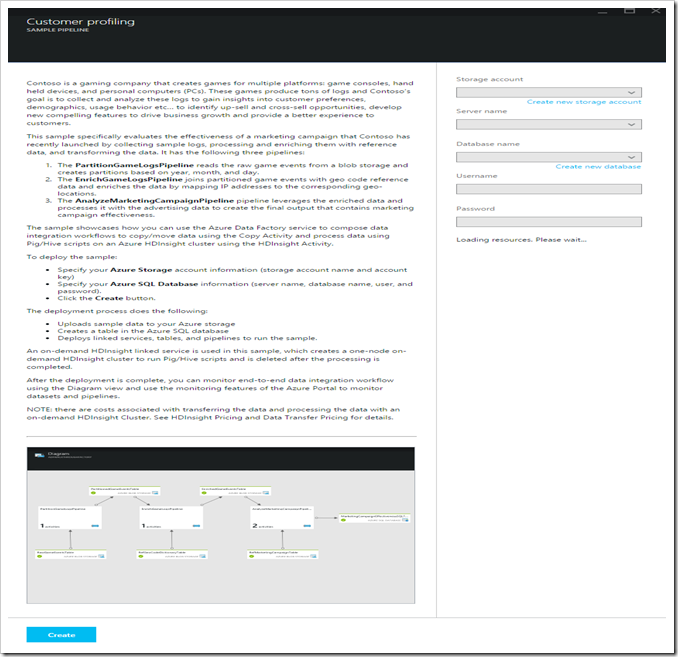
図 3 – サンプルの説明とリソースの構成
デプロイ
サンプル用のストレージ リソースの構成を完了し、[Create] ボタンをクリックすると、デプロイ プロセスが開始されます。このプロセスでは、以下の処理を実行します。
- Azure Storage にサンプル データをアップロードする
- Azure SQL Database にテーブルを作成する
- サンプルに対応するすべての Data Factory エンティティ (リンクされたサービス、テーブル、パイプライン) をデプロイする
5 分以内に、サンプルがデプロイされて Data Factory で実行されます。以下のスクリーンショットのように、デプロイメントが成功したことを示すメッセージが表示されます。
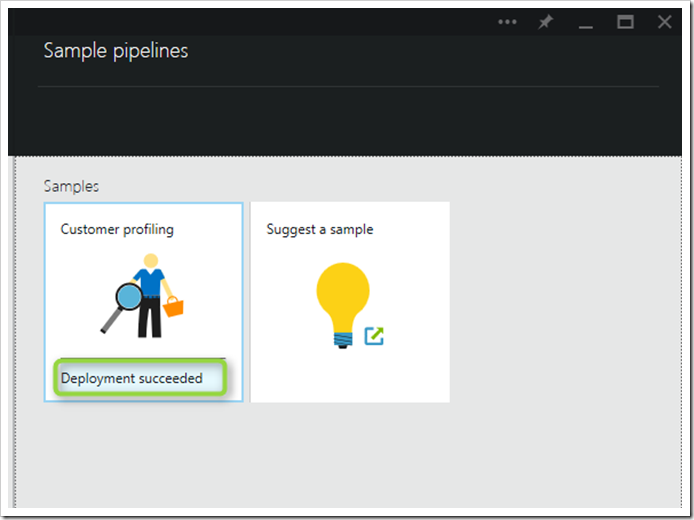
図 4 – サンプルのデプロイメントの成功を示すメッセージ
Data Factory の [DATA FACTORY] ブレードには、デプロイされたエンティティ (リンクされたサービス、データセット、パイプライン) が表示されます。

図 5 – Data Factory の [Summary] ページ
サンプルパイプラインの監視
Data Factory の [Diagram] ビューでは、エンドツーエンドのデータ統合ワークフローを確認し、高度な監視機能を使用してデータセットやパイプラインを監視できます。[Diagram] ビューを表示するには、サンプル アイコンの [Deployment succeeded] ホットスポットをクリックするか、DATA FACTORY の [Summary] ブレードの [Diagram] をクリックします。

図 6 – 選択したサンプルのホットスポットから簡単にアクセスできる
以下のスクリーンショットに示すように、[Diagram] ビューのテーブルまたはデータセットをダブルクリックすると、そのテーブルのすべてのスライスとその状態を確認できます。

図 7 – Data Factory の [Diagram] ビュー
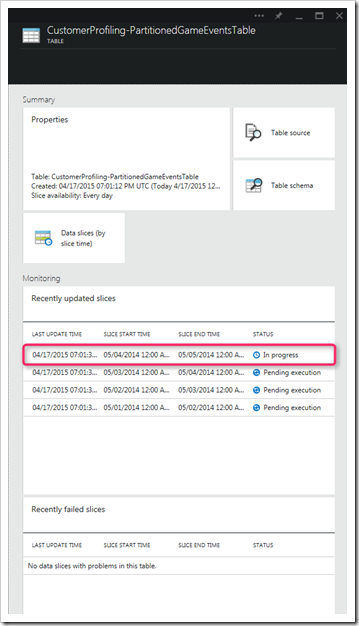
図 8 – データセットの状態
サンプルのパイプラインがデプロイされ、正常に実行されたら、Azure Data Factory エディターで開いて、デプロイされたすべてのエンティティの JSON ファイルを表示し、形式や構成を確認することができます。Data Factory の JSON スクリプトの詳細については、こちらのページ (英語) をご覧ください。

図 9 – エディター起動タイル
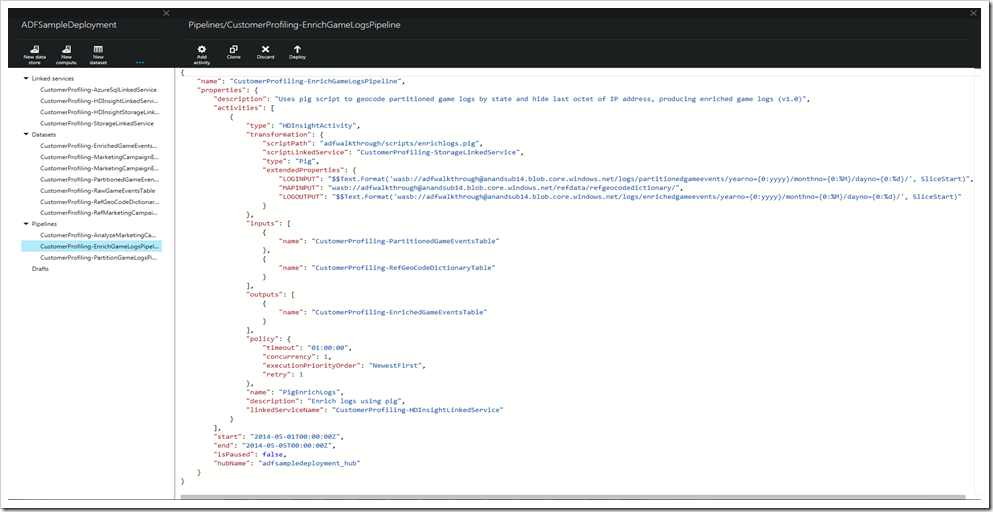
図 10 – エディターで JSON ファイルを表示、編集
出力の表示
すべてのパイプラインが正常に実行され、データセットの状態が「Ready」と表示されたら、adfcustomerprofilingsample コンテナーの Azure Storage で以下のフォルダー構造を確認できます。

図 11 – Azure Storage アカウントに未加工および処理済みのログを表示
このサンプルで使用されている Hive および Pig スクリプトは、scripts フォルダー内に格納されています。
リソース構成ページで選択した Azure SQL Database に移動して、MarketingCampaignEffectiveness テーブルに対してクエリを実行すると、Azure Data Factory のコピー パイプラインによってコピーされた最終出力データが表示されます。
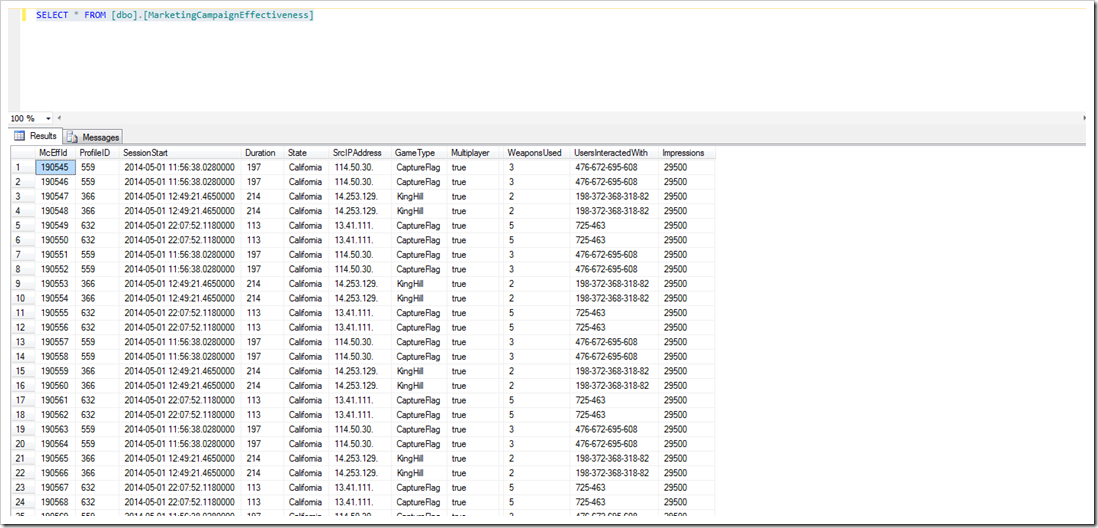
図 12 – Azure SQL Database テーブルに最終出力を表示
これで、Customer Profiling サンプルが正常にデプロイされました。Customer Profiling サンプルの一部としてデプロイされたすべてのエンティティをテンプレートとして使用し、独自のデータと動作するように、要件に合わせて JSON ファイルや Hive および Pig スクリプトを簡単に編集できます。
このサンプルの詳細については、こちらのチュートリアルをご覧ください。
Azure Data Factory チームでは、3 月に公開した ADF エディターや今回行ったサンプルのデプロイの容易化によって、お客様が導入とデプロイをスムーズかつ直観的に行い、パイプラインを簡単に実行できるようにすることを目指しています。これらの新たな取り組みに対する皆様からのフィードバックをお待ちしております。利用できない機能を見つけた場合や、問題が発生した場合には、Azure Data Factory フォーラム (英語) までフィードバックをお寄せください。