Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
このポストは、2 月 6 日に投稿された Auto-Healing Windows Azure Web Sites の翻訳です。
編集メモ : 今回は、Windows Azure Web サイト チームでプログラム マネージャーを務める Apurva Joshi による記事をご紹介します。
皆さんは、Web サイトを再起動するだけで解決できるような簡単な問題に対処するために、真夜中に呼び出された経験はありませんか。このような簡単な問題を自動検出し、自動的に復旧できればとても便利です。
Windows Azure Web サイト (WAWS) に施された今回の更新では、この機能の実現に向けて、「常時アクセス」機能をいくつかの点で強化しました。この機能強化により、Web アプリケーションをホスティングしているワーカー ロールのプロセスが自動的に再起動されるようになりました。この機能は「自動復旧」と呼ばれています。ここでは、そのしくみについてご説明します。
ユーザーが行うことは、Web サイトのルートにある web.config ファイルで、トリガーとその条件が発生したときに実行されるアクションを定義するだけです。構成セクションは、大まかに次のような構造になっています。

注意 : 「常時アクセス」と同様に、この機能は標準インスタンスでのみ使用可能です。
次に、使用可能なオプションをシナリオごとに詳細に説明していきましょう。
(サポート対象となっているすべての要素と属性についての詳細な説明は、この記事の最後にあります。)
シナリオ 1 – 「要求数に基づく再起動」
Y 時間の間に X 回の要求が処理された場合、アプリケーションを自動的に再起動するとします。短時間に膨大な数の要求が送られた場合、スケーリング機能では十分に対応できないため、このような状況を検出してワーカー プロセスを自動的に再起動し、このイベントをログに記録するようにします。
この場合、次の構成例を参考にして、ルートにある web.config ファイルをこのアプリケーション用に編集します (既に web.config が存在する場合は、既存の <system.webServer> セクションの下の <monitoring> セクションにコピーします)。

上記の構成例では、10 分間に 1000 回の要求を処理した場合にワーカー プロセスを再起動し、eventlog.xml にイベントのログを記録します (eventlog.xml は Webサイトのルートにある Logfiles フォルダーの中にあります)。イベントのログ記録は、Web サイトの自動復旧が発生したことを把握し、トラブルシューティングや根本原因の解析のための重要な手掛かりを得るために役立ちます。最初の要求を受け取ったときに、timeInterval が時間のカウントを開始します。ここから要求数のカウントを開始し、timeInterval の期限に達する前に、設定した最大回数に達すると、アクションが実行されます。timeInterval の期限に達した場合、時間と要求回数の両方の値がリセットされます。上記の構成例の条件では、次のように処理が実行されます。
00:00:00 – 最初の要求を受理
00:09:59 – 998 回目の要求を処理
00:10:00 – タイマーが期限に到達したため、0 にリセット
00:10:01 – 999 回目の要求を処理
この例では、1 回目と 2 回目のどちらの timeInterval でも 1000 回の要求は発生しなかったため、アクションは実行されませんでした。
注意 : Web サイトで複数のインスタンスを実行している場合、トリガー条件に達したインスタンスのワーカー ロールのみが再起動され、他のインスタンスでは再起動は実行されません。
次に、eventlog.xml に記録されたイベントのログの例を示します。

シナリオ 2 – 「要求の応答速度の低下に基づく再起動」
アプリケーションのパフォーマンスが低下し始め、ページの表示に長い時間が掛かるようになってきたとします。このような状況を検出し、ワーカー プロセスを自動的に再起動するようにします。
この場合、次の構成例を参考にして、ルートにある web.config ファイルをこのアプリケーション用に編集します (既に web.config が存在する場合は、既存の <system.webServer> セクションの下の <monitoring> セクションにコピーします)。

上記の構成例では、直近の 2 分間で 20 回の要求の処理に 45 秒以上掛かった場合を検出します。ここで、slowRequests は各要求の実行終了時に評価されるため、timeInterval の値は必ず timeTaken よりも大きな値を設定する必要があることに注意が必要です。
注意 : Web サイトで複数のインスタンスを実行している場合、トリガー条件に達したインスタンスのワーカー ロールのみが再起動され、他のインスタンスでは再起動は実行されません。
次に、eventlog.xml に記録されたイベントのログの例を示します。

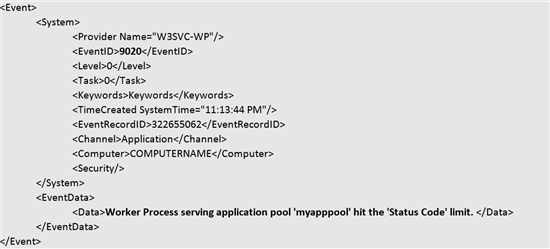
シナリオ 3 – 「 HTTP ステータスコードに基づくイベントのログの記録 ( または再起動 ) 」
Web サイトが特定の HTTP ステータス コードやサブステータス コード、win32 のステータス コードを返す場合に、ユーザーに通知するとします。このとき、イベントのログを eventlog.xml (Web サイトのコンテンツのルートにある Logfiles フォルダーの中にあります) に記録するだけか、または再起動するかを選択することができます。
次の構成例を参考にして、ルートにある web.config ファイルをこのアプリケーション用に編集します。

上記の構成例では、直近の 30 秒間に 10 個の要求に対して 500 番の HTTP ステータスコードと 100 番のサブステータスコードが返された場合、eventlog.xml にイベントのログを記録します。
注意 : Web サイトで複数のインスタンスを実行している場合、トリガー条件に達したインスタンスでのみイベントのログが記録され、他のインスタンスでは記録されません。オプションとして、イベントのログを記録するだけでなく、再起動することもできます。既定で、再起動のログは記録されるように設定されています。
次に、eventlog.xml に記録されたイベントのログの例を示します。
シナリオ 4 – 「メモリの制限に基づくカスタムアクション ( または再起動 / ログの記録 ) の実行」
Web サイトで発生したメモリ リークのトラブルシューティングを実施し、さらに、メモリ ダンプの作成、電子メール通知の送信、メモリダンプの作成とプロセスの再起動などといったカスタムのアクションを実行するとします。
この場合、次の構成例を参考にして、ルートにある web.config ファイルをこのアプリケーション用に編集します。

上記の構成例では、ワーカー プロセスのプライベートバイトが 800MB に達したと検出された場合に、カスタムのアクションとして procdump.exe を実行し、小規模なメモリダンプを作成します。要求がワーカー プロセスのパイプラインに対して作成されることはないため、自動復旧は http.sys (カーネル ドライバー) からの特定の HTTP エラー コードによってトリガーされることはありません。このようなステータス コードの例としては、304、302、400 (400 番の多くが該当しますが、例外もあります)、503 などがあります。
注意 : Web サイトで複数のインスタンスを実行している場合、トリガー条件に達したインスタンスでのみメモリ ダンプが作成され、他のインスタンスでは作成されません。オプションで、電子メールを送信するなどのカスタム アクションを実行することもできます。また、Web サイトのルート (d:\home) にある procdump.exe は、既定では使用できません。これは、Web サイトに xcopy 配置が存在する場合などが該当します。
次に、アクションで再起動を実行した場合に eventlog.xml に記録されたイベントのログの例を示します。

最後になりますが、FREB モジュールを使用すると、特定のページまたは URL に対してトリガー条件を構成できます。手順の詳細については、次のブログ記事をお読みください。
この場合、パフォーマンスに 5 ~ 10% の影響があります。また、FREB を有効化する必要があります。
注意: 共有モードと無料モードでは 1 時間後に自動的に FREB が無効化されるため、上記の手法は標準モードでも有効です。



