CLR Debugging
Improve Your Understanding of .NET Internals by Building a Debugger for Managed Code
Mike Pellegrino
Code download available at:CLRDebugging.exe(113 KB)
This article assumes you're familiar with .NET and the CLR
Level of Difficulty123
SUMMARY
With the release of .NET, the Microsoft scripting strategy has evolved. Script engines can now compile or interpret code for the Microsoft common language runtime (CLR) instead of integrating debugging capabilities directly into apps through Active Scripting. With that change comes a new set of published services for including debugging functionality in a custom host application. You'll see how to use the debugging services published in the .NET Framework to create a full-featured CLR debugger that allows you to set breakpoints, view call stacks, browse variables, view processes, enumerate threads, and perform other important debugging tasks.
Contents
CLR Debugging
CLR Debugging Overview
Debugger Types
SampleDebugger Revisited
SampleDebugger Architecture
Compiling Code
Debuggee Architecture
Debugging a Process
Breakpoints
Code Stepping
Applications Window
Call Stack Window
Application Threads Window
Processes Window
Variables Window
Conclusion
Since I last wrote about Active Script debugging about two years ago, the world of scripting has completely changed. The reason is simple: Microsoft® .NET. In the old days, Active Scripting language engines interpreted their source code and translated it into native code that was targeted to the host machine. Any language engine that provided debugging support did so by implementing a standard set of COM interfaces (such as IActiveScriptDebug). Today, script engines in .NET compile or interpret code into intermediate language (IL) to be run by the common language runtime (CLR). Because debugging now occurs at the lower level in the CLR, this changes the debugger integration and implementation strategy. In this article, I'm going to explore an integrated debugging strategy for scripting languages within .NET.
While I originally thought that the debugger would be implemented wholly in .NET, that idea quickly evaporated. Microsoft provides CLR debugger support as a set of COM interfaces. Although the new CLR COM interfaces slightly resemble Active Script debugging, there are more than 70 of them now, covering many new functional areas. In this article I will explore the CLR debugging services provided with the .NET Framework SDK, then I'll create a fully functioning debugger.
CLR Debugging
The CLR debugger is a new debugging platform designed from the ground up to support debugging any application run by the CLR. For the CLR to enable complete debugging support for all the languages it hosts, it must provide debugging services for all modern language features. Many of those new features were not captured by Active Script debugging services. This new approach increases overall complexity, but this complexity is necessary to harness the power provided by the CLR.
Such services include the addition of a class structure and support for rich types as well as many new native types. In addition, the CLR makes the actual runtime operations of the program, such as thread context inspection, process memory inspection, register set evaluation, and source code disassembly much more visible.
The CLR also provides extended runtime control. It allows the debugger to catch Control-C or Control-Break keystrokes to break a process at its current execution point, to move the instruction pointer to skip or reexecute code, and to modify the executable code at run time. The last item, known as dynamic code injection, is one of the more exciting features added to the debugger set. This feature provides the Edit and Continue capability introduced with Visual Studio® 6.0 (but which, unfortunately, did not make it into the first release of Visual Studio .NET). For example, the user can modify code while at a breakpoint, recompile, and continue executing the new code using the Edit and Continue services.
Finally, the CLR provides a whole host of notifications to the debugger when system events occur. System events, such as first and last chance exceptions, assembly and module load/unload, process and thread creation/exit, and a full data logging capability including trace levels, are available.
CLR Debugging Overview
The CLR is a low-level component within the .NET Framework. At higher levels there are user-friendly abstractions such as programming languages that make it easier to interact with the .NET Framework. Because debugging services are implemented within the CLR, they make no distinction among higher level programming languages, working in the same manner even though the language syntax and semantics may be different.
The CLR debugging services are implemented as a set of some 70-plus COM interfaces that are organized over a number of components. Those components include the design-time application, the CLR, the symbol manager, the publisher, and the profiler (see Figure 1).
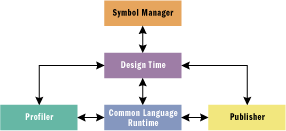
Figure 1** Debugging Architecture **
The design-time interface This contains all the functionality a user needs to write code, including the typical code and document editing capabilities. It must be implemented as a completely separate entity from the runtime. The host application can be implemented as a separate component, but it must use the CLR. The reason for this is pretty simple, and it mirrors the behavior of the traditional Win32® debug model. When the debugger breaks on some event, it halts all host processes, including all debugger threads. When the host process stops, it stops receiving user input and can never be restarted. Therefore, the design time must be separate from the runtime. By contrast, in Active Script debugging the application debugger is integrated with the host. The language engine doesn't stop the host process when a debug event occurs—it only stops the script it was interpreting.
The CLR is where code actually runs. It lives in its own Win32 host process and communicates back and forth with the CLR debugger services to perform such operations as inspection, runtime control, and Edit and Continue functionality. This is all done with the aid of a helper thread that sits in the process that's being debugged. This thread communicates behind the scenes with the CLR debugging services. It is important to understand that the CLR knows nothing about high-level languages or constructs. It knows only of Microsoft Intermediate Language (MSIL) and some metadata that is used to map the runtime code to source code.
The symbol manager This feature is probably the single largest change in the debugger architecture since the days of Active Script debugging. There was no concept of an independent symbol manager in Active Script debugging since the language engine and the host shared those services. The symbol manager represents the host behavior from the Active Script world with a set of document interfaces designed for reading and writing documents. It also provides a mechanism to store documents in an organized manner through the use of a binder. The binder is essentially a collection of documents that comprise the code that is to be debugged.
The symbol manager is responsible for the interpretation of program database (PDB) files, which contain all the data used to describe the code for the given module that is executing. Components within the system then use this data alongside the runtime metadata to present meaningful information to the software during the debugging process. PDB files are built when a module is compiled by telling the compiler to generate debug information. Each .NET module that runs within the system can have its own PDB file. The module represents the dynamic representation of the code being executed, while the PDB data represents the static representation of the code being executed.
The static and dynamic representations of code are related to each other through tokens, which are unique identifiers assigned to every element in a program. Every variable, class, class member, and function has a token associated with it. This token is part of the metadata included with each module when it is built and is part of the executable when the program is in a dynamic state. The symbol manager maintains the repository for decoding what each token means. Since a program won't generally change between successive runs, the PDB file is considered static. This repository is used to map the metadata tokens against their higher-level representations. For example, if you have a particular runtime function for which you're trying to get symbolic data, you'll get its function token and then find its match in the symbol manager to get its high-level representation. This high-level representation will include basic data like its name, function signature, and where it begins and ends in source code.
The publisher This component's functional equivalent in Active Script debugging is the Machine Debug Manager. The publisher is responsible for enumerating all running processes within the system. Facilities are provided to get descriptions of all managed and unmanaged processes running in the system. Also included are facilities to enumerate all application domains (AppDomains) within a given process. All the publishing facilities described are designed to populate user interfaces that allow developers to choose from the set of running processes and AppDomains to debug.
The profiler This component provides a set of services designed to allow you to track managed components and application performance at the CLR level. Typical profiler functionality such as runtime execution duration metrics can be captured, as can .NET-specific functionality like garbage collection performance.
Those who are familiar with the Active Script debugging architecture may be wondering what happened to the language engine within the architecture. There are still a number of language engines available, namely for JScript® and Visual Basic®, which are designed to be recognizable to those already familiar with Active Scripting. Concepts like a host and site are preserved within this structure. However, script debugging is implemented differently than it was in Active Script since debugging is handled at a lower level than the high-level language counterparts. Therefore, the new .NET language engines cannot be used for an integrated host/debugger application.
You may be wondering how to compile your source code given that you can no longer use the language engines. The solution is a new feature in the .NET library known as code compilers, which support a standard set of interfaces for compiling code. Microsoft provides a set of code compilers for the languages it supports in .NET, including C#, Visual Basic, and JScript. Through this code compiler support, the source code provided in the host application can be compiled and run in a process similar to parsing script code in Active Scripting. Other vendors also provide code compilers that are compatible with the code compiler interfaces, so those languages can be supported as well.
Debugger Types
The CLR supports two types of debuggers, each with a slightly different focus and execution model. The first is the in-process debugger which executes within the context of the host process being debugged. It provides a basic set of services and limited debugger-type behavior such as the ability to inspect the run-time state of the application and collect profiling information. Significantly lacking from the in-process debugger is the ability to modify the program's execution state, meaning that there is no way to add breakpoints, step through code, or modify program state at run time. I already touched on the reason for this limited functionality in the discussion of the design-time component. If the in-process debugger were to break on some event like a breakpoint getting hit, the entire host process would stop, including the in-process debugger, and there would be no way to resume either the debugger or the debuggee.
In-process debuggers, while limited in functionality, are quite fast. Their performance is exceptional compared to out-of-process debuggers. In situations where performance is crucial (such as collecting profiling statistics), speed is of the utmost importance. Also, in-process inspection debuggers can be written in managed code using objects exposed in the System.Diagnostics namespace.
The out-of-process debugger is the one most familiar to users of Visual Studio. The debugger runs in a separate process detached from the debuggee and is therefore decoupled from the host issues of the in-process debugger. Out-of-process debuggers provide a complete set of functionality typically associated with a debugger. They can modify the dynamic state of the debuggee and the executable using features similar to Edit and Continue. However, certain limitations come with the additional power provided by the out-of-process debugger. First, the debugger must be implemented entirely in unmanaged code. Second, the performance is not quite as good as that of the in-process debuggers (or running without a debugger) because there is considerable event communication between the debugger and the debuggee while the debuggee is executing.
In the .NET world, there are two types of code that can be executed—managed and unmanaged. Managed code executes within the confines of the CLR while unmanaged code (typically represented by legacy components) executes outside of the CLR. A managed code debugger will work on all managed code, regardless of the high-level programming language it's written in since it is completely implemented using the CLR debugger services.
Unmanaged code is generally found in existing software components and already has debugger representation in the traditional Win32 debuggers. Win32 debuggers send out event notifications to the debugger when events such as breakpoints are hit. In the case of .NET processes, the CLR acts as a proxy Win32 debugger, capturing Win32 debug events and notifying the debugger. Note that this is where unmanaged debugger support ends in the CLR. Once the event is received, it is up to the debugger to interpret what the event means and how to respond to it using traditional Win32 debugger libraries. For more information on writing Win32 debuggers, see John Robbins' book, Debugging Applications (Microsoft Press, 2000).
SampleDebugger Revisited
Active Scripting APIs: Add Powerful Custom Debugging to Your Script-Hosting App". The new version of SampleDebugger is called SampleDebugger 2.0, and is a purely managed code debugger that's designed around the .NET debugger architecture and implemented using the CLR debugging services. SampleDebugger therefore supports all .NET languages. (see the sidebar "Where's the Immediate Window?"
SampleDebugger 2.0 supports most of the features found in the first version and a few more, including breakpoints, call stack viewers, process enumeration, thread enumeration, and variable inspection and modification. There is also new functionality added for enumerating things like AppDomains and a much richer notification mechanism so events like exceptions and Control-C breaks into the application can be captured. Functionality that was typically reserved for implementation in the Process Debug Manager (PDM) in the Active Script debugging world now has visibility at the application debugger level.
SampleDebugger can easily be extended to support a whole host of additional features. For example, the CLR debugging services provide interfaces for doing things like register inspection, memory viewers, Edit and Continue-type code updates, source disassembly, and a richer breakpoint model.
In order to build SampleDebugger 2.0, you can download all the code from the link at the top of this article. You'll also want to download the latest .NET Framework SDK from Microsoft at https://www.microsoft.com/net.
SampleDebugger Architecture
SampleDebugger 2.0 is like its predecessor in regard to the base architecture of the application. It implements the design-time portion of the system by providing an editor, and it exposes a debugger controller by providing the user with mechanisms to control the application. The entire interaction between the components is done in an integrated manner that is transparent to the user.
SampleDebugger is an MFC application built using the SDI document view architecture. An edit control is used for the view class because it gives you a cheap and easy text editor with which to work. However, unlike the SampleDebugger 1.0, contents of the edit control are not fed to the language engine. Rather, the contents are handed off to another component responsible for compiling the source code into a standalone executable that the debugger will then proceed to debug. The ActiveX® Template Library (ATL) is used to implement COM interfaces for callback objects and standard MFC-based windows are used for the majority of interaction with the user.
Functionally, SampleDebugger's architecture is broken into two components comprised of managed and unmanaged code. The unmanaged code represents the MFC application and is built using Visual C++®. The managed code, written in Visual Basic, houses a special object used to compile the source code entered in the SampleDebugger text editor. A separate component is necessary because there is no way to get to the code compiler services provided by the .NET Framework using .NET Interop and unmanaged code. The preferred solution would be to directly call the code compiler services from unmanaged code through .NET Interop. However, the first version of the .NET code compiler services can't be called from unmanaged code. This situation requires you to do additional work, since you now have to create a .NET component that's also callable from unmanaged code through .NET Interop. That component then calls the code compiler services in the .NET Framework.
Inside of SampleDebugger, there are two helper classes, CDebuggerServices and CManagedCallback, which are used to make interaction with the CLR debugger services smoother. CDebuggerServices provides a wrapper around the core CLR debugger functionality to make it a bit easier to use by other components in the debugger. It is responsible for initializing the CLR, managing the current debugger state (including the current module, process, and thread being debugged), providing some utility functions for generic and repetitive communication with the CLR, and for shutting down the CLR when debugging is complete.
Initialization of the CLR debugger services begins when you create the CLR debugging services object, called CorDebug. It supports the ICorDebug interface shown in Figure 2. The CLR debugger services documentation states that ICorDebug::Initialize can only be called once during the execution of the host Win32 process. Calling it more than once in the same process may create unpredictable behavior. Therefore, initialization is done right when SampleDebugger starts so that it will maximize the time that CLR debugger services may be employed. Shutdown is done once per Win32 process, killing any processes already being debugged and allowing the application to kill the debugger session before exiting. This is an important step because the CLR will maintain references to objects given to it until ICorDebug::Terminate is called (see Figure 2).
Figure 2 ICorDebug
interface ICorDebug : IUnknown { HRESULT Initialize( ); HRESULT Terminate( ); HRESULT SetManagedHandler( [in] ICorDebugManagedCallback *pCallback ); HRESULT SetUnmanagedHandler( [in] ICorDebugUnmanagedCallback *pCallback ); HRESULT CreateProcess( [in] LPCWSTR lpApplicationName, [in] LPWSTR lpCommandLine, [in] LPSECURITY_ATTRIBUTES lpProcessAttributes, [in] LPSECURITY_ATTRIBUTES lpThreadAttributes, [in] BOOL bInheritHandles, [in] DWORD dwCreationFlags, [in] PVOID lpEnvironment, [in] LPCWSTR lpCurrentDirectory, [in] LPSTARTUPINFOW lpStartupInfo, [in] LPPROCESS_INFORMATION lpProcessInformation, [in] CorDebugCreateProcessFlags debuggingFlags, [out] ICorDebugProcess **ppProcess ); HRESULT DebugActiveProcess( [in] DWORD id, [in] BOOL win32Attach, [out] ICorDebugProcess **ppProcess ); HRESULT EnumerateProcesses( [out] ICorDebugProcessEnum **ppProcess ); HRESULT GetProcess( [in] DWORD dwProcessId, [out] ICorDebugProcess **ppProcess ); HRESULT CanLaunchOrAttach( [in] DWORD dwProcessId, [in] BOOL win32DebuggingEnabled ); };
Once the CLR is up and running, a managed callback must be registered with it. The managed callback is used by the CLR to communicate to the debugger any events that occur within the system through an instance of an ICorDebugManagedCallback interface. The CManagedCallback class implements the ICorDebugManagedCallback interface and receives all notifications from the CLR on behalf of SampleDebugger. This managed callback object is created during initialization of the CLR and is registered with the CLR through ICorDebug::SetManagedHandler. There is also an unmanaged callback type that can be registered with the CLR for receipt of Win32 debugger events. While the implementation is nearly identical to registering the managed callback, the unmanaged callback is skipped because SampleDebugger is only interested in debugging managed code.
ICorDebugManagedCallback is a rich interface that supports 26 different CLR notification types. If you take a close look at this interface, it's obvious that the debugger is much more aware of events that are occurring in the system at run time than in the Active Script debugging world. This debugger is now aware of a number of activities, which are described in Figure 3.
Figure 3 Debugger-recognized Events
| Event | Description |
|---|---|
| Process events | When processes are created and exited |
| Thread events | When threads are created and destroyed |
| Application domain events | When application domains are created and destroyed |
| Assembly events | When assemblies are loaded and unloaded |
| Module events | When modules are loaded and unloaded |
| Class events | When classes are loaded and unloaded |
| Breakpoint events | When breakpoints and program breakpoints are hit and when breakpoint set errors occur |
| Log events | When log messages to the system console are received and passed on |
| Execution events | Execution events such as step operation and code evaluation completion, exceptions, and general debugger errors |
Whenever a callback is executed a number of things occur. First, the process is placed into a synchronized state—that is, a known, predictable state of execution. This is important because it would be undesirable for the process to continue running while the debugger was attempting to interact with it in a potentially dangerous way, such as modifying its runtime state. Generally speaking, attempts to use CLR debugger services when the process is not in a synchronized state will result in the error CORDBG_E_PROCESS_NOT_SYNCHRONIZED being returned and the operation failing to complete.
Once a notification is received by the managed callback, the process is in a stopped state. To continue the process requires instruction to the CLR from the IDebugController interface, but the application doesn't support this interface. Instead, the interface is supported by processes (the COM interface ICorDebugProcess) and application domains (the COM interface ICorDebugAppDomain) hosted in the CLR, both of which derive from IDebugController. IDebugController has a method called Continue that is used to resume the process in the CLR. If IDebugController::Continue is never called, the process will stop responding and remain in a stopped state. It will appear as if the process being debugged were hung. With every callback, the CLR provides either the AppDomain or the process that generated the event so there is always a means to resume the process. This is a simpler, more direct mechanism to use than in the Active Script debugging world where the thread was issued during the notification and from that, the parent application had to be queried and subsequently resumed.
Compiling Code
Getting code into a compiled executable changes with SampleDebugger 2.0. In the first version, the code was handed to the language engine for parsing and then execution. In the new version, SampleDebugger has a component that uses classes within the .NET Framework, called through .NET Interop, to provide the compiled executable that you need to debug. This component takes advantage of code compilers, which take some source code of a given language and generate an executable based on that source code. Code compilers support a standard interface, namely ICodeCompiler, which provides services that will take source code directly provided to it from a text buffer or source files and then build an executable complete with debug information.
SampleDebugger contains a .NET component that will compile code. Written in Visual Basic, it supports a single object with a standard interface, ISampleDebuggerCompiler, which has a single method called Compile. ISampleDebuggerCompiler::Compile takes file paths to both the source code (only one file is supported, just like in SampleDebugger 1.0) and the target executable that is to be built. When it is complete and the source code is successfully compiled, the executable will be at the path provided and the return value will be true; however, if there are compile-time errors, then there will be no executable created and a value of false will be returned.
The source code for SampleDebuggerCompiler is shown in Figure 4. Visual Basic was my host language, but any .NET language that has compiler support for ICodeCompiler can be used.
Figure 4 SampleDebuggerCompiler
Imports System Imports System.CodeDom.Compiler Imports Microsoft.VisualBasic Namespace SampleDebugger Public Interface ISampleDebuggerCompiler Function Compile( codeToCompile As String, outputFileName _ as String) As Boolean End Interface < System.Runtime.InteropServices.ComVisible( True ) > _ Public Class SampleDebuggerCompiler : Implements ISampleDebuggerCompiler Function Compile( codeToCompile As String, outputFileName as _ String) As Boolean Implements ISampleDebuggerCompiler.Compile Dim cc as ICodeCompiler Dim results as CompilerResults Dim vbp as new VBCodeProvider() cc = vbp.CreateCompiler() Dim options as new CompilerParameters options.GenerateExecutable = true options.IncludeDebugInformation = true options.OutputAssembly = outputFileName dim source as string source = codeToCompile results = cc.CompileAssemblyFromFile( options, source) If results.Errors.Count = 0 Then Compile = True Else Compile = False End If End Function End Class ' SampleDebuggerCompiler End Namespace ' SampleDebugger
As you can see, the source code is pretty straightforward. To build a source file into an executable, the compiler must first be created. An instance of the Visual Basic compiler was created here, but substituting another engine would also work. Once that is done, the compiler parameters must be set, which is the equivalent of command-line parameters for most compilers. Note that special steps are taken to indicate that debug information is desirable. Doing so will cause the compiler to generate the PDB file necessary to map the executable code to the source code. Finally, the compilation process is initiated. Any errors encountered along the way are reported back through the CompilerResults collection. If the collection is empty, indicated by an Error collection count of 0, the compilation was successful.
To build the app, I provide a basic batch file to do all the work. The component must first be built, then linked, then registered with the global assembly cache (GAC), and finally moved into the GAC. I created a batch file to do all of this because I noticed that my component couldn't be called after each time it was built. The reason for this is that the GUIDs associated with my object and its interface changed each time the source code was compiled. Therefore, a batch file makes haste of all the steps needed to get the .NET component ready for calling through .NET Interop. For a more complete discussion of .NET Interop, see David Platt's article, ".NET Interop: Get Ready for Microsoft .NET by Using Wrappers to Interact with COM-Based Applications".
I should note that SampleDebuggerCompiler presumes a naive approach to library usage in the .NET code that's passed to the compiler. SampleDebuggerCompiler only includes the default system libraries. To add additional libraries, those compiler references would need to be set as well. This would include modifications to ISampleDebuggerCompiler::Compile as well as the debugger to support adding project references. The user would select project references in much the same way as they might in Visual Basic. Then the path names for those referenced components would be added to the compiler parameters before the code is compiled.
Debuggee Architecture
Before I get into the procedures for starting a debuggee, it's good to know a little bit about its structure. All processes in the system, managed and unmanaged, are represented by an instance of ICorDebugProcess. ICorDebugProcess provides the basic identity type data that is used to drive user interfaces and some utility services, but it also includes facilities to enumerate AppDomains, modules, and threads.
AppDomains, as represented by ICorDebugAppDomain, are the replacement for IRemoteDebugApplication in the Active Script debugging world. AppDomains are similar to Win32 processes in that they offer protection against AppDomains crashing other AppDomains; however, the context switching between AppDomains is a lot quicker than the Win32 process. The speed doesn't come without a cost, though. In the current version of the CLR, when one AppDomain blocks (say, when a breakpoint is hit), so do all the other AppDomains within the process. AppDomains contain a number of assemblies, each one of which is a collection of modules that, when combined together, form a deployable software package. Assemblies do not contain code, though. Rather, code is found in modules, which are the items packaged into the assembly.
Modules contain all the code that is run as well as the metadata used to map source code to executable code. Like almost all the components in the CLR, modules provide some basic identity information and can be used to configure the CLR for certain types of operations such as just-in-time (JIT) debugging and class load/unload notifications. Figure 5 shows the relationship between the process, an AppDomain, an assembly, and a module.
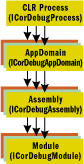
Figure 5** Components **
Debugging a Process
When a SampleDebugger 2.0 user enters code into the editor and chooses to debug it, a number of things need to occur before debugging actually starts. First, the module must be compiled. Using the SampleDebuggerCompiler component that I discussed earlier, the source code is compiled and saved to a known file location. Note that an external file must be used to execute and debug the code because the CLR must manage the entire lifetime of the process. I used a temporary file in the same directory as the source file as a starting point and named it debuggee.exe. Barring any compiler errors, a ready-to-debug executable should be waiting as the external file specified by SampleDebugger.
At this point, the process needs to be created. I used a function called DebugProcess, which I wrote into CDebuggerServices and which take the path to the executable that is being debugged and starts it. ICorDebug provides the CreateProcess method to start the process for debugging, which looks remarkably like its Win32 equivalent. Most of the parameters are the same as in the Win32 call; however, it's important to note two distinguishing characteristics of ICorDebug::CreateProcess. First, there is a new flag after the process information structure that provides CLR-specific instructions for creating the process. Currently, there is only one option, DEBUG_NO_SPECIAL_OPTIONS, but the functionality is in place for future support for such actions. The other new parameter is a reference to an ICorDebugProcess interface, which represents the newly created process. SampleDebugger stores this reference for future use in CDebuggerServices.
There is no further interaction directly with the CLR until SampleDebugger is notified of debug events through its registered managed callback. The process object that was returned can be called and controlled from that reference (which is fine as long as the process is running); however, many of the calls to control the process will fail because the process is not in a synchronized state.
Where's the Immediate Window?
Those familiar with the first version of SampleDebugger based on Active Script debugging services will notice that this updated version drops the Immediate window. It does so because the CLR debugging services don't provide the same mechanism for evaluating expressions that was used in Active Script debugging. In Active Script, the language engine would parse and execute the code that was to be evaluated. Therein lies the rub. Compilation of the code is now separate from its execution since the high-level language representation of an expression is not understood by the CLR.
Fortunately, the CLR provides mechanisms for variable inspection and the execution of functions. While function evaluation is a new concept here, variable inspection is performed in a similar way to what was done in the Variables window. The CLR allows you to execute a given function and then it tells the caller of the function's return value. It does this through the ICorDebugEval interface, which is retrieved by creating an evaluator from a given thread. Once the ICorDebugEval interface is retrieved, calling the CallFunction method of that interface will allow the debugger to execute function code within the debuggee.
Having the ability to inspect and set variables and to execute functions provides the basic building blocks to build an expression evaluator. The debugger would collect the raw text that represents the expression and parse it out according to the syntax and semantics of the language in which the expression is written. Then, it would begin executing the expression a chunk at a time, using some data buffers to store intermediate results before the final answer is returned to the user.
At this point, the app is started, but it is not necessarily being debugged yet. If you look at the code in CManagedCallback::CreateAppDomain, you'll see the following statement and comment:
// Attach to this app domain. This is similar to calling // IDebugApplication::ConnectDebugger in the active scripting world. // We must call Attach here before we can use any of the methods of // IDebugController for the pAppDomain hr = pAppDomain->Attach( );
The application domain must first be attached to the debugger before application domain debugging can occur. This is identical in behavior to the Active Script IDebugApplication::ConnectDebugger function. The connection is required because the user may want to attach or detach from the application during the debugging process. Before making the call to attach on the AppDomain, the process was merely started within the CLR. Attaching to the AppDomain when it is created indicates that it is being debugged.
Breakpoints
You may notice that there hasn't been any mention of when to set breakpoints within the debuggee. In the Active Script debugging world, breakpoints are typically added just before the code is executed. SampleDebugger 2.0 uses a window and breakpoint insertion mechanism similar to version 1.0, but in the CLR world, breakpoints are added later, when the CLR notifies SampleDebugger of some events via the managed callback.
There are different kinds of breakpoints supported natively in the CLR. Traditional breakpoints can be set within a particular function that will be called when a given line of code is hit. Breakpoints can also be set at the module level so the debugger is notified whenever code in a given module is executed. Value breakpoints can be set for a given variable (known as a value in the CLR nomenclature), so that when the value is updated, the CLR automatically notifies the debugger of the change so that it may respond. The CLR will notify the debugger when errors are encountered when setting breakpoints.
CLR breakpoints are not as intuitive to the debugger writer as they are in Active Script debugging. In Active Scripting, the language engine takes the source code and does the mapping to figure out the code contexts in which to add a breakpoint. This is not the case in the CLR since, again, it knows nothing about the higher-level source code that represents the IL that the CLR is executing. This makes it somewhat difficult to tell the CLR where to set a breakpoint for the debugger. The concept of a source line isn't used at all in the CLR.
What the CLR understands is IL and the instruction pointer, which indicates the current instruction being executed. The instruction pointer's value is an offset from a base address for a given execution context. If the execution context were a function in a block of code, the base address for the context would be the beginning of the function and the offset (the instruction pointer) would be relative to that base address. The following output from ILASM.EXE on some sample code displays the difference between the high-level language and the IL code:
//000024: BigIntegerGuy = BigIntegerGuy + 1 IL_0022: /* 06 | */ ldloc.0 IL_0023: /* 17 | */ ldc.i4.1 IL_0024: /* D6 | */ add.ovf IL_0025: /* 0A | */ stloc.0
The top line is the high-level source code in Visual Basic and the remaining four lines are its IL representation. Note that there are four instructions employed to add the number 1 to a variable. The IL offset is the reference to the left beginning with the characters IL and the actual code is to the right.
The trick becomes how to take a line of source code, which maps to one or more instructions, and properly map it to the instruction set represented by that line of code. This behavior lets the user know when and on what line a breakpoint was hit. The CLR cannot provide such data, but the symbol manager can provide it to the debugger through the use of an abstraction called a sequence point, which is basically an executable statement in the high-level language. For example, the following represents a sequence point in code:
...Some code before this... variable = variable + 1; ...Some more code after this...
A sequence point is not a line of code, for there can be many sequence points on a given line of code. Consider the following:
GetObject( )->GetSubObject( )->DoSomething( );
A sequence point represents each function call in this example code. GetObject is a sequence point, as are GetSubObject and DoSomething. If there was any construction going on behind the scenes, those sequence points would be implicitly represented here as well. Furthermore, multiple code statements separated by a semicolon on the same line constitute different sequence points, such as in the following example:
X = X + 1; Y = Y + 2;
Sequence points are the key for the debugger to map IL to source code because they are represented as offsets from the base address of the context, just like the instruction pointer. The symbol manager can provide all the sequence points for a given function and the source lines where they occur. This means that once the sequence points are known, it is relatively straightforward to find the source code for the current instruction pointer. SampleDebugger takes the following steps:
- From the current frame, the SampleDebugger application queries for its IL frame.
- From the IL frame, it retrieves the current instruction pointer (which is an offset from the beginning of the function).
- From the current frame, SampleDebugger retrieves the current function through ICorDebugFrame::GetFunction.
- From the current function, the debugger retrieves its token.
- Using the module's metadata, the debugger retrieves the symbolic method for the runtime function.
- From the symbolic method, SampleDebugger retrieves its sequence point count, allocates some space to hold the data, and then retrieves the method's sequence points.
- SampleDebugger then searches each sequence point returned, comparing its offset (which is an instruction pointer offset) to the current instruction pointer offset from Step 2.
- When a match is made, SampleDebugger looks at the source line where the sequence point occurred and stops searching the remaining sequence points. Matching the instruction pointer to the sequence point implicitly matches the current instruction pointer to the line of source code that is executing.
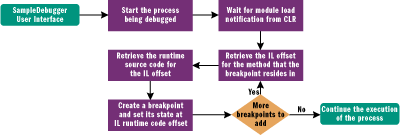
Figure 6** Finding Breakpoints **
Once you know how to decode where breakpoints have occurred, they need to be added. Ultimately, breakpoints belong with the module (which contains the code) to which they are matched. Since the debugger is notified when a module is loaded through the managed callback, all it has to do is wait for the notification from the CLR and then add the breakpoints as needed. The steps to adding the breakpoints can be viewed in CManagedCallback::LoadModule (in ManagedCallback.cpp) and CDebuggerServices::AddBreakpointToModule (in DebuggerServices.cpp in the code download). Figure 6 shows how this process works. The steps can be summarized as follows:
- Start the process and wait for the module load notification.
- Match the module name to the module being debugged.
- Retrieve the module's metadata interface so source code can be matched to IL.
- Retrieve a symbol reader and then get the document from it.
- Retrieve the method from the document position for the given breakpoint.
- Retrieve the method's token.
- Retrieve the method's IL offset from the beginning of the method.
- Retrieve the runtime function from the CLR from the current module based on the token previously retrieved.
- Retrieve the IL code for the runtime function.
- Create a breakpoint on the code returned and set it (whether it's active or not).
- Add additional breakpoints by repeating Steps 6-11 until all breakpoints are added.
- Continue the process that was stopped on the module load notification.
Removing breakpoints is a little more difficult since there is no way to remove them in the CLR, so the removal must take place at a higher level. The CLR knows only two states for a breakpoint once it is created: active or inactive. If it is active, the CLR notifies the debugger through the managed callback of a breakpoint event. If the breakpoint is not active, then there is no notification. Thus, to remove breakpoints, they are merely deactivated and never reactivated. SampleDebugger just deletes removed breakpoints from its list so the user never sees them again.
Breakpoints are removed from the module by default when it is unloaded; they do not persist with the module. Breakpoint persistence and other concepts like conditional breakpoints (where a breakpoint is executed a certain number of times, or when a variable meets certain criteria) are higher-level concepts that are not natively supported by the CLR. The debugger writer implements such functionality.
The CLR uses different callback types for the different kinds of break events that occur within the system. All breakpoints, regardless of type, are notified through ICorDebugManagedCallback::Breakpoint. There are also callbacks to detect a Ctrl-Break or Ctrl-C keystroke within an application. The CLR notifies the debugger of this through the ICorDebugManagedCallback::Break event. In this case, there is no identified current thread that is executing, so debugging a multithreaded application will take some consideration on the part of the debugger implementer. Thought should be given, for example, to what thread is shown in the Call Stack window.
Code Stepping
If you thought breakpoints were a lot of work, then you'll love code stepping. In Active Script debugging, stepping was pretty simple. When the application resumed, there was a flag to indicate whether the code was being stepped or continued. This is not the case with the CLR, which provides objects that perform the actual stepping operations called steppers, represented by the ICorDebugStepper interface (which is retrieved from the current thread being debugged). ICorDebugStepper provides services to step a single instruction which, while useful in a disassembly view, is not of much value for stepping high-level source code. Steppers can also step over a range of instructions, which is what a high-level language debugger would use. The debugger will use the symbol manager to get a range of instructions represented by a line of code and step over the entire range in one operation. Once it is determined how to step, either by single instruction or by range, it's just a matter of telling the CLR whether to step in or over the code. Check out CDebuggerServices::Step in DebuggerServices.cpp for more detail on how this occurs.
Stepping out of code is much more straightforward than stepping through it. ICorDebugStepper provides a method to step out of the current context. This is much easier to implement because you don't have to worry about mapping between the source code, range data, or interaction with the symbol manager. Once the code is stepped, the process is continued in the standard way through ICorDebugController.
Applications Window
The Application Domain window enumerates all application domains in a given process and displays their name. The bulk of the work is done in CApplicationsDlg::OnInitDialog in ApplicationsDlg.cpp. There the application domains are enumerated and each AppDomain's name is retrieved and added to the window. While the window doesn't currently do anything else, it could be extended to allow you to attach or detach a debugger to a given application domain. This would give the user the ability to start debugging an application domain already running (known as a soft attach) or to stop debugging an application domain without actually terminating it (known as a soft detach).
Call Stack Window
The Call Stack window is a familiar component in debuggers. It shows the user where they are in the program and how deep the call tree is at the time of inspection. The CLR provides a rich set of services to interact with call stacks. It needs to do this because the concept of a call tree, while essentially the same in .NET, is complicated by the fact that code can be created in various languages and can also span managed and unmanaged modules. SampleDebugger implements a basic Call Stack window based on the current thread. This window can easily be extended to support all current application threads.
Call stack user interfaces traditionally involve iterating over the stack frames and building up the call tree from there. However, call stacks in the CLR are comprised of both managed and unmanaged code, which complicates things. Since the individual addressing schemes and the way debugging occurs for managed and unmanaged code are so different, that approach is not sufficient. There are still stack frames in the CLR, but there is also a higher-level entity known as a chain that is used to group related stack frames together.
Chains represent a portion of managed or unmanaged code that may span multiple modules. Chains are represented by the ICorDebugChain interface and are retrieved from the current thread object through an enumerator object returned by ICorDebugThread::EnumerateChains. ICorDebugChain provides a host of services for navigation among chains around it (such as previous chain and next chain, caller and callee) as well as a standard set of identity functions for information like execution context, registers, address range, and whether the chain represents managed code. Since SampleDebugger will only display managed frames, it is interested in this last property, which identifies the chain as managed or unmanaged. Once a given chain is retrieved, the familiar stack frames can be enumerated from the chain through ICorDebugChain::EnumerateFrames, which are represented by an instance of ICorDebugFrame.
Stack frames are finer in granularity and represent code on contiguous stack space. The frame supports navigation functions similar to chains to get previous/next stack frames, but what's required is the ability to get the current function represented by the frame. By calling ICorDebugFrame::GetFunction, the function represented by the stack frame is returned as an ICorDebugFunction instance. ICorDebugFunction represents the actual function being called, providing access to data through its metadata interface. SampleDebugger uses a small portion of that data (for example, just the function name), but it can be extended to provide all sorts of meaningful data such as function arguments, current argument values, and current execution address. What is interesting is that there are no direct methods to get the function's metadata interface, so SampleDebugger uses the metadata interface for its parent module and then uses the symbolic token associated with the runtime code to get its design-time description (see Figure 7).
Figure 7 Getting Function Name from Runtime Function
// Error checking code removed for brevity mdMethodDef functionTokenToGetNameFor; hr = activeFunction->GetToken( &functionTokenToGetNameFor ); hr = activeFunction->GetModule( &activeModule ); // Get a metadata interface so we can hook up to the symbol reader hr = activeModule->GetMetaDataInterface( IID_IMetaDataImport, reinterpret_cast< IUnknown ** >( &metaDataInterface ) ); mdTypeDef classToken = mdTypeDefNil; // Class we want to get // method for. WCHAR methodName[256]; // Buffer to store name ULONG methodNameLength = 0; // Length of method name // placed into buffer by // GetMethodProps PCCOR_SIGNATURE signatureBlob = NULL; // Actual blob of metadata (we // don't use it) ULONG signatureBlobSize = 0; // Size of metadata blob we // don't use DWORD methodAttr = 0; // Attributes for method // (yep—unused) hr = metaDataInterface->GetMethodProps( functionTokenToGetNameFor, &classToken, methodName, sizeof( methodName ), &methodNameLength, &methodAttr, &signatureBlob, &signatureBlobSize, NULL, NULL ); USES_CONVERSION; m_callStackList.InsertString( m_callStackList.GetCount( ), W2T( methodName ) );
Unmanaged chains will have no frames that can be viewed in this way. To get stack data for unmanaged frames, you'd have to use more traditional services in the Win32 debug library.
Application Threads Window
The .NET Framework supports a complete set of threading facilities regardless of the language you use. By necessity, the CLR must provide a robust set of threading services to assist the developer in debugging multithreaded applications. Such services include the ability to enumerate all threads, suspend and resume threads, inspect thread context and registers, and retrieve thread identity. While the CLR provides extensive services, SampleDebugger uses only a subset of those for its Application Threads window (see Figure 8).
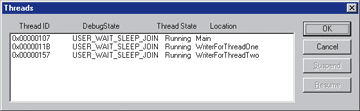
Figure 8** SampleDebugger 2.0 Threads Window **
The Threads window functions as it did in SampleDebugger 1.0, displaying all the threads within the current process debuggee, plus information including thread ID, current debug state, thread state, and the function at the top of its call tree. In the window's OnInitDialog handler, the threads are enumerated for the current running process. Each thread that is part of the current process is stuffed into a separate object of the CDebuggerThread class. CDebuggerThreads are used to abstract a bit of the thread interaction. Since most of these properties are directly accessible from the thread through its ICorDebugThread interface, this may, in fact, appear to be overkill.
The thread ID is pretty straightforward (that is, the thread state and debug state), however getting the current thread location is not as trivial. The code to get the thread location is identical to the code used in the Call Stack window. The only difference is that in the case of the Application Threads window, only the first stack frame in the managed chain of the call tree is used. The Call Stack window includes all stack frames in all chains. Since the window updates its data when threads in the window are suspended or resumed, this update is cleaner if the logic is outside the window. If there are no managed chains and frames within the thread, then nothing is displayed for the thread.
Suspending and resuming threads within the window is fairly straightforward. Each thread has state information associated with it that can be either running or stopped. This state can be queried from the current thread through the ICorDebugThread::GetDebugState method, which returns the thread state as an enumeration. The state can be set through the orthogonal ICorDebugThread::SetDebugState method. The signature for both methods is shown here:
HRESULT GetDebugState( [out] */ CorDebugThreadState *pState); HRESULT STDMETHODCALLTYPE SetDebugState( [in] */ CorDebugThreadState state;
CorDebugThreadState is an enumeration defined in the Framework SDK in CorDebug.idl and can be one of two values: THREAD_RUN or THREAD_SUSPEND. To suspend a given thread, set its debug state to THREAD_SUSPEND. To resume the thread, set its debug state to THREAD_RUN. Review the source code in DebuggerThread.cpp to see this in action.
Processes Window
Processes in the CLR are a new entity relative to the Active Script paradigm. While CLR application domains and Active Script remote applications approximate the same functionality, there is no real equivalent in the Active Script world for a process. For a good reason, too—the script code always runs in-process to the host. I've already shown why processes are needed with CLR debugging, so now I will explain how they can be enumerated and interacted with through the Processes window.
The Processes window uses the publisher component, discussed earlier, to enumerate and list all managed processes in the system (the publisher does not display unmanaged processes).
The UI simply displays the current process ID and the name of the process. The data is extracted from an enumeration returned by the publisher in the window's OnInitDialog handler (see Figure 9).
Figure 9 ProcessesDlgOnInitDialog
BOOL CProcessesDlg::OnInitDialog() { // local variables ICorPublish *corDebuggerPublisher = NULL; // Used to iterate // published processes ICorPublishProcessEnum *activeProcesses = NULL; // Used to enumerate // all applications ICorPublishProcess *currentProcess = NULL; // Active process we're // enumerating HRESULT hr; // COM function return // code // BEGIN // Error code , exception handling code, and base dialog code // removed for brevity hr = ::CoCreateInstance( __uuidof( CorpubPublish ), NULL, CLSCTX_INPROC_SERVER, __uuidof( ICorPublish ), reinterpret_cast< LPVOID * >( &corDebuggerPublisher ) ); // To maintain original SampleDebugger behavior, // we only look at the managed processes hr = corDebuggerPublisher->EnumProcesses( COR_PUB_MANAGEDONLY, &activeProcesses ); hr = activeProcesses->Reset( ); static const int const NUMBERITEMSTOFETCH = 1; unsigned long numberItemsFetched = 0; while( activeProcesses->Next( NUMBERITEMSTOFETCH, ¤tProcess, &numberItemsFetched ) == S_OK ) { // If no items were fetched, then none were available // so let's just get outta here if( 0 == numberItemsFetched ) { break; } // end if( 0 == numberItemsFetched ) unsigned int processID = 0; // ID of process we're working // with WCHAR processName[MAX_PATH]; // Name of the process we're // working with unsigned int processNameLength; // Length of name received back CString processDescription; // String used to describe process // in dialog hr = currentProcess->GetProcessID( &processID ); hr = currentProcess->GetDisplayName( sizeof( processName ), &processNameLength, reinterpret_cast< WCHAR * >( &processName ) ); processDescription.Format( _T( "0x%08X\t%S" ), processID, processName ); m_processesList.AddString( processDescription ); currentProcess->Release(); } // end while( activeProcesses->Next( ... ) == S_OK ) } // end CProcessesDlg::OnInitDialog
First, the publisher component is created and an enumeration, containing a collection of ICorPublishProcess interfaces that represent running processes, is retrieved from it. SampleDebugger 2.0 maintains the spirit of the Active Script version, asking the publisher for only the managed processes. ICorPublishProcess has a set of properties retrievable to get display identity data within the window. Like the Applications window, this can be extended to permit the user to debug an active process. ICorDebug can attach to a process already executing within the system through its DebugActiveProcess method. To do this, you take the process ID returned by the publisher component and use it to identify the process to attach to in the call to ICorDebug::DebugActiveProcess.
Variables Window
In the Active Script debugging version of SampleDebugger, the Variables window was the most complex of all that were implemented. This is most certainly the case in the SampleDebugger 2.0 Variables window as well (see Figure 10). Most of the complexity of the window is introduced because the CLR supports a host of new variable types (such as arrays and native types) and has different interfaces for accessing each one of them. Therefore, to interact with them in a uniform manner requires a bit of work.
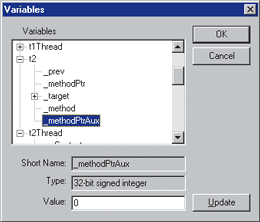
Figure 10** Variables Window **
The Variables window is more complex mainly because of the way the different data types are accessed. The CLR provides for a host of different data types, from basic types like integers, characters, and floats, to object instances, arrays, strings, and reference types. Each has its own mechanism for accessing the data that is populated in the Variables window. Active Script debugging spoiled us because it treated all data types in the same way, regardless of the type it represented. The CLR ultimately does something similar for getting and setting variable values, but getting to that point takes considerably more work.
Let's drill into the differences between the Active Script and CLR-based methods of variable interaction. First, the concept of class member variables is new in this Variables window. Active Script debugging provided interfaces based on properties, which could have been function locals, function parameters, or properties of COM objects; these interfaces don't distinguish among the types. Second, properties of COM objects are not included at all in the CLR debugging services. In the Active Script debugging realm, if I were to drill into an object to see its properties, all properties exposed through COM would be displayed. This doesn't happen by default anymore. To implement this functionality, you would need to search the symbol information for each object and inspect each method in it to determine whether it was a property get or property put function. Once that was determined, the get function would need to be executed to retrieve the value (where it's desirable to display the current value), or the put function would be executed to update the value using function evaluators.
Next, there's an issue that has been encountered over and over again in the article: how to map design-time constructs, such as variable names, to the runtime equivalent. Remember that the runtime knows nothing of high-level constructs like variable names. What it does know about are fields and offsets. Fields are class members, and offsets are local variable IL offsets from a base address just like they were with functions. The mapping between variable names and their IL representations is the same as it was for functions. Metadata is used alongside tokens to perform the design-time-to-runtime mapping.
The next new concept is variable scopes. Although Active Script debugging supported scopes, it did not support the distinction of nested scopes within a local function scope. Such scopes may be represented as follows in a high-level language:
int FunctionWithNestedScope( void ) { int someVariable; { // begin nested local scope int someOtherVariable; } // end nested local scope } // end FunctionWithNestedScope
In the sample I just showed, there are two scopes in FunctionWithNestedScope. The integer someVariable is in one scope, while the integer someOtherVariable is in the second nested scope. Active Script debugging never enabled this kind of granularity because all variables were scoped at the function level. The CLR provides mechanisms such as these for traversing scopes and for enumerating all variables at the local scope level, as well as for traversing nested scopes.
The Variables window is programmed to recursively parse the scopes of the current thread. This ensures that all local variables are captured properly in the Variables window. The only problem is that the scopes are a design-time phenomenon tied to a symbolic method. The first thing you must do is get the symbolic method from the runtime function using the same practices of matching through tokens (as in the Call Stack and Application Threads windows). Once the symbolic method is retrieved, the first scope in the function, known as the root scope, is retrieved through ISymUnmanagedMethod::GetRootScope.
The GetRootScope call returns an ISymUnmanagedScope interface pointer. ISymUnmanagedScope provides services to do two things that are important to SampleDebugger. First, it provides a mechanism to get nested scopes through its GetChildren method, which allows SampleDebugger to iterate the child (nested) scopes and look for their variables. Scopes can be nested indefinitely, so SampleDebugger recursively processes these scopes through the CVariablesDlg::AddVariablesToTree method in VariablesDlg.cpp. Second, the scope provides a way to get all the local variables for the scope through its GetLocals method.
The CLR does provide the means to drill into a given variable to get characteristics such as type and size. Variables are represented by the ICorDebugValue interface whose signature is as follows:
ICorDebugValue : public IUnknown { public: HRESULT GetType( /* [out] */ CorElementType *pType); HRESULT GetSize( /* [out] */ ULONG32 *pSize); HRESULT GetAddress(/* [out] */ CORDB_ADDRESS *pAddress); HRESULT CreateBreakpoint( /* [out] */ ICorDebugValueBreakpoint **ppBreakpoint); };
ICorDebugValue provides the ability to get the basics on a variable such as its type, size, and address. It also provides a way to create and set breakpoints to detect when the variable changes. This is great functionality and provides for a nice future extension to SampleDebugger. However, ICorDebugValue lacks the ability to get and set the value of the variable. The reason is that ICorDebugValue can represent complex data types as well. For those types, the concept of a single value doesn't apply. The ICorDebugGenericValue interface provides the necessary functions to get and set the variables value and can be retrieved by querying the ICorDebugValue for its ICorDebugGenericValue interface. SampleDebugger does all this, but wraps each variable in a separate object of the CVariable class. This consistent interface makes variables easier to interact with regardless of type. For example, setting integer values is similar to, yet slightly different from, setting floats.
The CLR supports references for types and boxed variables. Reference types are pretty straightforward, and the CLR provides a means to dereference them before they are used. Once the variables are dereferenced, they are interacted with in the same way as value-type variables. Boxed variables are a little more interesting because they are value-types that have been converted to an object. In order to interact with them to get and set a boxed variable value, it must first be unboxed, which gets back the value-type variable. From there, the value can be used in a manner consistent with value-type variables.
Complex variable types that have member variables (like classes) support the inspection of those members. To get to those members, the variable must first be identified as a class through a query of the actual value for the ICorDebugObjectValue interface. Once it's identified as an object through a successful query for ICorDebugObjectValue, then the class's member variables can be retrieved. Class member variables, known as fields in the CLR, support the same types of mechanisms for interaction as local variables. Therefore, it is possible for a given field to get either its ICorDebugValue or ICorDebugGenericValue interface to get and set the field's value. The primary difference in the access of fields versus local variables is within the symbol manager. Fields are properties of classes, whereas locals are properties of a scope.
Classes have a different mechanism for retrieving their fields, in the form of design-time and runtime representations that are mapped by a token. The runtime class is represented by the CLR with the ICorDebugClass interface. The design-time class is represented by the module metadata interface and the class token. Using the module metadata interface, the class token is passed to enumerate all the fields that match the class token. Then, for each field, the runtime class is used to get its corresponding ICorDebugValue interface. Once that is retrieved, the field is treated like a local variable and added to the tree. Finally, once all the members for a given class are retrieved, SampleDebugger traverses up the class hierarchy to retrieve all parent class members, which gives the user the most visibility into the program state.
I mentioned that services are provided within the CLR to inspect and update complex types such as arrays and strings. SampleDebugger doesn't currently implement these, but they represent a more simple case to implement compared with an implementation that inspects classes. Instead of querying the actual value for ICorDebugObjectValue, it would be queried for ICorDebugArrayValue or ICorDebugStringValue. From there, the complex types can be broken down into simpler types and added to the Variables window.
Conclusion
I must admit that the course of this article has changed somewhat significantly from what I originally intended. The simple swap-in of script debugging technology from one platform to another didn't quite go according to my master plan. But I wasn't disappointed with the course I wound up taking. It's clear after undertaking the project that the Active Script debugging services were not going to be able to handle the advanced features common to the new .NET script languages and subsequently all languages running in the CLR. This is where the CLR steps up and provides all the requisite functionality to create an advanced debugger that can support integration into a custom host application.
For related articles see:
John Robbins' Bugslayer archive
NET CLR Profiling Services: Track Your Managed Components to Boost Application Performance
Mike Pellegrinois a principal software developer at Logikos Systems and Software Inc. He specializes in software development for Win32 platforms and can be reached at mpellegrino@logikos.com.