XSLT
Simplify Development and Maintenance of Microsoft .NET Projects with Code Generation Techniques
Peter Ashley
Code download available at:CodeGeneration.exe(224 KB)
This article assumes you're familiar with XML and XSLT
Level of Difficulty123
SUMMARY
Code generation techniques using technologies such as XSLT are playing an increasingly important part in software projects as they support the development of a rapidly maintainable code base. This article discusses some of the benefits and possible applications of code generation.
To demonstrate these techniques the author develops a Web Forms application that supports the maintenance of records in a SQL Server database, using the database's own metadata to drive the generation process. The SQL Server database schema is extracted using SQLXML 3.0 data access and processed through XSLT stylesheets that generate both a database access layer and a Web Forms user interface with query and update pages.
ContentsGetting to the Metadata
Prototyping the Architecture
Loading and Storing Records
Running Transformations
Stylesheets
Stored Procedure Stylesheet
Web Forms User Interface
Analysis
Implementation Recommendations
Conclusion
Did you ever have one of those days where you seem to be writing the same code over and over again? If the answer is yes, then congratulations! You've met a key requirement for employing one of the most powerful and underutilized technologies in software development—code generation. The key prerequisite for generating code is the ability to recognize the recurring software patterns that take place while you're programming. Developers usually attempt to abstract these generalized programming constructs into reusable functions, but frequently this approach fails because the code patterns are not regular enough for a general function. Also, devising the right design for a functional style generalization is often more difficult or less type-safe than just generating code, once you're comfortable with the technique.
Code generation is increasingly used for all aspects of programming. Developers employ code generation indirectly almost every day, through compilers, wizards, XSLT, C++ templates, application servers, and so on. Enterprise product developers use code generation techniques to produce mountains of code. But how can developers comfortably harness code generation for their own Microsoft® .NET Framework projects? Even those with slight familiarity with these techniques can reduce tedious coding and attain a much more flexible code base. See the sidebar "Benefits and Costs of Code Generation" for more on this topic.
Fundamentally, the code generation process involves three ingredients. First, you need a concrete model or schema that will be used as input to the process. For example, SQL Server schemas, exports of UML models, Web Services Description Language (WSDL) documents, XML Metadata Interchange (XMI) documents, and IDL interfaces all define metadata that can drive a code generation process. Second, you need a .NET Framework code example or prototype that shows what the output code will look like; you will convert this into a generic template. Third, you need a processing facility that can convert modeled data into your desired output code.
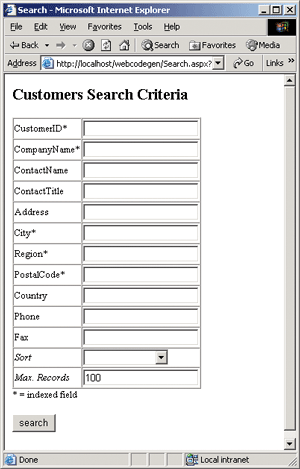
Figure 1** Search Criteria **
XSLT is one example of a processing facility that can generate output dynamically based on an abstract pattern. This process is much easier to understand using a concrete example, so I will walk through a sample application that searches database records (partially shown in Figure 1 and Figure 2) to illustrate these principles.
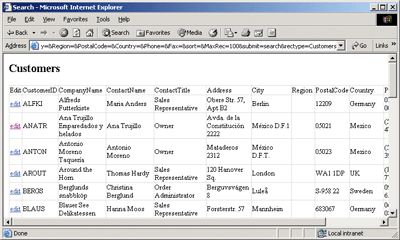
Figure 2** Customer Search Results **
Getting to the Metadata
In starting this project, my interest was in developing a technique to rapidly construct data access layers that connect directly to an existing SQL Server database. The DataSet-based tools provided in the .NET Framework are great in many situations, but sometimes you want the architectural control provided by direct database access. The SQL Server visual design tools can be used to design the schema on a new project quickly, and an existing project will already have a database, thus using SQL Server schemas seemed like a very good starting point.
I also wanted to use XSLT for my transformation engine because of its wide availability and familiarity to many developers. This project would also provide a challenging use of XSLT to thoroughly burn in my understanding of its syntax. XSLT requires an XML input source, so first I needed to extract my SQL Server schema into an XML format. This operation needs to be automatic, so that I can update the whole system for additions or changes in the database.
To extract the XML model for my code generation process, I wrote a stored procedure that accesses SQL Server system tables. The procedure outputs metadata on tables, views, and procedures, and their associated columns and parameters. The SQL XML capabilities in SQL Server (available as a download for SQL Server 7.0 and built into SQL Server 2000), with the appropriate query as shown in Figure 3, allowed the direct generation of this document in XML format.
Figure 3 Stored Procedure
CREATE PROCEDURE up_DatabaseXML /* ***Stored Procedure: up_DatabaseXML **** * Purpose: Stored Procedure that builds an XML document describing the user * created tables, views and stored procedures in the database. A view is * output as a table, but with a false IsUpdateable attribute. This * procedure is highly dependent upon the internal structure of SQL Server * system tables and metadata, reverse engineered from stored procedures in * the master database. */ AS SET NOCOUNT ON /* First select fetches table document elements and defines document format * through SQLXML explicit format column names. */ SELECT distinct 2 as tag, NULL as parent, syso.name as [Table!2!Name], [Table!2!IsUpdateable] = CASE syso.xtype WHEN 'u' THEN 1 WHEN 'v' THEN 0 END, NULL as [Column!3!Name], NULL as [Column!3!DataType], NULL as [Column!3!Length], NULL as [Column!3!IsNullable], NULL as [Column!3!ID], NULL as [Column!3!Description], NULL as [Column!3!IsIndexed], NULL as [Column!3!IsPrimaryKey], NULL as [Column!3!IsIdentity], NULL as [Procedure!4!Name], NULL as [Parameter!5!Name], NULL as [Parameter!5!DataType], NULL as [Parameter!5!Length], NULL as [Parameter!5!IsNullable], NULL as [Parameter!5!ID], NULL as [Parameter!5!IsOutParam], NULL as [Parameter!5!Description] FROM sysobjects syso WHERE syso.name != 'dtproperties' AND syso.name != 'meta' AND syso.name != 'sysconstraints' AND syso.name != 'syssegments' AND (syso.xtype = 'u' or syso.xtype = 'v') /* select procedure elements */ UNION ALL SELECT distinct 4 as tag, NULL as parent, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, syso.name, NULL, NULL, NULL, NULL, NULL, NULL, NULL FROM sysobjects syso WHERE (syso.xtype = 'p') AND (syso.category = 0) /* select table column elements */ UNION ALL SELECT DISTINCT 3 as tag, 2 as parent, syso.name, NULL, syscol.name, syst.name, syscol.length, syscol.isnullable, syscol.colid, isnull(sysp.value, ''), isnull((select top 1 1 from sysindexkeys sys WHERE syscol.id = id and syscol.colid = colid AND sysk.keyno = 1), 0), isnull((select top 1 1 from sysindexkeys sysk, sysindexes sysi Where syscol.id = sysk.id and syscol.colid = sysk.colid AND sysk.id = sysi.id and sysk.indid = sysi.indid and (sysi.status & 2048)<>0), 0), (syscol.status & 128)/128, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL FROM sysobjects syso LEFT JOIN syscolumns syscol ON syso.id = syscol.id LEFT JOIN sysindexkeys sysk ON syscol.id = sysk.id and syscol.colid = sysk.colid LEFT JOIN systypes syst on syscol.xtype = syst.xtype LEFT JOIN sysproperties sysp ON syscol.id = sysp.id AND syscol.colid = sysp.smallid WHERE syso.name != 'dtproperties' AND syso.name != 'meta' AND syso.name != 'sysconstraints' AND syso.name != 'syssegments' AND (syso.xtype = 'u' or syso.xtype = 'v') AND syst.name != 'sysname' /* select procedure parameter elements */ UNION ALL SELECT 5 as tag, 4 as parent, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, syso.name, syscol.name, syst.name, syscol.length, syscol.isnullable, syscol.colid, syscol.IsOutParam, isnull(sysp.value, '') FROM sysobjects syso LEFT JOIN syscolumns syscol ON syso.id = syscol.id LEFT JOIN systypes syst on syscol.xtype = syst.xtype LEFT JOIN sysproperties sysp ON syscol.id = sysp.id AND syscol.colid = sysp.smallid WHERE (syso.xtype = 'p') AND (syso.category = 0) AND syst.name != 'sysname' /* organize elements properly in parent, child order */ ORDER BY [Table!2!Name], [Column!3!ID], [Procedure!4!Name], [Parameter!5!ID] for xml explicit
Two aspects of the procedure in Figure 3 are especially tricky: the OPTION EXPLICIT column formatting to get the correct XML document structure, and the WHERE clauses that use some lower-level SQL Server system table information. The key elements for the OPTION EXPLICIT formatting are the leading tag and parent query fields, the field names, such as [Table!2!Name], specified in the first query, and the ORDER BY clause. OPTION EXPLICIT formatting is explained in detail in SQL Server Books Online, under the heading "Using EXPLICIT Mode." To understand the system table information, I examined the code of built-in SQL Server stored procedures in the master database, such as sp_MShelpindex and sp_columns.
Fortunately, the XML document produced by this procedure (see Figure 4) is much easier to understand. It was derived from the Northwind database that ships with SQL Server. XML elements are shown for a stored procedure and a table. The procedure elements contain parameter elements and the table elements contain column elements. Views are exported as non-updateable tables. The XML attribute information for the columns and parameters provided the information I needed to fill in the code patterns. The column data types, name, and length are important for implementing the data access code and the UI. Identity columns can't be updated. The search user interface shown in Figure 1 indicates the indexed columns CustomerID, CompanyName, and so on.
Figure 4 XML
<?xml version="1.0" encoding="utf-8" ?> <Database> <Procedure Name="Sales by Year"> <Parameter Name="@Beginning_Date" DataType="datetime" Length="8" IsNullable="1" ID="1" IsOutParam="0" Description=""/> <Parameter Name="@Ending_Date" DataType="datetime" Length="8" IsNullable="1" ID="2" IsOutParam="0" Description=""/> </Procedure> ••• <Table Name="Shippers" IsUpdateable="1"> <Column Name="ShipperID" DataType="int" Length="4" IsNullable="0" ID="1" Description="" IsIndexed="1" IsPrimaryKey="1" IsIdentity="1"/> <Column Name="CompanyName" DataType="nvarchar" Length="80" IsNullable="0" ID="2" Description="" IsIndexed="0" IsPrimaryKey="0" IsIdentity="0"/> <Column Name="Phone" DataType="nvarchar" Length="48" IsNullable="1" ID="3" Description="" IsIndexed="0" IsPrimaryKey="0" IsIdentity="0"/> </Table> ••• </Database>
To extract the XML document from SQL Server, I first installed the stored procedure in the Northwind database using Query Analyzer, then set up HTTP access to the database using the Microsoft Management Console (MMC) snap-in wizard. To start the wizard, select the "Configure SQL XML Support in IIS" item in the SQL Server program group. Note though that the SQLXML ISAPI handler is not installed by default during the installation of SQL Server 2000. Rather, it's part of the client tools. To create a virtual directory, select the default Web site and choose Actions | New | Virtual directory from the context menu. Work through the tabs and select Allow URL Queries on the Settings tab. This allows you to run the stored procedure from Microsoft Internet Explorer using a URI such as https://localhost/northwind?sql=EXEC%20up_DatabaseXML&root=Database. In this case, the virtual directory, called northwind, was created on my machine and the root XML document element containing the <Procedure> and <Table> elements was called <Database>. I then used the File | Save As menu item in Internet Explorer to save the XML document to the hard drive for further processing.
Prototyping the Architecture
Next, I developed a prototype of the data access wrapper procedures using one table with a couple of columns. For my data access layer, a database details class holds the contents of a single row of each table and view in the database. I wanted this class to have type-safe member accessors, such as public String GetCustomerDesc for column values. The members are stored internally in the details class as objects rather than C# value types because value types cannot be null, whereas the database allows null values for types such as int.
Each member's dirty property was tracked so that the update procedure can avoid unnecessarily updating indexed columns, thus reducing lock contention and increasing the probability of an in-place update. To assist in dirtiness tracking, I declared two variables for each member, one of which held the old value. The load methods must initialize the original member values and the set methods must protect the member values from being erroneously overwritten with objects:
private Object _CustomerTypeID; // member value private Object _CustomerTypeIDOrig; // original member value
In addition to the benefit of dirtiness tracking, storing old and new values enables you to write storage-time validation code, though not in the member set method itself. This code can reject illegal value transitions, or allow the update code to be written in a SQLXML diffgram.
By creating overloaded member set methods that take object and string parameters my loading and UI code was easier to write. This enabled the database code and UI layers to specify values in a convenient format, where the set method does the work to properly handle the values. For example, it's easiest for the database code to send in an object, which will have a runtime type in the System.Data.SqlTypes namespace.
Under these conditions, the object's set methods must handle a number of issues, such as:
- Allowing the member to be set to null.
- Handling native SQL-specific datatypes like System.DBNull and System.Data.SqlTypes.SqlString.
- Rejecting input objects that are equal in value to the existing member to avoid unnecessary updates.
- Accepting Strings and native objects that are statically dispatched by the compiler to the object interface. Even if a set method takes a String parameter and the target object is a String, the String will be dispatched to the Object set method if the variable passing the String is typed as Object.
- Telling you the type of the source class that can't be legally cast to your specific value type.
The code in Figure 5 includes a typical member set method that handles these issues.
Figure 5 Member Set Method
/// <summary>Object modifier for EmployeeID</summary> /// <param name="Int32Value">member value to set public void SetEmployeeID(Object value) { // Object may be provided from SQL row/cell in dataset or other sources // Handle known types based on runtime type test of incoming object if (value == null || value is System.DBNull) { _EmployeeID = null; } // handle db type else if (value is SqlInt32) { SetEmployeeID((Int32)((SqlInt32)value).Value); } else if (value is String) { SetEmployeeID((String) value); } // cast using native type else { try { SetEmployeeID((Int32) value); } catch (Exception e) { throw new ApplicationException("unable to cast from "+value.GetType().ToString(), e); } } }
Loading and Storing Records
Once the basic member accessor methods were developed, the wrapper classes needed an easy-to-use Load and Store API—something that enabled you to modify and store a record:
EmployeesDetails Employee = EmployeesDetails.Load("EmployeeID=1", null, null); Employee.SetBirthDate("1965/09/23"); Employee.Store(null, null);
The "EmployeeID=1" parameter to the WHERE clause used by the Load method is not type-safe, but will work with tables with integer or unique identifier row IDs, as well as tables with multicolumn primary keys. If you're designing your own tables, you should add a LoadByID method based on your chosen row ID scheme. The flexibility that the current load method provides will work with all kinds of databases.
The Load and Store database interaction code I developed uses dynamic SQL based on samples in the .NET Framework documentation (see Figure 6). Optional connection and transaction parameters in the API calls facilitate explicit transaction management. Some repetitive code was extracted into procedures in an associated Util class.
Figure 6 Load and Store Database Interaction
/// <summary> /// Details class for records in table CustomerDemographics. /// </summary> public class CustomerDemographicsDetailsBase { /// <summary> /// Load record specified by optional where clause. /// null where clause causes creation of a new record. /// throws ArgumentOutOfRangeException if where clause is invalid /// </summary> public static CustomerDemographicsDetails Load(String where, SqlConnection myConnection, SqlTransaction myTrans) { CustomerDemographicsDetails result = new CustomerDemographicsDetails(); if (where == null) { result.PostLoad(myConnection, myTrans); result.ResetDirtyStatus(); // reset dirty flags affected by sets return result; // no where = new record } DataSet dSet = Utils.GetDataSet("CustomerDemographics", "2", where, null, myConnection, myTrans); // check results if (dSet == null || dSet.Tables[0].Rows.Count == 0) { throw new ArgumentOutOfRangeException( "where clause, "+where+", resulted in retrieval of no records"); } if (dSet.Tables[0].Rows.Count != 1) { throw new ArgumentOutOfRangeException( "where clause, "+where+", resulted in retrieval of multiple records"); } // select first and only row DataRow dRow = dSet.Tables[0].Rows[0]; result.SetCustomerTypeID(dRow["CustomerTypeID"]); result.SetCustomerDesc(dRow["CustomerDesc"]); result._loadNew = false; result._loadWhere = where; result.PostLoad(myConnection, myTrans); result.ResetDirtyStatus(); // reset dirty flags affected by sets return result; } /// <summary> Store record which was previously loaded. </summary> public void Store(SqlConnection myConnection, SqlTransaction myTrans) { // use load history to whether to create new record or update existing. PreStore(myConnection, myTrans); if (_loadNew) { Create(myConnection, myTrans); } else { Update(myConnection, myTrans); } } /// <summary>Delete record which was previously loaded. </summary> public void Delete(SqlConnection myConnection, SqlTransaction myTrans) { // if this is a new record, then delete is a no-op if (!_loadNew) { Utils.Delete("CustomerDemographics", _loadWhere, myConnection, myTrans); } } /// <summary>Get dataset for table</summary> public static DataSet GetDataSet(String topLimit, String where, String orderBy, SqlConnection myConnection, SqlTransaction myTrans) { return Utils.GetDataSet("CustomerDemographics", topLimit, where, orderBy, myConnection, myTrans); } /// <summary>create new record</summary> private void Create(SqlConnection myConnection, SqlTransaction myTrans) { bool manageConnection = Utils.GetConnectionIfNeeded(ref myConnection, myTrans); bool needComma = false; StringBuilder cmdStr = new StringBuilder("INSERT [CustomerDemographics] ("); if (IsCustomerTypeIDDirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append("CustomerTypeID"); } if (IsCustomerDescDirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append("CustomerDesc"); } needComma = false; cmdStr.Append(") VALUES ("); if (IsCustomerTypeIDDirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append(Utils.PrepForSQL(GetCustomerTypeIDObject())); } if (IsCustomerDescDirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append(Utils.PrepForSQL(GetCustomerDescObject())); } cmdStr.Append(")"); String cmd = cmdStr.ToString(); SqlCommand myCommand = new SqlCommand(cmd, myConnection, myTrans); try { myCommand.ExecuteNonQuery(); } finally { Utils.CloseConnectionIfNeeded(ref myConnection, manageConnection); } ResetDirtyStatus(); } •••
A number of features in the Load and Store code warrant further discussion. Let's start with one of the most important topics: error handling. I didn't try to catch exceptions in the data access layer. Many coding examples show exception handling in low-level code where an adequate decision as to what to do about the error can't be made. Sometimes these well-intentioned catch methods throw away information by returning status Booleans or even by swallowing the exception entirely. Pushing exception handling up the stack makes code more reusable. The business logic using the database wrapper code can handle the error in different ways depending upon the situation. The database access code is wrapped with try...finally blocks to close database connections in case a runtime database error occurs, preventing a resource leak in the form of database connections. Do not rely on the common language runtime (CLR) garbage collector for all your database resource management.
The Load method is the only public way to get your hands on a database wrapper class. Load returns a different class than the CustomerDemographicsDetailsBase class declaring the Load method, namely, CustomerDemographicsDetails. The class CustomerDemographicsDetails will be hand-coded to extend the CustomerDemographicsDetailsBase. This hand-coded class will be the place to implement storage field validation logic, additional business logic methods, and methods that use stored procedures. Some template method hooks, such as PreStore, are built into the CustomerDemographicsDetailsBase methods as a convenient place to put business validation logic without the need to override the entire Load or Store method. Here's an example CustomerDemographicsDetails class:
/// <summary>Class for adding hand code</summary> public class CustomerDemographicsDetails : CustomerDemographicsDetailsBase { /// <summary>hook to simplify override access in hand-coded class /// </summary> override protected void PreStore(SqlConnection myConnection, SqlTransaction myTrans) { if(_CustomerTypeID == null) { throw new ApplicationException("null CustomerTypeID not allowed"); } } }
Further improvements could be made in this basic data access pattern. I didn't bother to parameterize the SQL statements, which should improve performance considerably by increasing the likelihood of the execution plan being cached by SQL Server. No update contention detection occurs in my basic system. This would be easiest to add by creating a last-updated timestamp field on your tables, with comparison logic to reject the update if another user has updated the table in the database since the time that the record was retrieved for display.
Running Transformations
With a working code prototype, the code can be reworked into an XSLT stylesheet that generates this same code. First I need to be able to run the XSLT transformation. By downloading msxsl.exe from the command-line transformation utility (XSLT Utilities and Samples You Can Download), I am able to create a batch file with commands to run the transformations, rather than creating code to do it. The batch file allows integration of the transformation process into my build. The following is an example batch file command line using msxsl.exe:
msxsl Database.xml DBWrapperTemplate.xslt -o DBWrapper.cs
Database.xml is the input file, DBWrapperTemplate.xslt is the stylesheet, and DBWrapper.cs is the output code.
Stylesheets
If you're not familiar with stylesheets, you should review one of the background information articles, such as "XSL Transformations: XSLT Alleviates XML Schema Incompatibility Headaches," in the August 2000 issue of MSDNMagazine, which has an excellent overview of the main concepts. I won't be repeating all the usual details here, but I will discuss some of the troubles that I had creating my code generation templates. Figure 7 contains the complete DBWrapperTemplate stylesheet used to generate the database wrappers for tables and views.
Figure 7 DBWrapper
<xsl:stylesheet version="1.0" xmlns:xsl="https://www.w3.org/1999/XSL/Transform"> <xsl:import href = "CommonTemplates.xslt" /> <xsl:output method="html"/> <xsl:template match="/"> using System; using System.Data; using System.Text; using System.Data.SqlClient; using System.Xml; using System.Data.SqlTypes; namespace DBWrapper { <xsl:for-each select="//Table"> <!-- whitespace not tolerated in function and class names --> <xsl:variable name="rawTableName"><xsl:value-of select="@Name"/></xsl:variable> <xsl:variable name="tableName"><xsl:value-of select="translate($rawTableName,' ','')"/></xsl:variable> /// <summary>Details class for records in<xsl:value-of /// select="@Name"/>.</summary> public class <xsl:value-of select="$tableName"/>DetailsBase { /// <summary>Load record specified by optional where clause. /// null where clause causes creation of a new record. /// throws ArgumentOutOfRangeException if where clause invalid. /// </summary> public static <xsl:value-of select="$tableName"/>Details Load(String where, SqlConnection myConnection, SqlTransaction myTrans) { <xsl:value-of select="$tableName"/>Details result = new <xsl:value-of select="$tableName"/>Details(); if (where == null) { result.PostLoad(myConnection, myTrans); result.ResetDirtyStatus(); // reset dirty flags affected by sets return result; // no where = new record } DataSet dSet = Utils.GetDataSet("<xsl:value-of select="@Name"/>", "2", where, null, myConnection, myTrans); // check results if (dSet == null || dSet.Tables[0].Rows.Count == 0) { throw new ArgumentOutOfRangeException( "where clause, "+where+", resulted in retrieval of no records"); } if (dSet.Tables[0].Rows.Count != 1) { throw new ArgumentOutOfRangeException( "where clause, "+where+", resulted in retrieval of multiple records"); } // select first and only row DataRow dRow = dSet.Tables[0].Rows[0]; <xsl:for-each select="Column"> <xsl:variable name="datatype"> <xsl:call-template name="convert_datatype"/></xsl:variable> result.Set<xsl:value-of select="@Name"/>(dRow[ "<xsl:value-of select="@Name"/>"]);</xsl:for-each> result._loadNew = false; result._loadWhere = where; result.PostLoad(myConnection, myTrans); result.ResetDirtyStatus(); // reset dirty flags affected by sets return result; } <!-- some APIs not applicable for views --> <xsl:if test="@IsUpdateable='1'"> /// <summary> /// Store record which was previously loaded. /// </summary> public void Store(SqlConnection myConnection, SqlTransaction myTrans) { // use load history to whether to create new record or update // existing. PreStore(myConnection, myTrans); if (_loadNew) { Create(myConnection, myTrans); } else { Update(myConnection, myTrans); } } /// <summary>Delete record which was previously loaded.</summary> public void Delete(SqlConnection myConnection, SqlTransaction myTrans) { // if this is a new record, then delete is a no-op if (!_loadNew) { Utils.Delete("<xsl:value-of select="@Name"/>", _loadWhere, myConnection, myTrans); } } </xsl:if> /// <summary>Get dataset for table</summary> public static DataSet GetDataSet(String topLimit, String where, String orderBy, SqlConnection myConnection, SqlTransaction myTrans) { return Utils.GetDataSet("<xsl:value-of select="@Name"/>", topLimit, where, orderBy, myConnection, myTrans); } <xsl:if test="@IsUpdateable='1'"> /// <summary>Create new record</summary> private void Create(SqlConnection myConnection, SqlTransaction myTrans) { bool manageConnection = Utils.GetConnectionIfNeeded(ref myConnection, myTrans); bool needComma = false; StringBuilder cmdStr = new StringBuilder("INSERT [<xsl:value-of select="@Name"/>] ("); <!-- identity column value assigned by SQL Server --> <xsl:for-each select="Column[@IsIdentity='0']"> if (Is<xsl:value-of select="@Name"/>Dirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append("<xsl:value-of select="@Name"/>"); } </xsl:for-each> needComma = false; cmdStr.Append(") VALUES ("); <xsl:for-each select="Column[@IsIdentity='0']"> if (Is<xsl:value-of select="@Name"/>Dirty()) { needComma = Utils.InsertCommaIfNeeded(needComma, cmdStr); cmdStr.Append(Utils.PrepForSQL(Get<xsl:value-of select="@Name"/>Object())); }</xsl:for-each> cmdStr.Append(")"); String cmd = cmdStr.ToString(); SqlCommand myCommand = new SqlCommand(cmd, myConnection, myTrans); try { myCommand.ExecuteNonQuery(); } finally { Utils.CloseConnectionIfNeeded(ref myConnection, manageConnection); } ResetDirtyStatus(); } ••• </xsl:for-each> } </xsl:template> </xsl:stylesheet>
I had a couple of common templates in my stylesheets, primarily for converting from SQL datatypes such as nvarchar in the database.xml document to C# ValueTypes such as String. These templates are removed to a separate stylesheet, CommonTemplates.xslt, and are included with one of the first elements in the DBWrappersTemplate.xslt stylesheet, <xsl:import href = "CommonTemplates.xslt" />.
Another important element in Figure 7 is the <xsl:output method="html"/> output method. I started with text as my output method, which was disappointing because non-XSL elements in comments, such as <summary>my method</summary>, were stripped from the output. By explicitly inserting the less-than character with the xsl:text element (for example, <xsl:text><</xsl:text>), I could get the desired output with the text method, but this seemed like too much work and not very elegant. With the HTML output method, non-XSL elements are included in the output. However, other side effects occur, like single quotes being converted to double quotes and the <param> comment element being output as an empty element because <param> is defined as empty in the HTML spec. Given the choice, I would stick with the text output method for non-HTML code.
The stylesheet really gets rolling, though, with the first xsl:for-each element, as shown here:
<xsl:for-each select="//Table"> <!-- whitespace not tolerated in function and class names --> <xsl:variable name="rawTableName"><xsl:value-of select="@Name"/></xsl:variable> <xsl:variable name="tableName"><xsl:value-of select="translate($rawTableName,' ','')"/></xsl:variable>
This XSL code repeats all the code within the for-each loop for every table (and view) in the database.xml file. Within the for-each block, the XSL context is set to the table, so attribute accessors such as @Name will provide the name of the current table in each transform iteration.Benefits and Costs of Code Generation
Code generation can reduce all the time it takes to type repetitive code, especially once you're comfortable with the technique. The time you save can be used for other important things like validating your architecture, refining requirements, performance testing, and so on.
The most important benefits occur in the maintenance cycle. If you need to change your architecture, upgrade your technology, or add a technology, this becomes much easier in a template-generated system. Change your templates and you're mostly finished. Since changes aren't being manually applied, testing is reduced because you don't need to look for human error throughout the code base. On one of my projects, I decided to completely change the transaction management, object API, and component automation strategies because the performance overhead of the existing architecture was too high. This only took a couple of weeks and resulted in almost no new bugs because of the high level of generation in the system.
Another big benefit of code generation, which was a great help in the previously mentioned code overhaul, is the ease of creating type-safe code. After changing my system APIs, a lot of code that was written by hand broke. The compiler helped find all the places that needed to be fixed, as opposed to finding problems at run time during an extended testing phase.
Constructing type-safe code by hand can be a lot more time consuming than designing general techniques or design patterns that are not type safe. The temptation for developers who are unassisted by code generation to use object-based APIs, untyped property bags, and so on, can be high. Imagine two different possible implementations for a factory class. The generated API might be defined as public static CustomerOrder CreateCustomerOrder, and an ungenerated API might be defined as public static Object CreateObject(String ObjectType). Make a typo using the generated API and the compiler complains, unlike when you make a typo in the string or you make a casting error with the hand-coded API.
Code generation also enables you to make performance improvements. Type-safe generated code runs much faster for many patterns than hand-coded equivalents that might need to use runtime type identification, type conversions such as int to String, or reflection techniques. In order to gain performance improvements you typically will face the task of writing more complex or low-level code, such as when you use parameterized SQL queries as opposed to dynamic SQL queries with inline parameters. Generation of the majority of the low-level code can take away most of the sting in this process.
A code-generated system is more forgiving than a hand-coded system. A designer can become paralyzed making design decisions for a hand-coded system because the architectural decisions, once made, are hard to change. A developer will typically require much more experience to know all the proper design patterns that their system requires up front, compared with the experience required to just dive in with a generated layer. Patterns can be refactored into the templates once the need for them becomes apparent in the developed code base.
Code generation can speed up the development of hand-coded parts of a system since APIs can be made to order for IntelliSense in Visual Studio. IntelliSense will bring CreateCustomerOrder right to your fingertips, whereas with CreateObject, you must remember and correctly type the object type string parameter in order to avoid a runtime error.
The learning curve you will most likely encounter when you first begin to use code generation techniques will be steep, especially if you're a new developer joining an existing project. Plan for training and thorough documentation of the models that drive a code generation process.
Adding handwritten code into a generated code base without modifying generated code can be tricky. One important technique is to generate lower levels of a system, such as the database interaction layer, and then hand-code on top of the generated parts by using class inheritance. Template methods can also be added to lower levels of generated code to simplify insertion of hand-coded business logic.
Sometimes the power of code generation activates hammer-and-nail syndrome within an organization. In other words, if your main tool is a hammer, everything starts to look like a nail. In order to avoid the negative effects of too much one-size fits all code, periodically examine your generated code base to look for opportunities where design patterns or common procedures will simplify things. Carefully consider whether generation is worth the initial cost for each tier and functional aspect of your system.
To manage performance issues in bottleneck areas, you may have to abandon perfectly functional but slow code relying on a generated layer, and craft a customized routine. For example, set oriented operations may be more efficiently handled by a custom-coded stored procedure than by iterative code using a record-oriented database wrapper layer.
The amount of code generated for a project can grow quite large, resulting in an ever increasing memory footprint for an application. Usually the amount of code isn't an issue in itself with application-level code running on modern hardware, but be wary if you're doing development at the system level or for a hardware and memory-deficient platform.
I ran into a problem when first switching to the Northwind database because spaces are embedded in the name of some of Northwind's views. The two xsl:variable elements first pull the table name into a variable, then use the XSL translate function to strip out spaces. Translate replaces spaces (encoded as  ) with nothing, encoded as empty quotes. The tableName variable has all spaces removed, which is better suited for use in class and method names, where spaces aren't allowed.
In Figure 7, you will find that there are several instances of the following XSL element:
<xsl:value-of select="$tableName"/>
This element gets replaced with the name of the current table during the transform. To convert my sample code to a stylesheet, I replaced all instances of the table name with that xsl:value-of element.
The next new structure in the template is in the Load method, where I need to start accessing individual column values. The XSLT in the following sample causes the transform to iterate over all the columns, and output a line of code to set the member data for the column from the corresponding DataRow object:
<xsl:for-each select="Column"> result.Set<xsl:value-of select="@Name"/>(dRow[ "<xsl:value-of select="@Name"/>"]);</xsl:for-each>
This XSLT will produce a line of code for each column, such as:
result.SetOrderID(dRow["OrderID"]); result.SetCustomerID(dRow["CustomerID"]); result.SetEmployeeID(dRow["EmployeeID"]); result.SetOrderDate(dRow["OrderDate"]);
Occasionally the for-each column elements are augmented with an XPath query, as shown here:
<xsl:for-each select="Column[@IsIdentity='0']">
This XPath query causes only those columns that have an IsIdentity attribute of 0 to be included in the for-each iteration. Identity columns cannot be updated, so this technique is used to screen these columns out of the update statements.
Another important XSLT technique is the use of templates to establish variables. In the following code snippet, datatype and valuetype variables are being created:
<xsl:for-each select="Column"> <xsl:variable name="datatype"> <xsl:call-template name="convert_datatype"/></xsl:variable> <xsl:variable name="valuetype"> <xsl:call-template name="convert_valuetype"/></xsl:variable>
The convert_datatype and convert_valuetype templates in CommonTemplates.xslt supply the variables values. These templates use an xsl:choose block to convert the SQL Server datatypes such as nvarchar into C# ValueTypes such as String and System.Data.SqlTypes such as SqlString.
Figure 8 shows the xsl:choose block for the convert_valuetype template. I put "###DEBUG###" in the xsl:otherwise block so that the compiler will let me know about any problems finding a valid type conversion.
Figure 8 Convert Types
<!-- return System.Data.SqlTypes valuetype corresponding to SQL Server datatype --> <xsl:template name="convert_valuetype"> <xsl:choose > <xsl:when test="@DataType='int'">SqlInt32</xsl:when> <xsl:when test="@DataType='bit'">SqlBoolean</xsl:when> <xsl:when test="@DataType='smallint'">SqlInt16</xsl:when> <xsl:when test="@DataType='datetime'">SqlDateTime</xsl:when> <xsl:when test="@DataType='ntext'">SqlString</xsl:when> <xsl:when test="@DataType='nvarchar'">SqlString</xsl:when> <xsl:when test="@DataType='image'">SqlBinary</xsl:when> <xsl:when test="@DataType='bigint'">SqlInt64</xsl:when> <xsl:when test="@DataType='binary'">SqlBinary</xsl:when> <xsl:when test="@DataType='char'">SqlString</xsl:when> <xsl:when test="@DataType='decimal'">SqlDecimal</xsl:when> <xsl:when test="@DataType='float'">SqlDouble</xsl:when> <xsl:when test="@DataType='money'">SqlMoney</xsl:when> <xsl:when test="@DataType='nchar'">SqlString</xsl:when> <xsl:when test="@DataType='real'">SqlSingle</xsl:when> <xsl:when test="@DataType='smalldatetime'">SqlDateTime</xsl:when> <xsl:when test="@DataType='smallmoney'">SqlMoney</xsl:when> <xsl:when test="@DataType='text'">SqlString</xsl:when> <xsl:when test="@DataType='timestamp'">SqlBinary</xsl:when> <xsl:when test="@DataType='tinyint'">SqlByte</xsl:when> <xsl:when test="@DataType='uniqueidentifier'">SqlGuid</xsl:when> <xsl:when test="@DataType='varbinary'">SqlBinary</xsl:when> <xsl:when test="@DataType='varchar'">SqlString</xsl:when> <xsl:when test="@DataType='variant'">Object</xsl:when> <xsl:otherwise>###DEBUG### unhandled convert_valuetype = <xsl:value-of select="@DataType" /> </xsl:otherwise> </xsl:choose> </xsl:template>
I also needed to use some xsl:if blocks in the code. For example, I suppressed the output of storage code like Store for views with the element <xsl:if test="@IsUpdateable='1'">. Also, some of the SQL datatypes such as image needed special handling, and xsl:if blocks were used to insert the right code in these cases.
Stored Procedure Stylesheet
Another stylesheet provides an important aspect of the database wrapper layer, namely, the stored procedure wrappers. These wrappers are especially handy when used in conjunction with IntelliSense® in Visual Studio®. Let's consider the following code using a stored procedure wrapper:
DataGrid1.DataSource = SPWrapper.EmployeeSalesbyCountry(new DateTime(1980, 1, 1), DateTime.Today, null, null); DataGrid1.DataBind();
When I typed "SPWrapper", IntelliSense instantly produced a list of all the stored procedures in the database along with their result types and descriptive parameters. This is, in my opinion, far simpler than using the Data Access Application Block provided by Microsoft. Calling the same stored procedure requires the developer to remember the procedure name and return type, as well as the parameter names and types. As a developer, I already have enough to remember without committing all this to memory. Here is an example of how the same code to use a stored procedure would typically be written without code generation:
DataGrid1.DataSource = SqlHelper.ExecuteDataset( connectionString, CommandType.StoredProcedure, "Employee Sales by Country", new SqlParameter("@Beginning_Date", new DateTime(1980, 1, 1)), new SqlParameter("@Ending_Date", DateTime.Today,)); DataGrid1.DataBind();
A current limitation of the database XML metadata document is that when a stored procedure doesn't return an explicit parameter, the metadata document doesn't tell you whether the stored procedure returns a RowSet or nothing. Determining the correct SQL Server metadata to answer this question would take more research into SQL Server internals, so for now I just assumed that any stored procedure that returns no parameter returns a DataSet. This assumption works fine with the Northwind database, but may not work in other scenarios.
Web Forms User Interface
To test the data wrapper layer, I generated a plain Web Forms UI, as shown in Figure 9 and Figure 10. A directory page lists all the record types, a search/browse page displays records in a DataGrid, and an edit page displays a full page form for modifying column values.
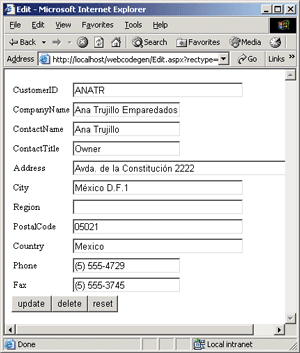
Figure 9** Web Forms Edit Page **
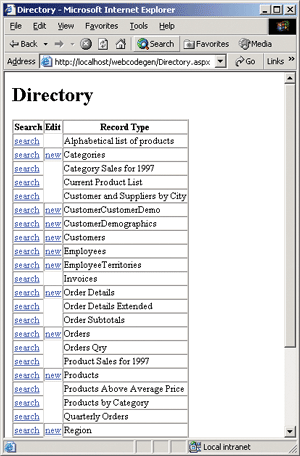
Figure 10** Web Forms Directory Page **
For these mostly HTML pages, using the HTML output mode from XSL makes sense. XSLT complains about the syntax of the <% %> script escaping used by ASP, which is neither legal XML nor HTML. To output script, I need to enclose script directives in XSL text elements, with the disable-output-escaping attribute set to yes so that greater-than and less-than characters aren't changed into the XML entities < or >. The script directives must further be enclosed in a CDATA section to allow the parser to ignore the angle brackets:
<xsl:text disable-output- escaping="yes"><![CDATA[ <% DrawPage(); %>]]> </xsl:text>
I began by generating these pages as "single file" Web Forms, but switched to the preferred codebehind model used in Visual Studio .NET because compile-time errors weren't detected until I browsed the page, which is a documented limitation of the single file format. Within the stylesheets that produce the C# code, several changes to the prototype code were needed to produce legal XML syntax. In some of the if statements, I was using && in logical comparisons, which was being parsed as invalid XML, so I flipped them into || operations using DeMorgan's theorem (for example, !(A & B) = !A | !B). In other cases, I used externally defined constants in place of angle brackets in strings to avoid the interpretation of the angle brackets as XML. Within an XML element, the HTML output method caused the conversion of single quotes to double quotes and other things I didn't want. For example, in this statement, Utils.lt is defined as "<" in another, non-XSL file.
Response.Write(Utils.lt+"OPTION selected=\"\" /"+Utils.gt);
Analysis
The stylesheet's constraint to valid XML is a bit of a hassle for general code generation. Moving selected code to functions in non-generated classes can reduce these problems. Developers regularly run into character escaping problems when using template languages, so the problem is not unique to XSLT. An advantage of XSLT is its built-in functions such as translate, position, and so on. The requirement that a stylesheet be legal XML also helps you find template programming errors more quickly, since the transformation will alert you to invalid nesting of elements.
If you're working on a large project, you may want to consider code generation technology offered by vendors. There are a variety of products now available from both high-end vendors, and more affordable vendors, providing powerful features that may be more suitable for your needs than straight XSLT.
Implementation Recommendations
Here are some guidelines for using code generation that will maximize the power of the technique.
Don't check in generated code The beauty of code generation is that you can modify your template and instantly update your code base. Modifying code by hand defeats this. Prohibiting check-ins to generated code prevents developers on the team from making this mistake. Use template methods or class inheritance to separate handwritten code from generated code.
Control your code generation technology Using third-party products can save you time, especially in modeling tools or translation engines. But be wary of losing control of your architecture. If a vendor provides your code templates, then you are at the whim of their architecture. What if after your product is implemented, for example, you discover the need for field-level dirtiness control for performance reasons, but your vendor doesn't support this?
Standardize and simplify Generated templates shouldn't try to support every possible construct. For example, when generating a database wrapper you might not want to support complicated scenarios such as stored procedures that return multiple parameters or tables with multiple identity columns. Code the anomalies by hand.
Know when to stop After developers experience the benefits of code generation, they often take it too far, trying to generate business logic that just varies too much to be worth generating.
Pay attention to your architecture Generated code is only as good as your templates. Make sure your architecture has the performance, scalability, and flexibility you need.
Support the hand-coder You should always try to generate APIs that are easy for the hand-coder to use. Nothing speeds up the development process like using a class library with an intuitive API, especially when it is combined with the IntelliSense feature that's found in Visual Studio.
Document and integrate A generated code base can be more challenging for new developers to get up to speed on, so document extensively. Integrate the transformation technology into your build process so generation occurs automatically.
Refactor Reviewing generated code, you will frequently find patterns that could be simplified with a convenience function or by implementing a design pattern. Refactoring will reduce the verbosity of your generated code base and simplify maintenance.
Unit tests Generate unit tests and test harnesses for your code as part of the development process.
Conclusion
Hopefully this article has given you an appreciation for some of the benefits of code generation, and stimulated some ideas on how code generation might benefit your current projects. XSLT can be used for this task in a general way, in addition to some of its more common uses such as generating HTML presentation for XML and translating XML documents between schemas. XSLT knowledge is useful in a variety of situations, whereas knowledge of other more proprietary or less widely used products might be less transportable to new organizations and environments.
For related articles see:
Bug Tracker: Build a Configurable Web-Based Bug Management Tool Using ADO.NET, XML, and XSLT
For background information see:
SQLXML 3.0: Build Data-Driven Web Services with Updated XML Support for SQL Server 2000
Peter Ashley has 15 years of development experience including projects at large computer manufacturers, ERP software vendors, and software startups. Peter is currently a development team lead at IM Logic in Waltham, MA. Please e-mail comments to Peter at MSDN@AshleyFamily.com.