Scale
Real-World Load Testing Tips to Avoid Bottlenecks When Your Web App Goes Live
Jeff Dunmall and Keith Clarke
This article assumes you're familiar with IIS and Web Development
Level of Difficulty123
SUMMARY
Load testing should be part and parcel of every Web development effort, and it should be performed early in the process. However, if you think you can load test using your development environment, you're going to have some surprises when you go live. In this article, the authors outline the process of planning your load testing effort, considering which machines to use, how many users to simulate, which tools are right for you, and how to interpret your results.
Contents
Start Early
Define Your Environment
Define Your Testing Strategy
But How Many Users?
Know Your Metrics
Interpret Your Metrics
Choosing the Right Load Testing Tool
Know Your History
Conclusion
L et us propose a scenario. You're wrapping up a six-month development effort on a complex Internet application or Web Service and you're getting ready to deploy it. The development team was meticulous in its design of a loosely coupled, n-tier Web application. All the necessary ingredients for a scalable, stable, high-performance application were carefully built into the system architecture from day one. The QA team has thoroughly tested your system, removed the most severe bugs, and considers the remaining bugs to be known. So your deployment should go pretty smoothly, right? Think again.
Did you implement load testing as part of your development effort? If not, you should accept the fact that somewhere in the complexity of your design you will have introduced concerns around performance, scalability, and stability. Bottlenecks are elements of your system that impede the normal flow of traffic. Although good design is crucial to building a successful Web application, experience has taught us that the majority of these kinds of bugs can only be found when your system is placed under load. These are issues you won't discover by testing the system as a single user during the development process. By implementing a load testing plan early enough, you can help ensure that any surprises at deployment time are truly minimal.
In this article, we will steer away from the conventional load testing strategy to describe an approach that is based on real-world experience. Having led numerous load testing teams, we've learned some lessons that you might find helpful.
We'll discuss the merits of starting your testing effort early and cover key considerations for setting up your testing environment. We'll help you to determine which metrics are appropriate for your implementation and describe some tools for interpreting them. In addition, we'll show you why the familiar question "can my site handle x users simultaneously?" is too vague to answer accurately. Finally, we'll discuss some important considerations for choosing the appropriate load testing tool for your particular needs and make recommendations on tracking your test results.
We'll use the term load testing to describe performance, scalability, and stability testing. The term scalability testing is too often used to describe all three, and your team is likely doing more than just that. Figure 1 describes these goals.
Figure 1 The Goals of Load Testing
| Testing Type | Goal |
|---|---|
| Performance | To reduce the time necessary to execute a request. May involve the optimization of methods, stored procedures, and transaction lengths. |
| Scalability | To exceed the number of concurrent users anticipated at peak load in production. The number of concurrent users supported should be proportional to the amount of hardware. |
| Stability | To reduce component memory leaks and system crashes. |
Start Early
You should begin planning your load testing effort during the design phase. From our own experience, we can suggest that you take a "no surprises" approach to your development effort. Always work with the assumption that you will find problems. The architecture for distributed Web applications and Web Services is increasingly complex, allowing potential problems to be inherent in the design of your application.
We recently conducted load testing well into the development phase on a complex n-tiered Web architecture. We made two underestimations. First, we underestimated how many problems we would uncover in the system once testing began. Our first test run failed at just 2 users and 100 orders processed. Second, we underestimated the length of time necessary to set up the test environment. Fortunately, we started planning for testing early enough that we had time to resolve or minimize the problems found prior to the deployment date. By paying close attention to design, the scalability of the system improved very quickly once the first few issues were successfully resolved.
You can begin planning for your testing effort by defining your testing environment. Depending on the size of your development effort, this may be a significant task.
Define Your Environment
In defining the testing environment, the first task is to evaluate what kind of effort is required. A general guideline we use for resource costs is that 15-20 percent of implementation time should be spent on testing, with approximately one third of this time dedicated to load testing.
It is important to create a separate testing environment that is comparable to production. If the machine configuration, speed, and setup aren't the same, extrapolating performance in production is nearly impossible. In other words, you can make a determination as to whether adding more hardware to your system will achieve greater scalability, but you cannot accurately answer questions like "how many users can one Web server in production handle?" One of your main tasks should be to reduce the uncertainty and answer questions with conclusive evidence. Without comparable hardware, you'll be forced to make educated guesses at best.
You may be cringing at the cost of putting production machines in your load testing environment, but consider the cost of finding hardware-related problems in production and the value in accurately predicting the load a single Web server can handle. Variables like processor speed and the available RAM affect the available system resources and consequently may change how scalability problems manifest themselves. In the lab, situational variables are your nemesis. Too many, and you cannot identify the source of the problem. Consider accelerating your production hardware purchase for use in the load testing lab if a separate environment is out of the question. The lab equipment can also be used as a standby for the production equipment once the system is deployed. Another benefit is that you will be able to iron out the system wrinkles long before your go-live date.
There are several reasons why you shouldn't test with your development environment. See the sidebar "Don't Use Your Dev Environment for Load Testing" for details. The same goes for the system test environment used by your QA team. It is intended for single user testing with the purpose of tracking functional bugs that appear independent of the system load. This kind of testing relaxes the constraints on the type of hardware used in the system test environment. It also receives more frequent software updates from the development team. In load testing, only releases that affect system performance should be installed, minimizing the amount of time spent tweaking load scripts.
In addition to the resources necessary to run the scalability lab, the success of your load testing effort depends on other roles within your organization. Figure 2 summarizes the roles.
Figure 2 Load Testing Team Required Roles
| Role | Contribution and Importance |
|---|---|
| Load test lab team | Takes ownership of the effort and runs the system test. Minimum of one person is necessary. Importance: critical. |
| Database | Identifies and solves database problems |
| administrator (DBA) | such as row locking and transaction timeouts. Importance: critical. |
| Development team | Identifies and tracks problems involving stability, performance, or transaction length. Helps identify areas where code practice can be improved. Importance: critical. |
| Business intelligence | Defines the quality bar for the site based |
| analyst | on available or projected information. This is an ongoing task since the level of traffic and the site features change over time. Importance: high. |
| Network team | Sets up the scalability lab hardware and builds it to production specs. Provides information about traffic on the production system. Identifies and resolves bottlenecks. If you use the production environment, you must increase this role. Importance: medium. |
| QA manager | Ensures that any external builds scheduled for deployment have been tested in the load test lab in conjunction with the regression and quality testing efforts of the QA team. Importance: medium. |
We cannot overemphasize the fact that the most important role outside of the lab is a strong database administrator (DBA). Scalability problems are most likely rooted in the database, the data access strategy (such as stored procedures, prepared statements, or inline SQL), or data access technologies (such as ADO, ODBC, and so on). The DBA can help identify and solve problems related to the database such as expensive indexing, excessive locking, and transaction timeouts. Ideally, you should have a dedicated, well-qualified DBA available as a full-time resource for key points in the load test effort.
We also recommend that you dedicate a member of your development team to the test lab on a rotating schedule so that each team member participates in this testing effort. If you do this, you'll get great cross-training while providing the lab with a continuous stream of fresh ideas.
Define Your Testing Strategy
By now you've had that meeting in which the customer leaned across the boardroom table and asked "Will this system handle thousands of users?" The conventional approach to load testing requires you to write scripts and perform tests that attempt to accurately answer this question. With this kind of testing, you need to define what you mean by handle and what 1000 typical users would be doing on the site. You need to define test cases to represent various user activities like buying a stock or registering a new account. Next, you must estimate the distribution of users across these test cases. Assumptions are made for how much think time (or wait time) is required to simulate a real user interaction with the application. A cross-section of activity during a load test would therefore approximate what the same number of real users would be doing on the site.
There are several flaws with this methodology. First, the results are only as good as the assumptions you make. Obviously, incorrect assumptions will skew the results.
Second, approximating real users requires a lot of client hardware. Given the amount of processing power and memory required per virtual user, a typical client machine can handle about 200 virtual users. Testing for a level of concurrency of 2000 users would therefore require 10 client machines—a significant investment. Testing the site using HTTPS will require substantially more client hardware.
Finally, this approach makes it difficult to provide action-oriented information to your development team. When something does go wrong, it is often difficult to reproduce the problem.
As an alternative, we suggest you design your test cases around these key questions:
- Where is the system bottleneck, and how many synchronized concurrent requests can it handle?
- How many nonsynchronized super users can one machine handle before response time becomes unacceptable?
- Do the results scale linearly as you add additional hardware?
- Are there any stability issues that will prevent the site from operating in a production environment?
This approach uses additional information from the development team which anticipates where problems might arise. Focus on these areas. Using our previous example, the order submission area is likely to be a bottleneck. From here you can derive more specific questions such as "how many simultaneous requests can the submit process handle?" Attacking these specific areas is the fastest and cheapest way to provide action-oriented information to your development team so that they can improve the system. While using this approach, we suggest you remember to follow these suggestions.
Focus the Load Testing As we've already mentioned, the first thing to do is build scripts that load potential bottlenecks and stability issues. This "data first, assumption second" approach lets you gather raw data from your application and then, based on your assumptions, determine higher-level results. Don't worry about scripting areas of the site which have been identified as low risk. For example, scripting the help area of the site or a read-only documentation area is unlikely to reveal a system bottleneck.
Synchronize the Requests Hit your bottleneck with synchronized requests. The idea here is to simulate the worst-case scenario—every user on your site hitting the bottleneck at exactly the same time. By synchronizing your users, you make this test repeatable. Not synchronizing the results makes it difficult to reproduce a failure. You can achieve this by using synchronization points, a feature found in most of the more robust (and costly) testing tools. A synchronization point forces each virtual user to wait until the remaining users reach a defined point in the script before beginning the next request. It allows you to accurately and repeatedly determine the number of concurrent users that can be handled by a potential bottleneck area of the site. As an example, your lower limit might be seven concurrent, synchronized users.
Create Circular Test Case Scripts Make your test cases circular. Put another way, the site should be in the same state before and after each test case iteration. This allows you to repeatedly run the test case over a long period of time.
Use Super Users Finally, use what we call super users. As mentioned before, super users run with think time set to zero. Remember that the think time assumption is used in conventional testing to make your virtual users simulate real users. However, if you were to halve the virtual user think time, you would effectively double load on the servers. Put another way, the only variable your servers really care about in relation to load is the number of requests per second. The number of virtual users and their think times are combined to produce that load.
Let's do some math to make this concept clearer. The following formula calculates the load generated (requests/second) by real users accessing the site:
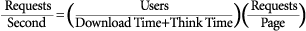
For example, a site with 100 concurrent users, assuming 10 seconds of download time and 30 seconds of think time, would produce about 2.5 pages per second. If we assume 3 requests per page, that would translate to 7.5 requests per second on the Web server.
Watch the number of requests per second as you run your tests with super users and compare against the number just calculated. In our experience, the ratio of real users to super users is typically around 15:1. Using the same example, that would mean that super users (100/15) would generate the same load as 100 normal users. To give you another example, let's say response time becomes unacceptable after 10 super users. Note the number of requests per second at that point to convert back to real users. Now you can make any think-time assumption you like and even change it without rerunning the test. After a few days of testing, you'll be able to intuitively convert from super users to real users. This approach allows you to keep the user count manageable, reduce the amount of client hardware required, and contain the cost of the load testing software.
These super user test cases are useful for more than just single-machine testing. To test the scalability of the site, add a second Web server and a load balancer and repeat your super user test. Ideally, you will be able to double the number of super users before you see the same response times.
To answer the stability question, run a test to sustain a reasonable number of concurrent, unsynchronized super users for an extended period of time. We used overnights and 24-hour periods on our last project, but the duration is application dependent. We refer to this as a "burn-in" test. Once you've taken steps to identify and potentially resolve the bottleneck found, repeat the synchronization point test to see if the lower limit has increased. Then rerun the "burn-in" test with the new number for concurrent users supported. Repeat this cycle with the goal of striving to improve upon this number until the quality bar is reached.Don't Use Your Dev Environment for Load Testing
There are several reasons why it is best to build a load test environment that is isolated from development and system test environments. First, even if the hardware is the same as production, the chance that you control the software installed and the configurations is small.
Second, load test scripts require a stable environment, as you'll want to minimize the amount of time spent rerecording scripts between tests. Some products allow you to ignore HTML or code changes to a Web page.
Yet page names, frame names, and query string changes will certainly cause your scripts to break. You want to minimize the number of times you allow code changes into the load test environment. Maintaining a separate environment means that rerecording may only be necessary between builds rather than throughout your testing day.
Also, because the development team will be adding additional load on the environment when testing functionality, it becomes difficult to isolate problems.
Finally, it is crucial to ensure version control for testing. You must be able to relate your metrics gathered to a specific build number. Without it, you can't accurately quantify the difference in performance between test runs when a change is made.
But How Many Users?
While this approach provides valuable information to the development team, it makes it more difficult to answer that boardroom question. However, you can approximate an answer. For example, say the worst-case bottleneck of the site shows response time over 10 seconds with more than 20 super users per machine. Based on your calculations from the formula we suggested, you approximate 300 real users (20 super users × 15 real users). At this point you can make the same kinds of assumptions as you would have made in the conventional case. What percentage of users would typically be using this area of the site? Say 50 percent are expected in this area and the other areas, like documentation or reading from the database, are not as popular. That means a system with one Web server would handle approximately 600 users.
So far we've discussed what to do if you can definitely point to one bottleneck area of the site, but what should you do if there is more than one area that might be affecting performance? The answer is to create test scripts that look at each area individually. First run the scripts in isolation, and then run them together. Then compare the results to see how much of an effect one area of the site has on another.
Know Your Metrics
The next step is to clearly define your metrics. Examples of metrics include the number of orders processed per minute or the number of milliseconds required to execute a request on an ASP page. Metrics allow you to quantify the results of the changes made between each of your test runs. They provide a comparison to the standard defined for your Web application.
In order to decide which metrics you need to track, there are a number of steps to work through. You need to define the questions for which you need answers, define the quality bar for each of these questions, and then determine which metrics are necessary to compare your test results to your quality bar.
The first step is straightforward. For example, you might want to know the checkout response time. Remember to form the questions in relation to the testing strategy and avoid vague questions you won't be able to test.
The next step is to define the quality bar for each of these questions. Let's use a typical order submission process as an example. We may decide that the site must handle 10 orders per minute during peak load and a user should not wait more than 30 seconds for a request to execute. In order to establish such a standard, you might look to a number of different sources. Talk to the business community first to get a feeling for the acceptable levels of performance for the system. Bringing historical data to these meetings can help facilitate the discussions and can often be used to manage expectations. If a version already exists in production, data can be gathered from current site activity and short-term projections of increased traffic, or by querying an existing database for activity trends.
With a list of questions and a quality standard for each question, you now need to determine which metrics to use. Based on the last example, orders per minute and the number of orders in a given test would be good high-level metrics serving as indicators of how the site measures up against the quality bar. These are the kind of metrics you'd report to management when you want to update them on the progress of your testing.
The lower-level metrics measure performance and help you resolve or minimize system bottlenecks and stability issues. Increasing performance may have a direct impact on your high-level metrics. For example, decreasing the transaction time of a specific activity may result in an increased number of orders per minute.
Most load testing tools allow you to set timers on individual pages or groups of pages and provide average times for running a test case. Both kinds of metrics allow you to account for the progress of your high-level metrics from one test run to the next, but neither metric assists you in providing any insight into what exactly needs improvement.
This is where Windows® performance counters are useful. For example, you could monitor Process:Private Bytes of the dllhost process to detect a memory leak in your server package. A good, detailed description of individual Microsoft® Internet Information Services (IIS) counters is available at The Art and Science of Web Server Tuning with Internet Information Services 5.0, and Figure 3 has a description of the main counters used in load testing and the trends to watch for.
Figure 3 Key Performance Counters
| Performance Counter | Description/Trends |
|---|---|
| Active Server Pages: Requests Per Second | If the counter is low during spikes in traffic, the application is causing a performance bottleneck. |
| Active Server Pages: Requests Executing | If pages execute quickly and don't wait for I/O, this number is likely to be low. If pages must wait for I/O, the value is likely to be higher. |
| Active Server Pages: Requests Queued | Should remain close to zero, but will fluctuate under varying loads. As the server reaches capacity, this number should start increasing to avoid resource contention. |
| System: Processor Queue Length | Displays the number of threads waiting to be executed in the queue shared by all processors in the system. If the value is consistently much higher than the number of processors, you have a processor bottleneck. |
| System: Context Switches Per Second | Combined rate at which threads on the computer are switched from one to another. Increasing threads may increase the number of context switches to the point where performance degrades instead of improves. Ten or more per request is high. |
| Process: Private Bytes | Current number of bytes this process has allocated that cannot be shared with other processes. Log this counter over several hours to pinpoint memory leaks in your components. |
| Processor: % Processor Time | Percentage of time that the processor is executing a non-idle thread. Processor bottlenecks may exist when this number is high while the network adapter card and disk I/O remain below capacity. |
| Distributed Transaction Coordinator: Active Transactions | Number of currently active transactions. |
However, performance counters are only useful in identifying the symptoms of a problem, not the cause. If your system breaks at 20 concurrent users, the Active Server Pages:Requests Timed Out counter may indeed confirm that at least one user timed out, but determining the cause of the timeout becomes a bit like looking for a needle in a haystack. This is due to performance counter data providing information primarily at the OS and network level. To successfully pinpoint the source of the problem, you need to access the data at the application level. Building a distributed logging system to retrieve and centrally store error and performance data from within your application is critical to this task. It allows you to know immediately whether your system is working. If it isn't, you have the information necessary to pinpoint the problem areas.
Interpret Your Metrics
With all these metrics at your disposal, you now have access to a lot of data. So how do you make sense of it in an efficient manner? There are three options we'll discuss for interpreting performance counter data: Performance Monitor, Perfcol, and performance data integrated with load testing tools.
The Performance Monitor in Windows 2000 allows you to display the progress of various counters graphically. A useful feature is the ability to capture readings in log files, allowing you to visually examine the entire test run upon its completion. Figure 4 illustrates how site activity on an online ordering application can be interpreted within Performance Monitor.
.gif "Figure 4")
Along the same line as Performance Monitor, the Windows DNA Performance Kit Beta contains a tool called Perfcol. This tool serves a purpose similar to Performance Monitor, except that it stores sampled data in a database rather than writing it to a file.
Some load testing tools such as the Microsoft Application Center Test (ACT) and the e-TEST suite from Empirix include built-in performance counter functionality that can record measurements over the duration of the test run. Counter data is then written to a database for later access. ACT, which is included with Visual Studio® .NET, integrates Performance Monitor counters, allowing all test data to be stored in a single repository.
Whether or not your load testing tool integrates some form of performance counter monitoring, you may find that you still need the support of a tool like Performance Monitor, particularly if your load generating servers do not have the appropriate security access to monitor the application servers, as frequently occurs when the environment includes firewalls.
Regardless of the monitoring tool you choose, the key is to store each test run's metrics for future evaluation. Going back to past data is critical to understanding how the system is reacting to the changes being made.
For application-level data generated by a logging system, we suggest building a viewer that enables you to obtain immediate access to error and performance information in one location. It's worth the effort, considering the alternative is generating a SQL query at the command line each time you require feedback.
Choosing the Right Load Testing Tool
To implement this testing strategy, you need to be able to choose a suitable load test tool. A complete evaluation of the available load testing tools is beyond the scope of this article, but we do want to help identify some options and considerations when making a decision on which kind of tool is appropriate.
The first option to consider are free tools like the Windows Application Stress Tool (WAST). On the other side of the scale, you can go with a more flexible tool such as ACT or Empirix's e-TEST suite. Figure 5 shows the interface for e-Load, the load-generating portion of the e-TEST suite.
.gif "Figure 5")
There are obviously some functional differences between the tools. WAST is a good tool to use for smaller sites that aren't too complex. You can easily test a couple of key pages on your site and get a good idea of what the response rate should be. However, it's more of an isolation test tool than one capable of testing a multipage site. Also, there are a few significant features not available in WAST that are necessary for testing complex sites (and implementing some of the recommendations in this article). Achieving complex results with WAST would require you to customize your application in order to load test it, which is obviously undesirable.
To perform the kind of testing that we're suggesting for complex sites, one of the more robust testing tools such as ACT or the e-TEST suite makes more sense. If you're developing in .NET, then ACT will integrate throughout your development cycle. However, it does require programming skills and knowledge of the ACT object model to produce powerful test scripts. If you decide instead to use a tool like e-TEST, you will need to pay licensing fees.
Figure 6** ACT Results Interface **
A quality tool must not only test the site effectively but also report the results of the test in a useful manner. Both ACT and e-TEST provide detailed reporting environments allowing you to graph your results as required. The ACT results interface is shown in Figure 6. Figure 7 provides a summary of common features and a description of what each type of tool has to offer.
Figure 7 Load Test Tool Feature Comparison
| Feature | Empirix e-TEST Suite | Application Center Test | Web Application Stress Tool |
|---|---|---|---|
| Browser emulation | Emulates Web traffic. Uses object-level recording that insulates the user from minor changes in code. Generates multithreaded browser requests that look like real traffic. | Provides programmable access to the load-generating scripts. Will automatically handle such browser details as cookies. | Records HTTP requests and then plays back copies of the recording. Doesn't take into account threading issues, client-side script, and other factors that affect how a real browser requests a page. The input response is independent of the output request. |
| Synchronization points | Available through a property setting. | Available through manually programming the script's behavior. | Not available. |
| Test duration | Allows you to specify time, the number of iterations, or allows you to stop the test manually. | Allows you to specify time, the number of iterations, or allows you to stop the test manually. | Tests are timed, so it does not guarantee that the start state for a user will equal the end state. |
| Regression testing | Serves the purpose of both a script creation tool and a regression test tool. | The same scripts that are used for load testing can be used for functional testing. Programming of the scripts is required to identify errors. | Not available. Specifically designed for load testing. |
| Distribute load across client machines | Tests can be coordinated from multiple client machines. | Not available. | Tests can be coordinated from multiple client machines. |
| Reporting | Stores session data in a database. Provides page timers and profile (test case) timers. Capable of graphically displaying test results such as the average times for the duration of the test run. | Stores session data such as server statistics and average time to first/last byte for a response. Can graphically display improvements between test runs. | Stores session data in a database. No page or profile timer functionality. Reporting available intabular format only from performance counters. |
| Executes client-side JavaScript | Yes, but depending on the script, a client agent that consumes more memory may be required. Try using the thin client first. | No. | No. |
If you do decide that a more robust tool is necessary, don't underestimate the time necessary to get up and running. Some tools will claim that it takes mere hours to write the scripts necessary to begin testing. This may be true if you have some previous experience with it or a similar load testing tool, but be prepared to spend a few days or even weeks in preparation, depending on the complexity of your site. Our first test case took approximately three weeks to get up and running. You may find that you cruised through the sample tutorial, but there are several tricks that can only be learned through experience and many calls to the support line. The cost of hours spent learning the tool may far outweigh the cost of formal training or the presence of an experienced consultant. Also, you can't afford the lost time if you're starting your testing effort late in the development phase, in which case one or both of these resources is strongly recommended.
Know Your History
The number of tests you run in a day or even a week may vary. If you're tuning the Web server, you may decide to run a series of hourly tests. If your goal is to test the stability of the application, you would likely run the test overnight. Either way, keeping track of the variables and the progress made from one test to the next is going to be difficult unless you keep a documented history. It's crucial that you can easily pinpoint what has already been tested for, what was found, and what should be tested next.
At a minimum, you should record the start and end time of the run, the number of virtual users in the test, and a start description that describes the goal of the test and what has been changed. Complete the run with an end description that describes the results of the test.
Conclusion
To successfully deploy a complex Web application, you must first adopt a "no surprises" approach to testing that goes beyond system testing. Load testing—consisting of scalability, performance, and stability testing—is the only way to uncover major problems inherent in the architecture. In order to achieve this, you'll need a separate environment with comparable production hardware, a robust load test tool, and the cooperation of several people in your organization.
Appropriate metrics provide the means for determining whether your system measures up to the quality bar. Of these, the most valuable to the scalability lab team is the error and performance data captured by a distributed logging system, since it provides information at the application level.
By using the recommendations discussed in this article and making sure to document as you go, you're well on your way to ensuring a smooth deployment date.
For background information see:
Scalability
Performance
The Art and Science of Web Server Tuning with Internet Information Services 5.0
Jeff Dunmall is a principal consultant at imason inc., an Internet consulting company specializing in legacy integration for companies building business-to-business and line-of-business applications. You can reach him at jeff.dunmall@imason.com.
Keith Clarke is an independent consultant based in Toronto. Along with his expertise in scalability testing, he specializes in .NET server technology consulting and technical training. He can be reached at keith.clarke@imason.com.