Design Patterns
Architecture of an Autonomous Application
Sten Sundblad and Per Sundblad
Contents
What Is a Fiefdom?
Secured Gateways
An Architecture Pattern
Emissaries
Validation Against Business Rules
Loose Coupling to Clients
XML-based Web Services
Designing XML Datasets According to Usage
Using Customized Entity Classes
Mapping an Entity Object to the Database
An XML Dataset is Never Connected to the DB
Conclusion
No man is an island. That's even true of developers. Software architects, designers, and developers need to communicate with each other in order to be successful. The same is true with applications. It used to be that an application could be thought of as self-contained. Mainframe applications, and on a smaller scale PC applications, contained everything they needed. They controlled the user interface, the business logic, and the data, all without having to look outside the application or letting outsiders in.
This isn't so anymore. The applications we build today often need to integrate with existing software, and that trend is likely to continue. What's more, increasingly applications are losing control of the user interface, both because it's designed elsewhere and because it's accessing the application over the Internet.
Obviously, when we architect and design applications, we should consider this need for integration across computing platforms. Luckily, there's an architectural solution. Service-Oriented Architecture (SOA) sees an application as a service that's discoverable and accessible over the Internet without regard to the platform the consumer is running on or which programming language was used in order to create the consumer. In other words, a service provides platform- and language-independent services. Web Services is just one example of this.
What Is a Fiefdom?
A service should be a completely autonomous application. It's not an island though because you can ask it to perform services for you. But it is autonomous in the sense that it completely controls its data and it denies the outside world direct access to that data or to its objects. The only way to access its goodies is to send it a message asking it to perform a task for you. If it doesn't like the way you ask or who you are, it will refuse to perform the service. Nobody decides this on its behalf; it decides for itself.
Pat Helland, an architect at Microsoft, was one of the first people to talk about autonomous applications, but he's not the only one anymore. It's a sound concept, as we'll try to show you in this column. Pat uses the term "fiefdom" to describe an autonomous application, and we'll use it here too.
A fiefdom keeps, manages, guards, and protects its main resource—its data. The data of a fiefdom can be kept in different types of data sources, but in most cases structured data is kept in a relational database such as Microsoft® SQL Server™. A fiefdom never allows anybody or anything outside of the fiefdom to gain direct access to its data. The fiefdom might access its data for somebody outside the fiefdom, and even operate on it on their behalf, but direct access is only given to the fiefdom.
A fiefdom doesn't allow an outsider to put a lock on any of its data. Therefore, you must think of all the data that leaves a fiefdom as a snapshot rather than the real thing. For all practical purposes, current data exists only inside the fiefdom. You can't expect the data you receive from it to be current, not even the moment you receive it. Some transaction inside the fiefdom might have changed the data, in its source, even before you receive the snapshot.
Most fiefdoms insist on managing their own transactions. A fiefdom should never allow an outsider to control a transaction or part of a transaction that runs inside the fiefdom. Yet, a fiefdom can expose a service to manage part of a transaction that's controlled and coordinated by an outside party, if that part of the transaction is what is called a compensating transaction. The fiefdom exclusively controls its part of the transaction, but it does it as a service to the client, which is a transaction coordinator.
An example of a compensating transaction is one that follows the Web Services Transactions specification, Part II: Business Activity (BA). Such a transaction has two distinct scenarios. The normal scenario performs the operations that are specified by the transaction. The compensating scenario performs another set of operations that are meant to remove the effects of an already committed transaction within the fiefdom. The compensating scenario is called by a transaction coordinator, which may itself be another fiefdom. It occurs when a fiefdom has already committed its part of the transaction and the coordinator later finds out that some other part of the transaction has failed. In such a case, the effects of the part of the transaction that was run and committed by the fiefdom must be removed, even though it can't be rolled back. The locks on its records are already released, and other transactions might already have changed their state. The compensating scenario removes these effects.
Not all types of transactions are suitable for compensation. Most fiefdoms would not (and should not) take part in transactions for which a robust compensating scenario doesn't exist.
Secured Gateways
To an extent, a service-oriented application is secure by the nature of its service orientation. The only way to have the application perform anything for you is to send it a message, asking it to perform some service. It's up to the application to decide whether to perform or deny the request.
In many cases, the application might permit anyone to have a certain service or set of services performed. In these cases, all the Web Service has to do is delegate the job to a suitable component and then deliver the response to the client. In other cases, the Web Service might need to authenticate the user to find out if he's authorized to have the service performed. This could involve a simple check against Active Directory® or a SQL database at the gateway only; it could also involve security techniques such as impersonation or delegation combined with role-based security checks at different levels within the application. Keep in mind that you must always consider the risk of denial-of-service attacks, hackers trying to intrude on the system, and other malicious threats.
As part of a security initiative, Microsoft has published several security-oriented documents; one of the most important is called "Building Secure ASP.NET Applications," now also available in book form (Microsoft Press®, 2003). You can download the document (Building Secure ASP.NET Applications: Authentication, Authorization, and Secure Communication) or you can buy the book; it contains a great deal of information on how to build in-depth security for your Web-based application.
An Architecture Pattern
Clearly, fiefdom is an architecture pattern. As with other patterns, you as a software architect should be able to say "I think we should design this application as a fiefdom," and the people around you should understand immediately what you're saying. That's one of the great advantages of patterns; they help you discuss architecture and design on a higher level of abstraction and give you a common vocabulary with which to do that.
Obviously, fiefdoms don't all have to be architected the same way. The set of services they will provide affects the component types they need internally, so any fiefdom would be architected by using other patterns as well within its internal implementation. For example, most fiefdoms would use patterns such as data accessors to access the database, service agents to access other services, data transport objects to transport data through the layers, and entity managers to uphold entity-level business rules.
Emissaries
Some fiefdoms will also provide UIs to its services. Such a fiefdom might use one of the emissary patterns—either a Web Form emissary or a Windows® Forms emissary. An emissary is like a sales agent or a mortgage broker. It can display reference data to the user, allowing the user to select from valid alternatives rather than type the information. The emissary also knows many of the business rules used by the fiefdom, so it can help the user fill the request in a way that the fiefdom is more likely to accept it.
An emissary can also save session state for the user. An obvious example is an ASP.NET Web Form that saves the shopping cart for the user between calls, thus allowing the user to add items to those already in the cart, where they remain until it's time to complete the purchase.
The fiefdom, however, doesn't trust the emissary, not even when the emissary must be viewed as a part of the fiefdom. Any request coming in through an emissary is evaluated for security, completeness, and correctness, just as carefully as a request coming in without the assistance of an emissary. This is exactly what an insurance company would do with an insurance application brought in by a sales agent. The emissary is there to serve the interests of the client more than the fiefdom.
So how do you distribute work between a fiefdom and its emissaries? Well, a fiefdom must work with shared data, which means that writing operations must be serialized in order to protect the integrity of the data. In contrast, emissaries can work with local read-only copies of reference data and with per-user data. Therefore, emissaries can ignore concurrency issues. Emissaries typically work with one client at a time in the demilitarized zone, whereas the fiefdom typically resides in a protected intranet and must always be available to all clients.
Using a Web Farm, emissaries can scale up practically without limit. It's much harder to scale out a fiefdom because it handles shared data that must always be available to all.
So, if you can distribute more work to emissaries, thus off-loading the fiefdom, the scalability of your application will improve considerably. You can achieve this through thoughtful design. Think of Amazon.com. When you work your way through their site by putting books and other items into your shopping cart, this could all be emissary work. Not until you press the Submit button to finalize the purchase do you need to engage the fiefdom.
But this is true only if you design your system wisely, drawing a clear line between the fiefdom and the emissary and using performance and scaling enhancers, such as the cache object, vigorously. You must also design the fiefdom's service interfaces in a way that interaction between emissaries and the fiefdom can be minimized.
Validation Against Business Rules
Some requests sent to a fiefdom require the saving or deletion of data. There's no way a fiefdom should accept such requests without carefully validating the request itself against security policies and its data against business rules. That's why business rules and policies belong to fiefdoms, as defined by Pat Helland, and in services, as defined by SOA.
Loose Coupling to Clients
A fiefdom is loosely coupled to its clients. There's normally no connection at all between the client and the fiefdom until the client establishes one by sending a message to the fiefdom. The fiefdom acts on the message and sends a response to the client. The response might be the result of the requested operation, or it might be a refusal to perform the service. In any case, the connection between the client and the fiefdom is broken as soon as the fiefdom has responded, much like an HTTP exchange of messages. Like HTTP, there are ways to maintain the connection over an entire session, but it's normally limited to one complete message cycle.
Loose coupling is good for scalability. It minimizes the time any client is connected to the system and using the system's resources. Loose coupling is the same principle that once governed the design of Microsoft Transaction Services (MTS), which later evolved into COM+ Component Services, and is now known as .NET Enterprise Services.
XML-based Web Services
One of the ideas behind SOA is location transparency; another is independence of computing platform and programming language. Web Services are ideal for meeting the demands underlying these ideas. Since a Web Service is known by its URL, its actual location can change as long as the service provider still points to it.
Since a Web Service is completely independent of the underlying platform and programming language, it only requires the client to understand SOAP, XML, and the transport protocol used. The transport protocol is normally HTTP, but it could also be SMTP or any standard Internet transport protocol.
One could argue that any fiefdom written in a Microsoft .NET-targeted language should expose its data and functionality through Web Services. It shouldn't necessarily expose those Web Services to the outside world; their only type of direct client could very well be emissaries that are well known by the fiefdom.
The interior of a fiefdom should be built on the concept of loose coupling between the fiefdom and its clients. The fiefdom should use stateless service components rather than collections of state objects. It should, as much as possible, transport and manipulate data in the same form in which it receives it and delivers it to clients, which is in the form of XML streams. The Microsoft .NET Framework helps because it provides perfect XML-based APIs for the transport of data through a fiefdom and for the exposure of data to clients.
These APIs are comprised of the XML datasets of ADO.NET. The data access capabilities of ADO.NET make it easy to fetch data from any number of database tables, filling an XML dataset with that data. You can easily transport such a dataset between components, even over process and machine boundaries, to the consumer. In addition, because the data contained in a dataset can be regarded as an easy-to-use XML document, it's extremely easy to use it as an XML Web Service response. Finally, even if the dataset contains XML, you don't have to use XML syntax in order to access or to manipulate its data. You can use ordinary object-oriented syntax such as TrainerData.Trainers(3).LastName in order to access a property.
We sometimes hear an argument against the use of XML datasets to represent business entities that goes something like this: "We don't want to expose the structure of the database to the client." In fact, in most cases it would be extremely unwise to allow the structure of the database to influence the structure of an XML dataset. Usage needs alone should dictate the structure of a dataset. You could easily define the structure of a dataset without having a clue about the structure of the database; it's certainly possible to define all the datasets of an application before even starting on the design of the database.
Designing XML Datasets According to Usage
As an example, you should consider the View Upcoming Racedays use case belonging to a racing application that we built in our previous books and articles. The purpose of this use case is to display a list of upcoming race dates. The data needed includes Date, Track, City, and Country.

Figure 1** XML Dataset **
Knowing the data requirements for this use case, we can design an XML dataset for it. Figure 1 represents the ideal design of such a dataset. As you can see, the dataset contains only one table. The RaceDayTable data table contains all the data the use case needs. With the exception of the RaceDayId column, each column in the data table corresponds to a column shown to the client, as seen in Figure 2. (The RaceDayId column is in the data table to allow the user to select one of the race days displayed and then to have details on that race day displayed on another page.)
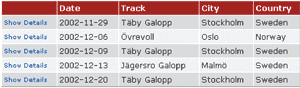
Figure 2** Raceday Details **
Let's see where this data comes from. As shown in Figure 3, which displays part of the database model for the application, you must access four database tables to create the one and only dataset table needed by the use case.
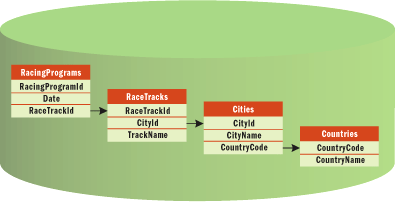
Figure 3** Four Database Tables **
Just for fun, also take a look at a stored procedure that can move the data from the four database tables to the one dataset table, using one SQL SELECT statement and only one round-trip to the database, as shown in the following code:
CREATE PROCEDURE GetFutureRacedays AS SELECT RacingProgramId As RaceDayId, Date, TrackName As RaceTrackName, CityName, CountryName FROM RacingPrograms As RP JOIN RaceTracks As RT ON (RP.RaceTrackId = RT.RaceTrackId) JOIN Cities As Ci ON (RT.CityId = Ci.CityId) JOIN Countries As Co ON (Ci.CountryCode = Co.CountryCode) WHERE Date > GetDate() ORDER BY RacingProgramId
As you can see from this example, the structure of the dataset and the structure of the database are totally different. This is because the dataset is designed from the requirements of a single use case, whereas the database is designed using formal rules that help prevent anomalies from occurring when using the data.
Using Customized Entity Classes
Let's see how developers who don't want to expose the structure of the database to the client would design their objects. Chances are they will follow one of the popular design patterns for stateful objects, which represent the so-called domain model. The domain model, of course, represents the objects of the real-world domain. In our racing application, the domain model would consist of classes such as horses, trainers, jockeys, and races.
Incidentally, the real source for domain data is the database. This is where most structured data is stored. It stands to reason that the database model closely represents the domain; therefore, it is a domain model.
This is why the set of entity classes in an application, which is mainly comprised of customized entity classes, closely corresponds to the set of tables in a database that represents the same domain. This is also one reason that many developers grossly underestimate the value of real data modeling as opposed to class modeling.
Ideally, the correspondence between the class domain model and the relational domain model shouldn't be as close as it usually is; the database should be properly normalized. Normalizing in-memory entity classes the same way often leads to a lot of code that you don't really need. It also leads to increased complexity of that code and to slow operations.
Mapping an Entity Object to the Database
So why do in-memory entity classes tend to be as normalized as database tables? This is mainly because of the strategies often used to map the in-memory objects and the relational tables to each other. With few exceptions, authors who recommend a memory-based domain model also recommend a nearly one-to-one mapping between memory-based classes and database tables.
Figure 4 provides a simplified example of what a client must face in such a situation. With the exception of keys and collection classes, this is an exact replica of the database tables. It goes without saying that it takes more than one SQL SELECT statement to populate these four entity objects. It's also obvious that it takes longer to make four round-trips to the database than it takes to make one round-trip. And it's all in the interest of making the client less dependent on the database.
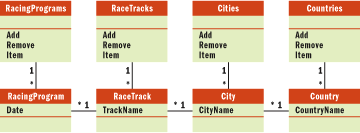
Figure 4** Result of Mapping **
It should be clear that exposing XML datasets to client applications is not the same as making the client dependent on the database. In fact, it's the opposite! But you must understand the XML datasets to take full advantage of them. When you define their XSD schemas, you should concentrate exclusively on their usage; you shouldn't consider the structure of the database at all.
This is especially important in service-oriented apps. A service-oriented app exposes programming interfaces that return XML streams or XML documents to clients. This is at least true for service-oriented apps that expose Web Services. The structure of an XML document is controlled by its XSD schema, and the same is true for XML datasets which, in effect, are XML documents.
An XML Dataset is Never Connected to the DB
What some developers may not know yet is that an XML dataset is never connected to the database. It can't be. To move data between an XML dataset and a database you need some kind of proxy to map dataset tables to relational tables. ADO.NET offers such an object, which comes in different flavors for different database products. It's called a data adapter, and its only purpose is to move data between datasets and data sources. The dataset itself doesn't know anything about the database or about the SQL statements that fill it or that move data to a data source.
So why is it so easy to be confused about this? Why do so many believe that using a dataset means depending on the database? The reason is probably that the XML dataset, in a manner of speaking, is a replacement for the old recordsets used in traditional ADO, Remote Data Objects (RDO), and Data Access Objects (DAO). In all of these models, the recordset is directly connected to a data source such as a relational database. The only exception is the ADO recordset, which can be disconnected from and then reconnected to the database.
XML datasets are entirely different from the old recordsets. Their purpose is to keep and transport snapshots of data, totally independent from and in total ignorance of any database that the data might come from.
Conclusion
The next time you're involved in starting a software development project, consider architecting it as a fiefdom. If your would-be application will expose a user interface, which most applications do, you should think about architecting it as a set of emissaries. The emissaries should try as much as possible to do their jobs without consulting the fiefdom, except when it's absolutely necessary. For example, they should cache reference data and they should keep session state without bothering the fiefdom. An application built this way will be more scalable than an application that makes maximum use of server resources such as shared data.
This strategy will help you design your fiefdom to use stateless components. This is extremely useful in terms of scalability and simplicity. However, you should use stateful components only when absolutely necessary. In most applications, you should really consider using ADO.NET XML datasets as data transporters. Together with data adapters, they work beautifully with databases. They work across process and machine boundaries transparently, and they're completely based on XML. They are designed for data binding, which in many cases should be the preferred method of displaying data to users in Web Forms or Windows Forms.
If you want to learn more about Pat Helland's fiefdom and emissary architecture patterns, listen to him in person at Architect Webcasts: Autonomous Computing: Fiefdoms and Emissaries; it's well worth the time spent.
Send your questions and comments for Design Patterns to mmpatt@microsoft.com.
Sten Sundblad and Per Sundblad jointly run Sundblad & Sundblad ADB-Arkitektur in Sweden, a company specializing in .NET development in general, and architecture and design in particular. Together they wrote Designing for Scalability with Microsoft Windows DNA (Microsoft Press, 2000) and Design Patterns for Scalable Microsoft .NET Applications (Sundblad & Sundblad, 2002). More information on Sten and Per is available at https://www.2xSundblad.com. You can reach them at stens@2xSundblad.com and pers@2xSundblad.com, respectively.