XML in Yukon
New Version Showcases Native XML Type and Advanced Data Handling
Bob Beauchemin
Code download available at:XMLinYukon.exe(114 KB)
This article was based on Beta 1 of Microsoft SQL Server Code Named "Yukon" and all information contained herein is subject to change.
Note: This document was developed prior to the product's release to manufacturing and, as such, we cannot guarantee that any details included herein will be exactly as the same as those found in the shipping product. The information represents the product at the time this document was printed and should be used for planning purposes only. Information subject to change at any time without prior notice.
SUMMARY
The next version of Microsoft SQL Server, code-named "Yukon," represents quite a few steps forward in the evolution of XML integration. Yukon supports native storage of XML data using the XML data type, which makes it possible to run native queries on XML data using the emerging industry standard XQuery language. Data integrity of the XML data type can be enforced through schema validation and XML-based check constraints, and special indexes can be defined that help speed up queries. In addition, Yukon has the built-in ability to expose its data through Web services. This article discusses these and other XML features of Yukon.
Contents
The XML Data Type
XML Indexes
The XML Data Type Functions
XQuery 1.0—An XML Query Language
Using The XQuery Functions
XQuery Extended Functions in SQL Server
XML DML—Updating XML Columns
FOR XML and OpenXML Enhancements
Native Web Service Support
Wrap-up
The next version of Microsoft® SQL Server™, code-named "Yukon," takes the groundbreaking XML support that was introduced in SQL Server 2000 and enhances it to include even more innovative functionality and ease of use. Yukon adds native XML data storage to the database management system (DBMS) through a new native XML data type. The introduction of this native XML data type, coupled with the emerging industry standard XQuery language, should spark a revolution in database application development.
Support for the native XML data type is extensive. It includes XML Schema-based validation and additional XML-based constraints, special XML Infoset-based indexes, and queries over XML content objects using XQuery. In addition to this radical new functionality, the existing SQL Server 2000 XML functionality has been fine-tuned for better performance and ease of use.
XML itself is a platform-independent data representation format that was used initially as a document format. As XML has gained wide acceptance, users have sought to solve tough business problems like data integration via XML. This has led to the evolution of XML as a data storage format. XML, like its structured counterpart, has its own type system based on the XML Schema Definition language (XSD). Both XML and XSD are W3C standards at the recommendation level. An XML Schema defines the format of an XML document, just as a SQL Server schema defines the layout of objects in a SQL Server database. The XML type system is quite rigorous; XSD can define almost all of the constructs available in relational databases, object-oriented type systems, and semi-structured and unstructured document formats. (See the sidebar "Standards Compliance".)
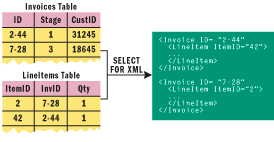
Figure 1** Hierarchical XML Returned from FOR XML **
XML data is hierarchical, and XML documents used in business applications are most often comprised of data that is stored in multiple relational tables. For example, an XML order document might contain customer information, order information, and order detail information. In a relational database, this information would typically be stored in multiple tables. In SQL Server 2000, you had two choices if you wanted to store XML: store the entire document in a text field, or decompose the document into multiple relational tables. If you chose text field storage, you would use SQL Server only to store and retrieve the data; queries against the document content would occur in client-side libraries.
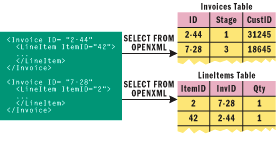
Figure 2** From OpenXML to Tables **
In SQL Server 2000, by using the FOR XML extension to the Transact-SQL (T-SQL) SELECT statement you could query multiple relational tables and compose the returned data into a hierarchical XML document, as shown in Figure 1. The system-defined OPENXML function accomplished document decomposition, as shown in Figure 2, and also permitted distributed relational queries between XML and relational data. In Yukon this support is enhanced to include composition, decomposition, and distributed relational queries. It also includes native XML queries and native XML storage, as shown in Figure 3.

Figure 3** XML Storage **
The XML Data Type
Let's look at the XML data type and see how it differs from the conventional storage of an XML document in a text data type. The new data type is a first-class type; you can use it in most of the ways any other SQL Server data type can be used, including as a column in a table, a variable in T-SQL, a stored procedure or user-defined function parameter, or a user-defined function return value.
The XML type is quite similar to the concept of a distinct type defined by SQL-99 (the latest version of the ANSI SQL standard) and to the character-based large object (CLOB) types varchar(max) and nvarchar(max). You must convert it to and from a varchar or nvarchar type, although the T-SQL INSERT statement will do automatic conversion from a varchar and nvarchar value used in a VALUES list to an XML data type column value. You cannot CAST or CONVERT the XML type to any type other than varchar or nvarchar. Two instances of an XML data type cannot be compared. Like a SQL-99 distinct type, the XML type has its own methods; these methods enable you to use an alternate query language, XQuery. The data in an XML type does not follow the relational data model, but it does follow the XQuery 1.0 and XPath 2.0 data model.
The primary reason for having an XML data type is that when you define an XML data type column, the data in that column is stored in the database itself. The column is not a pointer to an XML document on the file system. This means that XML data is included in the backup and restore process, is subject to ordinary SQL Server security, and participates in transactions and logging. Having XML data inside a relational database may offend some relational purists, but it means that your data lives in a single repository for reasons having to do with administration, reliability, and control.
Here's an example of using an XML type in a table. The table stores invoice documents in XML format.
CREATE TABLE invoices ( id INTEGER IDENTITY PRIMARY KEY, xmlinvoice XML)
Note that you cannot use the XML column itself as a primary key. This is because instances of the XML data type are not directly comparable, though they can contain (and be tested for) a NULL value. Although it would not be difficult to perform a string comparison with XML data, it would be an order of magnitude more difficult to perform a comparison at the data level. For example, the following two XML documents are data-equivalent, but nowhere near lexically equivalent:
<!-- These two documents are equivalent --> <doc1> <row au_id="111-11-1111"/> </doc1> <doc1> <row au_id='111-11-1111'></row> </doc1>
You can store XML documents or XML fragments in an instance of the XML data type. XML fragments are data instances that follow the rules for well-formed XML, but do not necessarily contain a single root element. Well-formed means simply that the document conforms to the syntax defined in XML 1.0.
As an example, the output of the T-SQL FOR XML query is an XML fragment; it doesn't have a root element. Permitting fragments as well as documents is consistent with the XQuery 1.0 and XPath 2.0 data model. The data that you store in an XML data type must be well formed, however.
Because XML data types follow the XML XQuery 1.0 and XPath 2.0 data model, they are not constrained by relational constraints, but by an XML Schema. In addition to storing XML documents or fragments in an XML data type column, you can also use SQL Server to validate your XML data type column by associating the column with an XML Schema. Therefore, you can think of XML data types, which can contain documents or fragments, as being schema-valid—that is, conforming to a type defined in a schema or merely well formed.
XML Schemas define a set of data types that exist in a particular namespace. Schemas are themselves well formed, and conform to a schema called the schema for schemas. Schemas are valid XML documents, just as relational table definitions and other data definition language (DDL) statements are valid T-SQL. Although there can be more than one schema definition document for a particular namespace, a schema definition document defines types in only one namespace. XSD defines a standard set of base types that are supported as types in XML documents, in just the same manner as the SQL-99 standard defines a set of base types that relational databases must support.
In order to be able to validate an XML document with its corresponding schema, SQL Server Yukon stores XML Schemas in the database. Schema documents are catalogued in the SQL Server Engine by using the CREATE XMLSCHEMA DDL statement, as shown in the code in Figure 4.
Figure 4 CREATE XMLSCHEMA
CREATE XMLSCHEMA'<xsd:schema xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns:tns="https://example.org/People" targetNamespace="https://example.org/People" > <xsd:simpleType name="personAge" > <xsd:restriction base="xsd:float" > <xsd:maxInclusive value="70" /> <xsd:minExclusive value="0" /> </xsd:restriction> </xsd:simpleType> <xsd:element name="age" type="tns:personAge" /> </xsd:schema>'
An XML Schema is dropped from the database by referring to its target namespace. For example, the schema I just catalogued would be dropped by the following statement:
DROP XMLSCHEMA NAMESPACE 'https://example.org/People'
Note that no matter how the database is configured, namespaces are case-sensitive.
XML data type columns, parameters, and variables may be typed or untyped—that is, they may conform to a schema or not. To specify that you're using a typed column (for example, in the XML column in Figure 4), you would specify the schema namespace in parentheses, like this:
CREATE TABLE xml_tab ( the_id INTEGER, xml_col XML('https://example.org/People') )
By doing this, you've just defined a series of integrity constraints with respect to what can appear in the XML that comprises that column. Typing the XML data in a column by using an XML Schema not only serves as an integrity constraint, but as an optimization for the SQL Server XQuery engine because you are using typed data in the query. This also allows the XQuery engine to know the data type of its intermediate and final results. If the XML data is not strongly typed, XQuery can either perform implicit type conversions based on the syntax of the query, as T-SQL does in some cases, or treat everything as a string data type.
When an XML Schema is stored in SQL Server, it is not stored directly as an XML document. Instead, it is shredded into a proprietary format that is useful for optimizing schema validation. Once you have stored your XML Schema, it's possible for SQL Server to reconstruct most of it using the xml_schema_namespace function. However, items such as annotations and comments are not reconstructed by this function, so you may need to keep track of the original schema document separately. A convenient way to keep a full-fidelity copy of a schema for later use would be to store it in a separate table as a varchar(max) column.
XML Indexes
The syntax for creating an index on an XML column is similar to what you'd use to create a SQL index:
CREATE XML INDEX xml_idx ON xml_tab (xml_col)
Although this looks like a normal index creation statement with an extra XML keyword, the actual effect of the statement is much different than what you get when you create a traditional index. What you are creating in the case of an XML column is an index over the internal representation of the column for the purpose of optimizing XQuery queries, not SQL queries. Remember that the SQL comparison operators cannot be used on an XML column. Because XML indexes and SQL indexes share the same value space in a database, you cannot create an XML index and a SQL index with the same index name. You can, however, also create a full-text index on the contents of an XML type column; this is unrelated to an XML index. (The details of full-text search are outside the scope of this article.)
The XML Data Type Functions
In addition to being able to use an XML data type as a column in a table or view, variable, or parameter in its entirety, the XML data type contains a variety of type-specific methods. These are invoked by using a double-colon variable::method syntax. The XML type functions encompass a couple of different types of functionality: determining if a node or nodes exist for a given XQuery path expression, and querying and modifying the value of the XML type through XQuery.
The XML data type is, by definition, a complex type—that is, a type that almost always contains more than one data value. You can use XML data type columns in two distinct ways. First, you can query the data and perform actions on it using T-SQL as though it were a simple data type. This is analogous to the way you would treat an XML file in the file system; you read the entire file or write the entire file. Second, you can run queries and actions on the XML data in the column, using the fact that the XQuery 1.0 and XPath 2.0 models allow the concrete data to be exposed as a series of data values or nodes. For this you need an XML query language.
XQuery 1.0—An XML Query Language
In addition to the SQL Server query functions, Yukon supports a set of native XQuery functions that are designed specifically for the XML data type. Although XQuery appears to be nominally SQL-like, it's designed especially to handle the semi-structured nature of XML data, including strong recursion capabilities and node navigation. In addition to the query capabilities of XPath, XQuery allows element and attribute construction via XSLT. A native XQuery 1.0 engine and an XPath 2.0 parser live inside of the Yukon query processor alongside the relational engine. Unlike XPath 1.0, XQuery 1.0 and XPath 2.0 are strongly typed query languages. This is quite evident in the wide range of constructors and casting functions for different data types. The reasoning behind this is that XQuery is built to be optimized and uses strong types rather than strings. This allows the query engine to do a better job in optimizing and executing the query. Just imagine if the T-SQL query parser in SQL Server had to deal with everything as a single data type!
XML data type columns, XML variables, and XML procedure parameters can be strongly typed by reference to an XML Schema, or they can be untyped. When typed XML is used in an XQuery, the query parser has more information to work with. If untyped XML is used, the query engine must start with the premise that every piece of data is a string type; the built-in data function can be used with strongly typed data to return the exact data type.
XQuery supports static type analysis, meaning that if the types of items that are input into an expression are known, the output type of an expression can be inferred at parse time. In addition, strong typing permits the XQuery language to syntax-check the input based on types at parse time, just as T-SQL can. This results in fewer implicit type conversions at run time. SQL Server supports XQuery on the XML data type directly. It does this through three XML data type methods:
- xml::exist takes an XQuery as input and returns 0, 1, or NULL depending on whether the query returns an empty sequence (0), a sequence with at least one node (1), or the column is NULL.
- xml::value takes an XQuery as input and returns a SQL type as a scalar value.
- xml::query takes an XQuery as input and returns an XML data type as a result.
Standards Compliance
In addition to the prolific specifications for everything XML, guided by the W3C, the ANSI SQL committee has gotten into the act with an effort to standardize the integration of XML and relational databases. This series of specifications started under the auspices of the SQLX committee of database vendors, but has been subsumed as part 14 of the ANSI SQL 200n specification. A committee that includes representatives from Microsoft, Oracle, IBM, and other companies is working on this part of the SQL specification.
This specification touches on a number of subjects that I've discussed in this article. Although OpenXML and FOR XML predate the standard and are not included in it, the new XML features in SQL Server follow the standard closely. The XML data type in Yukon is patterned after the XML data type defined by the ANSI SQL specification. The data model of the XML data type defined by ANSI SQL part 14 is based on the XPath 2.0 and XQuery 1.0 data model. This data model permits an XML data type to contain XML documents, document fragments, and top-level text elements. The SQL Server XML data type adheres to this standard.
Because both the XPath and XQuery data model and ANSI SQL part 14 are specifications in progress, the specs may be out of sync at various points in the standardization process. SQL Server uses the standard way to encode SQL names as XML names (XML names have different escape character rules), and almost the exact rules for converting between SQL types and XML types.
The mapping of the database to a virtual XML document is implemented in the client libraries and will be enhanced in the next release of Visual Studio® .NET and the .NET Framework, code-named "Whidbey." This mapping is a superset of the single canonical mapping in the proposed spec.
The dialect of XQuery that's currently implemented using these functions in the prerelease version of SQL Server Yukon reflects the December 2001 version of the XQuery specification as a base. As SQL Server Yukon and the XQuery specifications move closer to production, the syntax will become more closely aligned to the current working specification.
Although the XQuery language itself can be used to construct complex documents, only the xml::query function takes full advantage of this feature. When using xml::value and xml::exist, you'll normally create simple XPath 2.0 expressions rather than complex XQuery with sequences, constructors, formatting information, and so on. This is because xml::value can only return a sequence containing a single scalar value (it cannot return an XML data type), and xml::exist is used to check for Boolean existence.
Using The XQuery Functions
The xml::exist function will search the specified XML column, looking up data that matches the given XQuery expression. For each row, if it contains matching data in the specified column, the function returns true (1). The XML functions can be used in check constraints on XML columns, either in addition to or instead of XML Schema constraints. Here's an example:
-- pdoc must have a person element -- as a child of the people root CREATE TABLE xmltab( id INTEGER PRIMARY KEY, pdoc XML CHECK (pdoc::exist('/people/person')=1) )
The xml::value function takes a textual XQuery as a string and returns a single scalar value. The SQL Server type of the value returned is specified as the second argument, and the value is cast to that data type. The data type can be any SQL Server type except a SQL Server XML data type, a user-defined type, or a SQL Server timestamp data type.
The xml::value function must return a single scalar value, or else an error is thrown. You don't need to have xml::value to return a single XML data type—that's what xml::query does.
Using a simple document and table values such as this
CREATE TABLE xml_tab( the_id INTEGER PRIMARY KEY IDENTITY, xml_col XML) GO INSERT xml_tab values('<people><person name="curly"/></people>') INSERT xml_tab values('<people><person name="larry"/></people>') INSERT xml_tab values('<people><person name="moe"/></people>') GO
the following SQL query using xml::value would produce a single row containing the ID and the name for each row.
SELECT the_id, xml_col::value('/people/person/@name', 'varchar(50)') AS name FROM xml_tab
The result would look like this:
the_id name -------- ------------------------ 1 curly 2 larry 3 moe
Although all of the functions of the XML data type invoke the internal query processor, the function that actually executes a complete XQuery on an instance of the XML data type is xml:query. This function takes the XQuery text, which can be as simple or complex as you like, as an input string and returns an instance of the XML data type. The result is always an XQuery sequence as the spec indicates, except when your XQuery instance is NULL. If the input instance is NULL, the result is NULL. The resulting instance of an XML data type can be returned as a SQL variable, used as input to an INSERT statement that expects an XML type, or in can be returned as an output parameter from a stored procedure.
In SQL Server Yukon, remember that the xml::query function refers to a specific column (or instance of the XML data type), and input will come from that column or instance's data—this is the context document. The simplest XQuery might consist of nothing but an XPath 2.0 expression. This would return a sequence containing zero or more nodes or scalar values. Given the previous document, a simple XQuery
SELECT xml_col::query('/people/person') AS persons FROM xml_tab
would return a sequence containing a single node for each row:
persons ----------------------------------- <person name="curly"/> <person name="larry"/> <person name="moe"/>
XQuery differs from XPath in that, in addition to querying a document, it may be used to compose a document utilizing what are known as node constructors. This is analogous to XSLT, but implemented differently. Figure 5 contains an example that constructs a Payment XML document from an Invoice document. The invoice document used and the payment document produced are included in the code download for this article (see the link at the top of this article).
Figure 5 Constructing XML
SELECT invoice::query(' {-- XQuery program --} namespace inv="urn:www-develop-com:invoices" namespace pmt="urn:www-develop-com:payments" for $invitem in //inv:Invoice return <pmt:Payment> <pmt:InvoiceID> { data($invitem/inv:InvoiceID) } </pmt:InvoiceID> <pmt:CustomerName> { data($invitem/inv:CustomerName) } </pmt:CustomerName> <pmt:PayAmt> { data(sum($invitem/inv:LineItems/inv:LineItem/ inv:Price)) }</pmt:PayAmt> </pmt:Payment> ') as xmldoc FROM xmlinvoice
XQuery Extended Functions in SQL Server
Because the XQuery engine is executing in the context of a relational database, Yukon provides two convenient, standard ways to use non-XML data (that is, relational data) inside the XQuery itself. The extension functions sql:column and sql:variable serve this purpose. These functions allow you to refer to relational columns in tables and to T-SQL variables from inside an XQuery.
These functions can be used anywhere an XQuery can be used, namely xml:exist, xml::value, xml::query, and also xml::modify (which is discussed in the following section of this article). Figure 6 contains a user-defined function that returns all overpriced items in a particular invoice.
Figure 6 UDF to Return Items
CREATE FUNCTION OverPricedItems(@price money, @theid int) RETURNS xml AS BEGIN declare @x as xml select @x = invoice::query(' {-- XQuery program --} namespace inv="urn:www-develop-com:invoices" for $invitem in //inv:Invoice/inv:LineItems/inv:LineItem where $invitem/inv:Price > sql:variable("@price") return <OverPriced> <Sku> { data($invitem/inv:Sku) } </Sku> <Price> { data($invitem/inv:Price) } </Price> </OverPriced> ') from xmlinvoice where id = @TheID return @x END
XML DML—Updating XML Columns
One thing that was left out of the XQuery 1.0 specification was a definition of an XQuery syntax for mutating XML instances or documents in place. Currently there is no announced plan to add a data manipulation language (DML) to the XQuery specification, although a "standard extension to the standard" is being discussed by some vendors. Because Yukon will use XQuery as the native mechanism for querying the XML data type inside the server, it is required to have some sort of manipulation language. The alternative would be to give users only the ability to replace the instance of the XML type as an entire entity. Since changes to XML data type instances should participate in the current transaction context, this would be equivalent to using SELECT and INSERT in SQL without having a corresponding UPDATE statement. Therefore Yukon introduces a nonstandard implementation of XML DML.
XML DML is implemented using XQuery-like syntax with SQL-like extensions. This emphasizes the fact that manipulating an XML instance inside SQL Server is equivalent to manipulating a complex type or, more accurately, a graph of complex types. You invoke XML DML by using the xml:modify function on a single XML data type column, variable, or procedure parameter. You use XML DML within the context of a SQL SET statement, using either UPDATE...SET on an XML data type column, or by using SET on an XML variable or parameter. A simple example of the UPDATE...SET syntax would look like this:
-- change the value of XML data type column instance UPDATE some_table SET xml_col::modify('some XML DML') WHERE id = 1 -- change the value of an XML variable DECLARE @x XML -- initialize it SET @x = '<some>initial XML</some>' -- now, mutate it SET @x = @x::modify('some XML DML')
The xml::modify function supports the inserting, updating, and deleting of nodesets in an existing instance of an XML type. An example that inserts the InvoiceDate element as the first child of an Invoice element is shown in the following:
SET @x::modify(' {-- XQuery program --} namespace inv="urn:www-develop-com:invoices" insert <inv:InvoiceDate>2002-06-15</inv:InvoiceDate> as first into /inv:Invoice ')
FOR XML and OpenXML Enhancements
The composition and decomposition functionality in SQL Server 2000 have been improved in Yukon. Although the major change to OpenXML is support of the XML data type (as an output column and through its related XML parsing stored procedure, sp_xml_preparedocument), the FOR XML syntax contains a number of exciting enhancements.
SQL Server 2000 provides an enhancement to T-SQL that permits composition of XML document fragments using SQL queries against relational tables. There are three dialects of FOR XML queries: FOR XML RAW, FOR XML AUTO, and FOR XML EXPLICIT. FOR XML RAW produces one XML element for each row in the result, no matter how many tables participate in the query. There is an attribute for each column, and the names of attributes reflect the column names or aliases. FOR XML RAW has been enhanced in Yukon to allow XML in element-normal form. FOR XML AUTO produces one XML element by row in the result, but produces nested XML elements if there is more than one table in the query. The order of nesting is defined by the order of the columns in the select statement. FOR XML EXPLICIT produces XML via SQL UNION queries. Each arm of the SQL UNION queries produces a different level of XML. This is by far the most flexible dialect and can produce element- or attribute-normal form and nested XML exactly as you like. This is also by far the most complex dialect to program.
SQL Server Yukon offers quite a few refinements and enhancements to FOR XML queries:
- FOR XML can produce an instance of an XML type.
- FOR XML AUTO and FOR XML RAW are able to preface the XML result with an inline schema in XSD schema format. The previous version of FOR XML could only preface an inline DTD or an XDR (XML Data Reduced) schema.
- You can nest FOR XML queries.
- You can produce element-centric XML using FOR XML RAW.
- You can choose to generate xsi:nil for NULL database values rather than leaving that element out of the XML result entirely.
- There is improved handling of white space by encoding some white space characters as entities.
- There are subtle improvements to the algorithm for determining nesting in FOR XML AUTO.
The most interesting of these enhancements is that FOR XML can produce an instance of the XML data type. This is an XML fragment that can be wrapped in a root element and returned to the caller, queried, or mutated with the XML data type functions, and stored in an XML column. An example of using FOR XML queries to produce input to a table using the SELECT INTO syntax is shown in the following:
-- create a table CREATE TABLE xml_tab(id INT IDENTITY PRIMARY KEY, xml_col XML) -- populate it with a FOR XML query DECLARE @x XML SET @x = (SELECT * FROM pubs.dbo.authors FOR XML AUTO) INSERT INTO xml_tab VALUES(@x) GO
Native Web Service Support
Web services expose a standard mechanism for communication that uses standard protocols and a common message format. The network protocol most often used is HTTP, with SOAP employed as the message format. XML Web services can be produced and consumed by any platform that can produce XML-style text messages and send them across HTTP, making it a popular method of communication across unlike systems, and may displace proprietary protocols over time.
SQL Server 2000 allowed communication over HTTP by using IIS and an ISAPI DLL. This DLL allowed users to issue HTTP requests (subject to security checks, of course) to well-known endpoints exposed by XML-based files known as templates. SQLXML Web Release 3.0 expanded the capability of the ISAPI DLL to produce SOAP packets, allowing programmers to expose SQL Server through IIS as a Web service.
Any stored procedure, user-defined function, or template query can be exposed as a SOAP endpoint. Output is available in a variety of formats, some optimized for .NET based consumers, but all using the SOAP protocol. The ISAPI application was also expanded to produce Web Services Description Language (WSDL), a standardized dialect of XML that describes the format and location of a Web service. This allowed any program that could consume WSDL to know how to communicate with SQL Server.
If you've installed SQL Server Yukon on Windows Server™ 2003, you can get even better performance and functionality due to improvements in the HTTP handlers at the OS level, including the ability to serve HTTP from multiple applications on the same port (like SQL Server and IIS at the same time).
The new functionality is built directly into Yukon. Rather than storing configuration information in the registry or the IIS metabase, the information is stored as SQL Server metadata, which can be defined with T-SQL. The relevant DDL statements are CREATE HTTP ENDPOINT, ALTER HTTP ENDPOINT, and DELETE HTTP ENDPOINT. With HTTP ENDPOINT statements, you can define all of the properties of the HTTP support and define stored procedures and user-defined functions as Web methods. You can also allow ad hoc SQL queries using your endpoint. Figure 7 shows an example endpoint definition against the pubs database that permits ad hoc queries and defines the byroyalty stored procedure as a Web method.
Figure 7 Endpoint Definition
CREATE HTTP ENDPOINT pubs_endpoint AS SITE = '*', PATH = '/pubs/', AUTHENTICATION = (INTEGRATED), PORTS = (CLEAR), STATE = STARTED FOR SOAP ( WEBMETHOD 'urn:www-develop-com:invoices'.'byroyalty' ( name=pubs.dbo.byroyalty, SCHEMA = STANDARD ) WITH BATCHES = ENABLED, -- allow ad-hoc queries WSDL = ENABLED, DATABASE = 'pubs' ) GO
Wrap-up
This article has provided a brief overview of the XML functionality enhancements found in the prerelease version of SQL Server Yukon. I haven't covered the client-side enhancements, only those that actually live in the SQL Server engine, and I haven't discussed the details of XQuery. To cover these would require another article or two, although SQL Workbench comes with a graphic XQuery tool to get you started. I hope that this article whets your appetite to try out the XML support in Yukon for yourself.
Bob Beauchemin is an instructor, course author, and database curriculum course liaison for DevelopMentor. He's written articles on ADO.NET, OLE DB and SQL Server. Bob is the author of Essential ADO.NET (Addison-Wesley, 2002) and coauthor of the upcoming book, A First Look at Microsoft SQL Server "Yukon" Beta for Developers, from which this article is excerpted.