New information has been added to this article since publication.
Refer to the Editor's Update below.
C# In-Depth
Harness the Features of C# to Power Your Scientific Computing Projects
Fahad Gilani
Code download available at:ScientificC.exe(127 KB)
This article assumes you're familiar with C#
SUMMARY
The C# language has been used quite successfully in many kinds of projects, including Web, database, GUI, and more. One of the last frontiers for the application of C# code may well be scientific computing. But can C# measure up to the likes of FORTRAN and C++ for scientific and mathematical projects?
In this article, the author answers that question by looking at the .NET common language runtime to determine how the JIT compiler, Microsoft intermediate language, and the garbage collector affect performance. He also considers C# data types, including arrays and matrices, along with other language features that play an important role in scientific computing applications.
Contents
Computational Science
Performance and Languages
MSIL and Portability
Is the JIT Compiler Getting Any Better?
Automatic Memory Management
Object Orientation
High-precision Floating-point Operations
Value Types, or Lightweight Objects
Complex Arithmetic
Multidimensional Arrays
The Unsafe Approach
Language Interoperability
Benchmarks
Conclusion
The C# language has gained much respect and popularity among developers working in very different areas. Over the last couple of years, C# has played an important role in delivering robust products, from desktop applications to Web services, from high-level business automations to system-level applications, and from single user products to enterprise solutions in network-wide distributed environments. Given the powerful features of this language, you might ask if C# and the Microsoft® .NET Framework can be used for more than just GUI and Web-based components. Is it ready to be taken seriously by the scientific community for developing high-performance numerical code?
The answer to this is not entirely straightforward because a number of other questions need to be answered first. For example, what is scientific computing? Why is it any different from conventional computing? Do languages really have characteristics that outline their relevance to scientific programming?
In this article, I will exploit some intrinsic features of C# that allow developers to employ performance-critical code in an easy, practical fashion. You will see how C# can play a serious role in the scientific community and open doors for next-generation numerical computing. You will also see how, despite rumors that managed code is slow due to memory management overhead, reasonably complex code performs blazingly fast; it is not interrupted by the garbage collector simply because most numerical processing doesn't discard enough memory to invoke garbage collection. I will explore the qualities that make C# a good choice in the numerical computing world. I will also look at some benchmarks and compare results with unmanaged C++ to see where C# stands in terms of performance and efficiency.
Computational Science
The availability of computers has enabled scientists to more easily prove theories, solve complex equations, simulate 3D environments, forecast weather, and perform many other processor-intensive tasks. Over the years, literally hundreds of high-level languages have been developed to facilitate the use of computers in these areas (some with a highly specialized conceptual framework of concurrent programming, such as Ada and Occam, and some that remained ephemeral computer science tools, like Eiffel or Algol). There were a few, however, that emerged as prominent scientific programming languages, such as C, C++, and FORTRAN—all of which have played a major role in the scientific computing world for quite some time now.
But how do you decide which high-level language to use for scientific programming? In general, for a language to qualify as a platform for producing scientific computational code, it must provide a rich set of tools that can be used for measuring performance and must allow developers to express the problem domain easily and effectively, among other criteria. Essentially, a scientific programming language should be able to produce efficient high-performance code, which can be carefully fine-tuned.
Performance and Languages
Performance has been one of the key differentiators for languages used in scientific programming. Compilers and code generation techniques are often considered performance-limiting factors, but this assumption isn't entirely correct. The most widely used C++ compilers, for example, do a good job of code generation and optimization. There are some subtleties, but they are usually less important than the efficiency of the code. For example, in C++ you should avoid creating too many temporary objects, particularly since it's a language where it's remarkably easy to create unnamed temporaries without realizing it. You can do this using expression templates, which allow you to defer the actual calculation of a mathematical expression until it is assigned. As a result, you'll avoid incurring a large abstraction penalty at run time.
This isn't to say that language features are the only factors affecting performance. When languages are explicitly evaluated against each other to measure performance and cost, what's really evaluated is the skill of compiler writers, not the languages themselves. If you can get acceptable performance from a language, a runtime, or a platform, then the choice might only be a matter of taste.
If you've had experience with C# and are thinking of doing some serious scientific computing, there's no need to resort to another language; C# is more than capable.
MSIL and Portability
Like all other .NET-targeted languages, C# compiles to Microsoft Intermediate Language (MSIL), which runs on the common language runtime (CLR). The CLR can loosely be depicted as the amalgamation of a just-in-time (JIT) optimizing compiler and a garbage collector. C# exposes and makes use of much of the functionality in the CLR, so it's important to take a closer look at what's going on in the runtime.
One of the key requirements for scientists is code portability. Scientific research institutes and laboratories work with a number of platforms and machines, both Unix-based workstations and PCs. They frequently want to run code on different machines in pursuit of better results or because a particular machine offers them a suite of data processing and analysis tools. Achieving complete hardware transparency, however, has not been an easy task and was not always entirely possible. For example, most large-scale projects are developed using a hybrid approach with multiple languages; therefore, it is difficult to ensure that an application that works on one architecture or platform will also work on another.
The CLR enables applications and libraries to be written in a collection of languages that compile to MSIL. The MSIL can then be run on any supporting architecture. Scientists can now write their math libraries in FORTRAN, employ them in C++, and use C# and ASP.NET to publish their results on the Internet.
Unlike the Java Virtual Machine (JVM), the CLR is a general-purpose environment designed to be a target for a variety of programming languages. Moreover, the CLR provides data-level, not just application-level, interoperability, and allows sharing of resources among languages.
There are a number of languages for which compilers are available that output MSIL. These languages include (but are not limited to) Ada, C, C++, Caml, COBOL, Eiffel, FORTRAN, Java, LISP, Logo, Mixal, Pascal, Perl, PHP, Python, Scheme, and Smalltalk. In addition, the System.Reflection.Emit namespace provides functionality that dramatically lowers the entry bar for developing new compilers that target the CLR.
Porting the CLR to different architectures is a work in progress. However, an open source implementation has been developed by Mono/Ximian and is available for s390, SPARC and PowerPC architectures, and StrongARM systems. Microsoft has also released an open source version that runs on FreeBSD systems, including Mac OS X. (For more information see Jason Whittington's article "Rotor: Shared Source CLI Provides Source Code for a FreeBSD Implementation of .NET" in the July 2002 issue of MSDN® Magazine.)
All of these developments have taken place in just the past few years. Given a little more time, it's likely that a full-featured CLR will be available for all commonly used architectures.
Is the JIT Compiler Getting Any Better?
JIT compilation is a remarkable bit of technology that opens the gates for a wide range of optimizations. Despite the fact that the current implementation is restrictive in the number of optimizations that can be performed due to time constraints, in theory it should be able to outperform any static compiler that exists. Of course, this is because dynamic properties of performance-critical code or its context are not fully known or verified until run time. The JIT compiler is able to exploit this gathered information by emitting more efficient code which can, in theory, be re-optimized every time it's run. Currently, the compiler emits machine code only once per method. Once machine code is generated, it executes at raw machine speed.
In scientific programming, this can be a handy tool. Scientific code is primarily comprised of numbers and numerical arithmetic. To perform these computations in a reasonable amount of time, some hardware resources need to be carefully utilized. Although a number of static compilers do a good job of optimizing code, the dynamic nature of the JIT compiler allows it to optimize resource utilization using techniques such as priority-based register allocation, lazy code selection, cache-tuning, and CPU-specific optimizations. These techniques also give you headroom for more rigorous optimization, such as strength reduction and constant propagation, redundant load-after-store, common sub-expression elimination, array bounds check elimination, method inlining, and so on. While it is possible for a JIT compiler to perform these types of optimizations, the current .NET JIT doesn't do the advanced ones.
In the past, it was general practice for the programmer to ensure that the code running on a certain machine was hand-optimized for the underlying architecture (by software pipelining for instance, or manually utilizing the cache). Running the same code on another machine with different hardware required modifying the original code to reflect the new hardware. Over time, processors have changed in the way they execute code, using special built-in instructions or techniques. These optimizations can now be exploited through the JIT compiler without the need to modify existing code. As a result, code that is run on a workstation at work can be made to perform equally well on a home PC that uses a completely different architecture.
The JIT compiler that ships with the .NET Framework 1.1 has improved considerably compared to its predecessor, version 1.0. The chart in Figure 1 shows performance comparison between CLR version 1.0 and 1.1 by running the SciMark 2.0 benchmark suite on the two platforms. The test machine was a 2.4GHz Pentium 4 with 256 MB RAM.
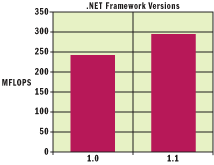
Figure 1** JIT Improvement in .NET 1.1 **
The SciMark benchmark is comprised of a number of common computational kernels found in scientific applications, each possessing different behavioral patterns in terms of memory access and floating-point operations. These kernels are: Fast Fourier Transformations (FFT), Successive Over-Relaxation iterations (SOR), Monte-Carlo quadrature, sparse matrix multiplications, and dense matrix factorization (LU) for the solution of complex linear systems.
SciMark was originally developed in Java (https://math.nist.gov/scimark) and was ported to C# by Chris Re and Wener Vogels. Note that this implementation doesn't use unsafe code, which could give it a small speed boost on the order of 5 to 10 percent.
Figure 1 shows the composite score in millions of floating-point operations per second (MFLOPS) for the two versions of the .NET Framework. This should give you an approximate idea of how well the current version (1.1) performs and how much better it will probably be in future versions.
The chart shows that version 1.1 of the common language runtime outperforms version 1.0 by quite a significant margin (specifically, 54.1 MFLOPS). Version 1.1 incorporates a number of performance improvements in its overall implementation, including some targeted architecture-specific optimizations that were added to the JIT compiler, such as a double-to-integer cast using IA-32 SSE2 instructions. The compiler, of course, generates optimized code for other processors as well.
I expect the next release of the JIT compiler to perform even better, and it's only a matter of time until JIT compilers will be able to produce faster running code than static compilers.
Automatic Memory Management
From an implementation standpoint, automatic memory management is probably the best gift the CLR could give to developers. Memory allocation is relatively fast (a heap pointer is simply moved to the next free slot), compared to a slower, expensive free-list traversal in a C/C++ malloc or new call. Moreover, memory is managed automatically at run time, freeing and compacting unutilized space. Programmers are no longer required to go chasing around pointers, freeing up blocks of memory prematurely or not freeing them at all (although languages like C# and Visual C++® still give developers that option).
It's almost predictable the way many developers react at the thought of using a garbage collector. While it's true that garbage collectors incur a small runtime cost in memory-intensive applications, they also take care of all the messy details of chasing down memory leaks and cleaning up dangling pointers. They keep your heap managed, compacted, and recycled at all times.
Recent studies and experiments have shown that in computationally intensive applications where objects are being allocated and released more frequently, garbage collection can actually speed up performance by compacting the heap. In addition, frequently referenced objects that would otherwise be spread out randomly in memory are squeezed together to provide better locality and cache utilization. This speeds up overall application performance at large. At the same time, one of the shortcomings of garbage collectors is their unpredictable timing, which can make it difficult to carry out collections at just the right time. Research in this area has been progressing and garbage collectors have improved over the years. In time better algorithms will emerge to provide more deterministic behavior.
Earlier I mentioned that numerical code generally does not invoke garbage collection. That holds true for moderately simple applications where you're largely concerned with crunching numbers and where there aren't many allocations involved. It really depends on the nature of the problem and the way you've designed the solution. If it involves a lot of objects with short or medium lives, the garbage collector will be invoked quite frequently. If a few objects have long lives and aren't released until the application terminates, then these objects will be promoted to older generations, resulting in significantly fewer collections (if any at all).
Figure 2 shows an application performing matrix multiplication that does not invoke the garbage collector.
[Editor's Update - 4/21/2004: In Figure 2, the Columns property was incorrectly returning the number of rows rather than the number of columns. The listing has been fixed.] I chose matrices because they're at the core of many scientific applications in the real world. Matrices provide a practical way of approaching many problems in areas such as computer graphics, computer tomography, genetics, cryptography, electrical networks, and economics.
Figure 2 Matrix Multiplication Did Not Invoke Garbage Collection
using System;<br xmlns="https://www.w3.org/1999/xhtml" />/// <summary><br xmlns="https://www.w3.org/1999/xhtml" />/// A class representing a Matrix /// </summary> class Matrix { double[,] matrix; int rows, columns; // This will not be called till before the applicationterminates ~Matrix() { Console.WriteLine("Finalize"); } public Matrix(int sizeA, int sizeB) { rows = sizeA; columns = sizeB; matrix = new double[sizeA,sizeB]; } // Indexer for setting/getting internal array elements public double this[int i, int j] { set { matrix[i,j] = value; } get { return matrix[i,j]; } } // Returnnumber of rows in the matrix public int Rows { get { return rows; } } // Return number of columns in the matrix public int Columns { get { return columns; } } }/// <summary> /// Matrix Multiplication Example /// </summary> class MatMulTest { [STAThread] static void Main(string[] args) { int i, size, loopCounter;Matrix MatrixA, MatrixB, MatrixC; size = 200; MatrixA = new Matrix(size,size); MatrixB = new Matrix(size,size); MatrixC = new Matrix(size,size); /*Initialize matrices to random values */ for (i=0; i<size; i++) { for (int j=0; j<size; j++) { MatrixA [i,j]= (i + j) * 10; MatrixB [i,j]= (i + j) * 20; } } loopCounter =1000; for (i=0; i < loopCounter; i++) Matmul(MatrixA, MatrixB, MatrixC); Console.WriteLine("Done."); Console.ReadLine(); } // Matrix multiplication routinepublic static void Matmul(Matrix A, Matrix B, Matrix C) { int i, j, k, size; double tmp; size = A.Rows; for (i=0; i<size; i++) { for (j=0; j<size; j++) { tmp = C[i,j]; for (k=0; k<size; k++) { tmp += A[i,k] * B[k,j]; } C[i,j] = tmp; } } } }
The code in Figure 2 defines a Matrix class which declares a two-dimensional array for storing matrix data. The Main method creates three instances of this class with dimensions 200 × 200 each (each object approximately 313KB in size). A reference to each of these matrices is passed to the Matmul method by value (the references themselves are passed by value and not the actual objects), which then performs a multiplication on the two matrices A and B, and stores the result in matrix C.
To make things more interesting, the method Matmul is called 1,000 times inside a loop. In other words, I managed to reuse these objects to effectively perform 1,000 "different" matrix multiplications without once invoking the garbage collector. You can monitor the number of collections using the .NET common language runtime memory performance counters.
However, for larger calculations, garbage collection will ultimately be unavoidable as you'll be requesting more space than is available. In these situations you could resort to alternatives, such as isolating performance-critical portions of your code to unmanaged code and then calling them from managed C# code. One caveat here is that P/Invoke or .NET interop calls incur a small runtime overhead so you might want to consider this as a last resort, or use it if you're sure that the granularity of the operations will be course enough to pay off the invocation cost.
Garbage collection should not hold you back from producing high-performance scientific code. Its purpose is to eliminate memory management problems that you would otherwise have to face on your own. As long as you're aware of how it works and what it costs, you won't need to worry about garbage collection overhead.
Now let's move away from the CLR and onto the language itself. As I mentioned earlier, C# has a number of features that make it quite suitable for scientific computing. Let's look at some of these features one by one.
Object Orientation
C# is an object-oriented language. Since the real world is composed of highly interrelated objects with dynamic properties, the object-oriented programming approach is often the best solution to scientific programming problems. Moreover, well-structured, object-oriented code can be more easily modified by replacing internal pieces as needed for the changes in scientific models.
However, not all scientific problems exhibit object-like features or relationships, and so object orientation can cause an unnecessary complication for such cases. For example, the matrix multiplication code in Figure 2 could have been written without the use of a special matrix class by declaring three multidimensional arrays in a single class.
The problem may involve a complex relationship between objects that would programmatically introduce further complexity or unwanted overhead. Take molecular dynamics (MD) for instance. Molecular dynamics is widely used in computational chemistry, physics, biology, and material science. It was one of the first scientific uses of computers going back to the work of Alder and Wainwright who, in 1957, simulated the motions of about 150 argon atoms. In MD, scientists are interested in simulating atoms interacting with each other via pairwise potentials in a similar manner to the way gravity influences the interaction between the planets, sun, moons, and stars. Modeling the interaction between two atoms using an object-oriented approach might not be such a bad idea. But consider a fictitious cubic box containing N3 atoms, where N is a very large number. The resulting equations for evaluating all the pairwise forces and energies would turn out to be so arithmetically intense that resorting to a traditional procedural approach (non-object-oriented) could become necessary for simplicity and performance issues. That said, procedural code could easily be more complex and less performant. It really depends on the data storage and algorithms used.
You can do this with C#. It might not be the most optimal use of the language's powerful object-oriented programming (OOP) capabilities, but it will provide the traditional scientific programmer with a good start. A single class can contain all the variables and methods for performing calculations and producing results. Nevertheless, for relatively large problems OOP can be a valuable tool for scientific programming as it provides modularity and data integrity, which make code expansion and reuse easier.
High-precision Floating-point Operations
No scientific code can ignore precision and accuracy. Even though the most powerful computers today only represent precision in a finite number of digits, having higher precision will help achieve more accurate results. The importance of this cannot be underestimated and is made clear by disasters caused by computer arithmetic errors, such as the famous unmanned Ariane 5 Rocket explosion in 1996 (a 64-bit floating-point number in the inertial reference system was incorrectly converted to a 16-bit signed integer...boom). Of course, you're probably not developing rocket software, but it's important to know how and why high precision in many scientific applications is so important, and how the IEEE standard 754 for binary floating-point arithmetic can actually be more constraining than helpful.
C# allows a higher precision type to be used for floating-point arithmetic on hardware platforms that support it, such as Intel's 80-bit double format. This extended type has greater precision than the double type and is used implicitly by the underlying hardware in performing all floating-point arithmetic, thus giving accurate, or near-accurate, results. The following excerpt has been taken directly from the C# specification, section 4.1, as an example of C# support for high-precision floating-point operations:
...in expressions of the form x * y / z, where the multiplication produces a result that is outside the double range, but the subsequent division brings the temporary result back into the double range, the fact that the expression is evaluated in a higher range format may cause a finite result to be produced instead of an infinity.
C# also supports the decimal type, a 128-bit data type suitable for financial and monetary calculations.
Value Types, or Lightweight Objects
There are two main categories of types in C#—reference types (heavyweight objects) and value types (lightweight objects).
Reference types are always allocated on the heap (with the sole exception of when the stackalloc keyword is used) and impart an extra layer of indirection; that is, they require access via a reference to their storage location. Since these types cannot be accessed directly, a variable of a reference type always holds a reference to the actual object (or null) and not the object itself. Given that reference types are allocated on the heap, the runtime must ensure that each allocation request is carried out correctly. Consider the following code, which may result in a successful allocation:
Matrix m = new Matrix(100, 100);
Behind the scenes, the CLR memory manager is passed an allocation request, which calculates the amount of memory required to store the object along with its header and class variables. The memory manager then checks available free space on the heap to see if there's enough room for an allocation. If there is, the object is successfully allocated and a reference to its storage location is returned. If there is not enough space to store the object, the garbage collector kicks in to free some space and compact the heap.
If the process is successful, there's another vital step the memory manager must take before the object can be written to memory in order to keep the generational garbage collector operational. This step involves generating a piece of code called a write barrier (implementation details for a generational garbage collector are beyond the scope of this article). Conversely, a write barrier is generated by the runtime every time there's an object written into some address in memory or when an object makes a reference to another object in memory (such as an object from an older generation pointing to an object from a younger generation). One of the many intricacies of making a generational garbage collector work is remembering that these object writes exist so that objects aren't erroneously collected during a collection process while they're being pointed to by another object from another generation. As you might have guessed, these write barriers incur a small runtime cost, and so having millions of objects created at run time wouldn't be an ideal scenario for a scientific application.
Value types are stored directly on the stack (although there is an exception to this rule that I'll look at in a moment). Value types do not require indirection and so variables of value types always hold the actual value itself and cannot hold references to other types (thus, they cannot hold null). The main advantage of using value types over reference types is that their allocation entails little runtime overhead. They are allocated by simply incrementing the stack pointer and are not managed by the memory manager. These objects will never invoke garbage collection. Moreover, value types do not generate a write barrier.
In C#, primitive data types (int, float, single, byte), enumerations, and structs are all examples of value types. Although I said earlier that value types are stored directly on the stack, I didn't use the word "always" as I did for reference types. A value type residing inside a reference type will not be stored on the stack but rather on the heap, contained inside the reference type object. For example, take a look at the following code snippet:
class Point { private double x, y; public Point (double x, double y) { this.x = x; this.y = y; } }
An instance of this class will take up 24 bytes, from which 8 bytes will be for the object header and the remaining 16 bytes will be for the two doubles, x and y. At the same time, having a reference type inside a value type object (an array inside a struct, for example) does not result in the whole object being allocated on the heap. Only the array will be allocated on the heap with a reference to the array placed in the struct on the stack.
Value types derive from System.ValueType, which itself is derived from System.Object. Because of this, value types exhibit class-like characteristics. Value types can have constructors (except for a parameterless constructor), methods, indexers, and overloaded operators, and they can implement interfaces. However, they cannot be inherited, nor can they inherit from other types. These objects easily qualify for a number of JIT optimizations, which result in the generation of efficient, high-performing code.
One caveat here is that it's extremely easy to accidentally trap value types into an object and cause it to be allocated on the heap—a technique known as boxing. Make sure that your code does not box values unnecessarily or you'll lose the performance you initially gained. Another caveat is that arrays of value types (such as an array of double or int) are stored on the heap, not the stack. Only a value holding the reference to the array is stored in the stack. This is because all array types implicitly derive from System.Array and are all reference types.
For scientific applications, value types can be fast, efficient, and an excellent choice over reference types whenever possible. In the next section, I'll take a look at one of the many uses of user-defined lightweight data types in scientific programming.
Complex Arithmetic
Even though C#, like C, does not support an intrinsic complex number data type, it doesn't stop you from creating your own. You can do so using a struct, which has value semantics.
A complex number is an ordered pair of real numbers (say x and y) multiplied by an the imaginary number i, and conforms to some arithmetic laws. In this example, z is a complex number:
z = x + yi, where i2 = -1
Complex numbers are widely used in scientific applications for studying physical phenomena, such as electrical current, wavelengths, and liquid flow in relation to obstacles, analysis of stress on beams, movement of shock absorbers in cars, the design of dynamos and electric motors, and the manipulation of large matrices used in modeling. They form fundamental equations of almost everything in this universe, and so being able to treat a complex number as just another data type in a programming language is vital for many scientific applications.
Figure 3 shows a basic implementation of a user-defined complex number data and its use.
[Editor's Update - 4/21/2004: In Figure 3, the subtraction operator used to subtract a Complex from a float was printed incorrectly and the equality operators were incorrectly comparing the Complex parameters. The listing has been fixed.] It essentially presents two different aspects of C# that contribute greatly to scientific computing. These are: the use of struct, a valuable resource for creating custom data types that benefit from being treated like just another primitive type (primitive data types in C# are all structs), and operator overloading of binary and unary operators on user-defined types, which significantly improves readability and manageability of scientific code. This point deserves some further attention. Most significantly, operator overloading improves code readability, which is extremely important in scientific computing. Although the same effect can be achieved by using method calls, this is not always a good idea if your code revolves around a number of complicated numerical expressions. Take the following simple numerical expression, for example, involving three complex numbers:
C3 = C1 * C2 + 5 * (C1-13)
If this was to be written using method calls, you'd have something like the following line of code:
Complex C3 = C1.multiply(C2).add((C1.minus(13)).multiply(5));
Forget one brace in the middle someplace and you'll find yourself staring at the screen trying to find the compiler error. Imagine what it would be like writing a much more intricate numerical expression than this. Or imagine going back to your code after a period of time and trying to change a method's name from "add" to "multiply" out of an expression which is nested with numerous add and multiply method names. First you'll have to understand what the code does and then, if you're lucky, you'll make the changes to produce correct results after a couple of unsuccessful attempts. Operator overloading allows you instead to express numerical expressions in their natural, logical form.
Figure 3 User-defined Complex Number Type
using System; /// <summary> /// Implementation of a single-precision Complex Number /// </summary> public struct Complex { // Real and Imaginaryparts of a complex number private float real, imaginary; public Complex(float real, float imaginary) { this.real = real; this.imaginary = imaginary; } //Accessor methods for accessing/setting private variables public float Real { get { return real; } set { real = value; } } public float Imaginary { get { returnimaginary; } set { imaginary = value; } } ////////////////////////////////////////////// // // Implicit and Explicit conversion operators // // Implicit conversion of Complex-to-float public static implicit operator float(Complex c) { return c.Real; } // Explicit conversion of float-to-complex (requires // explicit cast) public staticexplicit operator Complex(float f) { return new Complex(f, 0); } ////////////////////////////////////////////// // // Arithmetic overloaded operators: // +, -, *, /, ==, != //public static Complex operator +(Complex c) { return c; } public static Complex operator -(Complex c) { return new Complex(-c.Real, -c.Imaginary); } publicstatic Complex operator +(Complex c1, Complex c2) { return new Complex(c1.Real + c2.Real, c1.Imaginary + c2.Imaginary); } public static Complexoperator +(Complex c1, float num) { return new Complex(c1.Real + num, c1.Imaginary); } public static Complex operator +(float num, Complex c1) { returnnew Complex(c1.Real + num, c1.Imaginary); } public static Complex operator -(Complex c1, float num) { return new Complex(c1.Real - num, c1.Imaginary); } public static Complex operator -(float num, Complex c1) { return new Complex(num - c1.Real, -c1.Imaginary); } public static Complex operator -(Complex c1, Complex c2) { return new Complex(c1.Real - c2.Real, c1.Imaginary - c2.Imaginary); } public static Complex operator *(Complex c1, Complexc2) { return new Complex((c1.Real * c2.Real) - (c1.Imaginary * c2.Imaginary), (c1.Real * c2.Imaginary) + (c1.Imaginary * c2.Real)); } public static Complexoperator *(Complex c1, float num) { return new Complex(c1.Real*num, c1.Imaginary*num); } public static Complex operator *(float num, Complex c1){return new Complex(c1.Real * num, c1.Imaginary*num);} public static Complex operator /(Complex c1, Complex c2) { float div = c2.Real*c2.Real +c2.Imaginary*c2.Imaginary; if (div == 0) throw new DivideByZeroException(); return new Complex((c1.Real*c2.Real + c1.Imaginary*c2.Imaginary)/div,(c1.Imaginary*c2.Real - c1.Real*c2.Imaginary)/div); } public static bool operator ==(Complex c1, Complex c2) { return (c1.Real == c2.Real) &&(c1.Imaginary == c2.Imaginary); } public static bool operator !=(Complex c1, Complex c2) { return (c1.Real != c2.Real) || (c1.Imaginary != c2.Imaginary); }public override int GetHashCode() { return (Real.GetHashCode() ^ Imaginary.GetHashCode()); } public override bool Equals(object o) { return (o is Complex)?(this == (Complex)o): false; } // Display the Complex Number in natural form: // ------------------------------------------------------------------ // Note that calling thismethod will box the value into a string // object and thus cause it to be allocated on the heap with a size of // 24 bytes public override string ToString() {return(String.Format("{0} + {1}i", real, imaginary)); } } /// <summary> /// Class for testing the Complex Number type /// </summary> public classComplexNumbersTest { public static void Main() { // Create two complex numbers Complex c1 = new Complex (2,3); Complex c2 = new Complex (3,4); //Perform some arithmetic operations Complex eq1 = c1 + c2 * -c1; Complex eq2 = (c1==c2)? 4*c1: 4*c2; Complex eq3 = 73 - (c1 - c2) / (c2-4); // Implicitconversion of Complex-to-float float real = c1; // Explicit conversion of float-to-Complex (requires // explicit cast) Complex c3 = (Complex) 34; // Printcomplex numbers c1 and c2 Console.WriteLine ("Complex number 1: {0}", c1); Console.WriteLine ("Complex number 2: {0}\n", c2); // Print results ofarithmetic operations Console.WriteLine ("Result of equation 1: {0}", eq1); Console.WriteLine ("Result of equation 2: {0}", eq2); Console.WriteLine ("Resultof equation 3: {0}", eq3); Console.WriteLine (); // Print results of conversions Console.WriteLine ("Complex-to-float conversion: {0}", real);Console.WriteLine ("float-to-Complex conversion: {0}", c3); Console.ReadLine (); } }
When dealing with actual values stored on the stack, you might think that operator overloading would have no effect on the overall speed of execution. In theory, it shouldn't affect performance at all and a good C++ compiler should prove the theory correct. Due to some limitations, however, the current JIT compiler is unable to perform certain related optimizations, which can cause the code to run a bit slower than you would expect. This will be addressed in a future version of the JIT compiler.
Although operator overloading might not currently be the optimal solution for performance-critical applications, it does increase code readability and reusability. In fact, developers in the scientific community need to write code that is understandable and as close to actual numerical expressions, in terms of notation and syntax, as possible. If you're planning to perform only a handful of arithmetic operations on a custom-defined type, and you're satisfied using cryptic notations, then you can bypass the feature altogether and gain that extra bit of performance. C# gives you a choice, which makes it even more attractive as a language to be used for scientific computing.
Multidimensional Arrays
C# supports three types of arrays: single-dimensional arrays, jagged arrays, and rectangular arrays.
As they are in C, single-dimensional arrays are zero-based (the index of the array's first element is zero) and have elements stored sequentially in memory. These arrays are implicitly manipulated using a special set of MSIL instructions (newarr, ldelem, stelem, and so on) available specifically for this purpose. This makes single-dimensional arrays particularly attractive since the compiler is able to optimize them in a number of ways.
While single-dimensional arrays form part of almost any numerical application, numerical computing without efficient multidimensional arrays is unheard of. Multidimensional arrays in C# come in two flavors: jagged and rectangular.
A jagged array is a single-dimensional array of single-dimensional arrays. It is best to imagine a jagged array as a vertical column with each slot pointing out to another location in memory where some single-dimensional array is stored. Given that single-dimensional arrays are optimized in C# down to the MSIL level, it makes sense that an array of single-dimensional arrays would be extremely efficient. However, this depends almost entirely on how the array is accessed. If the accessing code exhibits poor locality, the cost of jumping about in memory chasing pointers could dominate the execution time. Another benefit (or problem, depending on your criteria) with jagged arrays is that its rows can be of varied lengths, hence the term jagged. This results in multiple bound checks every time a new row is accessed. In the current runtime, however, jagged array indexing is better optimized and inlined than rectangular array access.
Realizing some of the shortcomings of jagged arrays, C# designers decided to include C-like multidimensional arrays in the language specification, intending to target performance-critical applications and users who simply prefer rectangular arrays over jagged arrays. Unlike jagged arrays, a rectangular array is stored in contiguous memory locations and is not scattered about the heap. Unfortunately, rectangular arrays don't have their own set of MSIL instructions and instead a pair of set/get helper methods is used for accessing array elements. These helper methods do not incur any runtime overhead (at least for two- and three-dimensional arrays) as the JIT compiler treats them as intrinsic. In effect, the code is generated inline with a number of optimizations, such as eliminating bound checks and potentially using a single offset.
There is a minor limitation in the current JIT compiler regarding the graceful elimination of bound checks on rectangular arrays, hence accessing a relatively small two-dimensional jagged array sequentially (row-by-row) might be quicker than accessing a two-dimensional rectangular array on some machines. The same will not be true for larger array sizes as jagged arrays will lose more time in fetching random elements from different locations in memory. You can approximate that the performance of a jagged array is inversely proportional to the number of elements accessed when not walking linearly through each row.
Jagged arrays perform miserably in cases when elements are accessed diagonally or randomly because of their poor locality. Rectangular arrays, on the other hand, seem to perform four to five times better than jagged arrays in such scenarios. The code in Figure 4 uses performance counters to profile four different loops that test sequential and diagonal access on a large jagged and a large rectangular array.
Figure 4 Benchmarking Sequential and Diagonal Access
using System; namespace PerfCounter { /// <summary> /// The class provides a "stop watch" for applications /// requiring accurate timing measurements/// </summary> public class Counter { [System.Runtime.InteropServices.DllImport("KERNEL32")] private static extern bool QueryPerformanceCounter(reflong lpPerformanceCount); [System.Runtime.InteropServices.DllImport("KERNEL32")] private static extern bool QueryPerformanceFrequency(ref longlpFrequency); long totalCount = 0; long startCount = 0; long stopCount = 0; long freq = 0; public void Start() { startCount = 0;QueryPerformanceCounter(ref startCount); } public void Stop() { stopCount = 0; QueryPerformanceCounter(ref stopCount); totalCount += stopCount -startCount; } public void Reset() { totalCount = 0; } public float TotalSeconds { get { freq = 0; QueryPerformanceFrequency(ref freq); return((float) totalCount/ (float) freq); } } public double MFlops(double total_flops) { return (total_flops / (1e6 * TotalSeconds)); } public override string ToString() { returnString.Format("{0:F3} seconds", TotalSeconds); } } } using System; using PerfCounter; namespace BenchArrays { /// <summary> /// Test sequential anddiagonal access on jagged and /// rectangular arrays /// </summary> class TestArrays { [STAThread] static void Main(string[] args) { int loopCounter =1000; int dim = 1000; double temp; // Declare a jagged two-dimensional array double[][] arrJagged = new double[dim][]; // Declare a rectangular two-dimensional array double[,] arrRect = new double[dim, dim]; /* Instantiateand Initialize Arrays */ for (int i=0; i<arrJagged.Length; i++) { arrJagged[i] = newdouble[dim]; for (int j=0; j<arrJagged[i].Length; j++) { arrJagged[i][j] = arrRect[i, j] = i*j; } } Counter counter = new Counter(); // LOOP 1 // Measuresequential access for rectangular array counter.Reset(); counter.Start(); Console.WriteLine("Starting loop 1..."); for(int i=0; i<loopCounter; i++) { for(int j=0;j<dim; j++) { for(int k=0; k<dim; k++) { temp = arrRect[j, k]; } } } counter.Stop(); Console.WriteLine("Time for rect sequential access: {0}", counter);Console.WriteLine(); // LOOP 2 // Measure diagonal access for rectangular array Console.WriteLine("Starting loop 2..."); counter.Reset(); counter.Start();for(int i=0; i<loopCounter; i++) { for(int j=0; j<dim; j++) { for(int k=0; k<dim; k++) { temp = arrRect[k, k]; } } } counter.Stop(); Console.WriteLine("Time forrect diagonal access: {0}", counter); Console.WriteLine(); // LOOP 3 // Measure sequential access for jagged array counter.Reset(); counter.Start();Console.WriteLine("Starting loop 3..."); for(int i=0; i<loopCounter; i++) { for(int j=0; j<arrJagged.Length; j++) { for(int k=0; k<arrJagged[j].Length; k++) {temp = arrJagged[j][k]; } } } counter.Stop(); Console.WriteLine("Time for jagged sequential access: {0}", counter); Console.WriteLine(); // LOOP 4 //Measure diagonal access for jagged array counter.Reset(); counter.Start(); Console.WriteLine("Starting loop 4..."); for(int i=0; i<loopCounter; i++) { for(intj=0; j<arrJagged.Length; j++) { for(int k=0; k<arrJagged[j].Length; k++) { temp = arrJagged[k][k]; } } } counter.Stop(); Console.WriteLine("Time for jaggeddiagonal access: {0}", counter); Console.WriteLine("End Of Benchmark."); Console.ReadLine(); } } }
Figure 5 shows the result obtained from running the benchmark in Figure 4. As you can see, sequentially accessing a relatively large array for both types of arrays gave comparative timings, whereas diagonally accessing the jagged array was approximately eight times slower than the rectangular array.
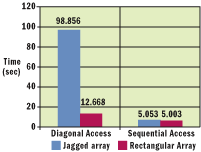
Figure 5** Sequential and Diagonal Access **
Although rectangular arrays are generally superior to jagged arrays in terms of structure and performance, there might be some cases where jagged arrays provide an optimal solution. If your application does not require arrays to be sorted, rearranged, partitioned, sparse, or large, then you might find jagged arrays to perform quite well. Note, however, that while this proposition might work best for most applications, it will not work for library code. You're often not aware of the context in which someone else will use your library code and this could lead to the production of poorly performing systems.
For example, you might write a general Matrix library using jagged arrays and find that it performs terribly in a range of applications involving graphics, image analysis, finite-element analysis, mechanics, data mining, data fitting, and neural networks. This is because you frequently encounter large sparse matrices, where most elements are zeros or not needed, and which therefore need to be accessed in a random fashion.
For such situations, switch to rectangular arrays and your overall performance will improve considerably. As an example, Figure 6 and Figure 7 test the performance of two different implementations of an application that multiplies a couple of large matrices. Each of these applications use the performance counter class that was shown in Figure 4. Figure 6 uses two-dimensional jagged arrays for representing the matrices and Figure 7 uses rectangular arrays. Each application outputs its running time along with the number of MFLOPS achieved. This simple test should show that the code using the rectangular arrays is approximately eight to nine times faster than the equivalent code using the jagged arrays.
Figure 7 Matrix Multiplication Using Rectangular Arrays
using System; using System.Diagnostics; using PerfCounter; namespace BenchRectMatrix { /// <summary> /// Matrix Multiplication using RectangularArrays /// </summary> class MatrixMul { [STAThread] static void Main(string[] args) { int i, n; // Declare rectangular matrices double[,] MatrixA, MatrixB,MatrixC; Random r = new Random(50); n = 1000; MatrixA = new double[n,n]; MatrixB = new double[n,n]; MatrixC = new double[n,n]; /* Initialize toRandom Values */ for (i=0; i<n; i++) { for (int j=0; j<n; j++) { MatrixA[i,j]=(double)r.Next(50); MatrixB[i,j]=(double)r.Next(50); } } Counter counter = newCounter(); /* Call and measure Matdot */ Console.WriteLine("Starting counter..."); counter.Reset(); counter.Start(); Matdot(n, MatrixA, MatrixB, MatrixC); //call // MatDot counter.Stop(); Console.WriteLine("Time taken: {0}", counter); Console.WriteLine("Obtained {0:F2} MFlops", counter.MFlops(2*n*n*n));Console.ReadLine(); } public static void Matdot(int n, double [,]a, double [,]b, double [,]c) { int i,j,k; double tmp; for (i=0; i<n; i++) { for (j=0; j<n; j++) { tmp= c[i,j]; for (k=0; k<n; k++) { tmp += a[i,k] * b[k,j]; } c[i,j]=tmp; } } } } }
Figure 6 Matrix Multiplication Using Jagged Arrays
using System; using System.Diagnostics; using PerfCounter; namespaceBenchJaggedMatrix { /// <summary> /// Matrix Multiplication using Jagged Arrays /// </summary> class MatrixMul { [STAThread] static void Main(string[]args) { int i, n; // Declare jagged matrices double[][] MatrixA, MatrixB, MatrixC; Random r = new Random(50); n = 1000; MatrixA = new double[n][];MatrixB = new double[n][]; MatrixC = new double[n][]; /* Instantiate and Initialize Arrays */ for (i=0; i<MatrixA.Length; i++) { MatrixA[i] = new double[n];MatrixB[i] = new double[n]; MatrixC[i] = new double[n]; for (int j=0; j<MatrixA[i].Length; j++) { MatrixA[i][j]=(double)r.Next(50); MatrixB[i][j]=(double)r.Next(50); } } Counter counter = new Counter(); /* Call and measure Matdot */ Console.WriteLine("Starting counter..."); counter.Reset(); counter.Start();Matdot(MatrixA, MatrixB, MatrixC); // call MatDot counter.Stop(); Console.WriteLine("Time taken: {0}", counter); Console.WriteLine("Obtained {0:F2}MFlops", counter.MFlops(2*n*n*n)); Console.ReadLine(); } public static void Matdot(double [][]a, double [][]b, double [][]c) { int i,j,k; double tmp; for (i=0;i<a.Length; i++) { for (j=0; j<c[i].Length; j++) { tmp = c[i][j]; for (k=0; k<b[i].Length; k++) { tmp += a[i][k]*b[k][j]; } c[i][j]=tmp; } } } } }
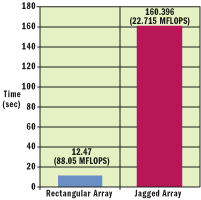
Figure 8** Jagged versus Rectangular Arrays **
Running the two codes on my test machine obtained the results shown in Figure 8. You can get even better results by converting a multidimensional array into a single-dimensional array. If you don't mind the syntax, this can be trivial; just use one index as an offset. For example, the following declares a single-dimensional array to be used as a two-dimensional array:
double[] myArray = new double[ROW_DIM * COLUMN_DIM];
For indexing the elements of this array, use the following offset:
myArray[row * COLUMN_DIM + column];
This will undoubtedly be faster than an equivalent jagged or rectangular array.
If rectangular arrays were not included as a part of the language, it would have been difficult to declare C# as a language suitable for scientific computing. Limitations currently present in the JIT compiler will hopefully be overcome, but as you can see from the results I've just shown, even with these limitations, rectangular arrays are able to perform much better than jagged arrays.
The Unsafe Approach
C# is full of surprises. As a developer with a C/C++ background, I wasn't willing to give up pointers. Surprisingly, C# supports C-style pointers. You might wonder how this is done since the garbage collector moves objects around during a collection and may move an object to which you were pointing. Fortunately, the runtime allows you to work outside the control of the garbage collector by pinning the objects in memory so that they're marked not to be moved during a collection. For array manipulation, this is good news. First, multidimensional rectangular arrays can very easily be accessed linearly as if they were a single-dimensional array. Second, when you access an array element, the runtime performs an array bounds check to make sure you're not accessing memory outside of the array (there are, however, some cases when the JIT can examine the bounds of the access and prove that it doesn't need to do a bounds check on every access). This incurs unwanted overhead in those cases where you're confident about your code.
But there's a catch. Code that uses pointers must be marked as unsafe and can only be run in a fully trusted environment, meaning, for example, that you cannot run this code directly from the Internet. However, this should not affect scientific programmers who intend to run code in a fully trusted environment, unless the intention is to write a network application or one used by the general public.
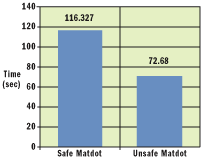
Figure 9** Unsafe Code Performance **
To show how well unsafe code can perform against safe code, Figure 9 shows a benchmark of two matrix multiplication methods; one uses pointers to access individual array elements and one doesn't. Results showed that the unsafe version was approximately twice as fast as the safe version. This improvement would be even more dramatic if the unsafe version used pointer arithmetic to move to the next element in the array, changing the multiplications and additions to more increments.
Language Interoperability
Most developers have spent time and resources building libraries or solutions based on the technologies and languages that preceded the .NET Framework. Although there are many advantages to porting your code to C#, this is not always an option when you already have a foundation of tested code upon which to build. Fortunately, .NET has built-in support for language interoperability thanks to the Common Language Specification (CLS) and Common Type System (CTS). This effectively allows legacy code written in any language to interact with code written in C#, provided the code is CLS-compliant. In effect, your favorite numerical libraries or code written in FORTRAN, for instance, can now be integrated seamlessly into your C# applications. You could even write performance-critical parts of your code in unmanaged C and use it from your managed C# application. The .NET Framework will usually make the transition between managed and unmanaged code look seamless.
This will bring a revolution to scientific development as developers can now simultaneously write code in a number of different languages and then integrate or share code effortlessly.
Benchmarks
The benchmark results I showed earlier were gathered by running the SciMark 2.0 benchmark suite on a 2.4GHz Pentium 4 with 256MB RAM. For the sake of comparison, results were also taken from the C version of SciMark 2.0 and are shown in Figure 10 to give you some idea of how well C# compared.
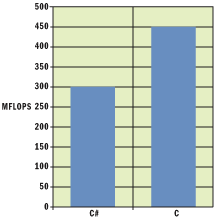
Figure 10** C# versus C Performance **
It should be pointed out that the current C# version of SciMark uses two-dimensional jagged arrays in most of its kernels, such as SOR, Sparse matmul, and LU. This is clearly the reason why C# seems to perform badly against C in these three kernels, and why it performs nearly as well as C in FFT. Perhaps switching to rectangular arrays would reveal a much better picture.
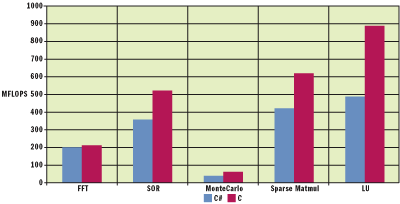
Figure 11** SciMark Results **
These results are not to be taken as a final indication on performance comparison of the two languages. Since SciMark has been directly translated to C# from Java, the implementation makes use of some not-so-optimal features of C# which could be further improved by including alternative features, such as structs, rectangular arrays, and even unsafe code blocks, to give a better comparison to C. Figure 11 shows the composite scores of all the results.
Conclusion
While developers have enjoyed C# for developing Internet-based components and distributed applications, little work has been done to investigate C# as a scientific language. In this article, I presented many powerful features present in C# that make the language an ideal platform for deploying scientific code. Although C# currently performs well enough to be recognized fully as a competent scientific language, let's hope that with the next version of the JIT compiler, its performance will be even better.
Fahad Gilani is studying embedded systems, high-performance computing, and memory managers at the Australian National University. Coauthor of several books on .NET published by Wrox Press Ltd, he also works as an independent consultant and a freelance developer. Fahad can be reached at Fahad_Gilani@yahoo.com.