[Editor's Update - 1/20/2006: This article refers to a beta version of Visual Studio 2005. An updated version of the article, reflecting features found in the final release of Visual Studio 2005, can be found at C#: Create Elegant Code With Anonymous Methods, Iterators, And Partial Classes.]
C# 2.0
Create Elegant Code with Anonymous Methods, Iterators, and Partial Classes
Juval Lowy
This article was based on a pre-release version of Microsoft Visual Studio 2005, formerly code-named "Whidbey." All information contained herein is subject to change.
This article discusses:
|
This article uses the following technologies: C# and Visual Studio |
Code download available at:C20.exe(164 KB)
Contents
Iterators
Iterator Implementation
Recursive Iterations
Partial Types
Anonymous Methods
Passing Parameters to Anonymous Methods
Anonymous Method Implementation
Generic Anonymous Methods
Anonymous Method Example
Delegate Inference
Property and Index Visibility
Static Classes
Global Namespace Qualifier
Inline Warning
Conclusion
Fans of the C# language will find much to like in Visual C#® 2005. Visual Studio® 2005 brings a wealth of exciting new features to Visual C# 2005, such as generics, iterators, partial classes, and anonymous methods. While generics is the most talked-about and anticipated feature, especially among C++ developers who are familiar with templates, the other new features are important additions to your Microsoft® .NET development arsenal as well. These features and language additions will improve your overall productivity compared to the first version of C#, leaving you to write cleaner code faster. For some background information on generics, you should take a look at the sidebar "What are Generics?"
Iterators
In C# 1.1, you can iterate over data structures such as arrays and collections using a foreach loop:
string[] cities = {"New York","Paris","London"}; foreach(string city in cities) { Console.WriteLine(city); }
In fact, you can use any custom data collection in the foreach loop, as long as that collection type implements a GetEnumerator method that returns an IEnumerator interface. Usually you do this by implementing the IEnumerable interface:
public interface IEnumerable { IEnumerator GetEnumerator(); } public interface IEnumerator { object Current{get;} bool MoveNext(); void Reset(); }
Often, the class that is used to iterate over a collection by implementing IEnumerable is provided as a nested class of the collection type to be iterated. This iterator type maintains the state of the iteration. A nested class is often better as an enumerator because it has access to all the private members of its containing class. This is, of course, the Iterator design pattern, which shields iterating clients from the actual implementation details of the underlying data structure, enabling the use of the same client-side iteration logic over multiple data structures, as shown in Figure 1.
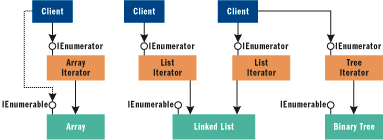
Figure 1** Iterator Design Pattern **
In addition, because each iterator maintains separate iteration state, multiple clients can execute separate concurrent iterations. Data structures such as the Array and the Queue support iteration out of the box by implementing IEnumerable. The code generated in the foreach loop simply obtains an IEnumerator object by calling the class's GetEnumerator method and uses it in a while loop to iterate over the collection by continually calling its MoveNext method and current property. You can use IEnumerator directly (without resorting to a foreach statement) if you need explicit iteration over the collection.
But there are some problems with this approach. The first is that if the collection contains value types, obtaining the items requires boxing and unboxing them because IEnumerator.Current returns an Object. This results in potential performance degradation and increased pressure on the managed heap. Even if the collection contains reference types, you still incur the penalty of the down-casting from Object. While unfamiliar to most developers, in C# 1.0 you can actually implement the iterator pattern for each loop without implementing IEnumerator or IEnumerable. The compiler will choose to call the strongly typed version, avoiding the casting and boxing. The result is that even in version 1.0 it's possible not to incur the performance penalty.
To better formulate this solution and to make it easier to implement, the Microsoft .NET Framework 2.0 defines the generic, type-safe IEnumerable<ItemType> and IEnumerator<ItemType> interfaces in the System.Collections.Generics namespace:
public interface IEnumerable<ItemType> { IEnumerator<ItemType> GetEnumerator(); } public interface IEnumerator<ItemType> : IDisposable { ItemType Current{get;} bool MoveNext(); }
Besides making use of generics, the new interfaces are slightly different than their predecessors. Unlike IEnumerator, IEnumerator<ItemType> derives from IDisposable and does not have a Reset method. The code in Figure 2 shows a simple city collection implementing IEnumerable<string>, and Figure 3 shows how the compiler uses that interface when spanning the code of the foreach loop. The implementation in Figure 2 uses a nested class called MyEnumerator, which accepts as a construction parameter a reference back to the collection to be enumerated. MyEnumerator is intimately aware of the implementation details of the city collection, an array in this example. The MyEnumerator class maintains the current iteration state in the m_Current member variable, which is used as an index into the array.
Figure 3 Simple Iterator
CityCollection cities = new CityCollection(); //For this foreach loop: foreach(string city in cities) { Trace.WriteLine(city); } //The compiler generates this equivalent code: IEnumerable<string> enumerable = cities; IEnumerator<string> enumerator = enumerable.GetEnumerator(); using(enumerator) { while(enumerator.MoveNext()) { Trace.WriteLine(enumerator.Current); } }
Figure 2 Implementing IEnumerable<string>
public class CityCollection : IEnumerable<string> { string[] m_Cities = {"New York","Paris","London"}; public IEnumerator<string> GetEnumerator() { return new MyEnumerator(this); } //Nested class definition class MyEnumerator : IEnumerator<string> { CityCollection m_Collection; int m_Current; public MyEnumerator(CityCollection collection) { m_Collection = collection; m_Current = -1; } public bool MoveNext() { m_Current++; if(m_Current < m_Collection.m_Cities.Length) return true; else return false; } public string Current { get { if(m_Current == -1) throw new InvalidOperationException(); return m_Collection.m_Cities[m_Current]; } } public void Dispose(){} } }
The second and more difficult problem is implementing the iterator. Although that implementation is straightforward for simple cases (as shown in Figure 3), it is challenging with more advanced data structures, such as binary trees, which require recursive traversal and maintaining iteration state through the recursion. Moreover, if you require various iteration options, such as head-to-tail and tail-to-head on a linked list, the code for the linked list will be bloated with various iterator implementations. This is exactly the problem that C# 2.0 iterators were designed to address. Using iterators, you can have the C# compiler generate the implementation of IEnumerator for you. The C# compiler can automatically generate a nested class to maintain the iteration state. You can use iterators on a generic collection or on a type-specific collection. All you need to do is tell the compiler what to yield in each iteration. As with manually providing an iterator, you need to expose a GetEnumerator method, typically by implementing IEnumerable or IEnumerable<ItemType>.
You tell the compiler what to yield using the new C# yield return statement. For example, here is how you use C# iterators in the city collection instead of the manual implementation of Figure 2:
public class CityCollection : IEnumerable<string> { string[] m_Cities = {"New York","Paris","London"}; public IEnumerator<string> GetEnumerator() { for(int i = 0; i<m_Cities.Length; i++) yield return m_Cities[i]; } }
You can also use C# iterators on non-generic collections:
public class CityCollection : IEnumerable { string[] m_Cities = {"New York","Paris","London"}; public IEnumerator GetEnumerator() { for(int i = 0; i<m_Cities.Length; i++) yield return m_Cities[i]; } }
In addition, you can use C# iterators on fully generic collections, as shown in Figure 4. When using a generic collection and iterators, the specific type used for IEnumerable<ItemType> in the foreach loop is known to the compiler from the type used when declaring the collection—a string in this case:
LinkedList<int,string> list = new LinkedList<int,string>(); /* Some initialization of list, then */ foreach(string item in list) { Trace.WriteLine(item); }
This is similar to any other derivation from a generic interface.
Figure 4 Providing Iterators on a Generic Linked List
//K is the key, T is the data item class Node<K,T> { public K Key; public T Item; public Node<K,T> NextNode; } public class LinkedList<K,T> : IEnumerable<T> { Node<K,T> m_Head; public IEnumerator<T> GetEnumerator() { Node<K,T> current = m_Head; while(current != null) { yield return current.Item; current = current.NextNode; } } /* More methods and members */ }
If for some reason you want to stop the iteration midstream, use the yield break statement. For example, the following iterator will only yield the values 1, 2, and 3:
public IEnumerator<int> GetEnumerator() { for(int i = 1;i< 5;i++) { yield return i; if(i > 2) yield break; } }
Your collection can easily expose multiple iterators, each used to traverse the collection differently. For example, to traverse the CityCollection class in reverse order, provide a property of type IEnumerable<string> called Reverse:
public class CityCollection { string[] m_Cities = {"New York","Paris","London"}; public IEnumerable<string> Reverse { get { for(int i=m_Cities.Length-1; i>= 0; i--) yield return m_Cities[i]; } } }
Then use the Reverse property in a foreach loop:
CityCollection collection = new CityCollection(); foreach(string city in collection.Reverse) { Trace.WriteLine(city); }
There are some limitations to where and how you can use the yield return statement. A method or a property that has a yield return statement cannot also contain a return statement because that would improperly break the iteration. You cannot use yield return in an anonymous method, nor can you place a yield return statement inside a try statement with a catch block (and also not inside a catch or a finally block).
Iterator Implementation
The compiler-generated nested class maintains the iteration state. When the iterator is first called in a foreach loop (or in direct iteration code), the compiler-generated code for GetEnumerator creates a new iterator object (an instance of the nested class) with a reset state. Every time the foreach loops and calls the iterator's MoveNext method, it begins execution where the previous yield return statement left off. As long as the foreach loop executes, the iterator maintains its state. However, the iterator object (and its state) does not persist across foreach loops. Consequently, it is safe to call foreach again because you will get a new iterator object to start the new iteration. This is why IEnumerable<ItemType> does not define a Reset method.
But how is the nested iterator class implemented and how does it manage its state? The compiler transforms a standard method into a method that is designed to be called multiple times and that uses a simple state machine to resume execution after the previous yield statement. All you have to do is indicate what and when to yield to the compiler using the yield return statement. The compiler is even smart enough to concatenate multiple yield return statements in the order they appear:
public class CityCollection : IEnumerable<string> { public IEnumerator<string> GetEnumerator() { yield return "New York"; yield return "Paris"; yield return "London"; } }
Let's take a look at the GetEnumerator method of the class shown in the following lines of code:
public class MyCollection : IEnumerable<string> { public IEnumerator<string> GetEnumerator() { //Some iteration code that uses yield return } }
When the compiler encounters a class member with a yield return statement such as this, it injects the definition of a nested class called GetEnumerator$<random unique number>__IEnumeratorImpl, as shown in the C# pseudocode in Figure 5. (Remember that all of the features discussed in this article—the names of the compiler-generated classes and fields—are subject to change, in some cases quite drastically. You should not attempt to use reflection to get at those implementation details and expect consistent results.)
Figure 5 The Compiler-generated Iterator
public class MyCollection : IEnumerable<string> { public virtual IEnumerator<string> GetEnumerator() { GetEnumerator$0003__IEnumeratorImpl impl; impl = new GetEnumerator$0003__IEnumeratorImpl; impl.<this> = this; return impl; } private class GetEnumerator$0003__IEnumeratorImpl : IEnumerator<string> { public MyCollection <this>; // Back reference to the collection string $_current; // state machine members go here string IEnumerator<string>.Current { get { return $_current; } } bool IEnumerator<string>.MoveNext() { //State machine management } IDisposable.Dispose() { //State machine cleanup if required } } }
The nested class implements the same IEnumerable interface returned from the class member. The compiler replaces the code in the class member with an instantiation of the nested type, assigning to the nested class's <this> member variable a reference back to the collection, similar to the manual implementation shown in Figure 2. The nested class is actually the one providing the implementation of IEnumerator.
Recursive Iterations
Iterators really shine when it comes to iterating recursively over a data structure such as a binary tree or any complex graph of interconnecting nodes. With recursive iteration, it is very difficult to manually implement an iterator, yet using C# iterators it is done with great ease. Consider the binary tree in Figure 6. The full implementation of the tree is part of the source code available with this article.
Figure 6 Implementing a Recursive Iterator
class Node<T> { public Node<T> LeftNode; public Node<T> RightNode; public T Item; } public class BinaryTree<T> { Node<T> m_Root; public void Add(params T[] items) { foreach(T item in items) Add(item); } public void Add(T item) {...} public IEnumerable<T> InOrder { get { return ScanInOrder(m_Root); } } IEnumerable<T> ScanInOrder(Node<T> root) { if(root.LeftNode != null) { foreach(T item in ScanInOrder(root.LeftNode)) { yield return item; } } yield return root.Item; if(root.RightNode != null) { foreach(T item in ScanInOrder(root.RightNode)) { yield return item; } } } }
The binary tree stores items in nodes. Each node holds a value of the generic type T, called Item. Each node has a reference to a node on the left and a reference to a node on the right. Values smaller than Item are stored in the left-side subtree, and larger values are stored in the right-side subtree. The tree also provides an Add method for adding an open-ended array of values of the type T, using the params qualifier:
public void Add(params T[] items);
The tree provides a public property called InOrder of type IEnumerable<T>. InOrder calls the recursive private helper method ScanInOrder, passing to ScanInOrder the root of the tree. ScanInOrder is defined as:
IEnumerable<T> ScanInOrder(Node<T> root);
It returns the implementation of an iterator of the type IEnumerable<T>, which traverses the binary tree in order. The interesting thing about ScanInOrder is the way it uses recursion to iterate over the tree using a foreach loop that accesses the IEnumerable<T> returned from a recursive call. With in-order iteration, every node iterates over its left-side subtree, then over the value in the node itself, then over the right-side subtree. For that, you need three yield return statements. To iterate over the left-side subtree, ScanInOrder uses a foreach loop over the IEnumerable<T> returned from a recursive call that passes the left-side node as a parameter. Once that foreach loop returns, all the left-side subtree nodes have been iterated over and yielded. ScanInOrder then yields the value of the node passed to it as the root of the iteration and performs another recursive call inside a foreach loop, this time on the right-side subtree.
The InOrder property allows you to write the following foreach loop to iterate over the entire tree:
BinaryTree<int> tree = new BinaryTree<int>(); tree.Add(4,6,2,7,5,3,1); foreach(int num in tree.InOrder) { Trace.WriteLine(num); } // Traces 1,2,3,4,5,6,7
You can implement pre-order and post-order iterations in a similar manner by adding additional properties.
While the ability to use iterators recursively is obviously a powerful feature, it should be used with care as there can be serious performance implications. Each call to ScanInOrder requires an instantiation of the compiler-generated iterator, so recursively iterating over a deep tree could result in a large number of objects being created behind the scenes. In a balanced binary tree, there are approximately n iterator instantiations, where n is the number of nodes in the tree. At any given moment, approximately log(n) of those objects are live. In a decently sized tree, a large number of those objects will make it past the Generation 0 garbage collection. That said, iterators can still be used to easily iterate over recursive data structures such as trees by using stacks or queues to maintain a list of nodes still to be examined.
Partial Types
C# 1.1 requires you to put all the code for a class in a single file. C# 2.0 allows you to split the definition and implementation of a class or a struct across multiple files. You can put one part of a class in one file and another part of the class in a different file, noting the split by using the new partial keyword. For example, you can put the following code in the file MyClass1.cs:
public partial class MyClass { public void Method1() {...} }
In the file MyClass2.cs, you can insert this code:
public partial class MyClass { public void Method2() {...} public int Number; }
In fact, you can have as many parts as you like in any given class. Partial type support is available for classes, structures, and interfaces, but you cannot have a partial enum definition.
Partial types are a very handy feature. Sometimes it is necessary to modify a machine-generated file, such as a Web service client-side wrapper class. However, changes made to the file will be lost if you regenerate the wrapper class. Using a partial class, you can factor those changes into a separate file. ASP.NET 2.0 uses partial classes for the code-beside class (the evolution of codebehind), storing the machine-generated part of the page separately. Windows® Forms uses partial classes to store the visual designer output of the InitializeComponent method as well as the member controls. Partial types also enable two or more developers to work on the same type while both have their files checked out from source control without interfering with each other.
You may be asking yourself, what if the various parts define contradicting aspects of the class? The answer is simple: a class (or a struct) can have two kinds of aspects or qualities: accumulative and non-accumulative. The accumulative aspects are things that each part of the class can choose to add, such as interface derivation, properties, indexers, methods, and member variables.
For example, the following code shows how a part can add interface derivation and implementation:
public partial class MyClass {} public partial class MyClass : IMyInterface { public void Method1() {...} public void Method2() {...} }
The non-accumulative aspects are things that all the parts of a type must agree upon. Whether the type is a class or a struct, type visibility (public or internal) and the base class are non-accumulative aspects. For example, the following code does not compile because not all the parts of MyClass concur on the base class:
public class MyBase {} public class SomeOtherClass {} public partial class MyClass : MyBase {} public partial class MyClass : MyBase {} //Does not compile public partial class MyClass : SomeOtherClass {}
In addition to having all parts define the same non-accumulative parts, only a single part can override a virtual or an abstract method, and only one part can implement an interface member.
C# 2.0 supports partial types as follows: when the compiler builds the assembly, it combines from the various files the parts of a type and compiles them into a single type in Microsoft intermediate language (MSIL). The generated MSIL has no recollection which part came from which file. Just like in C# 1.1 the MSIL has no record of which file was used to define which type. Also worth noting is that partial types cannot span assemblies, and that a type can refuse to have other parts by omitting the partial qualifier from its definition.
Because all the compiler is doing is accumulating parts, a single file can contain multiple parts, even of the same type, although the usefulness of that is questionable.
In C#, developers often name a file after the class it contains and avoid putting multiple classes in the same file. When using partial types, I recommend indicating in the file name that it contains parts of a type such as MyClassP1.cs, MyClassP2.cs, or employing some other consistent way of externally indicating the content of the source file. For example, the Windows Forms designer stores its portion of the partial class for the form in Form1.cs to a file named Form1.Designer.cs.
Another side effect of partial types is that when approaching an unfamiliar code base, the parts of the type you maintain could be spread all over the project files. In such cases, my advice is to use the Visual Studio Class View because it displays an accumulative view of all the parts of the type and allows you to navigate through the various parts by clicking on its members. The navigation bar provides this functionality as well.
Anonymous Methods
C# supports delegates for invoking one or multiple methods. Delegates provide operators and methods for adding and removing target methods, and are used extensively throughout the .NET Framework for events, callbacks, asynchronous calls, and multithreading. However, you are sometimes forced to create a class or a method just for the sake of using a delegate. In such cases, there is no need for multiple targets, and the code involved is often relatively short and simple. Anonymous methods is a new feature in C# 2.0 that lets you define an anonymous (that is, nameless) method called by a delegate.
For example, the following is a conventional SomeMethod method definition and delegate invocation:
class SomeClass { delegate void SomeDelegate(); public void InvokeMethod() { SomeDelegate del = new SomeDelegate(SomeMethod); del(); } void SomeMethod() { MessageBox.Show("Hello"); } }
You can define and implement this with an anonymous method:
class SomeClass { delegate void SomeDelegate(); public void InvokeMethod() { SomeDelegate del = delegate() { MessageBox.Show("Hello"); }; del(); } }
What are Generics?
Generics allow you to define a type-safe data structure or a utility helper class without committing to the actual data types used. This results in a significant performance boost and higher-quality code because you get to reuse data processing algorithms without duplicating type-specific code. For example, instead of defining a linked list in terms of System.Object, you can define it in generic terms, using generic type parameters:
public class LinkedList<T> { T[] m_Items = new T[100]; public void AddHead(T item) {...} public T RemoveHead(T item); {...} }
T is a merely a placeholder for the actual type to be used. When the client declares and instantiates the list, it provides the type to use instead of the generic type parameter:
LinkedList<int> list = new LinkedList<int>(); list.AddHead(3);
You can use multiple type parameters, such as K for the list key and T for the underlying data type stored:
public class LinkedList<K,T> {...}
You can define generic interfaces and have the subclass either provide a particular type or you can keep the subclass generic:
public interface IList<T> {...} public class NumberList : IList<int> {...} public class LinkedList<T> : IList<T> {...}
For additional information about generics, see Jason Clark's .NET columns in the September 2003 and October 2003 issues of MSDN® Magazine. There is also an MSDN whitepaper, "An Introduction to C# Generics," available.
The anonymous method is defined in-line and not as a member method of any class. Additionally, there is no way to apply method attributes to an anonymous method, nor can the anonymous method define generic types or add generic constraints.
You should note two interesting things about anonymous methods: the overloaded use of the delegate reserved keyword and the delegate assignment. You will see later on how the compiler implements an anonymous method, but it is quite clear from looking at the code that the compiler has to infer the type of the delegate used, instantiate a new delegate object of the inferred type, wrap the new delegate around the anonymous method, and assign it to the delegate used in the definition of the anonymous method (del in the previous example).
Anonymous methods can be used anywhere that a delegate type is expected. You can pass an anonymous method into any method that accepts the appropriate delegate type as a parameter:
class SomeClass { delegate void SomeDelegate(); public void SomeMethod() { InvokeDelegate(delegate(){MessageBox.Show("Hello");}); } void InvokeDelegate(SomeDelegate del) { del(); } }
If you need to pass an anonymous method to a method that accepts an abstract Delegate parameter, such as the following
void InvokeDelegate(Delegate del);
first cast the anonymous method to the specific delegate type.
A concrete and useful example for passing an anonymous method as a parameter is launching a new thread without explicitly defining a ThreadStart delegate or a thread method:
public class MyClass { public void LauchThread() { Thread workerThread = new Thread(delegate() { MessageBox.Show("Hello"); }); workerThread.Start(); } }
In the previous example, the anonymous method serves as the thread method, causing the message box to be displayed from the new thread.
Passing Parameters to Anonymous Methods
When defining an anonymous method with parameters, you define the parameter types and names after the delegate keyword just as if it were a conventional method. The method signature must match the definition of the delegate to which it is assigned. When invoking the delegate, you pass the parameter's values, just as with a normal delegate invocation:
class SomeClass { delegate void SomeDelegate(string str); public void InvokeMethod() { SomeDelegate del = delegate(string str) { MessageBox.Show(str); }; del("Hello"); } }
If the anonymous method has no parameters, you can use a pair of empty parens after the delegate keyword:
class SomeClass { delegate void SomeDelegate(); public void InvokeMethod() { SomeDelegate del = delegate() { MessageBox.Show("Hello"); }; del(); } }
However, if you omit the empty parens after the delegate keyword altogether, you are defining a special kind of anonymous method, which could be assigned to any delegate with any signature:
class SomeClass { delegate void SomeDelegate(string str); public void InvokeMethod() { SomeDelegate del = delegate { MessageBox.Show("Hello"); }; del("Parameter is ignored"); } }
Obviously, you can only use this syntax if the anonymous method does not rely on any of the parameters, and you would want to use the method code regardless of the delegate signature. Note that you must still provide arguments when invoking the delegate because the compiler generates nameless parameters for the anonymous method, inferred from the delegate signature, as if you wrote the following (in C# pseudocode):
SomeDelegate del = delegate(string) { MessageBox.Show("Hello"); };
Additionally, anonymous methods without a parameter list cannot be used with delegates that specify out parameters.
An anonymous method can use any class member variable, and it can also use any local variable defined at the scope of its containing method as if it were its own local variable. This is demonstrated in Figure 7. Once you know how to pass parameters to an anonymous method, you can also easily define anonymous event handling, as shown in Figure 8.
Figure 8 Anonymous Method as Event Handler
public class MyForm : Form { Button m_MyButton; public MyForm() { InitializeComponent(); m_MyButton.Click += delegate(object sender,EventArgs args) { MessageBox.Show("Clicked"); }; } void InitializeComponent() {...} }
Figure 7 Local Variable in Anonymous Method Code
class SomeClass { string m_Space = " "; delegate void SomeDelegate(string str); public void InvokeMethod() { string msg = "Hello"; SomeDelegate del = delegate(string name) { MessageBox.Show(msg + m_Space + name); }; del("Juval"); } }
Because the += operator merely concatenates the internal invocation list of one delegate to another, you can use the += to add an anonymous method. Note that with anonymous event handling, you cannot remove the event handling method using the -= operator unless the anonymous method was added as a handler by first storing it to a delegate and then registering that delegate with the event. In that case, the -= operator can be used with the same delegate to unregister the anonymous method as a handler.
Anonymous Method Implementation
The code the compiler generates for anonymous methods largely depends on which type of parameters or variables the anonymous methods uses. For example, does the anonymous method use the local variables of its containing method (called outer variables), or does it use class member variables and method arguments? In each case, the compiler will generate different MSIL. If the anonymous method does not use outer variables (that is, it only uses its own arguments or the class members) then the compiler adds a private method to the class, giving the method a unique name. The name of that method will have the following format:
<return type> __AnonymousMethod$<random unique number>(<params>)
As with other compiler-generated members, this is subject to change and most likely will before the final release. The method signature will be that of the delegate to which it is assigned.
The compiler simply converts the anonymous method definition and assignment into a normal instantiation of the inferred delegate type, wrapping the machine-generated private method:
SomeDelegate del = new SomeDelegate(__AnonymousMethod$00000000);
Interestingly enough, the machine-generated private method does not show up in IntelliSense®, nor can you call it explicitly because the dollar sign in its name is an invalid token for a C# method (but a valid MSIL token).
The more challenging scenario is when the anonymous method uses outer variables. In that case, the compiler adds a private nested class with a unique name in the format of:
__LocalsDisplayClass$<random unique number>
The nested class has a back reference to the containing class called <this>, which is a valid MSIL member variable name. The nested class contains public member variables corresponding to every outer variable that the anonymous method uses. The compiler adds to the nested class definition a public method with a unique name, in the format of:
<return type> __AnonymousMethod$<random unique number>(<params>)
The method signature will be that of the delegate to which it is assigned. The compiler replaces the anonymous method definition with code that creates an instance of the nested class and makes the necessary assignments from the outer variables to that instance's member variables. Finally, the compiler creates a new delegate object, wrapping the public method of the nested class instance, and calls that delegate to invoke the method. Figure 9 shows in C# pseudocode the compiler-generated code for the anonymous method definition in Figure 7.
Figure 9 Anonymous Method Code with Outer Variables
class SomeClass { string m_Space = " "; delegate void SomeDelegate(string str); private sealed class __LocalsDisplayClass$00000001 { public SomeClass <this>; //Back pointer, name is valid in MSIL public string msg; //Outer variable public void __AnonymousMethod$00000000(string name) { MessageBox.Show(msg + <this>.m_Space + name); } } public void InvokeMethod() { string msg = "Hello"; __LocalsDisplayClass$00000001 locals; locals = new __LocalsDisplayClass$00000001(); locals.<this> = this; locals.msg = msg; SomeDelegate del = new SomeDelegate(locals.__AnonymousMethod$00000000); del("Juval"); }
Generic Anonymous Methods
An anonymous method can use generic parameter types, just like any other method. It can use generic types defined at the scope of the class, for example:
class SomeClass<T> { delegate void SomeDelegate(T t); public void InvokeMethod(T t) { SomeDelegate del = delegate(T item){...} del(t); } }
Because delegates can define generic parameters, an anonymous method can use generic types defined at the delegate level. You can specify the type to use in the method signature, in which case it has to match the specific type of the delegate to which it is assigned:
class SomeClass { delegate void SomeDelegate<T>(T t); public void InvokeMethod() { SomeDelegate<int> del = delegate(int number) { MessageBox.Show(number.ToString()); }; del(3); } }
Anonymous Method Example
Although at first glance the use of anonymous methods may seem like an alien programming technique, I have found it quite useful because it replaces the need for creating a simple method in cases where only a delegate will suffice. Figure 10 shows a real-life example of the usefulness of anonymous methods—the SafeLabel Windows Forms control.
Figure 10 The SafeLabel Control
public class SafeLabel : Label { delegate void SetString(string text); delegate string GetString(); override public string Text { set { if(InvokeRequired) { SetString setTextDel = delegate(string text) {base.Text = text;}; Invoke(setTextDel,new object[]{value}); } else base.Text = value; } get { if(InvokeRequired) { GetString getTextDel = delegate(){return base.Text;}; return (string)Invoke(getTextDel,null); } else return base.Text; } } }
Windows Forms relies on the underlying Win32® messages. Therefore, it inherits the classic Windows programming requirement that only the thread that created the window can process its messages. Calls on the wrong thread will always trigger an exception under Windows Forms in the .NET Framework 2.0. As a result, when calling a form or a control on a different thread, you must marshal that call to the correct owning thread. Windows Forms has built-in support for solving this predicament by having the Control base class implement the interface ISynchronizeInvoke, defined like the following:
public interface ISynchronizeInvoke { bool InvokeRequired {get;} IAsyncResult BeginInvoke(Delegate method,object[] args); object EndInvoke(IAsyncResult result); object Invoke(Delegate method,object[] args); }
The Invoke method accepts a delegate targeting a method on the owning thread, and it will marshal the call to that thread from the calling thread. Because you may not always know whether you are actually executing on the correct thread, the InvokeRequired property lets you query to see if calling Invoke is required. The problem is that using ISynchronizeInvoke complicates the programming model significantly, and as a result it is often better to encapsulate the interaction with the ISynchronizeInvoke interface in controls and forms that will automatically use ISynchronizeInvoke as required.
For example, instead of a Label control that exposes a Text property, you can define the SafeLabel control which derives from Label, as shown in Figure 10. SafeLabel overrides its base class Text property. In its get and set, it checks whether Invoke is required. If so, it needs to use a delegate to access the property. That implementation simply calls the base class implementation of the property, but on the correct thread. Because SafeLabel only defines these methods so that they can be called through a delegate, they are good candidates for anonymous methods. SafeLabel passes the delegate, wrapping the anonymous methods to the Invoke method as its safe implementation of the Text property.
Delegate Inference
The C# compiler's ability to infer from an anonymous method assignment which delegate type to instantiate is an important capability. In fact, it enables yet another C# 2.0 feature called delegate inference. Delegate inference allows you to make a direct assignment of a method name to a delegate variable, without wrapping it first with a delegate object. For example, take a look at the following C# 1.1 code:
class SomeClass { delegate void SomeDelegate(); public void InvokeMethod() { SomeDelegate del = new SomeDelegate(SomeMethod); del(); } void SomeMethod() {...} }
Instead of the previous snippet, you can now write:
class SomeClass { delegate void SomeDelegate(); public void InvokeMethod() { SomeDelegate del = SomeMethod; del(); } void SomeMethod() {...} }
When you assign a method name to a delegate, the compiler first infers the delegate's type. Then the compiler verifies that there is a method by that name and that its signature matches that of the inferred delegate type. Finally, the compiler creates a new object of the inferred delegate type, wrapping the method and assigning it to the delegate. The compiler can only infer the delegate type if that type is a specific delegate type—that is, anything other than the abstract type Delegate. Delegate inference is a very useful feature indeed, resulting in concise, elegant code.
I believe that as a matter of routine in C# 2.0, you will use delegate inference rather than the old method of delegate instantiation. For example, here is how you can launch a new thread without explicitly creating a ThreadStart delegate:
public class MyClass { void ThreadMethod() {...} public void LauchThread() { Thread workerThread = new Thread(ThreadMethod); workerThread.Start(); } }
You can use a double stroke of delegate inference when launching an asynchronous call and providing a completion callback method, as shown in Figure 11. There you first assign the method name to invoke asynchronously into a matching delegate. Then call BeginInvoke, providing the completion callback method name instead of a delegate of type AsyncCallback.
Figure 11 Using Delegate Inference
class SomeClass { delegate void SomeDelegate(string str); public void InvokeMethodAsync() { SomeDelegate del = SomeMethod; del.BeginInvoke("Hello",OnAsyncCallBack,null); } void SomeMethod(string str) { MessageBox.Show(str); } void OnAsyncCallBack(IAsyncResult asyncResult) {...} }
Property and Index Visibility
C# 2.0 allows you to specify different visibility for the get and set accessors of a property or an indexer. For example, it is quite common to want to expose the get as public, but the set as protected. To do so, add the protected visibility qualifier to the set keyword. Similarly, you can define the set method of an indexer as protected, (see Figure 12).
Figure 12 Public Get and Protected Set
public class MyClass { public string this[int index] { get { return m_Names[index]; } protected set { m_Names[index] = value; } } string[] m_Names; //Rest of the class }
There are a few stipulations when using property visibility. First, the visibility qualifier you apply on the set or the get can only be a stringent subset of the visibility of the property itself. In other words, if the property is public, then you can specify internal, protected, protected internal, or private. If the property visibility is protected, you cannot make the get or the set public. In addition, you can only specify visibility for the get or the set, but not both.
Static Classes
It is quite common to have classes with only static methods or members (static classes). In such cases there is no point in instantiating objects of these classes. For example, the Monitor class or class factories such as the Activator class in the .NET Framework 1.1 are static classes. Under C# 1.1, if you want to prevent developers from instantiating objects of your class you can provide only a private default constructor. Without any public constructors, no one can instantiate objects of your class:
public class MyClassFactory { private MyClassFactory() {} static public object CreateObject() {...} }
However, it is up to you to enforce the fact that only static members are defined on the class because the C# compiler will still allow you to add instance members, although they could never be used. C# 2.0 adds support for static classes by allowing you to qualify your class as static:
public static class MyClassFactory { static public T CreateObject<T>() {...} }
The C# 2.0 compiler will not allow you to add a non-static member to a static class, and will not allow you to create instances of the static class as if it were an abstract class. In addition, you cannot derive from a static class. It's as if the compiler adds both abstract and sealed to the static class definition. Note that you can define static classes but not static structures, and you can add a static constructor.
Global Namespace Qualifier
It is possible to have a nested namespace with a name that matches some other global namespace. In such cases, the C# 1.1 compiler will have trouble resolving the namespace reference. Consider the following example:
namespace MyApp { namespace System { class MyClass { public void MyMethod() { System.Diagnostics.Trace.WriteLine("It Works!"); } } } }
In C# 1.1, the call to the Trace class would produce a compilation error (without the global namespace qualifier ::). The reason the error would occur is that when the compiler tries to resolve the reference to the System namespace, it uses the immediate containing scope, which contains the System namespace but not the Diagnostics namespace. C# 2.0 allows you to use the global namespace qualifier :: to indicate to the compiler that it should start its search at the global scope. You can apply the :: qualifier to both namespaces and types, as shown in Figure 13.
Figure 13 Using the Global Namespace Qualifier
namespace MyApp { class MyClass { public void MyMethod() { ::MyClass obj = new ::MyClass(); obj.MyMethod(); // Traces "Hello" instead of recursion } } } public class MyClass { public void MyMethod() { Trace.WriteLine("Hello"); } }
Inline Warning
C# 1.1 allows you to disable specific compiler warnings using project settings or by issuing command-line arguments to the compiler. The problem here is that this is a global suppression, and as such suppresses warnings that you still want. C# 2.0 allows you to explicitly suppress and restore compiler warnings using the #pragma warning directive:
// Disable 'field never used' warning #pragma warning disable 169 public class MyClass { int m_Number; } #pragma warning restore 169
Disabling warnings should be generally discouraged in production code. It is intended only for analysis when trying to isolate a problem, or when you lay out the code and would like to get the initial code structure in place without having to polish it up first. In all other cases, avoid suppressing compiler warnings. Note that you cannot programmatically override the project settings, meaning you cannot use the pragma warning directive to restore a warning that is suppressed globally.
Conclusion
The new features in C# 2.0 presented in this article are dedicated solutions, designed to address specific problems while simplifying the overall programming model. If you care about productivity and quality, then you want to have the compiler generate as much of the implementation as possible, reduce repetitive programming tasks, and make the resulting code concise and readable. The new features give you just that, and I believe they are an indication that C# is coming of age, establishing itself as a great tool for the developer who is an expert in .NET.
Juval Lowy is a software architect providing consultation and training on .NET design and migration. He is also the Microsoft Regional Director for the Silicon Valley. His latest book is Programming .NET Components (O'Reilly, 2003). Contact Juval at https://www.idesign.net.