Inside MSDN
Designing URLs for MSDN2
Tim Ewald
Contents
The Brittle URL Problem
Identifying Content
Content Aliases
Revisions and Versions
Locales
Alternates
Using Content in More Than One Context
So, How Does It Work?
This is the first installment of a new column about MSDN® projects: what we're doing, how we're doing it, and what we're learning along the way. It will be written by MSDN staff with the goal of sharing the team's experiences in solving the real-world business problems MSDN faces. This first installment introduces the URL model we implemented in the alpha release of the MSDN/TechNet Publishing System (MTPS), the new online infrastructure we launched in September 2004 to support MSDN2 (msdn2.microsoft.com). And as you're reading, keep in mind that because the technology discussed here is the alpha release of MSDN2 and the MTPS system behind it; it describes the functionality and implementation as of this writing. Things may change before the final version ships. If so, this column may revisit this topic in the future. Now, onto URLs!
It's easy to take URLs for granted. When you create ASP.NET pages, they get URLs intrinsically, based on their location on disk. For a small site, especially on an intranet, that's a very reasonable approach. But for a large site or one that's accessible on the Internet, how your URLs work is a key design aspect of your system. How will you support versions and translations of content? Can the same content appear in more than one place in your site? Or can the same content appear in multiple sites? What will happen to your URLs if you restructure the way you store the data your site exposes? What will happen if you change your implementation technology? Most importantly, how can you keep your customer's links to your content stable over time?
The Brittle URL Problem
One of the leading causes of dissatisfaction among the users of the MSDN Library online is that every so often, a lot of URLs break. This is such a problem that the 404 handling page is one of the most common entry points for visitors arriving at MSDN. On the surface, this seems like a simple problem to solve. After all, how hard can it be to keep links to a collection of documents—even a really big collection— stable over time? The answer, it turns out, is that it can be very hard, as you'll come to understand once you learn how the existing MSDN Library is built.
Here's how it goes. MSDN is responsible for publishing technical documentation for a wide range of products and technologies. The user education (UE) teams working on those products produce documentation in a format intended for installation directly on a user's machine. These documentation sets (or docsets) are a combination of HTML and XML packaged together in a single binary (either a .chm or .hxs file). Those files are consumed by the HTML Help Viewer, which renders topics locally.
The current MSDN Library is built by deconstructing those packaged help files, spreading the content out on disk, massaging it a bit, and building a site on top. The location of the topics on disk is derived from their location within the docset file that they came from. That location on disk is also reflected in the MSDN Library URL. Sometimes, a UE team decides to restructure the layout of the files in a docset. When that docset is given to MSDN and the Library is rebuilt, the URLs for topics change. Part of the Library build process updates internal links for consistency. External links from other sites or products to MSDN, however, can break.
Brittle URLs is one of the problems we set out to solve 18 months ago when we started to build a new online infrastructure that's now known as the MSDN/TechNet Publishing System. There were other goals, too, like publishing XML instead of HTML and making sure we could expose content in more than one context, for example in both the Library and a Developer Center. We developed a model that worked for MSDN and also met the needs of our content contributors. The first site to use the new system is the MSDN2 Library, which contains prerelease documentation for Visual Studio® 2005.
Identifying Content
The crux of the brittle URL problem is that topics in most UE docsets do not have unique identifiers that remain stable over time. Topics are only identified by path within a docset and, as I mentioned, those paths change from release to release. Solving this problem would require every topic to be assigned a unique ID at the point of origin. We chose to use a GUID which, once assigned to a topic, remains stable. If a topic's GUID ever changes, then it's really a new topic. The old topic remains, with the old GUID. (Some topics already have locally unique identifiers that remain stable over a period of time. In that case, the local ID is mapped to a GUID when the content is published.)
GUIDs are a natural choice for identifying content but they aren't a great thing to include in URLs if you ever expect people to transcribe them. MSDN URLs often appear in magazines and books. Readers often type them in. If our URLs contained GUIDs, the chance of a typo would be high and the chance of finding the error, low. To that end, we opted to assign each GUID a corresponding short ID. The short ID is an eight-character alphanumeric string. It's meaningless, but it's easier to type. Here is an example of a URL that uses a short ID: https://msdn2.microsoft.com/library/b8a5e1s5.aspx.
Short IDs are the preferred format for our new URLs, but there are others. It is legal to use the GUID associated with a topic as well. The two values are treated as synonyms. The mapping between the values is unique and bidirectional and it never changes. Also, the .aspx extension is optional. In other words, this URL is equivalent to the previous one: https://msdn2.microsoft.com/library/b8a5e1s5.
Some people wonder why we bother with the .aspx extension, as it ties us to a particular technology. Others wonder why we aren't using ASP.NET when we tell them they should (we are using ASP.NET, but without the .aspx it might appear as though we're not). To make both groups happy, we chose to use the .aspx extension, but you can leave it off if you feel like it. If you do leave it off, the system will add it for you via redirection.
Content Aliases
One limitation of short IDs is that while they are easy to transcribe, they're impossible to infer. This is okay for a lot of MSDN content because there's nothing you could base your inference on anyway. There are, however, some topics where this is possible, like APIs or error codes. To that end, some topics are also identified by an alias. An alias is a unique text string that is synonymous to a topic's GUID or short ID.
The alpha release of MSDN2 contains the Visual Studio 2005 documentation. These documents are split into two separate categories: conceptual and managed reference. The managed reference topics have aliases derived from their namespace, type, and member names. For instance, you can access a list of all the types in the System.Xml namespace, an overview for the System.Xml.XmlReader type, and a list of the XmlReader type's members using the following three URLs: https://msdn2.microsoft.com/library/system.xml, https://msdn2.microsoft.com/library/system.xml.xmlreader, https://msdn2.microsoft.com/library/system.xml.xmlreader\_ members.
Ultimately, you'll be able to access individual properties, fields, methods, events, and so forth, but the full implementation has not yet been completed.
This is my favorite MSDN2 feature, and based on feedback in the blogsphere, a lot of other people like it too. It provides the same quick access to API information that you get from the index in the offline help (which is not to say that I wouldn't like to see a real index online too). However, I'm compelled to mention that at the time of this writing, MSDN2 is based on an alpha version of MTPS, and some of the details on content aliasing may change. Since one of the big goals for this project is non-brittle URLs, you should link using short IDs until all the remaining aliasing details are sorted out.
Revisions and Versions
Once topics have identifiers that stay fixed over time, MSDN can provide URLs that don't break. But what happens when those topics are updated? Do they replace the previous copy or do both copies exist side by side. For MTPS-based sites like MSDN2, the answer is that it depends. The system differentiates between revisions and versions. A revision is a minor change to an existing topic, for instance, fixing a typo in a code sample. When a topic is revised, the new revision replaces the existing revision. A version is a major change to an existing topic, for instance, updating it to cover the .NET Framework 2.0 instead of 1.1. When a topic is versioned, the new version is published next to the current version and both remain available.
This leads to an interesting question: if two versions of a topic are published side by side, which one does a URL retrieve when the URL has no version specifier? The answer is the latest version that's available for the given product or technology. If you want a specific version, you can ask for it explicitly by including a version identifier in the URL. Here's an example: https://msdn2.microsoft.com/library/b8a5e1s5 versus >https://msdn2.microsoft.com/library/b8a5e1s5(vs.8).
The first URL is version independent. It will always provide access to the latest version of the topic (the overview for XmlReader). The second URL is version specific. This second URL refers to the Visual Studio 2005 version of the topic. When the next version of Visual Studio (the version after Visual Studio 2005, code-named "Orcas") ships, the first URL will point to the Orcas version of the topic but the second URL would keep pointing to the Visual Studio 2005 version of the topic.
While this isn't currently reflected in the MSDN2 alpha release, ultimately all links across topics in a given docset will include a version identifier so that once you've started browsing between topics in, say, the Visual Studio 2005 docs, you won't silently be moved to topics in the Orcas docs.
By supporting both version-independent and version-dependent URL formats, other sites and tools linking to MSDN2 topics have a lot of control over what version of a topic they're referring to.
Locales
Just as there can be multiple versions of a topic, there may be multiple locales as well. As with versions, multiple locales are published side by side. You can request a particular locale by adding an appropriate identifier to a URL. The following is an example: https://msdn2.microsoft.com/library/b8a5e1s5(fr-FR) and https://msdn2.microsoft.com/library/b8a5e1s5(vs.8, fr-FR). The first link explicitly requests the French/France locale. The second link requests the Visual Studio 2005 content for that same locale.
So what happens if you don't request a particular locale? It depends on the site you go to. The initial release of MSDN2 defaults to U.S. English. Other sites will default to other locales. You can ask explicitly for any locale within any site and it should be displayed, but the navigational elements for the site won't change.
Alternates
In the previous two sections, I described how the MTPS/MSDN2 URL scheme supports multiple side-by-side copies of the same topic, each representing a different version and locale. You can think of a single topic as a two-dimensional sparse array of content, with one dimension representing version and the other locale, as shown in Figure 1.
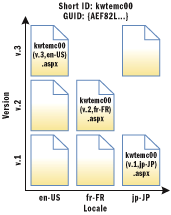
Figure 1** Content in Two Dimensions **
You can index into the array by including version and/or locale identifiers in parenthesis at the end of the URL. The order of these parameters doesn't matter and they can come before or after the .aspx extension if it's present.
You may be wondering, though, what values you're allowed to use. The answer is that it depends, and new values can be added over time. As Figure 1 shows, there is no requirement that every version/locale combination exists. Further, when a new version is added, it's unlikely that all translations to all locales will be done at the same time.
The easiest way to find out what version/locale combinations are legal for a given topic at a particular time is to request a list, called alternates. In theory, you can end a URL with an empty set of parentheses, like this: https://msdn2.microsoft.com/library/b8a5e1s5().
Unfortunately, this isn't implemented at the time of this writing. Instead, you have to pass an invalid parameter; any single letter (which is never a valid version or locale identifier) will do. Here's an example: https://msdn2.microsoft.com/library/b8a5e1s5(x).
If you resolve this URL, you'll get a page containing the following information (with essentially no formatting, but hey, it's only an alpha release):
b8a5e1s5 en VS.8 b8a5e1s5.aspx(VS.8,en)
The table lists all the possible legal combinations of versions and locales for a given topic, along with a hyperlink to each one.
Using Content in More Than One Context
Everything I've talked about so far has focused on the last token in a URL because that's what identifies a piece of content. The rest of the URL path identifies the context within which the content is being viewed. The two are entirely separate and any content can appear anywhere within a context, even in multiple places.
The reason the team designed the MTPS URL scheme this way is to be able to organize and present information in multiple ways, letting users choose the approach that works best for them. It's done that way to some extent today with the current MSDN Library and the various Developer Centers, but the implementation is not as flexible as the team wants it to be. In MTPS, there is no intrinsic link between content and context, making it easy to do a wide array of interesting things. MSDN2 is just the start.
So, How Does It Work?
The alpha version of MTPS and MSDN2 are built on ASP.NET 2.0 and SQL Server™ 2005. The system differentiates between physical content—pages on disk—and virtual data stored in our new XML-based publishing system. Virtual content uses the URL model described earlier. Physical content may or may not. Over time, more and more content will be made virtual, allowing us to use it in multiple contexts and to update it without touching the image of a site or the virtual root on each Web server in our cluster.
Figure 2 shows the complete architecture for the HTTP module, the virtual path provider and the content cache that MTPS uses to expose virtual content within a site like MSDN2. The pieces shown in blue are part of MTPS. Everything else in the figure is part of ASP.NET.
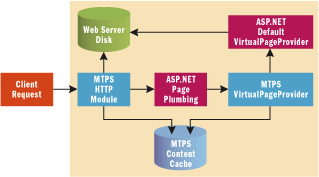
Figure 2** HTTP Module Architecture **
When a request for a page arrives, the HTTP module intercepts it and processes the URL, using logic like that encapsulated in the OnPreResolveRequestCache event handler shown in Figure 3.
Figure 3 OnPreResolveRequestCache
public void OnPreResolveRequestCache(
object o, EventArgs ea)
{
try
{
// check to see if file is virtual (not physical)
// and if it is a page
string ext = this.GetExtension(httpApp.Request.Path);
if (false == File.Exists(httpApp.Request.MapPath(
httpApp.Request.Path)) && (ext == @".aspx" || ext == @".gif"))
{ // it's virtual
// parse off query string
string[] path = httpApp.Request.Path.ToLower().Split('?');
string urlPath = path[0];
// figure out what piece of content set this
// request targets, the main document or an image
this.requestInfo = this.GetDocumentInfo(urlPath);
httpApp.Context.Items[requestInfoContextKey] = this.requestInfo;
// parse out version and locale, applying defaults as needed
string locale, version;
this.GetVersionAndLocale(HttpContext.Current.Request,
out locale, out version);
string identifier = this.GetIdentifier(
this.requestInfo.Type, urlPath);
// encapsulate key information from URL
ReadOnlyContentKey requestKey =
new ReadOnlyContentKey(identifier, locale, version);
// resolve requested key against content cache
// and store result in context
this.contentSet = DbContentLoader.CreateContentSet(
true, this.connectionString, requestKey);
httpApp.Context.Items[contentSetContextKey] = this.contentSet;
// if key didn't identify anything, 404, otherwise
// remap request to normalized virtual path
if (this.contentSet == null)
{
httpApp.Context.AddError(new HttpException(404,
"File not Found", new ApplicationException(
"invalid content identifier")));
}
else
{
string newPath = this.GetVirtualPath(
this.contentSet.Key, this.requestInfo);
httpApp.Context.RewritePath(newPath);
}
}
}
catch (Exception e)
{
// log error with EIF and propagate,
EifEvent.Error(Source.MpsDelivery, e,
@"ContentModule::OnPreResolveRequestCache");
throw;
}
}
The first thing OnPreResolveRequestCache does is check to see if the requested URL targets a page or an image that does not exist on disk. If it does not, then the event handler does nothing and the request is processed using normal ASP.NET techniques. If the handler determines that the URL targets a virtual page or image, it breaks the URL apart and pulls out several pieces of information. First, it determines what the URL targets, the text content associated with a topic or an image associated with a topic. It encapsulates that target information in a DocumentInfo object, which it stores in HTTP context for later use.
Then it looks for version and locale information, applying defaults as necessary, and pulls out the content identifier—a GUID, short ID, or alias. Finally, it combines the version, locale, and content identifier into a ReadOnlyContentKey.
After the URL parsing is complete, the OnPreResolveRequestCache event handler uses the DbContentLoader class, which encapsulates access to the content cache, to create a ContentSet object from the key it built from the URL. It stores the value in HTTP context for later use. If the value is null, there is no topic in the content cache with the requested content identifier. In this case, the handler raises an exception signaling a 404. If the value is non-null, there is a topic in the content cache with the requested content identifier. In this case, the URL path is rewritten to point to a normalized path and processing continues. This level of indirection is what allows every content ID to be used with any URL path, making it appear that all topics exist everywhere.
The normalized path points to a file that does not exist on disk. Rather, the page data is stored in the content cache. The system uses a VirtualPathProvider (VPP) to bridge the gap between the two. In essence, a VPP intercepts all of the ASP.NET plumbing's requests for file streams and gives you a chance to load them from wherever you like. Every ASP.NET app uses a default VPP that simply maps to the file system. An MTPS-based site registers a custom VirtualPathProvider, which sits in front of the default VPP, forming a chain. The custom VPP uses the DocumentInfo and ContentSet objects that the HTTP module's OnPreResolveRequestCache event handler stored in HTTP context to load a topic from the content cache and return it as an .aspx file stream.
It's important to note that the MTPS VPP gets called for every file request, even for pages that exist physically on disk. In that case, it simply delegates the request down the chain to the default path provider that's built into ASP.NET. Whichever path the request takes—whether the custom VPP loads content from the cache or delegates to the built-in VPP that reads files from the file system—the rest of the ASP.NET plumbing doesn't care; it treats all returned file streams the same way. It's completely unaware that the custom VPP materializes some pages on demand.
This implementation is likely to change in future versions of the MTPS plumbing. The VPP code is pretty complicated. The MSDN team went with that model because it made it possible to transform content being retrieved from the cache before the ASP.NET page compiler processed it. That let us convert XHTML markup elements in the cached topic to server-side control tags, in essence injecting site-specific behavior into a page before any other processing occurs. Another approach is to map all virtual paths to a single page that knows how to load content and convert markup elements to controls during the page rendering process. We had a version of that working, but moved away from it to explore the VPP option. It may prove simpler to go back.
This initial Inside MSDN column describes the alpha release of MSDN2 and the MTPS system behind it. I've described the existing functionality and implementation as of the time of this writing. Hopefully, the ideas and design I've discussed here will help you when you are developing similar functionality in your own Web sites and content libraries.
Send your questions and comments to insdmsdn@microsoft.com.
Tim Ewald is a developer at Mindreef, where he writes tools to help developers build Web services systems successfully. He was recently a Program Manager Lead at MSDN, where he designed MTPS, the XML-based publishing system at the center of the next generation of MSDN online infrastructure.