C++ Rules
Power Your App with the Programming Model and Compiler Optimizations of Visual C++
Kang Su Gatlin
Parts of this article are based on a prerelease version of Visual Studio, formerly code-named "Whidbey." All information pertaining to this Beta is subject to change.
This article discusses:
|
This article uses the following technologies: C++, Visual Studio |
Contents
Optimized MSIL
JIT and Compiler Optimization Interaction
Common Subexpression Elimination and Algebraic Simplification
Whole Program Optimization
64-bit NGEN Optimizations
Double Thunk Elimination
C++ Interop
Native and Managed Code in a Single Image
High-Performance Marshaling
Templates and STL with .NET Types
Determinism Helps Performance
Delay Loading
Why dllexport is Not Always a Good Idea
Conclusion
While there is no question that the Microsoft® .NET Framework improves developer productivity, many people have some concern regarding the performance of managed code. The new version of Visual C++® will allow you to set aside these fears. For Visual Studio® 2005, the C++ syntax itself has been greatly improved to make it faster to write. In addition, a flexible language framework is provided for interacting with the common language runtime (CLR) to write high-performance programs.
Many programmers think that C++ gets good performance because it generates native code, but even if your code is completely managed you'll still get superior performance. With its flexible programming model, C++ doesn't tie you to procedural programming, object-oriented programming, generative programming, or meta-programming.
Another common misconception is that the same kind of superior performance on the .NET Framework can be attained regardless of the language you use—that the generated Microsoft intermediate language (MSIL) from various compilers is inherently equal. Even in Visual Studio .NET 2003 this was not true, but in Visual Studio 2005, the C++ compiler team went to great lengths to make sure that all of the expertise gained from years of optimizing native code was applied to managed code optimization. C++ gives you the flexibility to do fine tuning such as high-performance marshaling that is not possible with other languages. Moreover, the Visual C++ compiler generates the best optimized MSIL of any of the .NET languages. The result is that the best optimized code in .NET comes from the Visual C++ compiler.
Optimized MSIL
In the .NET environment, there are two distinct parts to compilation. The first part entails a programmer compiling and optimizing with the language compiler (C#, Visual Basic®, or Visual C++) to generate MSIL. The second part involves the MSIL being fed to the just-in-time (JIT) compiler or NGEN, which reads the MSIL and then generates optimized native machine code. Obviously, the language compiler and JIT are intertwined components, which means that to generate good code, they must cooperate.
Visual C++ has always offered the most advanced set of optimizations of any compiler. This has not changed in managed code. This is apparent even in Visual C++ .NET 2003, which just began enabling the optimizations from the native compiler for MSIL code generation.
With Visual C++ 2005, the compiler can perform a large subset of the standard native code optimizations on MSIL code. These include everything from dataflow-based optimizations to expression optimization to loop unrolling. This level of optimization is unmatched in any other language on the platform. In Visual C++ .NET 2003, Whole Program Optimization (WPO) was not supported for builds using the /clr switch, but Visual C++ 2005 adds this capability for managed code. This feature enables cross-module optimization, which I'll discuss later in the article.
The only class of optimizations not available for managed code in Visual C++ 2005 are Profile Guided Optimizations, although they may be available in a future version. For more information, see Write Faster Code with the Modern Language Features of Visual C++ 2005.
JIT and Compiler Optimization Interaction
The optimized code that Visual C++ generates is fed to the JIT or NGEN to generate native code. Whether the code generated by the Visual C++ compiler is MSIL or unmanaged code, the optimizer that generates the code is the same one that has been developed and tuned for over a decade.
The optimizations done on MSIL code are a large subset of those done on unmanaged code. It's worth pointing out that the class of allowable optimizations is different depending on whether the compiler is generating verifiable code (/clr:safe) or unverifiable code (/clr or /clr:pure). A few examples of the types of things that the compiler can not do because of either metadata or verifiability constraints include strength reduction (to convert multiplications into pointer addition), and inlining the access of private members of one class into the method body of another class.
After the MSIL code is generated by the Visual C++ compiler, it is then consumed by the JIT. The JIT reads in the MSIL and begins to perform optimizations that are very sensitive to changes in the MSIL. One instruction sequence of MSIL might be very amenable to optimization, whereas another (semantically equivalent) sequence stifles optimization. For example, register allocation is an optimization in which the JIT optimizer attempts to map variables to registers; registers are what the actual hardware uses as operands to perform arithmetic and logical operations. At times, semantically equivalent code, written in two different ways, might cause the optimizer to have a more difficult time performing good register allocation. Loop unrolling is an example of a transformation that might cause the JIT to have problems register-allocating.
Loop unrolling done by the C++ compiler can expose more instruction-level parallelism, but can also create more live variables that the optimizer needs to track for register allocation. The CLR JIT can only track a fixed number of variables for register allocation; once it has to track more than this, it begins to spill the contents of registers into memory.
For this reason, the Visual C++ compiler and the JIT must be tuned in tandem to generate the best code. The Visual C++ compiler is responsible for those optimizations that are too time-consuming for the JIT and those for which too much information would be lost in the compilation process from C++ source to MSIL.
Let's look now at some Visual C++ optimizations on managed code.
Common Subexpression Elimination and Algebraic Simplification
Common subexpression elimination (CSE) and algebraic simplification are two powerful optimizations that allow the compiler to perform some basic optimization at an expression level so that the developer can focus on algorithms and architecture.
The following shows a snippet of code compiled as C# and as C++ respectively; both were compiled with Release configurations. The variables a, b, and c were copied from an array passed as a parameter to the function containing the code:
int d = a + b * c; int e = (c * b) * 12 + a + (a + b * c);
Figure 1 shows the MSIL generated from this code by the C# compiler and the C++ compiler, both with optimizations enabled. C# requires 19 instructions versus 13 for C++. Also, you can see that the C++ code has been able to do a CSE on the expression b*c. The optimizer has been able to do algebraic simplification on a+a, instead generating 2*a, and on (c*b)*12 + c*b, instead generating (c*b)*13. I find this latter CSE especially cool, as I've seen real programmers miss this sort of algebraic simplification in real code. See the sidebar "C# Compiler Optimizations".
Figure 1 Compiled Code Snippet
MSIL generated by the C# compiler
// a is in local 0, b is in local 1, c is in // local 2 1: ldloc.0 2: ldloc.1 3: ldloc.2 4: mul 5: add 6: stloc.3 7: ldloc.2 8: ldloc.1 9: mul 10: ldc.i4.s 12 11: mul 12: ldloc.0 13: add 14: ldloc.0 15: ldloc.1 16: ldloc.2 17: mul 18: add 19: add
MSIL generated by the C++ compiler
// a is in local 1, b is in local 2, c is on the // top of the stack but c is not in a local. 1: ldloc.2 // b, c 2: mul // b*c 3: stloc.0 4: ldloc.0 // b*c 5: ldloc.1 // a, b*c 6: add // a+b*c 7: ldloc.1 // a, a+b*c 8: ldc.i4.2 // 2, a, a+b*c 9: mul // 2*a, a+b*c 10: ldloc.0 // b*c, 2*a, a+b*c 11: ldc.i4.s 13 // 13, b*c, 2*a, a+b*c 12: mul // 13*b*c, 2*a, a+b*c 13: add // 13*b*c+2*a, a+b*c
Whole Program Optimization
WPO was added to unmanaged code in Visual C++ .NET. With Visual C++ 2005, this feature extends to managed code. Instead of compiling and optimizing one source file at a time, you compile and optimize across all of the source and header files at once.
The compiler can now perform analysis and optimization across multiple source files. Without WPO, for example, the compiler can only inline functions within a single compiland. With WPO, the compiler can inline functions from any source file in the program.
In the following example, the compiler can do things such as inlining and constant propagation across compilands, as well other types of interprocedural optimizations:
// Main.cpp ... MSDNClass ^MSDNObj = gcnew MSDNClass; int x = MSDNObj->Square(42); return x; ... // MSDNClass.cpp int MSDNClass::Square(int x) { return x*x; }
In this example, Main.cpp calls the method Square, which is part of the MSDNClass in another source file. When compiled with /O2 optimizations, but without whole program optimization, the resulting MSIL in Main.cpp looks like the following:
ldc.i4.s 42 call instance int32 MSDNClass::Square(int32)
You can see that the value 42 is loaded onto the stack and then the Square function is called. In contrast, here is the generated MSIL when the same program was compiled with whole program optimization turned on:
ldc.i4 0x6e4
There is no load of 42 and no call to the Square function. Instead, with Whole Program Optimization, the compiler was able to inline the function from MSDNClass.cpp and do constant propagation. The end result is simply one instruction that loads the result of 42*42, which in hex is 0x6e4.
While some of the analysis and optimization that is performed by the Visual C++ compiler is theoretically also possible with a JIT compiler, the time constraints that are imposed on a JIT compiler makes many of the optimizations mentioned here currently impractical to implement. In general, NGEN will get these types of optimizations before the JIT compiler does, because NGEN does not have the same type of response time restrictions that the JIT compiler has to contend with.
64-bit NGEN Optimizations
For the purposes of this article, I've referred to the JIT and NGEN together as the JIT. With the 32-bit version of the CLR, both the JIT compiler and NGEN perform the same optimizations. This is not the case for the 64-bit version, where NGEN does significantly more optimization than the JIT.
The 64-bit NGEN takes advantage of the fact that it can spend a lot more time compiling than a JIT can since the throughput of the JIT directly affects the response time of the application. I specifically mention the 64-bit NGEN in this article as it has been relatively well-tuned to work with C++-style code and it does some optimizations that greatly help C++, such as the Double Thunk Elimination optimization, which other JITs and NGENs do not do. The 32-bit JIT and the 64-bit JIT were implemented by two different teams within Microsoft using two different code bases. The 32-bit JIT was developed by the CLR team, whereas the 64-bit JIT was developed by the Visual C++ team and is based on the Visual C++ code base. Because the 64-bit JIT was developed by the C++ team, it is more aware of C++-related issues.
Double Thunk Elimination
One of the most important optimizations that the 64-bit NGEN performs is known as double thunk elimination. This optimization addresses a transition that happens when calling a managed entry point from managed code, through a function pointer or virtual call in C++ code compiled with the /clr switch. (This does not happen in /clr:pure or /clr:safe compiled code.) This transition occurs because neither the function pointer nor the virtual call have the necessary information at the callsite to determine if they're calling into a managed entry point (MEP) or an unmanaged entry point (UEP).
For backwards compatibility, the UEP is always selected. But what if the managed callsite is actually calling a managed method? In this case, there would be a thunk that goes from the UEP to the target managed method, in addition to the initial thunk from the managed callsite to the UEP. This managed-to-managed thunk process is what is commonly referred to as the double thunk.
64-bit NGEN optimizes this by realizing that the call to the "unmanaged to managed" is exactly that—a call that thunks back to managed code. There is a check that determines if this is the case; if so, it skips both thunks and jumps directly to the managed code, as shown in Figure 2. This saves many instructions and on real-world code-modeled benchmarks I've seen a factor of 5-10 ¥ improvement (on contrived tests I've seen over 100 ¥ performance improvement).
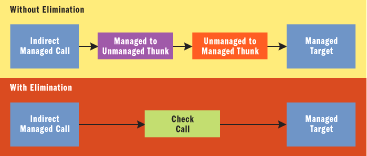
Figure 2** Double Thunk Elimination **
One thing that is worth noting, though, is that this optimization only kicks in when in the default application domain. A good rule of thumb is to remember that the default AppDomain will usually give better performance.C# Compiler Optimizations and Mike Montwill
The C# compiler contains a minimal set of optimizations to improve the generated MSIL. They can be turned on by specifying the /o+ flag on the command line passed to csc.exe or by the Optimize Code flag in the Build section of the Project Properties page in Visual Studio. When you turn on this option, you get a somewhat streamlined intermediate language instruction stream, which hopefully executes faster but is at the same time somewhat more difficult to debug.
The most obvious optimization is the removal of unused local variables. "Unused" means something very specific here. Basically, a local variable is unused if it is never read from in reachable code. Here's an example:
{ int a = foo(123); return; Console.WriteLine(a); }
If you try to debug a program containing this fragment after compiling with optimizations, the debugger will not be aware of the existence of the local variable, and the IL stream will contain the call to foo followed immediately by a POP instruction and the return sequence.
Another set of optimizations performed are best termed goto optimizations. They don't just apply to explicit goto statements you find in your code, but rather to IL branch instructions that are generated by the compiler, most frequently as a result of control flow statements such as if, switch, do, and while. Take for example, the following program fragment:
if (b < 20) { Console.WriteLine("true"); } else { goto After; } After:;
This would normally generate the following IL:
IL_0003: ldloc.0 // b is stored at location 0 IL_0004: ldc.i4.s 20 IL_0006: bge.s IL_0014 IL_0008: ldstr "true" IL_000d: call void [mscorlib]System.Console::WriteLine(string) IL_0012: br.s IL_0016 IL_0014: br.s IL_0016 IL_0016: ret
But when optimizations are applied, you get:
IL_0003: ldloc.0 // b is stored at location 0 IL_0004: ldc.i4.s 20 IL_0006: bge.s IL_0012 IL_0008: ldstr "true" IL_000d: call void [mscorlib]System.Console::WriteLine(string) IL_0012: ret
What basically happens is that branch instructions whose target is another (unconditional) branch instruction are retargeted to that second branch's target. Also, branches to the next instruction are eliminated.
The third kind of optimizations is somewhat more complicated. The following shows an example:
if (!a) { goto C; } Console.WriteLine(3); C: Console.WriteLine(2);
This compiles to:
IL_0002: ldloc.0 // a is stored at location 0 IL_0003: brtrue.s IL_0007 IL_0005: br.s IL_000d IL_0007: ldc.i4.3 IL_0008: call void [mscorlib]System.Console::WriteLine(int32) IL_000d: ldc.i4.2 IL_000e: call void [mscorlib]System.Console::WriteLine(int32)
But with optimizations, it turns into:
IL_0002: ldloc.0 // a is stored at location 0 IL_0003: brfalse.s IL_000b IL_0005: ldc.i4.3 IL_0006: call void [mscorlib]System.Console::WriteLine(int32) IL_000b: ldc.i4.2 IL_000c: call void [mscorlib]System.Console::WriteLine(int32)
What happens here is that a conditional branch around an unconditional branch is reversed and retargeted to point at the target of the unconditional branch.
The next set of optimizations to perform are Try block optimizations. They are as follows:
- A Try/Catch with no code inside of the Try is removed entirely.
- A Try-Finally with no code in the Try is left completely alone. This is because the semantics of code executing in a Finally block and outside of it are different. Asynchronous ThreadAbort exceptions (those thrown by another thread) may interrupt the execution of all code, except for code found in Finally blocks.
- A Try-Finally with an empty Finally block is converted to just the code in the Try block.
- A Try/Catch-Finally is treated just like a Try/Catch nested inside a Try-Finally.
We now reach the category of optimizations that consist of removing IL constructs added to make debugging easier. These transformations are performed by default unless you specifically turn off optimizations, and turning optimizations off causes them not to be performed.
Let's look at return simplification. Normally, a simple return statement is compiled as follows:
IL_0000: ldc.i4.0 IL_0001: stloc.0 IL_0002: br.s IL_0004 IL_0004: ldloc.0 IL_0005: ret
With optimizations on, it becomes much simpler:
IL_0000: ldc.i4.0 IL_0001: ret
The reason for the complicated code in the first case is to associate the return with the closing brace of the method body such that a breakpoint in that location can always be hit at the end of the method.
The second of these optimizations you should consider is nop insertion. The new Visual C#® 2005 compiler will insert nops (the NOP, or no-operation instruction) in specific places to make debugging easier. When compiling with optimizations, these no-operation instructions will not be inserted. The list of possible locations may change before the final release of the product, but here are the possibilities we are currently working on:
- Opening and closing braces of a block
- The beginning of the foreach statement
- After every call and property store statement
- Other places, not normally visible to the user, but needed to generate IL that is compatible with Edit and Continue
The end effect of these extra instructions should be to make stepping under the debugger more useful and predictable.
The list of optimizations performed by the C# compiler itself is really short. We currently depend on the JIT compiler or NGEN to perform the classical optimizations such as common subexpression elimination or method inlining. The set of our optimizations consists of only those that could be performed with a minimum of effort and those that would be expected to cause no large performance impact. After all, it makes a lot more sense to invest in a really smart JIT compiler that can be applied to intermediate language generated by all the various language compilers. Also, my comments should not be construed as advice regarding which language constructs to prefer and which to avoid for any imaginary performance reasons. Code should be written first and foremost for clarity and then the hotspots should be optimized until performance targets are met.
C++ Interop
C++ interop is a technology for managed-native interop that allows standard C++ code compiled with the /clr switch to call native functions directly, without the programmer having to add any additional code. The code generated when using the /clr switch is MSIL (except for some rare exceptions), and the data can be managed or unmanaged (the user specifies where the data should go). I like to refer to C++ interop as the most important .NET feature that no one knows about. It's really borderline revolutionary, but it takes a while to realize exactly how much power C++ interop gives you.
In other .NET-compliant languages, doing interop with native code requires you to place the native code in a DLL and call the function with an explicit P/Invoke using dllimport (or something similar, depending on the language you are using). Otherwise the heavyweight COM interop must be used to access native code. This clearly is not as convenient, and often suffers from much worse performance than C++.
C++ interop is not typically thought of as a performance feature of the C++ language, but as you'll see, the flexibility and convenience offered by C++ interop allows you to get higher performance by targeting the CLR.
Native and Managed Code in a Single Image
Visual C++ gives the programmer the ability to selectively choose, on a function-by-function basis, which functions are managed and which are native. This is done with #pragma managed and #pragma unmanaged, an example of which is shown in Figure 3. In many computationally intensive tasks, it may make sense to have the core functions compiled native, while the rest of the code is compiled managed. C++ can mix, in a single image, both managed and native code, and calling managed functions from native functions (and vice-versa) requires no special syntax. With this degree of granularity, C++ makes it easy to control transitions for managed to native code, and vice versa.
Figure 3 Using #pragma unmanaged
// The pragmas used here are enabled with /clr #pragma unmanaged int ComputeForces(Particles x) { // Computational intensive code, well suited for native } #pragma managed int UpdateAndRender() { // Code to setup variables while(true) { // Calling native code from managed. Notice how it // looks just like calling any other function. ComputeForces(particleList); // Code to render particles } }
When transitioning from managed to native code (or vice versa), the flow of execution goes through a compiler/linker-generated thunk. This thunk has a cost that programmers would obviously like to avoid. There was a lot of work done in the CLR and compilers to minimize the cost of this transition, but developers can also assist by minimizing the frequency of such transitions.
In part A of Figure 4, there is a C++ application where part of the code (Z.cpp) is compiled to generate MSIL (/clr) and the other parts (X.cpp and Y.cpp) are compiled to generate native code. In this program, there are functions in Y.cpp and Z.cpp that make many calls back and forth. This causes a lot of managed/native transitions, which can slow down program execution.
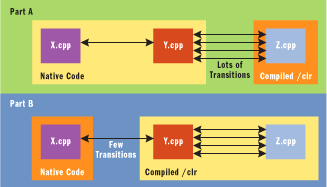
Figure 4** Changing Managed Boundaries **
Part B of Figure 4 shows how you could optimize this program to minimize the managed/native transitions. The idea here is to identify the chatty interfaces and move them all to one side of the managed/native boundary, thereby eliminating all transitions across the chatty interface. Using the facilities that Visual C++ provides for interop, this is a simple task.
For example, to go from A to B in Figure 4, you only need to recompile Y.cpp with the /clr switch. Y.cpp is now compiled to managed code and calls from Z.cpp no longer incur the managed-to-native transition cost. Of course, you also need to consider the performance cost associated with Y.cpp being MSIL, and ensure that this is the right tradeoff for the application.
High-Performance Marshaling
Marshaling is one of the most costly aspects of managed/native interop. With languages such as C# and Visual Basic .NET, the marshaling is done implicitly by the CLR when P/Invoke is invoked (either using the default marshaler or with custom marshaling code when implementing ICustomMarshaler). With C++ interop, the programmer explicitly marshals data in her code wherever she deems appropriate. The great thing about this is that the programmer can marshal data once to native data, and then reuse the result of this marshaling of data over several calls, thereby amortizing the cost of marshaling.
Figure 5 shows a snippet that is compiled with the /clr switch. In this code there is a for-loop where a native function (GetChar) is called. In Figure 6, the same code is implemented in C# and the call to GetChar results in the CSharpType class being marshaled to a NativeType, as shown in the following:
class NATIVECODE_API NativeType { public: NativeType(); int pos; int length; char *theString; };
In C++, the user explicitly uses a native type, thus not requiring the implicit marshaling. The cost savings for this type of optimization can be quite large. In this example, the C++ implementation was about 18 times faster than the C# implementation.
Figure 6 Functionally Equivalent C# Code
using System; using System.Runtime.InteropServices; [StructLayout(LayoutKind.Sequential, CharSet=CharSet.Ansi)] public class CSharpType { public int pos; public int length; public String str; public CSharpType() { pos = 0; str = "TheStartingString"; length = str.Length; } }; class MarshalExample { [DllImport("NativeCode.dll", CallingConvention=CallingConvention.Cdecl, EntryPoint = "?GetChar@@YAHPAVNativeType@@@Z")] extern static public int GetChar( [In, MarshalAs(UnmanagedType.LPStruct)]CSharpType theData); [DllImport("Kernel32.dll")] private static extern bool QueryPerformanceCounter( out long lpPerformanceCount); [DllImport("Kernel32.dll")] private static extern bool QueryPerformanceFrequency( out long lpFrequency); public static void Main() { long start, stop, freq; CSharpType theCSharpData = new CSharpType(); char theChar = ' '; QueryPerformanceFrequency(out freq); QueryPerformanceCounter(out start); for (int i = 0; i < 1000000; ++i) { theCSharpData.pos = i % theCSharpData.length; theChar = (char)GetChar(theCSharpData); } QueryPerformanceCounter(out stop); double time = (double)(stop - start) / (double)freq; Console.WriteLine(theChar); Console.WriteLine("{0}", time); } }
Figure 5 Optimizing Marshaling Costs with Native C++ Types
#include "stdafx.h" #include <windows.h> #include "NativeCode.h" using namespace System; using namespace System::Runtime::InteropServices; public ref class CppType { public: int pos; int length; String ^str; CppType() { pos = 0; str = gcnew String("TheStartingString"); length = str->Length; } }; int main() { LARGE_INTEGER start, stop, freq; NativeType *theNativeData = new NativeType; CppType ^theCppData = gcnew CppType; char theChar = ' '; QueryPerformanceFrequency(&freq); QueryPerformanceCounter(&start); // We copy the data from the managed type to the // native type theNativeData->pos = theCppData->pos; theNativeData->length = theCppData->length; theNativeData->theString = (char*)(void*)Marshal::StringToHGlobalAnsi(theCppData->str); for (int i = 0; i < 1000000; ++i) { theNativeData->pos = i % theNativeData->length; theChar = (char)GetChar(theNativeData); } QueryPerformanceCounter(&stop); double time = (double)(stop.LowPart - start.LowPart) / (double)freq.LowPart; Console::WriteLine("{0}", theChar); Console::WriteLine("{0}", time); }
Templates and STL with .NET Types
Some of the more interesting new performance features in Visual C++ 2005 are templates with managed types (including STL/CLI), whole-program optimization with managed code, delay loading, and deterministic finalization. Visual C++ .NET 2003 is able to generate MSIL for templates on native types, but cannot use managed types as the parameterized type in the template. In Visual C++ 2005, this has been rectified, and now templates can have managed or unmanaged types as parameters. The incredible usefulness of templates now becomes available to code written within .NET (you should also make a point of seeing the work done by the Blitz++ and Boost libraries).
The C++ Standard Template Library (STL) was one of the great innovations in library design. It proved that you can get great abstractions with containers and algorithms without a performance hit. In Visual C++ .NET 2003, the restriction on managed types in templates meant that there was no counterpart of the STL for managed types. With this restriction lifted in Visual C++ 2005, STL/CLI, a verifiable version of the STL which works with managed types, was also introduced. The base class library (BCL) in .NET originally brought containers to .NET, but the plan in the Visual C++ group is that the performance of STL/CLI will be superior. If you want more info on STL/CLI, there is an excellent article by Stan Lippman in the Visual C++ Developer Center, available at STL.NET Primer.
With STL/CLI, you get implementations of all your favorites from STL, including vectors, lists, deques, maps, sets, and hash maps and sets. You also get algorithms for sorting, searching, set operations, inner_products, and accumulate. One of the surprising things about the STL/CLI algorithms is that the same implementation is used for native and the STL/CLI version. The good design of STL will benefit every C++ programmer in the form of portable and powerful code.
Determinism Helps Performance
It's easier to write efficient C++ thanks to the great library of patterns and idioms at your disposal. Many of these, including Resource Acquisition Is Initialization (RAII), use a feature of the C++ language that is known as deterministic finalization. This is the principle whereby the destructor of an object is invoked when the object is either deleted by the delete operator (for heap allocated objects) or goes out of scope (for stack allocated objects). Deterministic finalization aids performance because the longer an object holds a resource (beyond what is absolutely necessary), the more performance will be degraded as other objects try to acquire the same resource.
Using a CLR finalizer results in the finalizer code being executed at some point after the object is out of scope (assuming that the code to release the lock is the finalizer), but not until the finalization thread is invoked on the object's finalizer. Clearly, this is not ideal because the finalization thread may not execute when the programmer expects. Additionally, the memory associated with the object is not garbage collected until after the finalizer is executed, which can increase the memory demands on the program.
One of the common idioms used to help avoid this problem in .NET-based code is the Dispose pattern. To use it, the developer implements a Dispose method for their class, which he then calls when the object is no longer needed. This is called at the same point in code when a C++ programmer would invoke delete on an object, but even in C++ this is error prone and overly verbose. Languages such as C# have added the "using" construct, which helps the latter two problems, but again for nontrivial cases it is complex and error prone.
In contrast, the C++ idiom of RAII automatically acquires and releases resources and is less error prone as the programmer needn't write any additional code. In Visual C++ .NET 2003, deterministic finalization of stack-allocated .NET objects was not supported, but in Visual C++ 2005 this is a supported feature.
In of the top half of Figure 7, notice that the objects of type Socket_t use stack-based syntax and will have stack-based cleanup semantics. So, what if an exception is thrown on the third line? With the stack-based semantics, the destructor is run for mainSock deterministically, but since backupSock has not been created on the stack yet, there is no object to destruct.
Figure 7 Deterministic Finalization
C++
int CheckPort(int p) { Socket_t mainSock(p); // constructor run if(mainSock.Check()) return 1; Socket_t backupSock(p+1); // constructor run if(backupSock.Check()) return 2; return 0; }
C#
int CheckPort(int p) { using(Socket_t mainSock = new Socket_t(p)) { if(mainSock.Check()) return 1; using(Socket_t backupSock = new Socket_t(p+1)) { if(backupSock.Check()) return 2; } } return 0; }
To write code that is semantically equivalent in C# would be a bit more tedious and error-prone; see the bottom half of Figure 7. Of course, this is a trivial example, but as the complexity of such a task increases, so does the likelihood of mistakes.
Delay Loading
Although the .NET Framework has been tuned for performance, there is a small delay during startup as the CLR loads. In many applications, there may be some code paths and scenarios, especially when retrofitting existing legacy programs with .NET functionality, where there is no managed code. In these situations, your application should not have this associated startup delay. You can solve this problem using an existing feature in Visual C++ known as delay loading of DLLs.
The idea is that you only load a DLL when you actually use something from the DLL. The same concept applies to loading DLLs that are .NET assemblies. By using the linker option /DELAYLOAD:dll, where you specify the .NET assemblies you want to delay load, in addition to delaying the loading of the listed .NET assemblies, you can delay the loading of the CLR (if all of the .NET assemblies are delay loaded). The end result is an application that launches as fast as it did when it was all native, thereby eliminating one of the most common complaints about managed apps.
Why dllexport is Not Always a Good Idea
Using __declspec(dllexport) has its drawbacks. The problem with dllexport occurs when you have two images (DLL or exe) that are both managed, but are exposing functionality via dllexport, rather than via #using. Because dllexport is a native construct, every call across the DLL boundary using __declspec(dllexport) will incur a managed-to-native transition, and then a native-to-managed transition. This won't provide great performance.
The options for correcting this performance issue are limited. There is no simple "switch" that suddenly makes __declspec(dllexport) a construct with no associated thunk going to managed code. The recommended fix is to wrap the exported functionality in a managed type (a ref or value class/struct), which the importer can then access via "#using" on the exporting DLL to directly access the functionality in the exporting DLL. With that change, there are no transitions when calling this managed code from a managed client. This is shown in Figure 8, where part A shows the cost associated with using __declspec(dllexport), and part B shows the optimization resulting from the use of #using and wrapping the functions in .NET types. A potential problem with this approach is that unmanaged importers of the exporting DLL will not be able __declspec(dllimport) the functionality of the DLL. This should be taken into consideration before making this change.
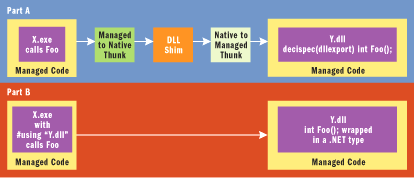
Figure 8** Reducing Thunk Costs **
The A section of Figure 8 shows the transition path of using __declspec(dllexport) to expose managed functions to managed code. In section B, the function is wrapped in a managed type, and #using is used to access the function. The result is a removal of the costly thunks, as compared to the process in section A.
Conclusion
The .NET Framework with Visual C++ has come a long way since its introduction in Visual Studio .NET 2002. C++ gives the programmer unprecedented flexibility to write high-performance managed code, and it does it all in a way that is natural to C++ programmers. There are many languages available for .NET-enabled programming; if you care about maximum performance, Visual C++ is the obvious choice.
Kang Su Gatlin is a Program Manager on the Visual C++ team at Microsoft where he spends most of his day trying to figure out systematic ways to make programs run faster. Prior to his life at Microsoft, he worked on high-performance and grid computing.