No More Hangs
Advanced Techniques To Avoid And Detect Deadlocks In .NET Apps
Joe Duffy
This article discusses:
|
This article uses the following technologies: .NET Framework, C#, C++ |
Code download available at:Deadlocks.exe(188 KB)
Contents
Deadlocks 101
Other Subtle Deadlock Examples
Avoiding Deadlocks with Lock Leveling
Detecting and Breaking Deadlocks
The Algorithms
Spelunking Through the Hosting APIs
Wait Graph Construction and Traversal
Custom Deadlock Host in Action
Wrap-Up
Application hangs are one of the most frustrating situations a user can experience. They're terribly difficult to find before shipping, and even more difficult to debug after an application has been deployed. Unlike a crash, an application hang may not produce a crash dump or trigger custom failure logic. Users frequently shut down a frozen application before such information can be captured, meaning there's no tell-tale stack trace to help you find the source of the problem.
Hangs can range from temporary to permanent. They can result from slow I/O, a computationally expensive algorithm, or mutually exclusive access to resources, in any case reducing the overall responsiveness of an application. Code that blocks a GUI thread's execution can prevent a window from processing incoming user input and system-generated messages, resulting in an app that is "Not Responding." Even non-GUI programs can suffer from responsiveness problems when using shared resources or when performing interthread, interprocess, or intermachine communication. Clearly the worst type of a hang is one that never comes back—in other words, a deadlock.
Engineering large concurrent applications using the standard Windows® shared-memory toolkit of threads and locks is significantly more involved than it might appear at first glance. Forgetting to lock memory in motion can lead to race conditions that lead to crashes at best and corrupt data at worst. There's a trade-off between correctness and sequential performance (coarse granularity of locks) and parallel scalability (fine granularity of locks). Disparate segments of code, each acquiring and releasing locks at varying granularities, tend to interact with each other in unforeseen ways. Assuming your system does nothing to mitigate deadlocks, a subtle misstep here is apt to gum up the complex machinery of your program.
Today's shared memory programming models require that the programmer think about the possible interleaving of instructions throughout program execution. When the unexpected occurs, it can be extremely difficult to replay the steps leading up to the incident. Deadlocks, while more obvious than races (in the simplest case, the program just stops dead in its tracks), are still difficult to locate and eliminate. You may find a small number of them by accident in your ordinary functional test suites, but it's more likely that many will lie dormant in your shipping product, waiting to spring onto an unsuspecting customer. And even when you find the cause, you may have already painted yourself into a corner.
You can combat deadlock using a combination of disciplined locking practices and aggressive stress testing on a range of hardware platforms. The former of these disciplines is the primary topic of this article. But first, let's review the basics of deadlocks.
Deadlocks 101
A deadlock occurs when a set of concurrent workers are waiting on each other to make forward progress before any of them can make forward progress. If this sounds like a paradox, it is. There are four general properties that must hold to produce a deadlock:
Mutual Exclusion When one thread owns some resource, another cannot acquire it. This is the case with most critical sections, but is also the case with GUIs in Windows. Each window is owned by a single thread, which is solely responsible for processing incoming messages; failure to do so leads to lost responsiveness at best, and deadlock in the extreme.
A Thread Holding a Resource is Able to Perform an Unbounded Wait For example, when a thread has entered a critical section, code is ordinarily free to attempt acquisition of additional critical sections while it is held. This typically results in blocking if the target critical section is already held by another thread.
Resources Cannot be Forcibly Taken Away From Their Current Owners In some situations, it is possible to steal resources when contention is noticed, such as in complex database management systems (DBMSs). This is generally not the case for the locking primitives available to managed code on the Windows platform.
A Circular Wait Condition A circular wait occurs if chain of two or more threads is waiting for a resource held by the next member in the chain. Note that for non-reentrant locks, a single thread can cause a deadlock with itself. Most locks are reentrant, eliminating this possibility.
Any programmer who has worked with pessimistic algorithms should already understand how a deadlock occurs. A pessimistic algorithm detects contention when attempting to acquire a shared resource, usually responding by waiting until it becomes available (for example, blocking). Compare this to optimistic algorithms, which will attempt forward progress with the risk that contention will be detected later on, such as when a transaction attempts to commit. Pessimism is generally easier to program and reason about—and is substantially more common on the platform compared to optimistic techniques, usually taking the form of a monitor (a C# lock block or a Visual Basic® SyncLock block), a mutex, or a Win32® CRITICAL_SECTION.
Lock-free or interlocked-based algorithms that can detect and respond to contention are relatively common for systems-level software; these algorithms often avoid entering a critical section altogether in the fast path, choosing to deal with livelock instead of deadlock. Livelock presents a challenge to parallel code too, however, and is caused by fine-grained contention. The result stalls forward progress much like a deadlock. To illustrate the effect of livelock, imagine two people trying to pass each other in a hallway; both move side to side in an attempt to get out of the other's way, but do so in such a way that neither can move forward.
To further illustrate how a deadlock might occur, imagine the following sequence of events:
- Thread 1 acquires lock A.
- Thread 2 acquires lock B.
- Thread 1 attempts to acquire lock B, but it is already held by Thread 2 and thus Thread 1 blocks until B is released.
- Thread 2 attempts to acquire lock A, but it is held by Thread 1 and thus Thread 2 blocks until A is released.
At this point, both threads are blocked and will never wake up. The C# code in Figure 1 demonstrates this situation.
Figure 1 Classic Deadlock
object lockA = new object(); object lockB = new object(); // Thread 1 void t1() { lock (lockA) { lock (lockB) { /* ... */ } } } // Thread 2 void t2() { lock (lockB) { lock (lockA) { /* ... */ } } }
Figure 2 outlines the six possible outcomes should t1 and t2 enter a race condition with each other. In all but two cases (1 and 4), a deadlock occurs. While tempting, you can't conclude that a deadlock will occur 2 out of 3 times (since 4 of the 6 outcomes lead to deadlock), because the tiny windows of time needed to produce 2, 3, 5, or 6 will not occur statistically as frequently as 1 and 4.
Figure 2 Figure 2
| Case | Results |
|---|---|
| 1 | t1 locks A |
| t1 locks B | |
| t2 locks B | |
| t2 locks A | |
2.gif) |
t1 locks A |
| t2 locks B | |
| t2 locks A | |
| t1 locks B | |
| 3 |
t1 locks A |
| t2 locks B | |
| t1 locks B | |
| t2 locks A | |
| 4 | t2 locks B |
| t2 locks A | |
| t1 locks A | |
| t1 locks B | |
| 5 |
t2 locks B |
| t1 locks A | |
| t2 locks A | |
| t1 locks B | |
| 6 |
t2 locks B |
| t1 locks A | |
| t1 locks B | |
| t2 locks A |
Regardless of the statistics, if you write code like this clearly you're balancing your program on a knife's edge. Sooner or later your program is apt to hit one of these four deadlock cases—perhaps due to new hardware your customer has purchased that you never used to test your software, or a context switch between two specific instructions resulting from a high-priority thread becoming runnable—stopping the program in its tracks.
The example just shown is easy to identify, and reasonably easy to fix: Just rewrite t1 and t2 such that they acquire and release locks in a consistent order. That is, write the code such that both t1 and t2 acquire either A followed by B, or vice versa, eliminating the so-called deadly embrace. But consider a more subtle case of a deadlock-prone locking protocol:
void Transfer(Account a, Account b, decimal amount) { lock (a) { lock (b) { if (a.Balance < amount) throw new InsufficientFundsException(); a.Balance -= amount; b.Balance += amount; } } }
If somebody tried transferring, say, $500 from account #1234 to account #5678 at the same time somebody else tried transferring $1,000 from account #5678 to account #1234, a deadlock becomes highly probable. Reference aliasing such as this, where multiple threads refer to the same object using different variables, can cause headaches and is an extraordinarily common practice. Calls to virtual methods implemented in user-code can likewise lead you into a call-stack that dynamically acquires certain locks in unpredictable orders, causing unforeseen combinations of locks held simultaneously by a thread and a real risk of deadlock.
Other Subtle Deadlock Examples
The risk of a deadlock is not limited to mutually exclusive critical sections. There are even subtler ways in which a real deadlock might occur in your program. Soft deadlocks—where an application appears to have deadlocked, but has really just gotten stuck performing a high-latency or contentious operation—are problematic, too. Computation-intensive algorithms that execute on the GUI thread, for example, can lead to a complete loss of responsiveness. In this case, scheduling the work to occur using ThreadPool would have been a better choice (preferably using the new BackgroundWorker component in the .NET Framework 2.0).
Understanding the performance characteristics of each method your program calls is important, but very difficult in practice. An operation that invokes another whose performance characteristics have a wide range can lead to unpredictable latency, blocking, and CPU-intensiveness. The situation gets worse if the caller holds an exclusive lock on a resource when it does so, serializing access to shared resources while some arbitrarily expensive operation takes place. Parts of your application might have great performance in common scenarios, but might change dramatically should some environmental condition arise. Network I/O is a great example: it has moderate-to-high latency on average, but deteriorates significantly when a network connection becomes saturated or unavailable. If you've embedded lots of network I/O in your application, hopefully you've carefully tested how your software works (or doesn't) when you unplug the network cable from your computer.
When your code is executing on a single-threaded apartment (STA) thread, the equivalent of an exclusive lock occurs. Only one thread can update a GUI window or run code inside an Apartment-threaded COM component inside an STA at once. Such threads own a message queue into which to-be-processed information is placed by the system and other parts of the application. GUIs use this queue for information such as repaint requests, device input to be processed, and window close requests. COM proxies use the message queue to transitioning cross-Apartment method calls into the apartment for which a component has affinity. All code running on an STA is responsible for pumping the message queue—looking for and processing new messages using the message loop—otherwise the queue can become clogged, leading to lost responsiveness. In Win32 terms, this means using the MsgWaitForSingleObject, MsgWaitForMultipleObjects (and their Ex counterparts), or CoWaitForMultipleHandles APIs. A non-pumping wait such as WaitForSingleObject or WaitForMultipleObjects (and their Ex counterparts) won't pump incoming messages.
In other words, the STA "lock" can only be released by pumping the message queue. Applications that perform operations whose performance characteristics vary greatly on the GUI thread without pumping for messages, like those noted earlier, can easily deadlock. Well-written programs either schedule such long-running work to occur elsewhere, or pump for messages each time they block to avoid this problem. Thankfully, the CLR pumps for you whenever you block in managed code (via a call to a contentious Monitor.Enter, WaitHandle.WaitOne, FileStream.EndRead, Thread.Join, and so forth), helping to mitigate this problem. But plenty of code—and even some fraction of the .NET Framework itself—ends up blocking in unmanaged code, in which case a pumping wait may or may not have been added by the author of the blocking code.
Here's a classic example of an STA-induced deadlock. A thread running in an STA generates a large quantity of Apartment threaded COM component instances and, implicitly, their corresponding Runtime Callable Wrappers (RCWs). Of course, these RCWs must be finalized by the CLR when they become unreachable, or they will leak. But the CLR's finalizer thread always joins the process's Multithreaded Apartment (MTA), meaning it must use a proxy that transitions to the STA in order to call Release on the RCWs. If the STA isn't pumping to receive the finalizer's attempt to invoke the Finalize method on a given RCW—perhaps because it has chosen to block using a non-pumping wait—the finalizer thread will be stuck. It is blocked until the STA unblocks and pumps. If the STA never pumps, the finalizer thread will never make any progress, and a slow, silent build-up of all finalizable resources will occur over time. This can, in turn, lead to a subsequent out-of-memory crash or a process-recycle in ASP.NET. Clearly, both outcomes are unsatisfactory.
High-level frameworks like Windows Forms, Windows Presentation Foundation, and COM hide much of the complexity of STAs, but they can still fail in unpredictable ways, including deadlocking. COM synchronization contexts introduce similar, but subtly different, challenges. And furthermore, many of these failures will only occur in a small fraction of test runs and often only under high stress.
Different types of deadlocks unfortunately require different techniques to combat. The remainder of the article will focus on critical-section deadlocks exclusively. The CLR 2.0 comes with useful tools for catching and debugging STA transitioning problems. A new Managed Debugging Assistant (MDA), ContextSwitchDeadlock, was created to monitor for deadlocks induced by cross-Apartment transitions. If a transition takes longer than 60 seconds to complete, the CLR assumes the receiving STA is deadlocked and fires this MDA. For further information on enabling this MDA, see the MSDN® documentation.
Two general strategies are useful for dealing with critical-section-based deadlocks.
Avoid Deadlocks Altogether Eliminate one of the aforementioned four conditions. For example, you can enable multiple resources to share the same resource (usually not possible due to thread safety), avoid blocking altogether when you hold locks, or eliminate circular waits, for example. This does require some structured discipline, which can unfortunately add noticeable overhead to authoring concurrent software.
Detect and Mitigate Deadlocks Most database systems employ this technique for user transactions. Detecting a deadlock is straightforward, but responding to them is more difficult. Generally speaking, deadlock detection systems choose a victim and break the deadlock by forcing it to abort and release its locks. Such techiques in arbitrary managed code could lead to instability, so these techniques must be employed with care.
Many developers are aware of the possibility of deadlocks at a theoretical level, but few know how to combat deadlocks in a serious way. We'll take a look at some solutions that fall into both of these categories.
Avoiding Deadlocks with Lock Leveling
A common approach to combating deadlocks in large software systems is a technique called lock leveling (also known as lock hierarchy or lock ordering). This strategy factors all locks into numeric levels, permitting components at specific architectural layers in the system to acquire locks only at lower levels. For example, in the original example, I might assign lock A a level of 10 and lock B a level of 5. It is then legal for a component to acquire A and then B because B's level is lower than A's, but the reverse is strictly illegal. This eliminates the possibility of deadlock. Cleanly factoring your software's architectural dependencies is a broadly accepted engineering discipline.
There are, of course, variants on the fundamental lock leveling idea. I've implemented one such variant in C#, available in the code download for this article. An instance of LeveledLock corresponds to a single shared lock instance, much like an object on which you Enter and Exit via the System.Threading.Monitor class. At instantiation time, a lock is assigned an int-based level:
LeveledLock lockA = new LeveledLock (10); LeveledLock lockB = new LeveledLock (5);
A program would normally declare all of its locks in a central location, for example, using static fields that are accessed by the rest of the program.
The Enter and Exit method implementations call through to an underlying private monitor object. The type also tracks the most recent lock acquisition in Thread Local Storage (TLS) so that it can ensure no locks are procured that would violate the lock hierarchy. You can thus eliminate entirely the chance that somebody will accidentally acquire B and then A (in the wrong order), removing the circular wait possibility and therefore any chance of a deadlock:
// Thread 1 void t1() { using (lockA.Enter()) { using (lockB.Enter()) { /* ... * } } } // Thread 2 void t2() { using (lockB.Enter()) { using (lockA.Enter()) { /* ... */ } } }
Attempting to execute t2 will throw a LockLevelException originating from the lockA.Enter call, indicating that the lock hierarchy was violated. Clearly you should use aggressive testing to find and fix all violations of your lock hierarchy prior to shipping your code. An unhandled exception is still an unsatisfactory experience for users.
Notice that the Enter method returns an IDisposable object, enabling you to use a C# using statement (much like a lock block); it implicitly calls Exit when you leave the scope. There are a couple other options when instantiating a new lock, available through constructor parameters: the reentrant parameter indicates whether the same lock can be reacquired when it is already held, true by default; the name parameter is optional, and enables you to give your lock a name for better debugging.
By default, intra-level locks cannot be acquired; in other words, if you hold lock A at level 10 and attempt to acquire lock C at level 10, the attempt will fail. Permitting this would directly violate the lock hierarchy, because two threads could try to acquire locks in the opposite order (A and the C, versus C and then A). You can override this policy by specifying true for an Enter overload that takes the permitIntraLevel parameter. But once you do this, a deadlock once again becomes possible. Carefully review your code to ensure this explicit violation of the lock hierarchy won't result in a deadlock. But no matter how much work you do here, it will never be as foolproof as the strict lock leveling protocol. Use this feature with extreme caution.
While lock leveling works, it does not come without challenges. Dynamic composition of software components can lead to unexpected runtime failures. If a low-level component holds a lock and makes a virtual method call against a user-supplied object, and that user object then attempts to acquire a lock at a higher level, a lock hierarchy-violation exception will be generated. A deadlock won't occur, but a run-time failure will. This is one reason that making virtual method calls while holding a lock is generally considered a bad practice. Although this is still better than running the risk of a deadlock, this is a primary reason databases do not employ this technique: they must enable entirely dynamic composition of user transactions.
In practice, many software systems end up with clumps of locks at the same level, and you'll find several calls using permitIntraLevel. This rarely occurs, not because the developers have been extremely clever or careful, but rather because lock leveling is a difficult and a relatively onerous practice to follow. It's much easier to knowingly accept the risk of a deadlock or pretend it isn't there—assuming the odds are that it likely won't come up in testing or even in the wild—than it is to spend hours cleanly refactoring code dependencies to make a single lock acquisition work. But disciplined locking, such as minimizing the time a lock is held, only invoking code over which you have static control, and making defensive copies of data when necessary, can be used to make living within the confines of your lock hierarchy simpler.
Many lock-leveling systems are turned off in non-debug builds to avoid the performance penalty of maintaining and inspecting lock levels at run time. But this means you must test your application to uncover all violations of the locking protocol. Dynamic composition makes this incredibly difficult. If you turn off lock leveling when you ship, one missed case can result in a real deadlock. An ideal lock-leveling system would detect and prevent violation of the hierarchy statically through either compiler or static analysis support. There is research available that uses such techniques, but unfortunately there are no mainstream products that can be used for managed applications.Instead of deadlock avoidance, a second technique, deadlock detection, can sometimes be used.
Detecting and Breaking Deadlocks
The techniques discussed so far are useful for avoiding deadlocks entirely. But lots of code is already written that might not lend itself to wholesale adoption of lock leveling. Normally when a deadlock occurs, it will manifest as a hang, which may or may not result in failure information being captured and reported. But ideally, if the system can't avoid them altogether, it would detect a deadlock when it occurred and report it promptly so that the bug can get fixed. This is possible even without adopting lock leveling in your applications.
While all modern databases use deadlock detection, employing the same techniques in arbitrary managed applications is more difficult in practice. When competing database transactions, try to acquire locks in a way that would lead to deadlock, the DBMS can kill the one with the least time and resources invested thus far, enabling all others involved to proceed as though nothing happened. The deadlock victim's operations are automatically rolled back by the DBMS. The application invoking the database call can then respond by either retrying the transaction or giving the user an option for retry, cancellation, or modification of their action. For a ticketing system, for example, a deadlock might mean that a reserved ticket was given to another customer to maintain forward progress, in which case the user might have to restart their ticket reservation transaction.
But a run-of-the-mill managed application that has not been written to deal with deadlock errors resulting from lock acquisitions will likely not be prepared to respond intelligently to an exception originating from an attempted lock acquisition. Crashing the process is just about the only thing you can do.
Managed code hosted in SQL Server™ 2005 enjoys deadlock detection similar to what I'll describe here. Since all managed code is implicitly wrapped in a transaction, this works very well in conjunction with SQL Server's ordinary data-based deadlock detection.
Sophisticated managed code can be written to notice deadlocks, and attempt one-by-one back-off of the locks that it has accumulated. For example, if code holds locks A and B, and receives a deadlock failure when attempting acquisition of C, it can roll back changes introduced since B was acquired, release B, yield execution so other threads can make progress, reacquire B, perform changes previously rolled back, and then attempt the acquisition of C. If that fails again due to deadlock, it can roll all the way back to the acquisition of A and retry.
The CLR's hosting interface can be used to inject custom logic for acquisition and release of monitors. I have used this capability to construct a new sample host to perform deadlock detection and mitigation (which is included in the code download). Now let's take a tour to review this host and demonstrate how deadlock detection might work in practice.
The Algorithms
There are two broadly accepted techniques for deadlock detection: timeout-based detection and graph-based detection.
With timeout-based detection, acquisition of a lock or resource is given a timeout that is much larger than the expected non-deadlock case. If that timeout is exceeded, it indicates failure to the caller. Sometimes failure causes an exception, while other times the function just returns false (like Monitor.TryEnter), which enables the user program to do something about it. The System.Transactions namespace uses this model for TransactionScopes, by default aborting any transaction that has run for 60 seconds or more.
The main drawback with this approach is that a deadlock will typically go undetected for longer than it should, or legit but lengthy transactions will be killed because they appear to be deadlocked. In addition, functions that leave it to the programmer to decide how to respond are error prone; the poor application developer seldom knows the right response, and might just attempt to reacquire the lock (without contemplating whether that might lead to a deadlock-induced infinite loop).
With graph-based detection, if you have a list of workers that are actively waiting and a list of which worker owns what resource, you can construct a graph of who is waiting for whom. If you do this and detect a cycle in the graph, a deadlock has occurred (unless somebody in the cycle is on the timeout plan and might break the deadlock willingly). This is a foolproof strategy, but can be costly in terms of run-time impact to lock acquisitions.
In many cases, a combination of techniques can lead to the best results. If a timeout occurs, you can perform graph-based detection. This avoids expensive detection on the common case, where the acquisition succeeds before the timeout is exceeded. This is what I have implemented.
Before diving into the implementation of the custom host, let's review the algorithm for wait graph construction and deadlock detection. Figure 3 describes this process.
Figure 3 Wait Graph Construction and Deadlock Detection
| 1. | Add the current thread t1 to the list of threads you have seen, called waitGraph. |
| 2. | Set current equal to the lock that t1 is about to acquire. |
| 3. | Set owner equal to the thread that currently owns current. |
| 4. | If owner is null (meaning current is unowned), there is no cycle. Stop looking and exit the procedure. |
| 5. | If owner is in waitGraph, you've seen it already, and thus have encountered a cycle. This is a deadlock. The graph begins at the index of owner in waitGraph and extends to the end. Return information to the caller about waitGraph. |
| 6. | Set current equal to the lock that owner is currently blocked on. |
| 7. | If current is null (meaning current is not blocked waiting on a lock acquisition), there is no cycle; stop looking and exit the procedure. |
| 8. | Otherwise, if you fell through to here, go to Step 3. |
The policy I will use for deadlock breakage (for example, if Step 5 finds a deadlock) is to kill the offending task whose acquisition would have caused the deadlock. This is by far the simplest and least expensive strategy, but isn't as clever as most DBMSs, which attempt to optimize overall system throughput by killing the transaction in the graph with the least amount of work invested. Because measuring work is more difficult for arbitrary managed programs than it is in transaction systems, I have chosen the simpler strategy. (An interesting alternative strategy would be to change the host to use an alternative technique—for instance, using lock-acquisition timestamps to simulate work, terminating the worker that acquired its first lock most recently.)
Let's see how this might work. Imagine three threads, 1, 2, and 3, and three locks, A, B, and C, that are involved in some form of shared-memory coordination. Thread 1 holds lock A and is blocked on acquiring lock B; thread 2 holds lock B and is blocked on acquiring lock C; thread 3 holds lock C. If thread 3 then attempts to acquire lock A, the algorithm kicks in and constructs a wait graph like that depicted in Figure 4. I will then detect a cycle and respond by terminating thread 3. This frees up lock C, which enables thread 2 to unblock, acquire C, execute, and release B. This unblocks thread 1, which is then able to acquire B and execute to completion. Thread 3 is probably not very happy, but threads 1 and 2 are (assuming the program survived the exception).
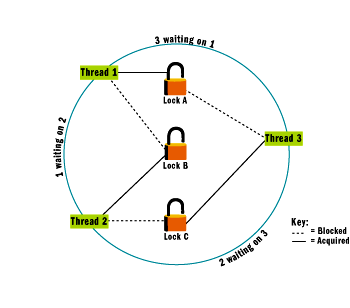
Figure 4** Sample Wait Graph **
Naturally, this discussion has been simplified to help illustrate the core elements of the algorithm. But now let's take a look at how you actually extend the CLR to perform this logic. This will require a few tangents related to harnessing the power of the CLR's hosting APIs.
Spelunking Through the Hosting APIs
The CLR hosting APIs provide ways to plug in your own manager objects to control assembly loading, memory management, thread-pooling, and startup and shutdown, among other things. In this sample, I've used the task and synchronization management extensions. The new host is a simple executable written in Visual C++®, deadhost.exe. When run, you pass to it the path of the managed executable to run with deadlock detection turned on, along with any arguments to that executable. It then starts the CLR in-process using a set of APIs exposed from mscoree.dll, loads the target program, and runs it. Any deadlocks that occur are reported immediately.
In the interest of brevity, I've omitted coverage of many fundamentals. For a complete overview of the CLR's hosting capabilities, I recommend picking up a copy of Steven Pratschner's book, Customizing the Microsoft .NET Framework Common Language Runtime (Microsoft Press®, 2005).
The two host controls implemented are DHTaskManager for the IHostTaskManager interface and DHSyncManager for the IHostSyncManager interface. Instances of these types are returned to the CLR on demand, at which point the CLR will make callbacks into my code for certain events. Of course, I've implemented all of the related interfaces, too: IHostCrst, IHostAutoEvent, IHostManualEvent, IHostSemaphore, and IHostTask. These interfaces are rather large, but most functions are simple translations to Win32 counterparts. Those functions that aren't can be safely ignored (thread-affinity, critical-regions, delay-aborts), and just a few require specialized logic for deadlock detection. I'll review only the latter.
The CLR implements the basic functionality of Monitor.Enter and Exit. For noncontentious lock acquisitions (for monitors without owners), the CLR just does a quick compare-and-swap (InterlockedCompareExchange) on an internal data structure. If this attempt fails, it means contention was detected and a Windows autoreset event is used. This event is then used to wait for lock availability. Whenever somebody releases the lock, they set the event, which has the effect of releasing one waiting thread into the monitor. It is lazily created the first time a specific monitor exhibits contention. The hosting APIs enable you to control the event creation and any calls to wait on or set it. The hosting APIs also support reader-writer locks (System.Threading.ReaderWriterLock), but for space considerations I will omit discussion of them in this article.
Here's precisely what the host needs to do: any time managed code tries to acquire a monitor that is already held by somebody, the CLR calls out to IHostSyncManager::CreateMonitorEvent. This returns an object whose type implements a simple event wait-handle-like interface (IHostAutoEvent, with Wait and Set methods) in which I can place custom detection logic to fire whenever anybody blocks on or releases a monitor. Attempting to acquire a blocked monitor results in a call to Wait, while releasing a monitor calls Set.
Each time the Wait method is called on an event returned by CreateMonitorEvent, I will insert a wait-record into a process-wide list to indicate that the thread is about to block on acquisition of a monitor. This is then used for deadlock detection further on.
I then perform timed waits, starting at 100 ms and backing off exponentially, executing the deadlock detection algorithm each time. Using a timeout first optimizes for the common case where locks are held for short periods of time, avoiding the costly process of wait graph construction and traversal. If a deadlock is ever discovered, I return HOST_E_DEADLOCK (0x80131020) to the CLR, which responds by generating a new COMException with the message "The current thread has been chosen as a deadlock victim." This is new functionality in CLR 2.0, facilitating deadlock detection and breakage in SQL Server 2005. I run the managed program in its own thread so that any such exceptions are able to go entirely unhandled, tripping the attached debugger (if any) on the first pass, crashing the process, and then giving the end user a second chance to attach the debugger. If I successfully acquire the monitor, I just remove the wait-record and return execution to the managed program.
The detection algorithm has been written to impose as little overhead as possible (most of it is lock-free), but there is still some synchronization necessary while accessing shared data structures, such as management of the wait-records. The fast-path occurs when the program doesn't have to execute this logic at all. The best case happens when the CLR can acquire the monitor without having to create an event and call Wait, when the monitor isn't contended, because both operations require costly kernel-mode transitions.
Something else is worth a brief mention. The Windows internal KTHREAD per-thread data structure contains a list of dispatcher objects a given thread is currently waiting on. The data is stored in a _KWAIT_BLOCK data structure, whose definition can be found in Ntddk.h. In Windows XP, the Driver Verifier program uses this to perform detection of deadlocks in device drivers. You too could use this data rather than inserting wait-records, and this would work for both managed and unmanaged code. But doing that requires some messy memory manipulation with internal data structures and an alternate strategy for obtaining current ownership information. It was much simpler for this sample to maintain a custom list of wait-records entirely in user mode. Because of this, I explicitly ignore deadlocks resulting from CLR internal locks, unmanaged and Windows locks, and the OS loader lock, however.
Wait Graph Construction and Traversal
When the CLR hooks our host for anything related to a monitor, it deals in terms of cookies (of type SIZE_T), which are unique identifiers for each monitor. I've created a type called DHContext that is generally responsible for implementing all deadlock-detection-related functionality. An instance of the host shares a processwide context across all managed threads. A context owns a list of wait-records, which associates tasks with the monitor cookies on which they are waiting:
map<IHostTask*, SIZE_T> *m_pLockWaits
The context also offers a set of methods for invoking the deadlock detection itself. TryEnter inserts a wait-record and checks for deadlock, returning a pointer to a DHDetails object if one was found or NULL otherwise; and EndEnter does some maintenance after a monitor has been acquired, such as removing the wait-record. This architecture is depicted in Figure 5.
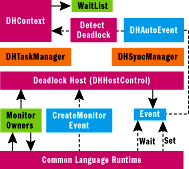
Figure 5** Host Architecture **
When the host needs an event for a contentious monitor, I construct and supply one from the DHSyncManager::CreateMonitorEvent function. I return an object of type DHAutoEvent, a custom implementation of the IHostAutoEvent interface that makes targeted function calls into the context through its field m_pContext of type DHContext. The Wait method (see Figure 6) is the most interesting, executing the first four steps outlined in Figure 3.
Figure 6 Wait Method
STDMETHODIMP Wait(DWORD dwMilliseconds, DWORD option) { DHContext *pctx = m_pContext; if (!pctx || option & WAIT_NOTINDEADLOCK) { return DHContext::HostWait(m_hEvent, dwMilliseconds, option); } else { DWORD dwCurrentTimeout = 100; DWORD dwTotalWait = 0; HRESULT hr; while (TRUE) { if (HOST_E_TIMEOUT != (hr = DHContext::HostWait(m_hEvent, min(dwCurrentTimeout, dwMilliseconds), option))) break; DHDetails *pDetails = pctx->TryEnter(m_cookie); if (pDetails) { pctx->PrintDeadlock(pDetails, m_cookie); hr = HOST_E_DEADLOCK; } else { dwTotalWait += dwCurrentTimeout; if (dwTotalWait >= dwMilliseconds) { hr = HOST_E_TIMEOUT; } else { if (dwTotalWait >= dwMilliseconds / 2) { if (dwMilliseconds != INFINITE) dwCurrentTimeout = dwMilliseconds – dwTotalWait; } else { dwCurrentTimeout *= 2; } continue; } } pctx->EndEnter(m_cookie); break; } return hr; } }
DHContext::HostWait performs a wait based on the flags specified by the CLR in Wait's option argument. This bypasses deadlock detection entirely if WAIT_NOTINDEADLOCK was supplied, and employs a pumping style and/or alertable wait as needed if WAIT_MSGPUMP and /orWAIT_ALERTABLE was specified.
Notice that a large portion of this code is dedicated to managing the exponential back-off timeout. The most interesting part is the call to TryEnter. After inserting the wait-record, it delegates to the internal method DHContext::DetectDeadlock to perform the actual detection logic. If TryEnter returns a non-null value, you've encountered a deadlock. You can respond by calling a custom PrintDetails function to print the deadlock information to the standard error stream (a more robust solution might write this to the Windows Event Log), and then return HOST_E_DEADLOCK so the CLR may react as discussed earlier (by throwing a COMException).
The deadlock detection algorithm outlined earlier in this article is implemented inside of the DetectDeadlock function shown in the code in Figure 7.
Figure 7 DetectDeadlock Method
STDMETHODIMP_(DHDetails*) DHContext::DetectDeadlock(SIZE_T cookie) { ICLRSyncManager *pClrSyncManager = m_pSyncManager->GetCLRSyncManager(); IHostTask* pOwner; m_pTaskManager->GetCurrentTask((IHostTask**)&pOwner); vector<IHostTask*> waitGraph; waitGraph.push_back(pOwner); SIZE_T current = cookie; while (TRUE) { pClrSyncManager->GetMonitorOwner(current, (IHostTask**)&pOwner); if (!pOwner) return FALSE; BOOL bCycleFound = FALSE; vector<IHostTask*>::iterator walker = waitGraph.begin(); while (walker != waitGraph.end()) { if (*walker == pOwner) { bCycleFound = TRUE; break; } walker++; } if (bCycleFound) { DHDetails *pCycle = new DHDetails(); CrstLock lock(m_pCrst); while (walker != waitGraph.end()) { map<IHostTask*, SIZE_T>::iterator waitMatch = m_pLockWaits->find(*walker); waitMatch->first->AddRef(); pCycle->insert(DHDetails::value_type( dynamic_cast<DHTask*>(waitMatch->first), waitMatch->second)); walker++; } lock.Exit(); return pCycle; } waitGraph.push_back(pOwner); CrstLock lock(m_pCrst); map<IHostTask*, SIZE_T>::iterator waitMatch = m_pLockWaits->find(pOwner); if (waitMatch == m_pLockWaits->end()) break; current = waitMatch->second; lock.Exit(); } return NULL; }
This code uses the IHostTaskManager::GetCurrentTask method to obtain the currently executing IHostTask, ICLRSyncManager::GetMonitorOwner to retrieve the owning IHostTask of a given monitor cookie, and the context's m_pLockWaits list to find what monitor on which a given task is waiting for acquisition. With this information in hand, you can fully implement the logic discussed earlier. Any code run through this host will correctly identify and break deadlocks. And that's it—a fully functional deadlock-detecting CLR host.
I've omitted over 1,000 lines of code, of course, so if this gave you the impression that writing a custom CLR host is straightforward, it's not. But the number of possibilities, deadlocks aside, that arise from the powerful CLR hosting interfaces is amazing, ranging from failure injection to testing reliability robustness in the face of rude AppDomain unloads. Deployment of custom hosts to your end users is obviously difficult, but a host can easily be used to perform deadlock detection in your test suites, for example.
Custom Deadlock Host in Action
I developed some simple tests while I was writing deadhost.exe, available in the \tests\ directory in the code download. For example, the program test1.cs shown in Figure 8 will deadlock close to 100 percent of the time.
Figure 8 Trying to Deadlock
static void Main() { Console.WriteLine("Main: locking a"); lock (a) { Console.WriteLine("Main: got a"); ThreadPool.QueueUserWorkItem(delegate { Console.WriteLine("TP : locking b"); lock (b) { Console.WriteLine("TP : got b"); Console.WriteLine("TP : locking a"); lock (a) { Console.WriteLine("TP : got a"); } } }); Thread.Sleep(100); Console.WriteLine("Main: locking b"); lock (b) { Console.WriteLine("Main: got b"); } } }
When run under the host by using the following command line, you will receive an unhandled exception:
deadhost.exe tests\test1.exe
If you break into the debugger (if it's already attached or if you choose to attach it in response to the error), you will be right at the line whose execution would have caused the deadlock, at which point you can inspect all of the threads involved and the locks held, and get a head start on debugging the problem. If left entirely unhandled, you will see a message similar to Figure 9 printed to standard output.
Figure 9 Resulting Output from Unhandled Deadlock
Main: locking a Main: got a TP : locking b TP : got b TP : locking a Main: locking b A deadlock has occurred, terminating the program. Details below. 600 was attempting to acquire 18a27c, which created the cycle 600 waits on lock 18a27c (owned by 5b4) 5b4 waits on lock 18a24c (owned by 600) Unhandled Exception: System.Runtime.InteropServices.COMException (0x80131020): The current thread has been chosen as a deadlock victim. at Program.Main() in c:\...\tests\test1.exe:line 23 at ...
The message printed to the console isn't directly useful in understanding and debugging the error in depth. It gives you the raw thread handles that are waiting and the monitor cookies on which they are waiting. With more time and effort, the host could be extended to gather more data during lock acquisitions and releases, printing details about the object used for the lock and source-code location of acquisitions, for example. But with just the information shown in Figure 8, you can easily see that thread 600 attempted to acquire 18a27c; 5b4 owned 18a27c and was waiting on lock 18a24c; but 18a24c was owned by 600, creating the deadlock cycle. And you can see the stack trace for the guilty deadlock victim. The best part is the ease with which you can enter the debugger and troubleshoot the problem right then and there.
Wrap-Up
In this article I discussed some basic information about deadlocks and presented an overview of strategies for avoiding them and dealing with them. Generally, the finer the granularity of your locks, the more of them that can be held at once—and the longer you hold them for, the higher your risk of deadlock. Increased parallelism on server and desktop computers will only exacerbate and expose this risk as instructions become interleaved in new and interesting ways.
Deadlock avoidance is widely recognized as the best practice for carefully engineered concurrent software, while deadlock detection can be useful for dynamically composed, complex systems, especially those equipped to deal with lock failures (such transacted systems and hosted or plug-in software). Doing something to ensure deadlocks don't plague your applications is better than doing nothing. Hopefully this article will help you to write easier-to-maintain deadlock-free code, improve the responsiveness of your programs, and ultimately save you a fair amount time when debugging concurrency-based failures.
Joe Duffy is a technical program manager on the Microsoft common language runtime (CLR) team, where he works on concurrency programming models for managed code. Joe blogs regularly at www.bluebytesoftware.com/blog and has written an upcoming book, Professional .NET Framework 2.0 (Wrox, 2006).