CLR Inside Out
Base Class Library Performance Tips and Tricks
Kit George
Contents
The Base Class Library
String Concatenation
Parsing Base Types
Collections
Reading from Files
General I/O Tips
Regular Expression Compilation
Local vs. UTC DateTimes
String Comparisons
PerformanceCounter Lifetime
Resource Lookup
Lock-Free Tracing
Conclusion
The common language runtime (CLR) sits at the very heart of managed code. Indeed, it is the heart of managed code, so to understand managed code you need to understand the CLR.
The CLR team continues to develop technologies that improve the Microsoft® .NET Framework and help you make full use of the managed environment. Over the next year, the CLR team will, in this column, provide insights into the core of managed code, share best practices, explain some of the more obscure functionalities, and present personal tips and suggestions. Everything from the String class to just-in-time (JIT) compilation is up for discussion, with each column focusing on a specific functional area of the CLR. Expect the odd foray into more general topics, such as .NET Framework design guidelines, as well.
The Base Class Library
The base class library (BCL) contains such fundamental types that everyone expects them to work under all conditions. Of course, this simply can't be the case. Like any other part of the Framework, BCL types are appropriate in some situations and not in others. This month I'm going to tackle performance tips and tricks for BCL types. While it would be nice to give you some absolute rules, such rules rarely work well for all scenarios. Plus, even if one API has a small performance benefit over another, it often comes at the cost of something else, like code simplicity. Where one style or pattern gives you more control, allowing you to tweak your performance, the other more general pattern requires less code but sacrifices performance. Thus, you shouldn't underestimate the impact of tweaking your use of BCL types. Using them properly can really affect your application speed.
With the introduction of the .NET Framework 2.0 comes generics and a wealth of other new features, including more base types exposing TryParse. If you want to maximize performance, it's a good idea to become familiar with the various patterns and best practices.
String Concatenation
It's well known that StringBuilders are an efficient way to concatenate strings. However, they are not always the best option. I've seen code use StringBuilders for every concatenation operation, and this is certainly not a wise choice.
StringBuilders are most efficient when you're concatenating a lot of strings, when the number of strings is unknown, and when the strings are long. However, if you're only concatenating a few strings or they're relatively short, standard concatenation is often a better choice. For this you can use either your language's chosen concatenation construct or String.Concat; these approaches will provide comparable performance. StringBuilders have associated overhead that standard strings don't have. Plus, at the end of the day, you have to turn the StringBuilder back into a string, which always incurs a cost.
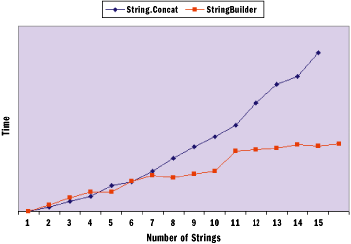
Figure 1** Processing Time with 25-Character Strings **
So, just as with any performance optimization, you should test to see if the changes you're making are worth it. Consider a scenario in which you're appending a variable number of strings, each of which is 25 characters long. The graph in Figure 1 shows the results of a simple test I ran to determine how long it takes to append the specified number of 25-character strings to a StringBuilder and to a string. You'll notice that for this scenario, StringBuilder is clearly better after seven concatenations.
Parsing Base Types
The .NET Framework 2.0 introduces a pattern across all the relevant base types called TryParse, which mimics Parse. The difference in behavior is that Parse will throw an exception when the data check fails, while TryParse simply goes to an else statement.
The code patterns for Parse and TryParse are very similar (see Figure 2). The key thing to note is that if and when the someString value is successfully parsed, the performance is exactly the same for both patterns. Therefore, you're not paying any kind of penalty for using Parse when you have a string you know will be of the type you're parsing into.
Figure 2 Parse vs. TryParse
Parse
Try
Dim i As Integer = Int32.Parse(someString)
' code which deals with the valid integer
Catch fe As FormatException
' code which deals with an invalid input
End Try
TryParse
Dim iVal As Integer
If Int32.TryParse(someString, iVal) Then
' code which deals with the valid integer
Else
' code which deals with an invalid input
End If
Performance takes a hit, however, when you strike a single string that cannot successfully be parsed. In the case of Parse, you'll notice it goes to an exception block. Exceptions are notoriously slow, but this is generally okay because, after all, you're meant to be in an exceptional state (which shouldn't happen frequently)! The point is that for this particular test, it's not really an exceptional state: you're simply checking if this data is like you want it to be. You end up paying a lot in performance for that exceptional case. In contrast, TryParse deals with this scenario through the simple use of an if-else block. There is no performance hit if it has to go to the else block.
TryParse will always perform equal to or better than Parse, and sometimes the performance difference can be dramatic. At its extreme (if every string being parsed cannot be turned into the underlying type making the attempt), Parse can take 150 times longer than TryParse. For example, the first time an exception is caught there's a huge performance hit. After that, cached information speeds things up, but it's still a lot slower. At the other end, if you're parsing 100 strings and only one of those strings won't successfully be parsed, then TryParse is only about 30 percent faster. Only! You may as well use TryParse from now on.
There's a good basic lesson here: make sure you don't use exceptions as a mechanism to detect logic flow. It might seem like a failed parse is an exceptional condition, but it's generally not. After all, you typically parse to find out if a string represents data of a specific type.
Of course, while TryParse is preferable when you need to determine whether a string is another data type, there are still situations where you should use Parse instead. One such occasion is when the parse is not expected to fail, and thus a failed parse is in fact an exceptional condition, and performance is not an issue. The other important case is when you need to distinguish between the reasons for a failed parse, such as an overflow versus a format exception.
In both of these examples, Parse is very appropriate. The FormatException that will result from an invalid Parse indicates that the failed Parse was unexpected and therefore by definition is an exceptional case.
As a historic note for those of you who have observed that Double.TryParse existed in previous versions of .NET, the reason is that the Visual Basic IsNumeric function was using Double.Parse and the Visual Basic team noted that the performance in the failure case was terrible.
Collections
Collections are a fundamental aspect to programming applications in .NET. It's critical to know which collection is best for your scenario. With the introduction of generics, you not only have to decide between conceptually different collections, but you now have two different patterns to choose from: generic and non-generic. It's a hint about what we on the BCL team consider to be the future of collections: there will be little ongoing work and additions in the non-generics collection space, although feedback is always considered.
The good news is that generics are on par with or better than their non-generic counterparts. Take the numbers in Figure 3 as a rough guide. Each of the specified operations was run many times on an ArrayList of Int32, on a List<Int32>, on an ArrayList of String objects, and on a List<String>. The critical differences compared here are a value type (Int32) and a reference type (string) in ArrayList and List<T>, for a variety of operations. The numbers show the relative performance of the generic operation compared to the non-generic operation (a value of 100 would mean they performed identically, a value of 200 would mean the generic version fared twice as well, and a value of 50 would mean the non-generic version was twice as fast as the generic version).
Figure 3 Comparing Generic and Non-Generic Collections
| Method | Relative Performance of List<Int32> Compared to ArrayList (percent) | Relative Performance of List<String> Compared to ArrayList (percent) |
|---|---|---|
| Add | 241.84 | 106.05 |
| Contains | 267.25 | 89.21 |
| ctor(ICollection) | 241.13 | 191.99 |
| Enumeration | 226.19 | 205.21 |
| Indexer | 106.33 | 109.77 |
| IndexOf | 669.42 | 108.52 |
| Insert | 107.89 | 99.71 |
| Remove | 765.85 | 102.20 |
| Sort | 1579.49 | 85.51 |
You can see that List<T> is always faster for value types. For reference types it is sometimes slower, but never by much. The gains far outweigh the losses, so it's pretty easy to say "use generics!" Of course, if you're performing intensive operations involving sorts, then you might want to try out both options to see which does better with your code.
SortedDictionary, a new generic counterpart to the SortedList collection, uses a tree-based implementation, so insertions, removals, and lookups should all be O(log N). In contrast, SortedList uses a sorted array-based implementation, so insertions and removals are O(N) and lookups should be O(log N). Generally then, SortedDictionary is the better choice, but it does have some drawbacks. Since each item in the tree is wrapped in a Node, and since a Node is a reference type, using a SortedDictionary will create a lot of objects on the garbage-collected heap, which may negatively impact the performance of the garbage collector (GC). Also, since the items in SortedDictionary are linked together through references and are not guaranteed to be near each other in memory, there is a greater chance that one of the items will not be found in the processor cache causing extra trips to memory and possibly extra page faults. The result of this will be performance that is worse than that of SortedList.
Reading from Files
The .NET Framework 2.0 introduces new APIs on the File class which enable simple reading and writing of an entire file. Rather than having to write your own logic to consume the contents of a file, File.ReadAllLines (and ReadAllBytes and ReadAllText) does this for you in one easy call. Performance-wise, if you actually want to retrieve and hold onto all of that data, these operations are great. For example, if you simply want to open a file and dump its contents into a Textbox (say your recreating notepad), ReadAllText is magic. Let's take a look at the code in Figure 4 to make sure we're on the same page. It shows how you'd use ReadToEnd with a StreamReader to get the data from a file versus how you'd use File.ReadAllText. For ReadAllText, I don't have to wrap the call in a try block, since the important task of closing the file is performed for me. These patterns are comparable from a performance perspective, although clearly ReadAllText is a little simpler. Note that there are a variety of ways to write the ReadLine code, and this is but one option. In this particular case, ReadAllText actually outperforms the code that reads a line at a time.
Figure 4 StreamReader vs. File.ReadAllText
Getting the data from a file using StreamReader
StringBuilder sb = new StringBuilder();
using (StreamReader sr = new StreamReader(filename))
{
while (sr.Peek() >= 0)
{
sb.AppendLine(sr.ReadLine());
}
}
textBox1.Text = sb.ToString();
Getting the data from a file using ReadAllText
textBox1.Text = File.ReadAllText(filename);
Of course, the new APIs on File (ReadAllLines, ReadAllText, ReadAllBytes) do read the entire file in one go and retain that information in memory. As you retrieve the data, if you need to perform some transformation logic or you're parsing the data into different types, then it may well be better to read a line at a time and release the underlying data as you go.
To demonstrate this case, imagine you're doing something with each line or segment of data as it comes in (see Figure 5). The Person class you're using has a Parse method, which creates a Person object from the line of data. For File.ReadAllLines, the data from the file is sitting around in memory the whole time, but this isn't the case for StreamReader.ReadLine. So for this scenario, ReadLine is an option to consider. Note that it would take a pretty sizable file to see the kind of difference that's going to make you prefer the ReadLine alternative. You'll notice as well that in this case, the coding pattern for File.ReadAllLines isn't much less complex than the coding pattern for StreamReader.ReadLine. Given this, either alternative seems fair.
Figure 5 StreamReader vs. File.ReadAllLines
Getting and parsing the data from a file using StreamReader.ReadLine
Dim lp As New List(Of Person)
Using sr As New StreamReader(filename)
Do While sr.Peek() >= 0
Dim p as Person
If Person.TryParse(sr.ReadLine(), p) Then lp.Add(p)
Loop
End Using
Return lp
Getting and parsing the data from a file using File.ReadAllLines
Dim lp As New List(Of Person)
For Each nextPerson As String In File.ReadAllLines(filename)
Dim p as Person
If Person.TryParse(nextPerson, p) Then lp.Add(p)
Next
Return lp
General I/O Tips
Here's a handful of things to remember when doing I/O operations. FileStream has an internal buffer which defaults to 4KB. When you're writing data to a file, if you're attempting to write more than 4KB, you actually bypass that buffer automatically—good news from a performance perspective. But now, imagine that you're trying to tweak performance of your application. You increase the size of FileStream's buffer to 32KB, so that a write isn't performed until at least that much data is available. The NTFS file system also has an internal buffer, and its size is 64KB. The 32KB of data you write from FileStream will be captured in that buffer. To bypass the NTFS buffer and go directly to the I/O device that you're writing to, increase the buffer of FileStream to above 64KB. This can result in a performance boost and provide good control over I/O operations.
If you have long-running applications that write a file and expect it to be sequential on disk, you may be surprised. When you first create the file to write to, a certain amount of space is reserved. If another file is created in the meantime (a likely scenario), then when you later add data to your original file it may be reserved in another location, resulting in disk fragmentation of your file and poorer performance than you expect. If you find yourself in this situation (writing data to a file in a long-running application) remember to reserve plenty of space in the file when you first create it. You can do this by using FileStream.SetLength.
When using the new compression APIs available in version 2.0 of the .NET Framework (the System.IO.Compression namespace), it's fundamentally important to consider buffering your data when writing out your file. When you write to the compressed stream, the algorithm for compressing the data will perform its operations based on the bits it can currently see. So if you're passing only a small segment of bits, the savings will be small or even negative. Wrapping the compressed stream in a buffered stream, so that the writes are performed in larger chunks, gives the compression algorithm more of an opportunity to spot good, positive savings for you.
Regular Expression Compilation
In the Regular Expression (Regex) space, there is the option to specify that a regular expression is compiled through use of the RegexOptions.Compiled setting. This switch hints at an underlying aspect of regular expressions in .NET: they have three modes. Let's look at each of those modes and discuss the relative performance trade-offs of each.
By default, regular expressions in .NET are interpreted. That is, you create a Regex with no compiled switch. Interpreted Regexes have the smallest impact to the startup performance of an application, but they have the slowest run-time speed since all of the processing remains to be conducted at run time. They are a good option if your Regex will be used rarely, since a rarely used expression won't impact overall run-time speed much (by definition), and taking any kind of startup hit probably isn't worth it:
Regex r = new Regex("abc*");
Regex.Match("1234bar", @"(\d*)bar");
The second option is regular expressions that are compiled on the fly. This is simple to achieve by passing in RegexOptions.Compiled when performing your Regex operation on the Regex (or by passing it into the Regex constructor). In this scenario, the regular expression engine does initial work to parse the expression into opcodes. Then, the engine turns those opcodes into Microsoft intermediate language (MSIL) using Reflection.Emit. Basically, it front loads as much work as it can to the startup of your app, effectively trading run-time speed for startup speed. In practice, compilation takes about an order of magnitude longer to start up, but on average yields 30 percent better run-time performance. This is a good solution if you have a regular expression you're going to be performing often. The overall run-time savings will add up and become significant compared to the hit you have to take at startup time.
There is a caution here, however. Emitting MSIL with Reflection.Emit loads a lot of code and uses a lot of memory, and that's not memory you'll ever get back. Generated MSIL cannot be unloaded, or at least, it couldn't in the .NET Framework 1.x. The only way to unload code is to unload an entire application domain. This is a general rule, and is simply the sacrifice you have to make. The good news is that part of this problem is solved in the .NET Framework 2.0—regular expressions are compiled using Lightweight Code Generation, which allows the generated MSIL to be garbage collected. But even then, you may need to release more of the functionality faster. Therefore, the general approach to compiled Regexes should be to only use this mode for a finite set of expressions that you know will be used repeatedly. Even more specifically, avoid this mode except for one or two key Regexes, and for the rest use either interpreted or, the final option, precompiled. Here's how RegexOptions looks:
Regex r = new Regex("abc*", RegexOptions.Compiled);
Regex.Match("1234bar", @"(\d*)bar", RegexOptions.Compiled);
Regex precompilation solves many of the problems associated with compiling on the fly, and retains all of the performance benefits. Precompilation means you do all of the work of parsing and generating MSIL when you compile your app, ending up with a custom class derived from Regex. Run-time performance of this technique is identical to what you get when you compile on the fly.
There is, of course, a trade-off: the whole meaning of precompiled is that the Regex is put into its own assembly before you run your application. You therefore can't have the code for constructing the Regex inline, and you'll have to write other code (a tool perhaps) to construct your precompiled Regex ahead of time. You can do this with Regex.CompileToAssembly:
Dim rci As RegexCompilationInfo = New RegexCompilationInfo( _
"abc*", RegexOptions.None, "standard", "Sample.Regex", True)
Regex.CompileToAssembly( _
New RegexCompilationInfo() {rci}, New AssemblyName("foo.dll"))
Once in its own assembly, your calling code can reference this Regex directly. There's the startup hit of loading the assembly, but the performance benefits of not having to interpret or compile the expression at run time are preserved. This option has an additional benefit for performance. Your startup time reduces to loading and JITing your class, which should be comparable to the startup cost of interpreted mode, making this option the best of both worlds.
Overall, I strongly suggest you consider precompilation of Regexes, particularly for expressions you use a lot, and from multiple applications or assemblies.
Local vs. UTC DateTimes
One of the easiest things to note is that UtcNow (basically, culture-neutral time) performs better than Now. And not a little bit better, a lot better.
Of course, this piece of information isn't that helpful when you're showing data to users. After all, at the point that you want to show someone a DateTime, more often than not it has to be turned into some form of localized useful data. But if you're comparing two DateTimes to see if one event occurred before or after another, or you're performing other calculations where culture is not required, then UtcNow is the clear choice. Of course, this means that it's better to keep your DateTimes as UTC values until you need to retrieve them in some localized format (performance aside, it's a good idea to keep your DateTimes as UTC values, as this allows you to compare data from multiple time zones accurately and without being adversely affected by Daylight Savings Time).
Try out the following example code to see the performance results for yourself. Simply change the call to UtcNow to calls to Now to try the culture-aware version:
DateTime dt = DateTime.UtcNow;
Stopwatch sw = new Stopwatch();
for (int i = 0; i < 10; i++) {
sw.Start();
for (int j = 0; j < 100000; j++) {
if (DateTime.UtcNow == dt) { /* do action */ }
}
Console.WriteLine(sw.ElapsedTicks);
}
String Comparisons
Strings in .NET are fairly powerful in that they can be compared in culture-sensitive ways, or with no regard for culture at all. By default, many, or even most, operations are culture sensitive. Unless you need to compare strings in a culture-sensitive fashion, then always use ordinal comparisons to compare strings. Of course, the same goes for sorting strings as well. As with UtcNow, the savings by sorting/comparing this way are dramatic. There are specific APIs on String which highlight the value of this approach (String.CompareOrdinal, for example). This kind of comparison is as first-class as its culture-aware counterpart.
When you want to keep case in mind (as many string comparisons do) but you still want the performance benefit, then StringComparer.OrdinalIgnoreCase is the way to go. This is also substantially faster than respecting culture in comparisons, while leaving you with the one concept that many sorts/comparisons typically want: the ability to be case-insensitive.
PerformanceCounter Lifetime
PerformanceCounters aren't free to instantiate—there is a cost overhead. Therefore, don't recreate PerformanceCounters if you can avoid it. Instead, instantiate an instance of the counter for your entire application and keep it around. A good way to achieve this, of course, is to have a static variable for each counter you want to represent and simply hold onto it in your application:
Shared ReadOnly myCounter1 As PerformanceCounter = _
New PerformanceCounter("category", "counter1", "instance")
Shared ReadOnly myCounter2 As PerformanceCounter = _
New PerformanceCounter("category", "counter2", "instance")
Resource Lookup
The NeutralResourcesLanguage attribute was added in the .NET Framework 2.0 solely for performance reasons, so it's a good choice for this column. When resource probing is performed, it's done in a very structured manner. If your culture is es-MX (Spanish in Mexico), for example, then resources are searched for in the order of es-MX, es, and finally, the fallback (default) resources in the main assembly.
It's expected that the fallback resources will be in the culture for which the app is most frequently distributed. Even for that culture the extra lookups are performed anyway. That is, if your fallback resources are the same as those used for en-US (English in US), then a search is still performed for en-US and en. The NeutralResourcesLanguageAttribute can help you bypass those checks. By applying it to an assembly (your Main assembly) you can tell the resources engine to avoid those lookups for the specified culture. Don't underestimate the cost of those lookups. They're good to avoid:
[C#]
[assembly: NeutralResourcesLanguageAttribute("en")]
[Visual Basic]
<Assembly: NeutralResourcesLanguageAttribute("en")>
Lock-Free Tracing
Lock-Free Tracing is a new feature in the .NET Framework 2.0. In previous versions of the Framework, two traces were not allowed to happen at the same time. All tracing was always locked internally, guaranteeing atomicity of the given operation, and that tracing would occur in the right order.
This is quite expensive, however, and impacts tracing performance considerably. In version 2.0, there's a new way to specify that you don't want to lock a particular listener—a new UseGlobalLock property on the Trace class. This property is set to true by default, reflecting the version 1.x behavior. But you can set it to false programmatically or in the config file:
<system.diagnostics>
<trace useGlobalLock="false" />
</system.diagnostics>
By turning off global locking, you're giving each listener the opportunity to specify whether it should be locked. Note that if a listener says it isn't thread safe, global locking is used anyway. This is basically to ensure that global locking is only used if it's absolutely clear that it's what you intended to do.
In order to take advantage of this feature, make your own custom TraceListener (derived from the TraceListener class). Ensure that critical operations, such as WriteLine, are atomic and that you set IsThreadSafe to true. If you take these actions, the TraceListener code will take advantage of the UseGlobalLock setting, resulting in a faster TraceListener.
Conclusion
In this month's installment, I've discussed myriad ways in which you can improve the performance of your application. The broad advice always remains: pay attention to the techniques you're using, and ensure you're considering the optimal performance for that scenario. If you do trade performance for functionality, at least do it consciously, not by accident. You can continually improve performance using new features or by using APIs the way they're designed to be used. So keep an eye out for ways to maximize performance when using the BCL.
Send your questions and comments to clrinout@microsoft.com.
Kit George is a Program Manager for the base classes within the Common Language Runtime team. David Gutierrez, Anthony Moore, Ravi Krishnaswamy, Brian Grunkemeyer, Ryan Byington, and David Fetterman, also from the CLR team, contributed to this column.