Talking Windows
Exploring New Speech Recognition And Synthesis APIs In Windows Vista
Robert Brown
This article is based on a prerelease version of WinFX. All information contained herein is subject to change.
This article discusses:
|
This article uses the following technologies: Windows Vista, WinFX |
Contents
Elements of Speech
Talking to Windows Vista
Windows Vista Speech APIs
System.Speech.Synthesis
System.Speech.Recognition
Telephony Applications
Conclusion
Microsoft has been researching and developing speech technologies for over a decade. In 1993, the company hired Xuedong (XD) Huang, Fil Alleva, and Mei-Yuh Hwang—three of the four people responsible for the Carnegie Mellon University Sphinx-II speech recognition system, which achieved fame in the speech world in 1992 due to its unprecedented accuracy. Right from the start, with the formation of the Speech API (SAPI) 1.0 team in 1994, Microsoft was driven to create a speech technology that was both accurate and accessible to developers through a powerful API. The team has continued to grow and over the years has released a series of increasingly powerful speech platforms.
In recent years, Microsoft has placed an increasing emphasis on bringing speech technologies into mainstream usage. This focus has led to products such as Speech Server, which is used to implement speech-enabled telephony systems, and Voice Command, which allows users to control Windows Mobile® devices using speech commands. So it should come as no surprise that the speech team at Microsoft has been far from idle in the development of Windows Vista™. The strategy of coupling powerful speech technology with a powerful API has continued right through to Windows Vista.
Windows Vista includes a built-in speech recognition user interface designed specifically for users who need to control Windows® and enter text without using a keyboard or mouse. There is also a state-of-the-art general purpose speech recognition engine. Not only is this an extremely accurate engine, but it's also available in a variety of languages. Windows Vista also includes the first of the new generation of speech synthesizers to come out of Microsoft, completely rewritten to take advantage of the latest techniques.
On the developer front, Windows Vista includes a new WinFX® namespace, System.Speech. This allows developers to easily speech-enable Windows Forms applications and apps based on the Windows Presentation Framework. In addition, there's an updated COM Speech API (SAPI 5.3) to give native code access to the enhanced speech capabilities of the platform. For more information on this, see the "New to SAPI 5.3" sidebar.
Elements of Speech
The concept of speech technology really encompasses two technologies: synthesizers and recognizers (see Figure 1). A speech synthesizer takes text as input and produces an audio stream as output. Speech synthesis is also referred to as text-to-speech (TTS). A speech recognizer, on the other hand, does the opposite. It takes an audio stream as input, and turns it into a text transcription.
Figure 1 Speech Recognition and Synthesis
.gif)
A lot has to happen for a synthesizer to accurately convert a string of characters into an audio stream that sounds just as the words would be spoken. The easiest way to imagine how this works is to picture the front end and back end of a two-part system.
The front end specializes in the analysis of text using natural language rules. It analyzes a string of characters to figure out where the words are (which is easy to do in English, but not as easy in languages such as Chinese and Japanese). This front end also figures out details like functions and parts of speech—for instance, which words are proper nouns, numbers, and so forth; where sentences begin and end; whether a phrase is a question or a statement; and whether a statement is past, present, or future tense.
All of these elements are critical to the selection of appropriate pronunciations and intonations for words, phrases, and sentences. Consider that in English, a question usually ends with a rising pitch, or that the word "read" is pronounced very differently depending on its tense. Clearly, understanding how a word or phrase is being used is a critical aspect of interpreting text into sound. To further complicate matters, the rules are slightly different for each language. So, as you can imagine, the front end must do some very sophisticated analysis.
The back end has quite a different task. It takes the analysis done by the front end and, through some non-trivial analysis of its own, generates the appropriate sounds for the input text. Older synthesizers (and today's synthesizers with the smallest footprints) generate the individual sounds algorithmically, resulting in a very robotic sound. Modern synthesizers, such as the one in Windows Vista, utilize a database of sound segments built from hours and hours of recorded speech. The effectiveness of the back end depends on how good it is at selecting the appropriate sound segments for any given input and smoothly splicing them together.
If this all sounds vastly complicated, well, it is. Having these-text- to speech capabilities built into the operating system is very advantageous, as it allows applications to just use this technology. There's no need to go create your own speech engines. As you'll see later in the article, you can invoke all of this processing with a single function call. Lucky you!
Speech recognition is even more complicated than speech synthesis. However, it too can be thought of as having a front end and a back end. The front end processes the audio stream, isolating segments of sound that are probably speech and converting them into a series of numeric values that characterize the vocal sounds in the signal. The back end is a specialized search engine that takes the output produced by the front end and searches across three databases: an acoustic model, a lexicon, and a language model. The acoustic model represents the acoustic sounds of a language, and can be trained to recognize the characteristics of a particular user's speech patterns and acoustic environments. The lexicon lists a large number of the words in the language, along with information on how to pronounce each word. The language model represents the ways in which the words of a language are combined.
Neither of these models is trivial. It's impossible to specify exactly what speech sounds like. And human speech rarely follows strict and formal grammar rules that can be easily defined. An indispensable factor in producing good models is the acquisition of very large volumes of representative data. An equally important factor is the sophistication of the techniques used to analyze that data to produce the actual models.
Of course, no word has ever been said exactly the same way twice, so the recognizer is never going to find an exact match. And for any given segment of sound, there are very many things the speaker could potentially be saying. The quality of a recognizer is determined by how good it is at refining its search, eliminating the poor matches, and selecting the more likely matches. A recognizer's accuracy relies on it having good language and acoustic models, and good algorithms both for processing sound and for searching across the models. The better the models and algorithms, the fewer the errors that are made, and the quicker the results are found. Needless to say, this is a difficult technology to get right.
While the built-in language model of a recognizer is intended to represent a comprehensive language domain (such as everyday spoken English), any given application will often have very specific language model requirements. A particular application will generally only require certain utterances that have particular semantic meaning to that application. Hence, rather than using the general purpose language model, an application should use a grammar that constrains the recognizer to listen only for speech that the application cares about. This has a number of benefits: it increases the accuracy of recognition, it guarantees that all recognition results are meaningful to the application, and it enables the recognition engine to specify the semantic values inherent in the recognized text. Figure 2 shows one example of how these benefits can be put to use in a real-world scenario.
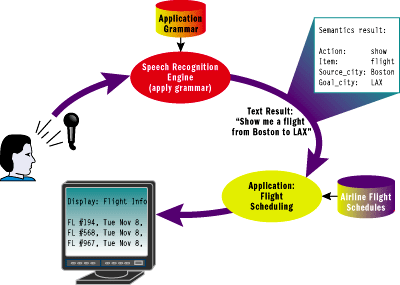
Figure 2** Using Speech Recognition for Application Input **
Talking to Windows Vista
Accuracy is only part of the equation. With the Windows Vista speech recognition technology, Microsoft has a goal of providing an end-to-end speech experience that addresses key features that users need in a built-in desktop speech recognition experience. This includes an interactive tutorial that explains how to use speech recognition technology and helps the user train the system to understand the user's speech.
The system includes built-in commands for controlling Windows—allowing you to start, switch between, and close applications using commands such as "Start Notepad" and "Switch to Calculator." Users can control on-screen interface elements like menus and buttons by speaking commands like "File" and "Open." There's also support for emulating the mouse and keyboard by giving commands such as "Press shift control left arrow 3 times."
Windows Vista speech technology includes built-in dictation capabilities (for converting the user's voice into text) and edit controls (for inserting, correcting, and manipulating text in documents). You can correct misrecognized words by redictating, choosing alternatives, or spelling. For example, "Correct Robot, Robert." Or "Spell it R, O, B, E, R as in rabbit, T as in telephone." You can also speak commands to select text, navigate inside a document, and make edits—for instance, "Select 'My name is,'" "Go after Robert," or "Capitalize Brown."
The user interface is designed to be unobtrusive, yet to keep the user in control of the speech system at all times (see Figure 3). You have easy access to the microphone state, which includes a sleeping mode. Text feedback tells the user what the system is doing, and provides instructions to the user. There's also a user interface used for clarifying what the user has said–when the user utters a command that can be interpreted in multiple ways, the system uses this interface to clarify what was intended. Meanwhile, ongoing use allows the underlying models to adapt continually improve accuracy over time.
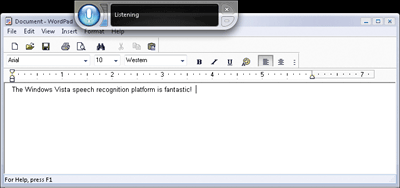
Figure 3** Speech UI in Windows Vista **
To enable built-in speech functionality, from the Start Menu choose All Programs | Accessories | Accessibility and click Speech Recognition. The first time you do this, the system will step you through the tutorial, where you'll be introduced to some basic commands. You also get the option of enabling background language model adaptation, by which the system will read through your documents and e-mail in the background to adapt the language model to better match the way you express yourself. There are a variety of things the default settings enable. I recommend that you ask the system "what can I say" and then browse the topics.
But you're a developer, so why do you care about all this user experience stuff? The reason this is relevant to developers is that this is default functionality provided by the operating system. This is functionality that your applications will automatically get. The speech technology uses the Windows accessibility interfaces to discover the capabilities of each application; it then provides a spoken UI for each. If a user says the name of an accessible element, then the system will invoke the default function of that element. Hence, if you have built an accessible application, you have by default built a speech-enabled application.
Windows Vista Speech APIs
Windows Vista can automatically speech-enable any accessible application. This is fantastic news if you want to let users control your application with simple voice commands. But you may want to provide a speech-enabled user interface that is more sophisticated or tailored than the generic speech-enabled UI that Windows Vista will automatically supply.
There are numerous examples of why you might need to do this. If, for example, your user has a job that requires her to use her hands at all times. Any time she needs to hold a mouse or tap a key on the keyboard is time that her hands are removed from the job—this may compromise safety or reduce productivity. The same could be true for users who need their eyes to be looking at something other than a computer screen. Or, say your application has a very large number of functions that get lost in toolbar menus. Speech commands can flatten out deep menu structures, offering fast access to hundreds of commands. If your users ever say "that's easier said than done," they may be right.
In Windows Vista, there are two speech APIs:
- SAPI 5.3 for native applications
- The System.Speech.Recognition and System.Speech.Synthesis namespaces in WinFX
Figure 4 illustrates how each of these APIs relates to applications and the underlying recognition and synthesis engines.
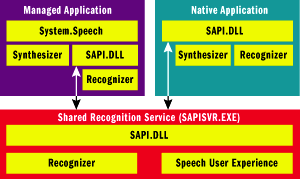
Figure 4** Speech APIs in Windows Vista **
The speech recognition engine is accessed via SAPI. Even the classes in the System.Speech.Recognition namespaces wrap the functionality exposed by SAPI. (This is an implementation detail of Windows Vista that may change in future releases, but it's worth bearing in mind.) The speech synthesis engine, on the other hand, is accessed directly by the classes in System.Speech.Synthesis or, alternatively, by SAPI when used in an unmanaged application.
Both types implement the SAPI device driver interface (DDI), which is an API that makes engines interchangeable to the layers above them, much like the way device driver APIs make hardware devices interchangeable to the software that uses them. This means that developers who use SAPI or System.Speech are still free to use other engines that implement the SAPI DDI (and many do).
Notice in Figure 4 that the synthesis engine is always instantiated in the same process as the application, but the recognition engine can be instantiated in another process called SAPISVR.EXE. This provides a shared recognition engine that can be used simultaneously by multiple applications. This design has a number of benefits. First, recognizers generally require considerably more run-time resources than synthesizers, and sharing a recognizer is an effective way to reduce the overhead. Second, the shared recognizer is also used by the built-in speech functionality of Windows Vista. Therefore, apps that use the shared recognizer can benefit from the system's microphone and feedback UI. There's no additional code to write, and no new UI for the user to learn.New to SAPI 5.3
SAPI 5.3 is an incremental update to SAPI 5.1. The core mission and architecture for SAPI are unchanged. SAPI 5.3 adds performance improvements, overall enhancements to security and stability, and a variety of new functionality, including:
W3C Speech Synthesis Markup Language SAPI 5.3 supports the W3C Speech Synthesis Markup Language (SSML) version 1.0. SSML provides the ability to mark up voice characteristics, speed, volume, pitch, emphasis, and pronunciation so that a developer can make TTS sound more natural in their application.
W3C Speech Recognition Grammar Specification SAPI 5.3 adds support for the definition of context-free grammars using the W3C Speech Recognition Grammar Specification (SRGS), with these two important constraints: it does not support the use of SRGS to specify dual-tone modulated-frequency (touch-tone) grammars, and it only supports the expression of SRGS as XML—not as Augmented Backus-Naur Form (ABNF).
Semantic Interpretation SAPI 5.3 enables an SRGS grammar to be annotated with JScript® for semantic interpretation, so that a recognition result may contain not only the recognized text, but the semantic interpretation of that text. This makes it easier for apps to consume recognition results, and empower grammar authors to provide a full spectrum of semantic processing beyond what could be achieved with name-value pairs.
User-Specified "Shortcuts" in Lexicons This is the ability to add a string to the lexicon and associate it with a shortcut word. When dictating, the user can say the shortcut word and the recognizer will return the expanded string.
As an example, a developer could create a shortcut for a location so that a user could say "my address" and the actual data would be passed to the application as "123 Smith Street, Apt. 7C, Bloggsville 98765, USA". The following code sets up the lexicon shortcut:
CComPtr<ISpShortcut> cpShortcut; HRESULT hr = cpShortcut.CoCreateInstance(CLSID_SpShortcut); if (SUCCEEDED(hr)) { hr = cpShortcut.AddShortcut(L"my address", 1033, L"123 Smith Street, Apt. 7C, Bloggsville 98765, USA", SPSHT_OTHER); }
When this code is used, the shortcut is added to the speech lexicon. Every time a user says "my address," the actual address is returned as the transcribed text.
Discovery of Engine Pronunciations SAPI 5.3 enables applications to query the Windows Vista recognition and synthesis engines for the pronunciations they use for particular words. This API will tell the application not only the pronunciation, but how that pronunciation was derived.
System.Speech.Synthesis
Let's take a look at some examples of how to use speech synthesis from a managed application. In the grand tradition of UI output examples, I'll start with an application that simply says "Hello, world," shown in Figure 5. This example is a bare-bones console application as freshly created in Visual C#®, with three lines added. The first added line simply introduces the System.Speech.Synthesis namespace. The second declares and instantiates an instance of SpeechSynthesizer, which represents exactly what its name suggests: a speech synthesizer. The third added line is a call to SpeakText. This is all that's needed to invoke the synthesizer!
Figure 5 Saying Hello
using System; using System.Speech.Synthesis; namespace TTS_Console_Sample_1 { class Program { static void Main(string[] args) { SpeechSynthesizer synth = new SpeechSynthesizer(); synth.SpeakText("Hello, world!"); } } }
By default, the SpeechSynthesizer class uses the synthesizer that is nominated as default in the Speech control panel. But it can use any SAPI DDI-compliant synthesizer.
The next example (see Figure 6) shows how this can be done, using the old Sam voice from Windows 2000 and Windows XP, and the new Anna and Microsoft® Lili voices from Windows Vista. (Note that this and all remaining System.Speech.Synthesis examples use the same code framework as the first example, and just replaces the body of Main.) This example shows three instances of the SelectVoice method using the name of the desired synthesizer. It also demonstrates the use of the Windows Vista Chinese synthesizer, Lili. Incidentally, Lili also speaks English very nicely.
Figure 6 Hearing Voices
SpeechSynthesizer synth = new SpeechSynthesizer(); synth.SelectVoice("Microsoft Sam"); synth.SpeakText("I'm Sam."); synth.SpeakText("You may have heard me speaking to you in Windows XP."); synth.SpeakText("Anna will make me redundant."); synth.SelectVoice("Microsoft Anna"); synth.SpeakText("I am the new voice in Windows."); synth.SpeakText("Sam belongs to a previous generation."); synth.SpeakText("I sound great."); synth.SelectVoice("Microsoft Lili"); synth.SpeakText("<span xmlns="https://www.w3.org/1999/xhtml">我是在北京被研究开发的我使用了专业播音员的声音。每 个听到过我说话的人都说我是中文语音合成中最棒的!</span>"); // Requires MS Mincho and SimSun fonts to view /* "I was developed in Beijing, using recordings of a professional news reader. Everybody who hears me talk says that I am the best synthesized Chinese voice they have ever heard!" */
In both of these examples, I use the synthesis API much as I would a console API: an application simply sends characters, which are rendered immediately in series. But for more sophisticated output, it's easier to think of synthesis as the equivalent of document rendering, where the input to the synthesizer is a document that contains not only the content to be rendered, but also the various effects and settings that are to be applied at specific points in the content.
Much like an XHTML document can describe the rendering style and structure to be applied to specific pieces of content on a Web page, the SpeechSynthesizer class can consume an XML document format called Speech Synthesis Markup Language (SSML). The W3C SSML recommendation (www.w3.org/TR/speech-synthesis) is very readable, so I'm not going to dive into describing SSML in this article. Suffice it to say, an application can simply load an SSML document directly into the synthesizer and have it rendered. Here's an example that loads and renders an SSML file:
SpeechSynthesizer synth = new SpeechSynthesizer(); PromptBuilder savedPrompt = new PromptBuilder(); savedPrompt.AppendSsml("c:\\prompt.ssml"); synth.Speak(SavedPrompt);
A convenient alternative to authoring an SSML file is to use the PromptBuilder class in System.Speech.Synthesis. PromptBuilder can express almost everything an SSML document can express, and is much easier to use (see Figure 7). The general model for creating sophisticated synthesis is to first use a PromptBuilder to build the prompt exactly the way you want it, and then use the Synthesizer's Speak or SpeakAsync method to render it.
Figure 7 Using PromptBuilder
//This prompt is quite complicated //So I'm going to build it first, and then render it. PromptBuilder myPrompt = new PromptBuilder(); //Start the main speaking style PromptStyle mainStyle = new PromptStyle(); mainStyle.Rate = PromptRate.Medium; mainStyle.Volume = PromptVolume.Loud; myPrompt.StartStyle(MainStyle); //Alert the listener myPrompt.AppendAudio(new Uri( "file://c:\\windows\\media\\notify.wav"), "Attention!"); myPrompt.AppendText("Here are some important messages."); //Here's the first important message myPrompt.AppendTextWithPronunciation("WinFX", "<span xmlns="https://www.w3.org/1999/xhtml">wɪnɛfɛks</span>"); myPrompt.AppendText("is a great platform."); //And the second one myPrompt.AppendTextWithHint("ASP", SayAs.Acronym); myPrompt.AppendText( "is an acronym for Active Server Pages. Whereas an ASP is a snake."); myPrompt.AppendBreak(); //Let's emphasise how important these messages are PromptStyle interimStyle = new PromptStyle(); interimStyle.Emphasis = PromptEmphasis.Strong; myPrompt.StartStyle(interimStyle); myPrompt.AppendText("Please remember these two things."); myPrompt.EndStyle(); //Then we can revert to the main speaking style myPrompt.AppendBreak(); myPrompt.AppendText("Thank you"); myPrompt.EndStyle(); //Now let's get the synthesizer to render this message SpeechSynthesizer synth = new SpeechSynthesizer(); synth.Speak(myPrompt);
Figure 7 illustrates a number of powerful capabilities of the PromptBuilder. The first thing to point out is that it generates a document with a hierarchical structure. The example uses one speaking style nested within another. At the beginning of the document, I start the speaking style I want used for the entire document. Then about halfway through, I switch to a different style to provide emphasis. When I end this style, the document automatically reverts to the previous style.
The example also shows a number of other handy capabilities. The AppendAudio function causes a WAV file to be spliced into the output, with a textual equivalent to be used if the WAV file can't be found. The AppendTextWithPronunciation function allows you to specify the precise pronunciation of a word. A speech synthesis engine already knows how to pronounce most of the words in general use in a language, through a combination of an extensive lexicon and algorithms for deriving the pronunciation of unknown words. But this won't work for all words, such as some specialized terms or brand names. For example, "WinFX" would probably be pronounced as "winfeks". Instead, I use the International Phonetic Alphabet to describe "WinFX" as "wɪnɛfɛks", where the letter "ɪ" is Unicode character 0x026A (the "i" sound in the word "fish", as opposed to the "i" sound in the word "five") and the letter "ɛ" is Unicode character 0x025B (the General American "e" sound in the word "bed").
In general, a synthesis engine can distinguish between acronyms and capitalized words. But occasionally you'll find an acronym that the engine's heuristics incorrectly deduce to be a word. So you can use the AppendTextWithHint function to identify a token as an acronym. There are a variety of nuances you can introduce with the PromptBuilder. My example is more illustrative than exhaustive.
Another benefit of separating content specification from run-time rendering is that you are then free to decouple the application from the specific content it renders. You can use PromptBuilder to persist its prompt as SSML to be loaded by another part of the application, or a different application entirely. The following code writes to an SSML file with PromptBuilder:
using(StreamWriter promptWriter = new StreamWriter("c:\\prompt.ssml")) { promptWriter.Write(myPrompt.ToXml()); }
Another way to decouple content production is to render the entire prompt to an audio file for later playback:
SpeechSynthesizer synth = new SpeechSynthesizer(); synth.SetOutputToWaveFile("c:\\message.wav"); synth.Speak(myPrompt); synth.SetOutputToNull();
Whether to use SSML markup or the PromptBuilder class is probably a matter of stylistic preference. You should use whichever you feel more comfortable with.
One final note about SSML and PromptBuilder is that the capabilities of every synthesizer will be slightly different. Therefore, the specific behaviors you request with either of these mechanisms should be thought of as advisory requests that the engine will apply if it is capable of doing so.
System.Speech.Recognition
While you could use the general dictation language model in an application, you would very rapidly encounter a number of application development hurdles regarding what to do with the recognition results. For example, imagine a pizza ordering system. A user could say "I'd like a pepperoni pizza" and the result would contain this string. But it could also contain "I'd like pepper on a plaza" or a variety of similar sounding statements, depending on the nuances of the user's pronunciation or the background noise conditions. Similarly, the user could say "Mary had a little lamb" and the result would contain this, even though it's meaningless to a pizza ordering system. All of these erroneous results are useless to the application. Hence an application should always provide a grammar that describes specifically what the application is listening for.
In Figure 8, I've started with a bare-bones Windows Forms application and added a handful of lines to achieve basic speech recognition. First, I introduce the System.Speech.Recognition namespace, and then instantiate a SpeechRecognizer object. Then I do three things in Form1_Load: build a grammar, attach an event handler to that grammar so that I can receive the SpeechRecognized events for that grammar, and then load the grammar into the recognizer. At this point, the recognizer will start listening for speech that fits the patterns defined by the grammar. When it recognizes something that fits the grammar, the grammar's SpeechRecognized event handler is invoked. The event handler itself accesses the Result object and works with the recognized text.
Figure 8 Ordering a Pizza
using System; using System.Windows.Forms; using System.ComponentModel; using System.Collections.Generic; using System.Speech.Recognition; namespace Reco_Sample_1 { public partial class Form1 : Form { //create a recognizer SpeechRecognizer _recognizer = new SpeechRecognizer(); public Form1() { InitializeComponent(); } private void Form1_Load(object sender, EventArgs e) { //Create a pizza grammar Choices pizzaChoices = new Choices(); pizzaChoices.AddPhrase("I'd like a cheese pizza"); pizzaChoices.AddPhrase("I'd like a pepperoni pizza"); pizzaChoices.AddPhrase("I'd like a large pepperoni pizza"); pizzaChoices.AddPhrase( "I'd like a small thin crust vegetarian pizza"); Grammar pizzaGrammar = new Grammar(new GrammarBuilder(pizzaChoices)); //Attach an event handler pizzaGrammar.SpeechRecognized += new EventHandler<RecognitionEventArgs>( PizzaGrammar_SpeechRecognized); _recognizer.LoadGrammar(pizzaGrammar); } void PizzaGrammar_SpeechRecognized( object sender, RecognitionEventArgs e) { MessageBox.Show(e.Result.Text); } } }
The System.Speech.Recognition API supports the W3C Speech Recognition Grammar Specification (SRGS), documented at www.w3.org/TR/speech-grammar. The API even provides a set of classes for creating and working with SRGS XML documents. But for most cases, SRGS is overkill, so the API also provides the GrammarBuilder class that suffices nicely for our pizza ordering system.
The GrammarBuilder lets you assemble a grammar from a set of phrases and choices. In Figure 8 I've eliminated the problem of listening for utterances I don't care about ("Mary had a little lamb"), and constrained the engine so that it can make much better choices between ambiguous sounds. It won't even consider the word "plaza" when the user mispronounces "pizza". So in a handful of lines, I've vastly increased the accuracy of the system. But there are still a couple of problems with the grammar.
The approach of exhaustively listing every possible thing a user can say is tedious, error prone, difficult to maintain, and only practically achievable for very small grammars. It is preferable to define a grammar that defines the ways in which words can be combined. Also, if the application cares about the size, toppings, and type of crust, then the developer has quite a task to parse these values out of the result string. It's much more convenient if the recognition system can identify these semantic properties in the results. This is very easy to do with System.Speech.Recognition and the Windows Vista recognition engine.
Figure 9 shows how to use the Choices class to assemble grammars where the user says something from a list of alternatives. In this code, the contents of each Choices instance are specified in the constructor as a sequence of string parameters. But you have a lot of other options for populating Choices: you can iteratively add new phrases, construct Choices from an array, add Choices to Choices to build the complex combinatorial rules that humans understand, or add GrammarBuilder instances to Choices to build increasingly flexible grammars (as demonstrated by the Permutations part of the example).
Figure 9 Using Choices to Assemble Grammars
private void Form1_Load(object sender, EventArgs e) { //[I'd like] a [<size>] [<crust>] [<topping>] pizza [please] //build the core set of choices Choices sizes = new Choices("small", "regular", "large"); Choices crusts = new Choices("thin crust", "thick crust"); Choices toppings = new Choices("vegetarian", "pepperoni", "cheese"); //build the permutations of choices... //choose all three GrammarBuilder sizeCrustTopping = new GrammarBuilder(); sizeCrustTopping.AppendChoices(sizes, "size"); sizeCrustTopping.AppendChoices(crusts, "crust"); sizeCrustTopping.AppendChoices(toppings, "topping"); //choose size and topping, and assume thick crust GrammarBuilder sizeAndTopping = new GrammarBuilder(); sizeAndTopping.AppendChoices(sizes, "size"); sizeAndTopping.AppendChoices(toppings, "topping"); sizeAndTopping.AppendResultKeyValue("crust", "thick crust"); //choose topping only, and assume the rest GrammarBuilder toppingOnly = new GrammarBuilder(); toppingOnly.AppendChoices(toppings, "topping"); toppingOnly.AppendResultKeyValue("size", "regular"); toppingOnly.AppendResultKeyValue("crust", "thick crust"); //assemble the permutations Choices permutations = new Choices(); permutations.AddGrammarBuilders(sizeCrustTopping); permutations.AddGrammarBuilders(sizeAndTopping); permutations.AddGrammarBuilders(toppingOnly); //now build the complete pattern... GrammarBuilder pizzaRequest = new GrammarBuilder(); //pre-amble "[I'd like] a" pizzaRequest.AppendChoices(new Choices("I'd like a", "a")); //permutations "[<size>] [<crust>] [<topping>]" pizzaRequest.AppendChoices(permutations); //post-amble "pizza [please]" pizzaRequest.AppendChoices(new Choices("pizza", "pizza please")); //create the pizza grammar Grammar pizzaGrammar = new Grammar(pizzaRequest); //attach the event handler pizzaGrammar.SpeechRecognized += new EventHandler<RecognitionEventArgs>( PizzaGrammar_SpeechRecognized); //load the grammar into the recognizer _recognizer.LoadGrammar(pizzaGrammar); } void PizzaGrammar_SpeechRecognized(object sender, RecognitionEventArgs e) { StringBuilder resultString = new StringBuilder(); resultString.Append("Raw text result: "); resultString.AppendLine(e.Result.Text); resultString.Append("Size: "); resultString.AppendLine(e.Result.Semantics["size"].Value.ToString()); resultString.Append("Crust: "); resultString.AppendLine(e.Result.Semantics["crust"].Value.ToString()); resultString.Append("Topping: "); resultString.AppendLine( e.Result.Semantics["topping"].Value.ToString()); MessageBox.Show(resultString.ToString()); }
Figure 9 also shows how to tag results with semantic values. When using GrammarBuilder, you can append Choices to the grammar, and attach a semantic value to that choice, as can be seen in the example with statements like this:
AppendChoices(toppings, "topping");
Sometimes a particular utterance will have an implied semantic value that was never uttered. For example, if the user doesn't specify a pizza size, the grammar can specify the size as "regular", as seen with statements like this:
AppendResultKeyValue("size", "regular");
Fetching the semantic values from the results is done by accessing RecognitionEventArgs.Result.Semantics[<name>].
Telephony Applications
Resources
This article only touches on the capabilities of the new speech technology included in Windows Vista. Here are several resources to help you learn more:
The following members of the Microsoft speech team have active blogs that you may find useful:
One of the biggest growth areas for speech applications is in speech-enabled telephony systems. Many of the principles are the same as with desktop speech: recognition and synthesis are still the keystone technologies, and good grammar and prompt design are critical.
There are a number of other factors necessary for the development of these applications. A telephony application needs a completely different acoustic model. It needs to be able to interface with telephony systems, and because there's no GUI, it needs to manage a spoken dialog with the user. A telephony application also needs to be scalable so that it can service as many simultaneous calls as possible without compromising performance.
Designing, tuning, deploying, and hosting a speech-enabled telephony application is a non-trivial project that the Microsoft Speech Server platform and SDK have been developed to address.
Conclusion
Windows Vista contains a new, more powerful desktop speech platform that is built into the OS. The intuitive UI and powerful APIs make it easy for end users and developers to tap into this technology. If you have the latest Beta build of Windows Vista, you can start playing with these new features immediately.
The Windows Vista Speech Recognition Web site, should be live by the time you're reading this. For links to other sources of information about Microsoft speech technologies, see the "Resources" sidebar.
Robert Brown is a Lead Program Manager on the Microsoft Speech & Natural Language team. Robert joined Microsoft in 1995 and has worked on VOIP and messaging technologies, Speech Server, and the speech platform in Windows Vista. Special thanks to Robert Stumberger, Rob Chambers and other members of the Microsoft speech team for their contribution to this article.