CLR Inside Out
Investigating Memory Issues
Claudio Caldato and Maoni Stephens
Contents
Tools of the Trade
GC Performance Counters
Windows Performance Counters
Verifying an OOM Exception in a Managed Process
Determining What Caused an OOM Exception
Measure Managed Heap Size
What If Objects Survive?
Is Fragmentation a Problem on Your Managed Heap?
Measuring Time Spent on Garbage Collection
Investigating High CPU Usage
Uncovering and correcting memory issues in managed applications can be difficult. Memory issues manifest themselves in different ways. For example, you may observe your application's memory usage growing unboundedly, eventually resulting in an Out Of Memory (OOM) exception. (Your application may even throw out-of-memory exceptions when there is plenty of physical memory available.) But any one of the following may indicate a possible memory issue:
- An OutOfMemoryException is thrown.
- The process is using too much memory for no obvious reason that you can determine.
- It appears that garbage collection is not cleaning up objects fast enough.
- The managed heap is overly fragmented.
- The application is excessively using the CPU.
This column discusses the investigation process and shows you how to collect the data you need to determine what types of memory issues you are dealing with in your applications. This column does not cover how to actually fix problems you find, but it does give some good insights as to where to start.
We'll begin with an overview of the most useful performance counters that can be used to investigate managed memory issues. Then we'll cover the tools that are commonly used for the investigation and will continue with a list of common managed memory issues and how to investigate them.
But before we get started, you should familiarize yourself with some fundamental concepts:
- Garbage collection in the Microsoft® .NET Framework. For more information, see these two blog entries: blogs.msdn.com/156626.aspx and blogs.msdn.com/234273.aspx.
- How virtual memory works in Windows®. This includes the concepts of reserving memory and committing memory.
- Using the Windows Debuggers (WinDbg and CDB).
Tools of the Trade
Before we start, we should spend a moment discussing some tools you will typically use to diagnose memory-related issues.
Performance Counters You will usually want to start with the performance counters. They let you collect essential data that you can use to determine where exactly a problem might be. The most useful performance counters are those that report on the .NET Framework, though there are some others also worth looking at.
Debugger Here we'll use WinDbg, which is available as part of the Debugging Tools for Windows. The Son of Strike extension (SOS), available in SOS.dll, is used for debugging managed code in WinDbg. After you start the debugger and attach it to a managed process (or load a crash dump), you can load the SOS.dll by typing:
.loadby sos mscorwks
If you are debugging an app that uses a different version of mscorwks.dll and as a result this command fails, find the SOS.dll for the mscorwks.dll version the application is using and run this command:
.load <path_to_sos>\sos.dll
SOS.dll is installed with the .NET Framework under %windir%\microsoft.net\framework\<.NET version>. The SOS.dll extension provides a lot of useful commands for examining managed heaps. For documentation on all of its commands, see SOS Debugging Extension (SOS.dll) .
Windows Task Manager Taskmgr.exe is handy for spotting higher-than-expected memory usage and for checking the trend of some simple process metrics over a period of time. Note that there are two metrics in taskmgr that are frequently misinterpreted: Mem Usage and VM Size (Virtual Memory Size). Mem Usage represents the process working set (just like the Process\Working Set performance counter). It does not indicate the committed bytes. VM Size reflects committed bytes by the process (just like the Process\Private Bytes performance counter). VM Size can provide a first hint of whether you are dealing with memory leaks (if your application has a leak, VM Size will grow over time).
Memory Dumps Most of the investigation techniques explained in this column rely on memory dumps. There are two ways to use the debugger—you can attach it to a running process or use it to analyze a crash dump. While the first option offers a direct view into what is going on in your application while it is running, this technique is not always feasible.
Memory dumps have the advantage of decoupling the data collection phase from the actual problem investigation phase. Say you want to diagnose issues on a production server; it may be easier to analyze the dump offline using a different machine.
The .dump /ma dmpfile.dmp command in the debugger can be used to create a full memory dump. Make sure you always capture a full dump when investigating memory issues since minidumps do not contain all the information you need.
The ADPlus tool, which is included in the Debugging Tools for Windows, can be of great help when collecting crash dumps. See John Robbins's Bugslayer column from March 2005 for more information.
Throughout this column, we'll assume that the dump file is already loaded into the debugger (crash dumps can be loaded using the File | Open crash dump command), or that the debugger is already attached to the process and the execution is stopped on a breakpoint.
GC Performance Counters
The first step in every investigation is to collect the relevant data and formulate a hypothesis for where the problem may be. Performance counters are usually the place to start. The .NET Framework Performance Console provides access to counters that provide useful information about the garbage collector (GC) and the garbage collection process. Note that the .NET Memory performance counters are updated only when a collection occurs; they are not updated according to the sampling rate used in the Performance Monitor application.
You should start by checking the % Time in GC. This indicates the percentage of time spent in the GC since the end of the last collection. If you see a really high value (say 50 percent or more), then you should look at what is going on inside the managed heap. If, instead, % Time in GC does not go above 10 percent, it usually is not worth spending time trying to reduce the time the GC spends in collections because the benefits will be marginal.
If you think your application is spending too much time performing garbage collections, the next performance counter to check is Allocated Bytes/sec. This shows the allocation rate. Unfortunately, this counter is not highly accurate when the allocation rate is very low. The counter may indicate 0 bytes/sec if the sampling frequency is higher than the collection frequency since the counter is only updated at the beginning of each collection. This does not mean there were no allocations; rather, the counter was not updated because no collection happened in that particular interval. Knowing how long garbage collection takes is an important consideration, so we'll take a closer look at % Time in GC a bit later.
If you suspect that you are allocating a lot of large objects (85,000 bytes or bigger), check the Large Object Heap (LOH) size. This is updated at the same time as Allocated Bytes/sec.
A high allocation rate can cause a lot of collection work and as a result might be reflected in a high % Time in GC. A mitigating factor is if objects usually die young, since they will typically be collected during a Gen 0 collection. To determine how object lifecycles impact collection, check the performance counters for Gen collections: # Gen 0 Collections, # Gen 1 Collections, and # Gen 2 Collections. These show the number of collections that have occurred for the respective generation since the process started. Gen 0 and Gen 1 collections are usually cheap, so they don't have a big impact on the application's performance. Gen 2 collectors however, can be very expensive.
As a rule of thumb, a healthy ratio between generation collections is one Gen 2 collection for every ten Gen 1 collections. If you are seeing a lot of time spent in garbage collection, it could be that Gen 2 collections are being done too often. You should check this ratio to ensure there aren't too many Gen 2 collections relative to the number of Gen 1 collections.
You may find that % Time in GC is high but the allocation rate is not high. This can happen if many of the objects you allocate survive garbage collection and are promoted to the next generation. The promotion counters—Promoted Memory from Gen 0 and Promoted Memory from Gen 1—can tell you if the promotion rate is an issue. You want to avoid a high promotion rate from Gen 1. This is because you may have a lot of objects that live long enough to be promoted to Gen 2 but don't live long enough to stay in Gen 2. And once promoted to Gen 2, these objects become more expensive to collect than if they had died in Gen1. (This phenomenon is called midlife crisis. Take a look at blogs.msdn.com/41281.aspx for more details.) The CLR Profiler can help you find out which objects live too long.
High values for the Gen 1 and Gen 2 heap sizes are usually associated with high values in the promotion rate counters. You can check the GC heap sizes by using Gen 1 heap size and Gen 2 heap size. There is a Gen 0 heap size counter, but it doesn't measure Gen 0 size. Instead, it indicates the budget of Gen 0—meaning how much you can allocate in Gen 0 before the next Gen 0 collection will be triggered.
In all scenarios where you use a lot of objects that need finalization—for instance, objects that rely on COM components for some processing—you can take a look at the Promoted Finalization-Memory from Gen 0 counter. This tells you the amount of memory that cannot be reused because the objects that use the memory need to be added to the finalization queue and therefore cannot be collected immediately. IDisposable and the using statements in C# and Visual Basic® can help reduce the number of objects that end up in the finalization queue, thus reducing the associated cost.
More data on the heap sizes can be found using # Total committed Bytes and # Total reserved Bytes. These counters indicate the total committed and reserved memory, respectively, on the GC heap at that time. (The value of the total committed bytes is slightly larger than actual Gen 0 heap size + Gen 1 heap size + Gen 2 heap size + Large Object Heap size.) When the GC allocates a new heap segment, the memory is reserved for that segment but will be committed only when needed. Thus, the total reserved bytes can be bigger than the total committed bytes.
It's also worth checking if the application is inducing too many collections. The # Induced GC counter tells you how many collections have been induced since the process started. In general it is not recommended that you induce GC collections. In most cases, if # Induced GC indicates a high number, you should consider it a bug. Most of the time people induce GCs in hopes of cutting down the heap size, but this is almost never a good idea. Instead, you should find out why your heap is growing.
Windows Performance Counters
So far, we've looked at some of the most useful .NET Memory counters. However, you shouldn't overlook the value of other counters. There are various Windows Performance counters (which can also be viewed through perfmon.exe) that provide useful information for investigating memory issues.
The Available Bytes counter, listed under the Memory category, reports the available physical memory. This gives a good indication of whether you are running low on physical memory. If the machine is running low on physical memory, paging will either be happening or will soon begin to happen. This is useful data for diagnosing OOM issues.
The % Committed Bytes in Use counter, which also appears under the Memory category, provides the ratio of commit charge to commit limit. If this value is very high (say, more than 90 percent) you may begin to see commit failures. This is a clear indication that the system is under memory pressure.
Under the Process category, the Private Bytes counter indicates the amount of memory being used that can't be shared with other processes. You should monitor this if you want to see how much memory your process uses. If you are experiencing a memory leak, the private bytes will grow over time. This counter also gives a good indication of how your application impacts the entire system—using a lot of private bytes has a big impact on the machine since the memory cannot be shared with other processes. This is vital in some scenarios, such as terminal service, where you need to maximize the memory shared across user sessions.
Verifying an OOM Exception in a Managed Process
Performance counters can give you a clear indication of whether you are dealing with a memory issue. In most of the cases, though, a memory issue is detected only when you get an Out Of Memory exception in your application. So you need to find out if you are in fact dealing with an OOM exception that is caused by managed code.
After you've loaded SOS.dll, type the following command in the debugger:
!pe
This is the short form for !PrintException. Without an argument, it will print the last managed exception on the thread (if there is one). An example of a managed OOM exception is shown in Figure 1.
Figure 1 OutOfMemoryException for WinDbg
0:010>!pe Exception object: 39594518 Exception type: System.OutOfMemoryException Message: <none> InnerException: <none> StackTrace (generated): SP IP Function 1A7BF848 789336E9 System.MulticastDelegate.CombineImpl( System.Delegate) 1A7BF87C 78930AC4 System.Delegate.Combine(System.Delegate, System.Delegate) ... [omitted] 1A7BFA9C 789B92A3 System.Threading._IOCompletionCallback. PerformIOCompletionCallback(UInt32, UInt32, System.Threading.NativeOverlapped*) StackTraceString: <none> HResult: 8007000e
If there is no managed exception on the current thread, you'll have to find out which thread the OOM is coming from. To find out, type the following into the debugger:
~*kb
Here, kb is short for Display Stack Backtrace. It lists all the threads with their call stacks (see Figure 2). In the output, look for the thread with the stack that has exception calls. The easiest way is to look for mscorwks::RaiseTheException.
Figure 2 Output of Display Stack Backtrace
28adf5e4 7c822124 77e6baa8 000000c0 00000000 ntdll!KiFastSystemCallRet 28adf5e8 77e6baa8 000000c0 00000000 00000000 ntdll!NtWaitForSingleObjec t+0xc 28adf658 77e6ba12 000000c0 ffffffff 00000000 kernel32!WaitForSingleObjec tEx+0xac 28adf66c 791f2dde 000000c0 ffffffff 791f2d8e kernel32!WaitForSingleObjec t+0x12 ... 28adf704 7c82ee84 28adfa9c 28adfbb8 28adf7bc ntdll!ExecuteHandler2+0x26 28adf7ac 7c82eda4 28add000 28adf7bc 00010007 ntdll!ExecuteHandler+0x24 28adfa8c 77e55dea 28adfa9c 25796140 e0434f4d ntdll!RtlRaiseException+0x3d 28adfaec 7924511d e0434f4d 00000001 00000000 kernel32!RaiseException+0x53 28adfb44 7923918f 5b61f2b4 00000000 5b61f2b4 mscorwks!RaiseTheException+0xa0 ...
The argument of the RaiseTheException function in mscorwks is the managed exception object. You can use !pe to dump it. In addition, !pe has a –nested option that will dump any nested exceptions in addition to the top-level ones.
Another way to find the thread that caused the OOM is to use the !threads command from SOS. The last column of the table displayed will contain the most recently thrown managed exception for the respective thread.
If you don't find an OOM exception using these techniques, there are no managed OOMs and the exception you're dealing with is being thrown by native code. In that case, you need to focus on the native code that your application uses (and that discussion is outside the scope of this column).
Determining What Caused an OOM Exception
After you've verified that you are dealing with an OOM case, you should check what caused the OOM. There are two legitimate cases for managed OOMs—either the process is running out of virtual memory or there is not enough physical memory available in order to commit.
The GC needs to allocate memory for its segments. When the GC decides that it needs to allocate a new segment, it calls VirtualAlloc to reserve space. If there isn't a contiguous free block large enough for a segment, the call fails and the GC cannot accommodate the new memory request.
In the debugger, the !address command shows you the largest free region of virtual memory. The output will look something like the following:
0:119>!address -summary ... [omitted] Largest free region: Base 54000000 - Size 03b60000 0:119>? 03b60000 Evaluate expression: 62259200 = 03b60000
If the largest free block of virtual memory for the process is less than 64MB on a 32-bit OS (1GB on 64-bit), the OOM could be caused by running out of virtual memory. (On a 64-bit OS, it is unlikely that the application will run out of virtual memory space.)
The process can run out of virtual space if virtual memory is overly fragmented. It's not common for the managed heap to cause fragmentation of virtual memory, but it can happen. For example, it might occur if the app creates a lot of temporary large objects, causing the LOH to constantly acquire and release segments.
The !eeheap –gc SOS command will show you where each garbage collection segment starts. You can correlate this with the output of !address to determine if the virtual memory is fragmented by the managed heap.
The following are some other typical conditions that can lead to fragmented virtual memory:
- Many small assemblies get loaded and unloaded all the time.
- Lots of COM DLLs loaded because of COM interop.
- Assemblies and COM DLLs are not both loaded in the managed heap. A common scenario that can lead to this is when an ASP.NET site has been compiled with the <debug> config flag enabled. This leads to every page being compiled in its own assembly, possibly fragmenting the virtual memory space enough to lead to OOMs.
Reserving memory does not require the OS to provide physical memory. Physical memory is assigned only when it is committed by the GC. If the system is running very low on physical memory, OOM exceptions should be expected. A simple way to check whether you are running low on physical memory is to open Windows Task Manager and look at the Commit Charge section on the Performance tab.
Figure 3 shows that the system has commited a total of 1981304KB and that the commit limit is 2518760KB. When total is close to limit, the system is running out of commit charge.
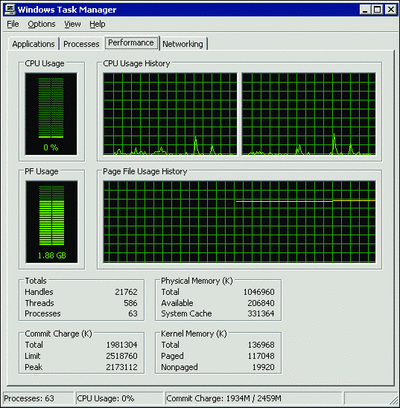
Figure 3** Viewing Commit Charge in Task Manager **(Click the image for a larger view)
The GC doesn't commit a whole segment all at once. Instead, it commits the segment in chunks as needed. (Note that how much the managed heap committed is indicated by the # Total committed Bytes counter, not # Bytes in all Heaps. This is because the Gen 0 size that is included in # Bytes in all Heaps is not the actual memory used in Gen 0, but rather its budget.)
You can use a user mode profiler, such as the CLR Profiler, to find out which objects are causing so much memory usage. In some cases, though, the overhead of running a profiler is not acceptable—for instance, when the problem needs to be debugged on a production server. In those cases, an alternative is to take memory dumps and then analyze them using the debugger. So let's take a look at how to use the debugger to analyze the managed heap.
Measure Managed Heap Size
When measuring managed heap size, the first thing you need to know is when to measure. Do you do this right before, right after, or during garbage collection? The best time to measure heap size consistently is right at the end of a Gen 2 collection because it collects the whole heap.
To look at objects at the end of a Gen 2 GC, set the following breakpoint in the debugger (for server GC, simply replace WKS with SVR):
bp mscorwks!WKS::GCHeap::RestartEE "j (dwo(mscorwks!WKS::GCHeap::GcCondemnedGeneration)==2) 'kb';'g'"
Now that you have stopped at the end of a Gen 2 GC, the next step is to look at the objects on the managed heap. These objects are the survivors and you want to find out why they survived.
The !dumpheap –stat command performs a complete dump of the objects on the managed heap. (Thus, when you have a big heap, !dumpheap may take a while to finish.) The list that !dumpheap produces is sorted by memory used by type . This means you can start analyzing from the last few lines since they are the objects that take up the most space.
In the example in Figure 4, strings take up most of the space. If strings are the issue, the problem is often easy to solve. The content of the strings may tell you where they come from.
Figure 4 !dumpheap Output
0:000>!dumpheap -stat ... [omitted] 2c6108d4 173712 14591808 MyClass.XtraGrid.Views.Grid. ViewInfo.GridCellInfo 00155f80 533 15216804 Free 7a747c78 791070 15821400 System.Collections.Specialized. ListDictionary+DictionaryNode 7a747bac 700930 19626040 System.Collections.Specialized. ListDictionary 2c64e36c 78644 20762016 MyClass.MyEditor.ViewInfo.TextEditViewInfo 79124228 121143 29064120 System.Object[] 035f0ee4 81626 35588936 Toolkit.TlkOrder 00fcae40 6193 44911636 MyStrategyObject.TimeOver[] 791242ec 40182 90664128 System.Collections.Hashtable+bucket[] 790fa3e0 3154024 137881448 System.String Total 8454945 objects
You can also look at strings in buckets. For example, you can check all strings that are between 150 to 200 in size, as shown in Figure 5. A lot of the strings in this sample are very similar. So instead of having so many strings, it is more efficient to store the common part ("PendingOrder-") and the numbers separately.
Figure 5 Viewing Strings of Specific Lengths
0:000>!dumpheap -type System.String -min 150 -max 200 Using our cache to search the heap. Address MT Size Gen 1874c4f0 790fa3e0 160 2 System.String 15.59.03: **** Transaction Completed. Account: 3344 Quantity: 50 18758218 790fa3e0 180 2 System.String PendingOrder-93344 187582cc 790fa3e0 180 2 System.String PendingOrder-12421 1875af38 790fa3e0 160 2 System.String 15.59.03: **** Transaction Complete. Account: 7722 Quantity: 2 1875be20 790fa3e0 152 2 System.String PendingOrder-10889 1875bf74 790fa3e0 152 2 System.String PendingOrder-10778 ... [omitted]
We have seen numerous scenarios where the managed heap contains the same string repeated thousands of times. The result is a big working set where much of the memory is consumed by strings. In this situation, it is often better to use string interning.
For other types that are not as obvious as string, you can use !gcroot to find out why these objects are alive (see Figure 6). Beware that the !gcroot command can take a long time if the object graph is very big.
Figure 6 Using !gcroot to Determine Why Objects Live
0:000>!gcroot 1875bf74 Note: Roots found on stacks may be false positives. Run "!help gcroot" for more info. ebx:Root:19011c5c(System.Windows.Forms.Application+ThreadContext)-> 19010b78(DemoApp.FormDemoApp)-> 19011158(System.Windows.Forms.PropertyStore)-> ... [omitted] 1c3745ec(System.Data.DataTable)-> 1c3747a8(System.Data.DataColumnCollection)-> 1c3747f8(System.Collections.Hashtable)-> 1c376590(System.Collections.Hashtable+bucket[])-> 1c376c98(System.Data.DataColumn)-> 1c37b270(System.Data.Common.DoubleStorage)-> 1c37b2ac(System.Double[]) Scan Thread 0 OSTHread 99c Scan Thread 6 OSTHread 484 ... [omitted]
Besides what survived on the managed heap, what gets allocated in Gen 0 is also part of your process's committed memory. If Gen 0 is allowed to grow big before the next garbage collection occurs, you may also observe committed memory being high due to this issue. This happens a lot more often on 64-bit Windows than on 32-bit. The !eeheap –gc SOS command will show you how big Gen 0 is.
What If Objects Survive?
Sometimes developers believe that their objects should be dead, but the GC doesn't seem to clean them up. The most common causes for this are:
- There are still strong references to the objects.
- The objects were not dead the last time their generation was collected.
- The objects are dead, but a collection for the generations in which those objects live has not been triggered yet.
For the first and the second cases, you can use !gcroot to check whether there is a strong reference keeping the object alive. One possibility people often overlook is that an object may be held alive by the finalize queue while the finalizer thread is blocked because it cannot call into a single-threaded apartment (STA) thread that is not pumping messages to run the finalizer (see support.microsoft.com/kb/828988 for more details). You can determine if this is the problem by adding the following code:
GC.Collect(); GC.WaitForPendingFinalizers(); GC.Collect();
This fixes the problem because WaitForPendingFinalizers pumps messages. However, once you confirm this is the issue, you should instead use Thread.Join since WaitForPendingFinalizers is quite heavyweight.
You can also verify whether this is the problem by running this SOS command:
!finalizequeue
And looking at the number of objects that are ready for finalization—not the number of "finalizable objects." When a finalizer is blocked, the finalizer thread shows which finalizer is currently being run, if any. (See Figure 7 for a sample finalization queue.)
Figure 7 Finalization Queue
0:003> !finalizequeue SyncBlocks to be cleaned up: 0 MTA Interfaces to be released: 0 STA Interfaces to be released: 0 ---------------------------------- generation 0 has 22 finalizable objects (002952f0->00295348) generation 1 has 0 finalizable objects (002952f0->002952f0) generation 2 has 0 finalizable objects (002952f0->002952f0) Ready for finalization 0 objects (00295348->00295348) Statistics: MT Count TotalSize Class Name 7911815c 1 20 Microsoft.Win32.SafeHandles.SafePEFileHandle 791003f4 1 20 Microsoft.Win32.SafeHandles.SafeFileMappingHandle 79100398 1 20 Microsoft.Win32.SafeHandles.SafeViewOfFileHandle 790fe034 2 40 Microsoft.Win32.SafeHandles.SafeFileHandle 790fb330 1 52 System.Threading.Thread 79111420 1 80 System.IO.FileStream 7910f304 15 300 Microsoft.Win32.SafeHandles.SafeRegistryHandle Total 22 objects 0:000>!gcroot 1875bf74 Note: Roots found on stacks may be false positives. Run "!help gcroot" for more info.
An easy way to get to the finalizer thread is by looking at the output of !threads-special. The stack shown in Figure 8 shows the state the finalizer thread is usually in—it's waiting for an event to indicate that there are finalizers to be run. When a finalizer is blocked, you will see that finalizer being run.
Figure 8 Finalizer Thread Waiting for Finalizer
0:005>!threads -special ThreadCount: 2 UnstartedThread: 0 BackgroundThread: 1 PendingThread: 0 DeadThread: 0 Hosted Runtime: no PreEmptive GC Alloc Lock ID OSID ThreadOBJ State GC Context Domain Count APT Exception 0 1 9b0 00181320 a020 Enabled 00000000:00000000 0014c260 0 MTA 3 2 c18 0018b078 b220 Enabled 00000000:00000000 0014c260 0 MTA (Finalizer) OSID Special thread type 2 cd0 DbgHelper 3 c18 Finalizer 4 df0 GC SuspendEE 0:003>~3s;k eax=00000000 ebx=00dffd20 ecx=00152ba0 edx=00000000 esi=00dffd24 edi=7ffdf000 eip=7ffe0304 esp=00dffcd4 ebp=00dffd7c iopl=0 nv up ei pl zr na po nc cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246 SharedUserData!SystemCallStub+0x4: 7ffe0304 c3 ret ChildEBP RetAddr 00dffcd0 77f4372d SharedUserData!SystemCallStub+0x4 00dffcd4 77e41bfa ntdll!NtWaitForMultipleObjects+0xc 00dffd7c 77e4b0e4 KERNEL32!WaitForMultipleObjectsEx+0x11a 00dffd94 7a01dd9a KERNEL32!WaitForMultipleObjects+0x17 00dffdb4 7a01e695 mscorwks!WKS::WaitForFinalizerEvent+0x7a ... 00dfff14 7a0983ef mscorwks!WKS::GCHeap::FinalizerThreadStart+0xbb 00dfffb8 77e4a990 mscorwks!Thread::intermediateThreadProc+0x49 00dfffec 00000000 KERNEL32!BaseThreadStart+0x34
The third cause shouldn't be an issue. Normally, unless you manually induce garbage collection, a collection is only triggered when the GC considers it to be productive. This means an object might be dead but its memory will not be reclaimed right away. But when the physical memory pressure on the system is high, the GC becomes more aggressive.
Is Fragmentation a Problem on Your Managed Heap?
When you investigate memory issues, fragmentation is a major concern. It's important because you want to know just how much space is wasted on the managed heap. The amount of fragmentation for a managed heap is indicated by how much space free objects take on the heap. You can use the !dumpheap command to find out how much free memory is available on the managed heap, like so:
0:000>!dumpheap -type Free -stat total 230 objects Statistics: MT Count TotalSize Class Name 00152b18 230 40958584 Free Total 230 objects
In this sample, the output indicates that there are 230 free objects for a total of about 39MB. Thus, the fragmentation for this heap is 39MB.
When you try to determine if fragmentation is a problem, you need to understand what fragmentation means for different generations. For Gen 0, it is not a problem because the GC can allocate in the fragmented space. For Gen 1 and Gen 2, fragmentation can be a problem. In order to use the fragmented space in Gen 1 and Gen 2, the GC would have to collect and promote objects in order to fill those gaps. But since Gen 1 cannot be bigger than one segment, Gen 2 is what you typically need to worry about.
Excessive pinning is usually the cause of too much fragmentation. In the .NET Framework 2.0 a lot of work was done to reduce fragmentation caused by pinning (see the blog entry at blogs.msdn.com/476750.aspx for more information on GC improvements in the .NET Framework 2.0), but you still may see high levels of fragmentation if the app simply pins too much. You can use an SOS command, !gchandles, to see the number of pinned handles (see Figure 9). And you can use !objsize to find out which objects are pinned, as shown in Figure 10.
Figure 10 Determining Which Objects Are Pinned
0:003> !objsize Scan Thread 0 OSTHread 1a9cDOMAIN(0024F0F0):HANDLE(WeakSh):2212fc: sizeof(01231d30) = 52 (0x34) bytes (System.Threading.Thread) DOMAIN(0024F0F0):HANDLE(Pinned):2213e8: sizeof(02234260) = 4096 (0x1000) bytes (System.Object[]) DOMAIN(0024F0F0):HANDLE(Pinned):2213ec: sizeof(02233250) = 4108 (0x100c) bytes (System.Object[]) DOMAIN(0024F0F0):HANDLE(Pinned):2213f0: sizeof(02233030) = 620 (0x26c) bytes (System.Object[]) DOMAIN(0024F0F0):HANDLE(Pinned):2213f4: sizeof(02232020) = 5276 (0x149c) bytes (System.Object[]) DOMAIN(0024F0F0):HANDLE(Pinned):2213f8: sizeof(0123118c) = 12 (0xc) bytes (System.Object) DOMAIN(0024F0F0):HANDLE(Pinned):2213fc: sizeof(02231010) = 102632 (0x190e8) bytes (System.Object[])
Figure 9 Checking the Number of Pinned Handles
0:002> !gchandles GC Handle Statistics: Strong Handles: 16 Pinned Handles: 4 Async Pinned Handles: 0 Ref Count Handles: 0 Weak Long Handles: 0 Weak Short Handles: 1 Other Handles: 0 Statistics: MT Count TotalSize Class Name 790f9d10 1 12 System.Object 790fb760 1 28 System.SharedStatics 791077ec 1 48 System.Reflection.Module 790fc894 2 48 System.Reflection.Assembly 790fad68 1 72 System.ExecutionEngineException 790facc4 1 72 System.StackOverflowException 790fac20 1 72 System.OutOfMemoryException 790fb9c0 1 100 System.AppDomain 790fb330 2 104 System.Threading.Thread 790fd91c 4 144 System.Security.PermissionSet 790fae0c 2 144 System.Threading.ThreadAbortException 79124314 4 8744 System.Object[] Total 21 objects
Fragmentation in the LOH is by design because we don't compact the LOH. This does not mean allocating on the LOH is the same as malloc using the NT heap manager! Due to the nature of how the GC works, free objects that are adjacent to each other are naturally collapsed into one big free space, which is available for large object allocation requests.
Measuring Time Spent on Garbage Collection
Developers often want to know how much time the GC takes for each collection. This is usually important data in a soft real-time scenario where there are some constraints on, for instance, the response time that the application must respect. And, of course, this is an important consideration, since too much time spent on garbage collection means CPU time taken away from actual processing.
The easiest way to get an idea of how much time garbage collection takes is to look at the % Time in GC performance counter. This counter is updated at the end of a collection and indicates the ratio of the time spent in the GC just finished divided by the time since the end of the last GC. If no collection happens during the sampling interval, the counter is not updated and you get the same value you got last time. Since you know the sampling interval in the performance monitor application (the default sampling interval in PerfMon is 1 second), you can roughly calculate the time.
Figure 11 gives some sample garbage collection data. In it, you'll see that Gen 0 collections occurred in the second and the third intervals. Since we don't know exactly when the collection happened during these intervals, this technique isn't 100 percent accurate. But it is useful for estimating time spent in the GC.
Figure 11 Sample GC Data
| Timestamp (Interval) | # Gen 0 Collections | # Gen 1 Collections | # Gen 2 Collections | % Time in GC |
|---|---|---|---|---|
| 1 | 9 | 3 | 1 | 10 |
| 2 | 10 | 3 | 1 | 1 |
| 3 | 11 | 3 | 1 | 3 |
| 4 | 11 | 3 | 1 | 3 |
Considering this sample, here's the worst case scenario for the eleventh GC. Say the tenth Gen 0 collection finished at the beginning of the second interval and the eleventh Gen 0 collection finished at the end of the third interval. That means the time between the end of the two collections is about two sampling intervals, or two seconds. The % Time in GC counter shows 3 percent, and so the eleventh Gen 0 collection took 3 percent of 2 seconds (or 60ms).
Investigating High CPU Usage
When a collection is happening, CPU usage is supposed to be high so the GC can complete as quickly as possible. Figure 12 shows an example of when CPU usage is pretty much always caused by collections. All the spikes in the % Process Time counter correspond directly to a change in % Time in GC. Obviously, this should never happen in reality since, in addition to the GC using the CPU, other processes will also use the CPU. To figure out what else is consuming CPU cycles, you can use a CPU profiler to look at the functions that consume the most CPU time.
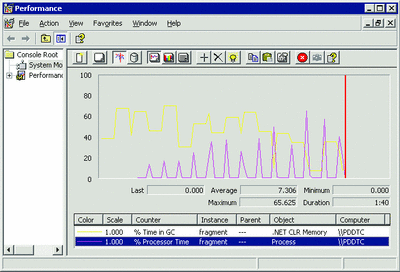
Figure 12** When CPU Usage is Caused by Collections **(Click the image for a larger view)
If indeed you are seeing too much CPU power being consumed by the GC, there are too many collections taking place or collections are taking too long. Consider the case when collections are triggered by allocations. The allocation rate is the major factor that determines how often collections are triggered.
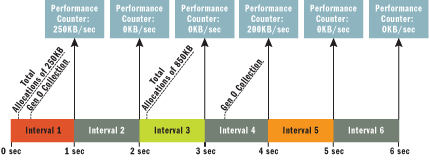
Figure 13** Less Accurate Data when Collections Are Spread Out **
When a collection begins, the value of the Allocated Bytes/sec counter is updated by adding the number of allocated bytes in Gen 0 and the LOH. Since the counter is expressed as a rate, the actual number you see is the difference between the last two values divided by the time interval. For example, Figure 13 illustrates what happens if the sampling rate is 1 second and a collection occurs only after some intervals have passed. When the second collection occurs, the performance counter is updated like so:
Allocation = 850-250=600KB Alloc/Sec = 600/3=200KB/sec
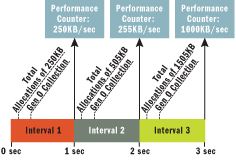
Figure 14** More Accurate Data if Collection Occurs Frequently **
Even though the application keeps allocating, the performance counter doesn't reflect that because it doesn't get updated until the next collection. If a collection happens more frequently, you get a better picture (see Figure 14).
A common mistake is to consider the allocation rate as the measure of how long garbage collections take—how long a collection takes is decided by how much memory the GC has to go through. Since the GC only goes through survived objects, a long collection means many objects survived. If you encounter this, use the technique we discussed earlier to determine why you have so many survivors.
Send your questions and comments to clrinout@microsoft.com.
Claudio Caldato is a Program Manager for Performance and Garbage Collector on the Common Language Runtime team at Microsoft.
Maoni Stephens is the main developer working on the Garbage Collector in the Common Language Runtime team at Microsoft. Before joining CLR, Maoni spent several years in the Operating System group at Microsoft.