XmlLite
A Small And Fast XML Parser For Native C++
Kenny Kerr
This article discusses:
|
This article uses the following technologies: XML, C++ |
Contents
Why a New XML Parser?
COM "Lite"
Reading XML
Writing XML
Working with Streams
Text Encoding when Reading
Text Encoding when Writing
Dealing with Large Data Values
Security Considerations
Conclusion
Despite the ongoing success of the .NET Framework, Microsoft is still serious about native C++ development. This is demonstrated by the introduction of XmlLite, a high-performance, low-overhead XML reader and writer geared for applications written in native C++.
Managed code has broad support for XML through the System.Xml namespace, and traditional Visual Basic® and C++ applications that rely on COM have access to similar functionality from Microsoft® XML Core Services (MSXML). However, these don't offer very attractive options for native C++ developers who want a fast and lean XML parser. Enter XmlLite.
In this article, I'll explore what you can do with XmlLite. First, however, to set expectations, I want to quickly review what XmlLite does not provide-at least, not in this initial release. For starters, it doesn't provide a Document Object Model (DOM) implementation, nor does it provide XML Schema or Document Type Definition (DTD) validation. It also lacks support for high-level facilities like cursor-based navigation (such as XPath), style sheets, and serialization. Any gaps, however, can be filled as needed with functionality built on top of XmlLite in the same way that almost all of the XML functionality in the Microsoft .NET Framework is built on top of the XmlReader and XmlWriter classes.
So what does XmlLite provide? Briefly, it provides a non-cached, forward-only parser (that delivers a pull programming model) and a non-cached, forward-only XML generator. Both have proven to be very valuable functions.
Why a New XML Parser?
Developers grow accustomed to libraries they use every day, and with their extensive use of XML, they are certainly going to ask some tough questions about a brand new XML parser. To appreciate the value of this new parser, let's first consider what the XML parser landscape looks like today.
Naturally, if an application is already making use of the .NET Framework, then the decision is usually a simple one: just use System.Xml. As a testament to this, the design of XmlLite is based on the design of the XmlReader and XmlWriter classes in the .NET Framework. There are usually no advantages to using XmlLite from managed applications written in C++. After all, XmlLite's functionality is much lighter than that provided by the XmlReader and XmlWriter classes. (The table in Figure 1 outlines how the main types in XmlLite map to those in the .NET Framework.) If, on the other hand, an application makes use of native code exclusively, then MSXML has traditionally been the solution of choice as far as Microsoft technology is concerned.
Figure 1 XmlLite Classes Map to the .NET Framework
| XmlLite | .NET Framework |
|---|---|
| IXmlReader interface | XmlReader class |
| IXmlWriter interface | XmlWriter class |
| XmlReaderProperty enum | XmlReaderSettings class |
| XmlWriterProperty enum | XmlWriterSettings class |
| CreateXmlReaderInputWithEncodingCodePage CreateXmlReaderInputWithEncodingName CreateXmlWriterOutputWithEncodingCodePage CreateXmlWriterOutputWithEncodingName |
Encoding class |
| XmlNodeType enum | XmlNodeType enum |
MSXML offers two very different XML parsers. The first is a DOM implementation that has been available in various incarnations. If you are working with relatively small XML documents and require random access to the XML documents for in-memory reads and writes, then the DOM implementation is a reasonable choice. Later versions of MSXML introduced an implementation of Simple API for XML (SAX2). Whether it is actually "simple" is debatable. When using SAX2, before you even get off the ground, you need to implement at least two COM interfaces-one that receives notifications of the various nodes in the XML document and one that receives notifications of parsing errors.
The reason the SAX2 implementation was added to MSXML was because, unlike the DOM implementation, the SAX2 parser reads an XML document as a stream and notifies you when various nodes have been reached. This means that your application's memory consumption does not grow along with the size of the document you are parsing.
The problem with SAX2, and the reason why the .NET Framework does not provide an implementation of it, is the inherent complexity of the SAX2 model. It requires interfaces or events to be implemented and forces the developer to employ a more indirect programming model, requiring the developer to manage additional state that inevitably complicates the application. Instead, the XmlReader and XmlWriter classes in the .NET Framework, as well as XmlLite's IXmlReader and IXmlWriter interfaces, provide a straightforward parser that can be used directly within a function without having to manage any external state or notifications.
Due to the simplicity of its design, XmlLite manages to provide considerably better performance, even when compared to the MSXML SAX2 implementation. Although the SAX2 parser is better at handling large documents than the DOM implementation, it pales in comparison to XmlLite.
Simply put, XmlLite outperforms MSXML and it is much easier to use from native C++. MSXML will remain the most viable solution for Visual Basic and COM-based scripting languages, but now native Visual C++® finally has an XML parser designed specifically for it. Although XmlLite is included with Windows Vista™ and later versions, an update is also available for 32-bit and 64-bit versions of Windows® XP and Windows Server® 2003. Since COM registration is not involved, this update package should not cause the headaches that MSXML has typically posed with regard to installation and versioning.
COM "Lite"
XmlLite is not just a catchy name; it is, in fact, a light XML parser. XmlLite takes the best of COM, namely the programming discipline and conventions, and drops the complex and potentially unnecessary parts, such as the COM registration, runtime services, proxies, threading models, marshaling, and so on.
Functions exported from XmlLite.dll create the XML reader and writer. You gain access to them by linking to XmlLite.lib and including the XmlLite.h header file from the Windows SDK. The resulting COM-style interfaces use the familiar IUnknown interface methods for lifetime management. The COM IStream interface also plays a part and represents storage. Other than that, there are no dependencies on COM; you do not need to register any COM classes or even call the obligatory CoInitialize function. The Active Template Library (ATL) CComPtr class takes care of the small slice of COM that remains. You do, however, need to concern yourself with thread safety, as XmlLite is not thread-safe for the sake of performance in single-threaded scenarios.
I use the COM_VERIFY macro in the following samples to clearly identify where methods return an HRESULT that needs to be checked. You can replace this with appropriate error handling-whether that is throwing an exception or returning the HRESULT yourself.
Reading XML
XmlLite provides the CreateXmlReader function that returns an implementation of the IXmlReader interface:
CComPtr<IXmlReader> reader;
COM_VERIFY(::CreateXmlReader(__uuidof(IXmlReader),
reinterpret_cast<void**>(&reader),
0));
Although optional, the CComPtr class template ensures that the interface pointer is released promptly.
CreateXmlReader accepts an interface identifier (IID) as well as a pointer to a void pointer. This is a common pattern in COM programming, allowing the caller to specify the type of interface pointer to return. My example uses the __uuidof operator, which is a Microsoft-specific keyword that extracts the GUID associated with a type. In this case, it is used to retrieve the IID for the interface. The final argument to CreateXmlReader accepts an optional IMalloc implementation to allow the caller to control memory allocations.
Once you have created the reader, you need to indicate the storage that the reader will use as input. The IStream interface represents storage, letting you use XmlLite with any stream implementation you might devise:
CComPtr<IStream> stream;
// Create stream object here...
COM_VERIFY(reader->SetInput(stream));
(I'll discuss streams later in this article.)
Once you have set the input for the XML reader, you can read with repeated calls to the Read method. The Read method accepts an optional argument that returns the node type on each successful call. The Read method returns S_OK to indicate that the next node has been successfully read from the stream and S_FALSE to indicate that the end of the stream has been reached. Here's an example of how you can enumerate through the nodes:
HRESULT result = S_OK;
XmlNodeType nodeType = XmlNodeType_None;
while (S_OK == (result = reader->Read(&nodeType)))
{
// Get node-specific info
}
To enumerate the attributes of the current node, you use the MoveToFirstAttribute and MoveToNextAttribute methods. Both return S_OK if the reader was successfully repositioned and S_FALSE if no more attributes are present. The following example illustrates how you can enumerate through the attributes for a given node:
for (HRESULT result = reader->MoveToFirstAttribute();
S_OK == result;
result = reader->MoveToNextAttribute())
{
// Get attribute-specific info
}
When you call the IXmlReader's Read method, it automatically stores any node attributes in an internal collection. This allows you to move the reader to a specific attribute by name using the MoveToAttributeByName method. However, it is usually more efficient to enumerate the attributes and store them in an application-specific data structure. Note that you can also determine the number of attributes in the current node using the GetAttributeCount method.
Once you have settled on a node or attribute, getting its information is straightforward. This example demonstrates how you can get the namespace URI and local name for a given node:
PCWSTR namespaceUri = 0;
UINT namespaceUriLength = 0;
COM_VERIFY(reader->GetNamespaceUri(&namespaceUri,
&namespaceUriLength));
PCWSTR localName = 0;
UINT localNameLength = 0;
COM_VERIFY(reader->GetLocalName(&localName,
&localNameLength));
All of the IXmlReader methods that return string values follow this pattern. The first argument accepts a pointer to a wide-character pointer constant. The second argument is optional and if it's not zero, it will return the length of the string measured in characters excluding the null terminator.
Here is another example of the emphasis on performance. The string pointers returned from IXmlReader methods are only valid until you move the reader to another node or invalidate the current node in some other way, such as by setting a new input stream or releasing the IXmlReader interface. In other words, the IXmlReader is not returning a copy of the string to the caller.
Unlike its counterpart in the .NET Framework, IXmlReader does not provide any methods for reading typed content. If a particular element or attribute contains a number or date, for example, you need to first get its string representation and then convert it yourself as necessary. Many of the other helper methods present in the XmlReader class of the .NET Framework are also not present in IXmlReader, but can be written as helper functions. XmlLite certainly conforms to the C++ philosophy of minimal interface design.
Figure 2 shows the objects and abstractions involved in reading an XML document with IXmlReader. Keep in mind, though, that IStream could abstract any storage, and the file shown here is just a common example.
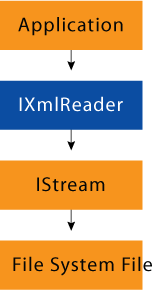
Figure 2** Reader **
Writing XML
XmlLite provides the CreateXmlWriter function to return an implementation of the IXmlWriter interface:
CComPtr<IXmlWriter> writer;
COM_VERIFY(::CreateXmlWriter(__uuidof(IXmlWriter),
reinterpret_cast<void**>(&writer),
0));
Once you have created the writer, you need to indicate the storage that the writer will use as output:
CComPtr<IStream> stream;
// Create stream object here
COM_VERIFY(writer->SetOutput(stream));
Before beginning to write, you can modify the writer properties. The XmlWriterProperty enum defines the properties that are available. You might, for example, want to specify whether the XML output is indented for human readability, as can be done with the SetProperty method:
COM_VERIFY(writer->SetProperty(XmlWriterProperty_Indent, TRUE));
You can then start writing to the underlying stream using IXmlWriter methods. XmlLite supports XML fragments. If you are planning to write a complete XML document, you should start by calling the WriteStartDocument method, which takes care of writing the XML declaration. The declaration is dependent on the encoding in use but the default is UTF-8, which should be suitable in most cases. (I'll cover text encoding in a moment.) A number of WriteXxx methods are provided for writing various node types, attributes, and values.
Consider this example:
COM_VERIFY(writer->WriteStartDocument(XmlStandalone_Omit));
COM_VERIFY(writer->WriteStartElement(0, L"html",
L"https://www.w3.org/1999/xhtml"));
COM_VERIFY(writer->WriteStartElement(0, L"head", 0));
COM_VERIFY(writer->WriteElementString(0, L"title", 0, L"My Web Page"));
COM_VERIFY(writer->WriteEndElement()); // </head>
COM_VERIFY(writer->WriteStartElement(0, L"body", 0));
COM_VERIFY(writer->WriteElementString(0, L"p", 0, L"Hello world!"));
COM_VERIFY(writer->WriteEndDocument());
The WriteStartDocument method handles writing the XML declaration to the stream. Its single argument accepts a value from the XmlStandalone enum, indicating whether the standalone document declaration appears, and if so, what value it holds. When writing an XML fragment, you typically omit the call to WriteStartDocument.
The WriteStartElement method accepts three arguments: the first specifies an optional namespace prefix for the element, the second specifies the local name of the element, and the third specifies the optional namespace URI. WriteElementString is one of the rare convenience methods provided by XmlLite. The following code for writing the XHTML document's title is equivalent to the WriteElementString used in the previous example:
COM_VERIFY(writer->WriteStartElement(0, L"title", 0));
COM_VERIFY(writer->WriteString(L"My Web Page"));
COM_VERIFY(writer->WriteEndElement());
Clearly, the WriteElementString method is not strictly necessary, but it certainly is useful.
Finally, the WriteEndDocument method closes the document. You may have noticed that the body and html elements were not explicitly closed. WriteEndDocument automatically closes any open elements. For that matter, releasing the writer also closes any remaining elements. However, the practice of not explicitly closing such elements can lead to bugs if you're not careful, as the lifetime of the stream and the lifetime of the writer can often be different. Speaking of which, if you need to ensure that all writes have been written to the underlying stream, just call IXmlWriter's Flush method.
Figure 3 shows the flow of objects and abstractions involved in writing an XML document with IXmlWriter. Keep in mind that IStream could abstract any storage and the file here is just a common example.
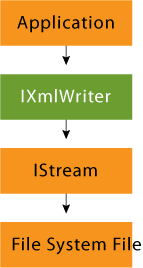
Figure 3** Writer **
Working with Streams
Thus far, I haven't talked much about streams. Unlike some of the more full-featured XML libraries, XmlLite does not provide any supporting functionality for reading from and writing to common storage locations (such as files or over network protocols). Because of this, you need to provide an IStream implementation for whatever storage you want to read from or write to. Implementing the IStream interface is not complicated, but in many cases, you won't need to do this since implementations may already exist.
The CreateStreamOnHGlobal function provides an IStream implementation backed by virtual memory. The first argument is an optional memory handle created using the GlobalAlloc function. You can, however, simply pass zero and CreateStreamOnHGlobal will create a memory object for you. The following example creates an IStream implementation that is backed by system memory and will dynamically grow as needed:
CComPtr<IStream> stream;
COM_VERIFY(::CreateStreamOnHGlobal(0, TRUE, &stream));
Freeing the stream will free the memory.
The SHCreateStreamOnFile function provides another useful IStream implementation. It creates an IStream backed by a file:
CComPtr<IStream> stream;
COM_VERIFY(::SHCreateStreamOnFile(L"D:\\Sample.xml",
STGM_WRITE | STGM_SHARE_DENY_WRITE,
&stream));
Text Encoding when Reading
Although XmlLite, by default, uses UTF-8 for writing and when attempting to detect the text encoding when reading, you can override this behavior. First, let's take a look at what you get automatically. Given a stream, IXmlReader will detect encoding hints via a byte order mark as a preamble to the XML. IXmlReader will also honor any encoding specified in the XML declaration. These characteristics are both expected of any XML parser. If you have an input stream that perhaps does not have any encoding information defined and XmlLite cannot heuristically determine the encoding in use, then you can direct IXmlReader to a specific encoding given a code page or encoding name.
Instead of passing the stream directly to the IXmlReader, you can create an XML reader input object under the guise of the IXmlReaderInput interface. Two functions are provided for creating the input object wrapping the input stream. The CreateXmlReaderInputWithEncodingCodePage function accepts an encoding in the form of a codepage number. The CreateXmlReaderInputWithEncodingName function accepts an encoding using its canonical name. Apart from this, the functions have identical signatures. To recap, ordinarily you would set the input stream for the XML reader as follows:
CComPtr<IStream> stream;
// Create stream object here
COM_VERIFY(reader->SetInput(stream));
To override the encoding, change the code to this:
CComPtr<IStream> stream;
// Create stream object here
CComPtr<IXmlReaderInput> input;
COM_VERIFY(::CreateXmlReaderInputWithEncodingName(stream,
0, // default allocator
L"ISO-8859-8",
TRUE, // hint
0, // base URI
&input));
COM_VERIFY(reader->SetInput(input));
The first argument indicates the stream that the XML reader will read from. The second argument accepts an optional IMalloc implementation. If provided, it overrides the XML reader's own implementation. The third argument specifies the encoding name. The documentation at msdn2.microsoft.com/ms752827.aspx lists the encodings natively supported; to support other encodings, you can provide an IMultiLanguage2 interface implementation. The next argument indicates whether the specified encoding must be used or whether it is merely a hint. Specifying TRUE instructs the parser to attempt to use the suggested encoding but if it fails it is free to attempt to determine the actual encoding heuristically. Specifying FALSE instructs the parser to attempt the suggested encoding and return an error if it does not match the input stream. The next argument accepts an optional base URI that may be used for resolving external entities. And the last argument returns an interface pointer representing the input object to pass to the SetInput method.
Text Encoding when Writing
The XML writer will determine the encoding to use based on the object passed to the SetOutput method. If the object implements the IStream interface, or even the limited ISequentialStream interface, the XML writer will employ UTF-8 encoding. You can create an XML writer output object to override this behavior. Two functions are provided for creating the output object wrapping the output stream. The CreateXmlWriterOutputWithEncodingCodePage function accepts an encoding in the form of a codepage number and the CreateXmlWriterOutputWithEncodingName function accepts an encoding using its canonical name. Apart from this, the functions have identical signatures. Ordinarily, you would set the output stream for the XML writer like this:
CComPtr<IStream> stream;
// Create stream object here
COM_VERIFY(writer->SetOutput(stream));
To override the default encoding, write this code:
CComPtr<IStream> stream;
// Create stream object here
CComPtr<IXmlWriterOutput> output;
COM_VERIFY(::CreateXmlWriterOutputWithEncodingName(stream,
0,
L"ISO-8859-8",
&output));
COM_VERIFY(writer->SetOutput(output));
The first argument indicates the stream that the XML writer will write to. The second argument accepts an optional IMalloc implementation. If provided, it overrides the XML writer's own implementation. The third argument specifies the encoding name. The last argument returns an interface pointer representing the output object to pass to the SetOutput method.
Dealing with Large Data Values
To limit memory usage when reading large data values, the XML reader provides a mechanism for reading values in chunks. The IXmlReader ReadValueChunk method will read up to a set maximum number of characters, moving the reader forward in anticipation of subsequent calls. This example illustrates how you might call ReadValueChunk repeatedly to read a large data value:
CString value;
WCHAR chunk[256] = { 0 };
HRESULT result = S_OK;
UINT charsRead = 0;
while (S_OK == (result = reader->ReadValueChunk(chunk,
countof(chunk),
&charsRead)))
{
value.Append(chunk, charsRead);
}
ReadValueChunk returns S_FALSE when no more data is available. In this example, I am writing the chunks to a CString object. This is only to illustrate how chunk lengths are managed and would obviously defeat the benefits of chunking in practice.
Security Considerations
XML-centric apps invariably have to deal with XML from untrusted sources. XmlLite provides a number of facilities for protecting your applications from known and future vulnerabilities.
XML documents can contain references to external entities. Some XML parsers resolve these automatically. Although potentially useful, this approach can lead to exploits if the XML resolver is not carefully written to mitigate various threats. XmlLite does not automatically resolve external entities, nor does it provide an XML resolver. To provide your own implementation (if necessary), implement the IXmlResolver interface and use the XmlReaderProperty_XmlResolver property with the IXmlReader SetProperty method to instruct the reader to use your resolver.
XML documents may also contain DTD processing instructions. Although XmlLite does not support document validation-with either XML Schema or DTD-it does support DTD entity expansion and default attributes. Since these DTDs can contain references to external entities, they may open up your application to various attacks. XmlLite disables DTD processing by default. You can allow DTD processing by setting the XmlReaderProperty_DtdProcessing property to the DtdProcessing_Parse value. There is also built-in mitigation for the DTD entity expansion attack (also known as the billion laughs attack), controlled by XmlReaderProperty_MaxEntityExpansion. The default for this property is 100,000.
Another way attackers can exploit applications using XML is by creating documents with very long names. If not prevented, this may use up tremendous amounts of memory and allow denial of service attacks. I have already hinted at ways that can be done. One obvious way to mitigate such a threat is to read large data values in chunks as the previous section described. Another useful technique is to provide a custom IMalloc implementation with restrictions on memory allocations. Given an input stream supporting random access, you can also instruct the XML reader to avoid caching attributes using the XmlReaderProperty_RandomAccess property. This reduces the amount of memory used to read a start element tag, but may also slow down parsing as the parser must seek back and forth to retrieve the various attribute values upon request.
Excessively deep XML hierarchies can also use up system resources quickly. To stop attackers from providing XML documents that have excessively deep hierarchies, you can use the XmlReaderProperty_MaxElementDepth property to limit the depth that the parser will allow. This property defaults to 256.
Conclusion
XmlLite provides a powerful XML parser for your native C++ applications. It emphasizes performance, is aware of the system resources it uses, and supports a great deal of flexibility in controlling these characteristics. With support for all common text encoding, XmlLite is a very useful and practical tool that can simplify XML usage in native C++ applications. For more information, see the XmlLite documentation at msdn.microsoft.com/library/ms752872.aspx.
Kenny Kerr is a software craftsman specializing in software development for Windows. He has a passion for writing and teaching developers about programming and software design. Reach Kenny at https://weblogs.asp.net/kennykerr.