Migration
Convert A Java Web Application To ASP.NET Using JLCA
Brian Jimerson
This article discusses:
|
This article uses the following technologies: ASP.NET, JLCA, and C# |
Code download available at: JLCA 2007_05.exe(157 KB)
Contents
About the JLCA
Locating Resources
Handling Input/Output APIs
Logging
Collections
Filters and HTTP Handlers
Source Tree and Naming Conventions
When to Refactor for Conventions
Directory Layout and Namespaces
Properties
Pascal-Casing Method Names
Conclusion
The typical software development cycle follows a straightforward model: gather requirements, design the application, write the code, test the software, and deploy it. Once in a while, though, a new development project is incepted simply based on the platform to which the customer wants to deploy the app. In this case, an existing application’s code base can be converted, or ported, to the desired platform.
In this article, I walk you through converting a Java Web application to an ASP.NET application implemented in C#. This article is based on an actual project I worked on. In that project, we had an existing Java-based application and a customer who wanted an ASP.NET version of it. I begin by introducing you to the Microsoft® Java Language Conversion Assistant (JLCA) and I demonstrate common development paradigms that do not have direct counterparts in the two platforms, such as:
- Input/output
- Resource resolution
- Source tree layout and naming conventions
- Leveraging the executing environment
This application is implemented as a SOAP-compliant Web service, with a traditional relational database persistent store. I won’t discuss the actual Web service presentation layer and SOAP interfaces, but rather the application that powers it. Sample code for this article is available for download.
About the JLCA
The JLCA is a tool used to convert a Java application into a C# application. The tool has shipped with Visual Studio® since Visual Studio .NET 2003. Currently in version 3.0, the JLCA is included with Visual Studio 2005 and is also available as a free download from the JLCA home page.
Version 3.0 includes enhancements to convert Java artifacts, such as Servlets and Java Server Pages (JSPs), as well as rich-client applications that use Swing or the Abstract Windowing Toolkit (AWT). In practice, the JLCA provides a very good place to start a conversion, but it will not successfully complete the entire process. So don’t expect this to be completely hands-free—you will still need to do some manual resolution of converted items after using the tool.
To get started with the JLCA in Visual Studio 2005, launch the wizard by clicking File | Open | Convert. The wizard’s screens are quite self-explanatory. The key piece of information you’ll need to enter, as shown in Figure 1, is the root directory of your existing Java project.
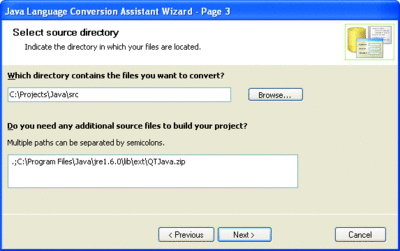
Figure 1** Enter the Root Java Directory in the JLCA Wizard **(Click the image for a larger view)
The JLCA then proceeds to convert the Java source code to C#. The process doesn’t take too long. Anecdotally, our code base with approximately 100 class files took less than 10 minutes for the conversion to complete—just enough time to get a cup of coffee. Of course, this number will vary for different projects and systems.
After the conversion process is finished, the JLCA creates an HTML report of errors and warnings. These items are also entered into the generated C# code as comments by the offending members. To help you, each item also contains a hyperlink for more information on resolving the problem.
Many of the warnings can be safely ignored. They simply note differences in behavior between Java and C#, such as the warning that states: "Type castings between primitive types may have different behavior." Still, you should look at each warning to ensure these different behaviors won’t affect your application.
When you first look at the conversion report, there may seem to be an overwhelming number of issues reported. In this case, there were 816 errors and 16 warnings. Most of the errors, however, could be categorized into one of three categories and addressed pretty easily. The three categories they fell into were:
- Members for which there are simply no C# or Microsoft .NET Framework equivalents.
- Popular third-party Java libraries that don’t have direct equivalents in the .NET Framework (such as Hibernate and log4j).
- Items that deal with class loading or resource resolution.
It is also worth noting that the JLCA does not seem to attempt to resolve imported packages (or using namespace statements) that it can’t find. Instead, it just passes them through to the generated C# code. If you were to try to compile your new C# application, you would probably get quite a few more compiler errors than the conversion report indicates.
Not to worry, though. As stated previously, the bulk of these errors falls into the same recurring patterns and can be addressed en masse. I look at resolutions to these common errors in the following sections, and I cover the other necessary tasks to make your converted app a true C# application.
Locating Resources
The process of resource locating—specifically, finding and loading file resources—in Java differs significantly from resource locating in C#. Java uses a class loader to load and parse a class definition at run time. Part of the responsibility of a class loader is to manage the context of a class and provide environmental facilities for classes loaded by it. In Java, a special type of environment variable, called a classpath, is used by a class loader to locate resources. A classpath is similar to a path environment variable in that it defines where a class loader should look for other classes and resources. An application that wishes to load another class or resource can do so by telling the class loader the location of the file relative to the classpath.
A very common approach to resource resolution in Java is to use a special type of file called a properties file for configurable information, such as connection or host information, paths to other resources, localization strings, and credentials to use for authentication. A properties file contains name=value pairs, which are separated by a new line. This format is very similar to INI files, but without the sections.
Furthermore, resource locating is always performed using file system notations—whether they are actually located in the file system. This alleviates the developer’s burden of having to know how the application is being deployed. Other types of resources, such as images and binary files, are located and loaded in this same manner. Here’s an example of locating and using a properties file in Java:
InputStream is = this.getClass().getResourceAsStream(
“/application.properties”);
Properties properties = new Properties();
properties.load(is);
String myValue = properties.getProperty(“myKey”);
On the contrary, resources in the .NET Framework can be deployed and loaded in two different ways: as an embedded, binary resource with an assembly or as a file in the local file system.
The appropriate technique for accessing a resource depends on its location. For example, if it is a file system resource, you might do something like the following:
string fileName = Path.Combine(Path.GetFullPath(
@”..\config\”), “properties.xml”);
Stream fileStream = File.Open(fileName, FileMode.Open);
//Do something with the stream
If, however, the resource is embedded in an assembly, your approach will be more like this:
Assembly assembly = Assembly.GetExecutingAssembly();
Stream fileStream = assembly.GetManifestResourceStream(
GetType(), “properties.xml”);
//Do something with the stream
My team’s application was written with the assumption that it would not have to know how the resource was deployed to be able to resolve. Since there are many resources being loaded throughout the application, it would have taken a lot of effort to analyze each resource being loaded, determine how the resource is deployed, and then modify the code to load it appropriately. So instead we created a utility class called ResourceLocator.
ResourceLocator was designed to approximate a Java class loader’s ability to resolve a resource based on its classpath. Since all of the calls to load resources were written with this approach, it seemed like the least intrusive method of conversion. All we would need to do after ResourceLocator was written would be to change calls from Class.getResourceAsStream to ResourceLocator.LocateResource. This could be done with a simple find and replace in Visual Studio.
Basically, ResourceLocator takes the name and relative path of the resource to find and then attempts to find it by walking through available assemblies and the local file system. There are also overloaded methods that provide more granular control, such as specifying the order in which areas should be searched and choosing to search only assemblies or the file system. The source for ResourceLocator is included in the code samples on the MSDN® Magazine Web site.
You might be thinking that it is very costly to look at all of the available locations to find a resource, and this is certainly true. But all of the resources located and loaded in the application were then cached. This means that each resource is only loaded once during the execution of the application, and thus this overhead is mitigated (though it does increase memory consumption, which could be an issue if there are a large number of resources being loaded). Therefore, we decided the trade-off was acceptable, considering how many code changes that it saved us. These types of changes can also be modified over time, starting with the simple solution to get the port up and running quickly, and then slowly but surely changing the implementation to better match design and implementation guidelines for .NET-based applications.
Handling Input/Output APIs
There are several differences between the I/O APIs in Java and those in .NET that need to be dealt with after conversion. One significant difference is that .NET I/O streams are bidirectional, whereas Java I/O streams are unidirectional. This means that in .NET programming, you can, in theory, read from and write to the same stream. In Java, however, you can only read from a stream or write to a stream, but not both to the same stream. This difference doesn’t pose much difficulty during the conversion since this is a widened difference and the .NET streams provide at least as much functionality as their Java counterparts.
If the safety of unidirectional streams needs to be maintained, then the .NET I/O readers and writers can be utilized. These will wrap an underlying stream to provide reading or writing functionality. The result will be I/O operations that are programmatically similar to Java I/O operations.
For our application, direct access to streams is sufficient. The JLCA properly converts I/O operations, so no changes are necessary for compilation. However, we did carefully review the converted code since there was a significant opportunity for logic errors in these low-level operations.
Logging
Logging concerns the ability to write messages to a destination at particular points of execution in the code, such as caught exceptions, areas in logic where debugging information might be useful, and configuration information being loaded. Java and the .NET Framework both provide powerful frameworks for logging information, but their designs and implementations are very different.
In Java, application logging is usually accomplished through the Apache Software Foundation (ASF) log4j framework or the Java Logging APIs distributed with recent versions of the Sun Microsystems Java Development Kit (JDK). The Java Logging API is very similar in execution to log4j and, therefore, the two frameworks can be applied interchangeably for the purposes of this discussion. For .NET-based applications, the Microsoft Enterprise Library provides a robust application block for logging, called the Logging Application Block (see the Microsoft Logging Application Block homepage).
The standard logging frameworks in both Java and .NET provide strong capabilities, with support for design-time configuration, a host of destinations for logs (such as databases, files, and e-mail recipients), and so on. Note, however, that the API designs are different and thus need some manual intervention on your part during conversion.
To better understand the differences in the APIs, consider the two code snippets shown in Figure 2. These demonstrate a common logging scenario performed in Java and in C#. The snippet using log4j creates a static instance of a Log object from the getLog factory method and assigns it to the MyClass category. The code then prints some information to the Log at a debug level. The C# snippet, which uses the Logging Application Block, creates a new instance of a LogEntry class. This represents an entry in the destination log. The code then assigns the log entry a priority of 2, sets the category as Debug, and provides a message. It is then written to the Logger class.
Figure 2 Logging in Java and in C#
Java with log4j
private static final Log log = Logger.getLog(MyClass.class);
...
//Somewhere else in the class
log.debug(“Printing some debug information.”);
C# with the Logging Application Block
Logger.Write(”Printing some debug information.”, “Debug”);
It is important to note that logging in both platforms is controlled by external configuration. Information such as logging destinations, selective filtering of log messages, and formatting of log entries is contained in this configuration. I’ve intentionally left the configuration out of this example, as it isn’t pertinent to the discussion.
Looking at these two examples, you can see that they perform very similar functions, but they are achieved in different ways. The log4j example uses the category to determine if a message is logged (based on its level) and where it is logged to. The Logging Application Block, meanwhile, uses a combination of filters for priorities and categories to determine what is logged.
The Logger class provides several overloaded Write methods, each with varying levels of flexibility (including an overload that allows you to provide a LogEntry instance which has lots of knobs and controls for tweaking how the information is logged). However, given the simple overload that’s used in Figure 2, we were able to accomplish the bulk of the conversion process with searching and replacing, in combination with regular expressions.
Logging is a very resource-intensive process and care needs to be taken so that it doesn’t affect your application’s performance. In the end, it only took a few hours to search and replace the logging invocations in the application.
Collections
Both the .NET Framework and Java offer a strong collections API. Both are very extensible and cover most of the scenarios you might encounter when working with collections. Let’s look closely at two frequently used types of collections: lists and dictionaries.
Lists are collections that can be accessed by an index. They are ordered collections and can be thought of as a kind of one-dimensional array. Dictionaries, on the other hand, are collections of name and value pairs. The name is the key used to access values in the collection. Note that there is not necessarily guaranteed ordering in dictionaries.
Figure 3 lists the equivalent C# and Java implementations for list and dictionary. The JLCA does a very good job of converting these Java collection classes to their .NET equivalents and there isn’t a lot left to be done after the conversion. At that point, warnings are generated stating that behaviors for these common collections are different on the two platforms, so the conversion should be verified. However, the vast majority of the conversion process should be successful and valid.
Figure 3 Equivalent Collection Classes in .NET and Java
| .NET | Java | |
|---|---|---|
| List interface | IList, IList<T> | List |
| Common list classes | ArrayList, List<T> | ArrayList, Vector |
| Dictionary interface | IDictionary, IDictionary<TKey,TValue> | Map |
| Common dictionary classes | Hashtable, Dictionary<TKey,TValue> | HashMap, HashTable |
That said, we encountered a problem with converting collections where we had used specialized collections in the original Java application. An example of this issue is the use of the Java LinkedHashSet class. According to the Java API documentation, the LinkedHashSet class ensures consistent ordering of entries in the HashSet (which is a type of dictionary), without the overhead imposed by other ordered dictionaries. While the definition of a LinkedHashSet is straightforward, the intent of its usage in the application was unclear. (The code was written by someone no longer on the team, and there wasn’t documentation as to why it was used.) Furthermore, the context of its usage didn’t give us anything, so it was unclear whether this class was used to fix a problem or perhaps for some other reason.
In looking through the code, we found no justification for its usage, and thus we had three options: assume it wasn’t actually needed in the original application, write our own implementation for our .NET app, or pick the closest appropriate collection in the .NET Framework. We assumed the specialized implementation of a LinkedHashSet was unnecessary, since there was no indication that ordered name value pairs were used anywhere else. As such, we substituted the basic .NET Hashtable class, and we verified the correct behavior with our existing unit and integration tests. However, if we had discovered performance or functional issues, we could have substituted the SortedDictionary<TKey, TValue> class in the .NET Framework 2.0 which represents a collection of key/value pairs that are sorted on the key; internally its implementation uses a set based on a red-black tree data structure.
In our project, there were only four uses of specialized Java collections classes, and they all presented similar circumstances. The additional functionality they provided was unused, and using the more generic .NET counterparts accomplished the task at hand.
I should note that our Java application was written using Java version 1.4. Generic collections, which allow strong typing of collection members, were not introduced to Java until version 1.5. Therefore, we did not have to delve into converting generics. Presumably converting collections in Java version 1.5 will thus add another layer of complexity to the conversion process since not only do the collections need to be converted, but so do their typed entries.
Filters and HTTP Handlers
A filter is a common paradigm used in J2EE Web applications to selectively intercept requests and responses to perform pre- and post-processing. Some common usages for filters are logging, usage auditing, and security.
Java filters implement the Filter interface, which defines particular lifecycle events. Filters are invoked by the application server by using a URL mapping to map Filter classes to full or partial URLs. When a match is made, the application server implements the lifecycle events of the mapped filter, passing a handle to the request and the response.
ASP.NET provides similar functionality in the form of an interface called IHttpHandler. Both filters and HTTP handlers have very simple interfaces, but are very powerful in what they can do. In our application, we had two different types of filters—one that used GZip compression to compress responses and one that intercepted requests to see if the request was from a known user agent.
The compression filter was implemented in the Java application to improve performance. It took every response stream, checked to see if the client supported GZip compression, and if so, compressed the response. Typically, this is unnecessary, as most modern HTTP servers provide this functionality without custom code. However, our application was contained as a Servlet application, which doesn’t necessitate an HTTP server, so the compression functionality was a value-added module.
The second filter, which rejected requests based on a user agent header value, is of more interest. Many of our clients wished to implement a level of authentication that compared the HTTP user agent header against a list of allowed agents. If the incoming request’s user agent value wasn’t an allowed user agent, the request should be rejected (usually by returning an HTTP unauthorized return value).
This type of request/response filter can be accomplished many ways. Most solutions, though, require a lot of injection of code or attributes. Luckily, J2EE and .NET both provide very simple mechanisms for intercepting, modifying, and adjusting requests and responses at an application level. Additionally, HTTP interceptors like these are not code-pervasive, meaning they are not lines of code in every class. Rather, they are separate classes that are managed and injected via the application server, so it is much easier to modify the functionality rather than perform a global search and replace.
The JLCA 3.0 does provide helper classes that aid in the migration of filters from Java to ASP.NET applications. Figure 4 shows a sample filter in Java that times the server processing, and it also shows how the JLCA attempts to convert this filter for ASP.NET. While in an ideal world the way to port to a .NET implementation probably requires rewriting the filter from scratch as an HTTP handler, JLCA provides the support class SupportClass.ServetFilter which gets you most of the way through a reimplementation. ServletFilter emulates the life cycle Java provides. While it doesn’t solve all problems, it can ease a port implementation.
Figure 4 JLCA Conversion Using ServletFilter
Java
import javax.servlet.*;
import java.io.*;
public final class TimerFilter implements Filter
{
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException
{
long startTime = System.currentTimeMillis();
chain.doFilter(request, response);
long stopTime = System.currentTimeMillis();
System.out.println(“Time to execute request: “ +
(stopTime - startTime) + “ milliseconds”);
}
public void destroy() {}
public void init(FilterConfig fc) {}
}
C#
using System;
using System.Web;
// UPGRADE_TODO: Verify list of registered servlet filters.
public sealed class TimerFilter : SupportClass.ServletFilter
{
public override void DoFilter(HttpRequest request,
HttpResponse response, SupportClass.ServletFilterChain chain)
{
long startTime =
(System.DateTime.Now.Ticks - 621355968000000000) / 10000;
chain.doFilter(request, response);
long stopTime =
(System.DateTime.Now.Ticks - 621355968000000000) / 10000;
Console.Out.WriteLine(“Time to execute request: “ +
(stopTime - startTime) + “ milliseconds”);
}
public void destroy() {}
// UPGRADE_ISSUE: Interface ‘javax.servlet.FilterConfig’
// was not converted.
public void init() {}
}
That said, our team took the path of manually converting the Java filter functionality to an HTTP handler. In order to walk you through this, I should compare the two interfaces. A J2EE filter has three methods: init, destroy, and doFilter. The init and destroy methods are lifecycle methods that have some significance, but are outside of the scope of this discussion. The doFilter method, however, does the lion’s share of the work in a filter.
In our scenario, the doFilter method gets the user agent header variable from the incoming request and inspects it against a list of configurable, known user agents. The most difficult thing in conversion is the difference in objects passed as arguments to the actionable method.
In the Java Filter.doFilter method, there are three arguments passed: a request object, a response object, and a filter chain object. Conversely, the IHttpHandler class’s ProcessRequest method has a single argument: an HttpContext variable. The HttpContext variable references an HttpRequest and an HttpResponse object, and most of the same functionality can be accomplished by accessing the HttpContext’s members.
The Java FilterChain object is interesting. This represents a chain of filters in an HTTP request. A filter may pass on the request to the next filter in the chain, allowing responsibilities to be delegated in a sequential fashion. The FilterChain is not used very often, however, but when it is, similar behaviors can be achieved with IHttpModule implementations.
The FilterChain aside, converting Java filters to .NET IHttpHandlers is straight-forward. First, an implementation of IHttpHandler needs to be created. Then the logic within the filter’s doFilter method needs to be reconstructed into the implementation’s ProcessRequest method, utilizing the HttpContext’s members instead of the passed request and response objects. Finally, the IsReusable method needs to be defined in the implementation; for simplicity, it can just return false (another case where later on you can write more code to determine whether the same handler instance can, in fact, be reused by later requests for performance gains).
Source Tree and Naming Conventions
While the Java and C# languages are similar, there are differences in lexicography, source tree layout, and naming conventions. Here, I’d like to detail some of these differences.
Java packages (which are the equivalent of namespaces in C#) follow a convention of a reversed domain name, followed by application or module name, followed by functionality. These packages are usually deeply nested (typically four or five levels deep). C# namespaces, on the contrary, are usually grouped by functionally descriptive names and are typically shallow (usually one to four levels). In addition, Java packages are usually lower or camel-cased, while C# namespaces are usually Pascal-cased. Likewise, Java methods are usually camel-cased, while C# methods and properties are usually Pascal-cased.
C# interfaces usually begin with a capital I, denoting an interface (this is purely a convention and is in no way required for correct functionality). Old Java convention said that interface names should end with "able", denoting the ability to do something. This convention is rarely followed any longer, and now there usually isn’t any distinction between an interface’s name and a class’s name.
C# uses properties to implement accessing and mutating private members. Properties are metadata wrappers for get and set accessor methods. But Java doesn’t have properties. Accessors and mutators for a private member are typically implemented as methods called getters or setters. In other words, an accessor for a private field called "name" would be getName.
Finally, Java classes must be located in a directory that matches its declared package, relative to the root of the source files (or classpath). C# does not impose this restriction.
When to Refactor for Conventions
Although a converted C# application will compile and run without addressing these differences, it is always best practice to follow conventions. Choosing when to refactor your converted code to conform to conventions is a difficult decision. However, there are two factors that suggest this should be done sooner rather than later.
Since refactoring code to conform to conventions is not absolutely critical for the application to function, not to mention the fact that it is tedious at times, it may be deemed as unnecessary later in the project. A variety of things can cause it to become a low-priority task and it will therefore run the risk of never getting done. However, if there is a team of developers working on the project, refactoring code to make it appear familiar can help to increase the team’s efficiency and productivity. Don’t underestimate the importance of these tasks. Refactoring of this sort is as important as the other tasks involved in the conversion process to ensure a successful result.
Directory Layout and Namespaces
Naming and directory conventions are a subjective process, but there are general guidelines. For our project, assume that there is a class for custom XML parsing, and it is located in the com.mycompany.myapplication.xml.util namespace (and directory, after conversion). C# convention suggests that this class should be located in the Xml.Util namespace. Before refactoring, our directory tree would look similar to Figure 5. Dragging and dropping files in Visual Studio will allow you to accomplish the physical movement of the file, so that your directory tree now looks like Figure 6.

Figure 5** Java Source Tree **

Figure 6** C# Source Tree **
However, C# does not dictate that the directory location of a file match its declared namespace. Therefore, the namespace of the class is not updated to match the file system location. There is no automatic way of moving multiple classes to different namespaces in Visual Studio—the best way that I’ve found to do this is to perform a Find and Replace for the whole solution, as shown in Figure 7. This, of course, assumes that you’re moving all of the classes in one namespace to the same destination.
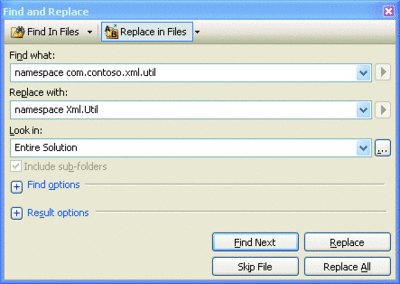
Figure 7** Find and Replace Namespace Declarations **(Click the image for a larger view)
Properties
The construction of properties in C# is significantly different from Java. Properties can be thought of as public fields that store the state of a class or, in UML terms, attributes of class. But Java does not have a property construct—instead, properties are represented in methods called getters and setters.
Consider a class that has an instance variable called "name". You don’t want to make this variable public because all control would be lost to modification of this variable. In Java, the standard method of providing access to this variable is through getters and setters, named so because the convention is to prepend a "get" or "set" to the variable name as the method name. Thus, if the name variable is a string, the Java getter and setter might look like this:
public String getName() {
return this.name;
}
protected void setName(String name) {
this.name = name;
}
C# provides property constructs to accomplish the same thing. Although they can be used for application logic, their intent is to provide protected access to private implementation details, as described above. Therefore, a C# implementation of the same access would look like this:
public String Name
{
get {return this.name;}
protected set {this.name = value;}
}
While C# properties accomplish the same objective, I find them to be clearer—in Java, methods that don’t modify a class’s state may begin with a get or set, leading to ambiguity. Therefore, I recommend that you refactor Java getters and setters to be C# properties.
That said, there isn’t an easy way to convert Java getters and setters to C# properties. A regular expression search and replace would be extremely complex, and the JLCA simply migrates the Java getter and setter methods as-is since there is no way to tell if the method is modifying a class’s state or performing some other functionality. Our approach to this problem was to use a more practical solution. Visual Studio provides a wizard for encapsulating private members with properties. This generates the desired properties without deleting the converted Java getters and setters.
As our team worked on code for other reasons, they also generated the C# properties in Visual Studio and deleted the corresponding getter and setter methods. After this step, developers would use the Visual Studio 2005 Find References functionality which provides a list of all call sites for a particular method. This gave them the references to the old getter and setter methods, so they could easily change the references to the new properties. This wasn’t an elegant solution, but it worked surprisingly well.
I should stress that this was considered a very important step in the porting process since properties are ingrained core aspect of C# and .NET and our goal was to create a C# application. (Remember, this application would eventually need to be supported by another team, which was expecting a C# application.)
Pascal-Casing Method Names
As I’ve already noted, Java method names are conventionally camel-cased. In other words, these names start with a lower-case letter, and each subsequent word boundary is upper-cased. C# convention says that methods and other members are Pascal-cased. Pascal-casing is similar to camel-casing, except that the first letter in the name is also upper case.
What does this mean to you? You should probably rename all of your methods to start with an upper-case letter instead of a lower-case letter. For example, the Java method
public void getResponseCode()
should be refactored as the C# method:
public String GetResponseCode()
As with converting getters and setters into properties, there is no easy way to go through all of the converted code and update members to conform to C# naming convention. However, we considered this a very important task since the members that were converted did not resemble C# members and, again, our team and our customer wanted this to be a proper C# application.
In theory, a code converter could be written to perform this task, and we considered doing this ourselves. However, we decided to take the same approach as we did with properties, updating member names piecemeal. We had several reasons for taking the manual approach.
For starters, our developers were already analyzing all of the code to update other elements, such as the getters and setters. The process could be incremental, since not changing the names of members did not affect the ability to compile or function. And, if for some reason one or two members were missed, the application wouldn’t break. The process didn’t take as much time as you might think—the main problem was that it was a tedious task.
Visual Studio 2005 has built-in refactoring support. Part of the refactoring support is safely renaming members, whereby a member can be renamed, and all references to that member are updated. It takes a little bit of time to go through all members you want to update, but it is an effective solution.
Conclusion
I have described to you a real case of converting a Java Web application to ASP.NET. Much of the heavy lifting was done by the JLCA, but there were several items that needed manual intervention on our part. Nevertheless, the JLCA is a powerful tool and allowed our application to be quickly ported to a production-quality .NET application.
My intent here is to demonstrate the viability of converting a Java application to .NET and to point out some of the issues that typically need to addressed beyond the JLCA’s capabilities. Every port of an application will present unique problems and I couldn’t address all of them in this article. However, I have offered some techniques and approaches that should help with any problems you might encounter.
Brian Jimerson is a senior technical architect for Avantia, Inc. (www.avantia-inc.com), a custom solutions provider based in Cleveland, Ohio. Brian has recently been helping clients define and implement infrastructure and architecture solutions for both Java and the .NET Framework.