Performance
Scaling Strategies for ASP.NET Applications
Richard Campbell and Kent Alstad
This article discusses:
|
This article uses the following technologies: ASP.NET |
Contents
The Performance Equation
Scaling Problems
Optimizing the Code
Load Balancing
Affinity
Minimizing Payload
Caching
Scaling Databases
The Endless Scaling Effort
As ASP.NET performance advisors, we are typically brought into a project when it's already in trouble. In many cases, the call doesn't come until after the application has been put into production. What worked great for the developers isn't working well for users. The complaint: the site is too slow. Management wants to know why this wasn't discovered in testing. Development can't reproduce the problem. At least one person is saying that ASP.NET can't scale. Sound familiar?
Some of the busiest Web sites in the world run on ASP.NET. MySpace is a great example; in fact, it was migrated to ASP.NET after running on a number of different platforms. The fact is, performance problems can creep into your app as it scales up, and when they do, you need to determine what the actual problem is and find the best strategies to address it. The biggest challenge you'll face is creating a set of measurements that cover the performance of your application from end to end. Unless you're looking at the whole problem, you won't know where to focus your energy.
The Performance Equation
In September 2006, Peter Sevcik and Rebecca Wetzel of NetForecast published a paper called "Field Guide to Application Delivery Systems." The paper focused on improving wide area network (WAN) application performance and included the equation in Figure 1. The equation looks at WAN performance, but with a few minor modifications it can be used to measure Web application performance. The modified equation is shown in Figure 2 and each element is explained in Figure 3.
Figure 3 Elements of the Performance Equation
| Variable | Definition |
|---|---|
| R | Response time. The total time from the user requesting a page (by clicking a link, and so on) to when the full page is rendered on the user's computer. Typically measured in seconds. |
| Payload | Total bytes sent to the browser, including markup and all resources (such as CSS, JS, and image files). |
| Bandwidth | Rate of transfer to and from the browser. This may be asymmetrical and might represent multiple speeds if a given page is generated from multiple sources. Usually, it is averaged together to create a single bandwidth expressed in bytes per second. |
| AppTurns | The number of resource files a given page needs. These resource files will include CSS, JS, images, and any other files retrieved by the browser in the process of rendering the page. In the equation, the HTML page is accounted for separately by adding in round-trip time (RTT) before the AppTurns expression. |
| RTT | The time it takes to round-trip, regardless of bytes transferred. Every request pays a minimum of one RTT for the page itself. Typically measured in milliseconds. |
| Concurrent Requests | Number of simultaneous requests a browser will make for resource files. By default, Internet Explorer performs two concurrent requests. This setting can be adjusted but rarely is. |
| Cs | Compute time on the server. This is the time it takes for code to run, retrieve data from the database, and compose the response to be sent to the browser. Measured in milliseconds. |
| Cc | Compute time on the client. This is the time it takes for a browser to actually render the HTML on the screen, execute JavaScript, implement CSS rules, and so on. |

Figure 1** The Original Performance Equation **(Click the image for a larger view)

Figure 2** The Web Version of the Performance Equation **(Click the image for a larger view)
Now that you have the formula, the challenge lies in measuring each element. The ending value, response time, is relatively easy to measure; there are a number of tools that will time exactly how long the entire process takes.
Payload can be measured using various tools (websiteoptimization.com/services/analyze is a great option), as can Bandwidth (see speedtest.net) and round-trip time (using Ping). Tools like websiteoptimization.com/services/analyze will also report the size of a Web page's HTML, CSS, JavaScript, images, and so forth. Concurrent Requests is essentially a constantly (Internet Explorer® defaults to 2).
That leaves Cs and Cc, which need some additional development effort. It's relatively straightforward to write code in an ASP.NET page that notes the exact second execution of the page begins and subtracts that time from the current time when execution completes. The same is true on the client side; a bit of JavaScript can execute right at the top of the HTML page to note the time and then subtract the time at the point that the OnLoad event fires when the page is completed.
In fact, all these elements can be coded for if you want to build in a debug mode of your Web site that utilizes the performance equation. And there's good reason to do so: if you can routinely render the performance equation elements on the browser, then you can easily detect where your performance problems lie.
For example, suppose you have an ASP.NET application whose users are on another continent and have low bandwidth. With high ping times (> 200ms) and low bandwidth (< 500kbps), your users would be highly sensitive to the total payload and the number of round-trips in your application. Looking at your application in the context of those users is vital since their experience will be very different from yours.
Scaling Problems
As consultants, we know we're probably dealing with a scaling issue when the application performs well in the test environment but poorly in the real world. Usually, the only difference between the two is the number of simultaneous users. If the application performed poorly all the time, you would have a performance problem rather than a scaling problem.
There are three strategies available that you can employ in order to improve scaling: specialization, optimization, and distribution. How you apply them will vary, but the actual strategies are straightforward and consistent.
The goal of specialization is to break your application into smaller pieces in order to isolate the problem. For example, you might want to consider moving static resource files such as images, CSS, and JS files off of the ASP.NET servers. A server well-tuned for ASP.NET is not especially well-suited to serving those sorts of files. For this reason, a separate group of IIS servers tuned to serve resource files can make a substantial difference in the scalability of the application you are running.
If you perform a lot of compression or encryption (for SSL), setting up servers dedicated to SSL can help. You should be aware that there are even specialized hardware devices available for compression and SSL termination.
While more traditional strategies for decomposing server tiers might have you considering separate servers for data access, complex computations, and so on, independent of the actual generation of the Web pages, I'd rather have five Web servers that do everything than three Web servers and two business object servers. All those out-of-process calls between the Web servers and business object servers create a lot of overhead.
Specialization should only be done for a known and expected benefit. And the fastest solution is not always the best. The goal of scalability is consistency of performance. You want to narrow the performance range as the load increases; whether there's one user or one thousand, you want a given page rendered for all users in the same amount of time.
Eventually you will need to optimize your server code to scale more effectively. Virtually every aspect of the performance equation scales linearly, except for compute time on the server; you can always add more bandwidth (and it's fairly easy to know when), and the compute time on the client doesn't change as the number of clients increases. The other elements of the performance equation also remain consistent as you scale. But compute time on the server will need to be tuned as the number of users increases.
Optimizing the Code
The trick to optimizing server code is to use testing to be sure you're actually making a difference. You should use profiling tools to analyze your application and find out where the application is spending the most time. The entire process should be empirical: use tools to find the code to improve, improve the code, test to see that you have actually improved performance, rinse, lather, repeat. In really large-scale sites, you'll often hear performance tuning like this compared to the job of painting the Golden Gate Bridge: once you finish painting the entire thing, it's time to go back to the beginning and start again.
I'm always amazed at the number of people who believe that the starting point of scaling is distribution. "Throw more hardware at it," they yell. Don't get me wrong; without a doubt, adding hardware can help. But without specialization and optimization, the return can be small indeed.
Specialization lets you distribute smaller parts of your application as needed. If you've separated out your image servers, for example, it's easy to scale your image services independently of the rest of the application.
Optimization also provides dividends for distribution by reducing the amount of work needed for a given operation. This translates directly into fewer servers needed to scale to the same number of users.
Load Balancing
To implement distribution you need to add servers, duplicate the application across them, and implement load balancing. For load balancing, you can use Network Load Balancing (NLB), a service included with all editions of Windows Server® 2003. With NLB, every server is an equal partner in the load-balancing relationship. They all use the same algorithm for balancing, and they all listen on a shared virtual IP address for all traffic. Based on the load-balancing algorithm, each server knows which server should be working on a given request. Each server in the cluster sends out a heartbeat to let the other servers know it is alive. When a server fails, the heartbeat for that server stops and the other servers compensate automatically.
NLB works well when you have a large number of users making fairly similar requests. However, the compensation mechanism does not work as well in a scenario when some requests create a much greater load than others. Fortunately, for that type of situation there are hardware load-balancing solutions available.
Affinity
Ultimately, the challenge of effective distribution lies in eliminating affinity. For example, when you have only one Web server, storing session data there makes perfect sense. But if you have more than one Web server, where do you keep session information?
One approach is to keep it on the Web server and use affinity. Essentially, this means the first request from a given user is load balanced, and after that, all subsequent requests from that user/session are sent to the same server as the first request. This is a simple approach, every load balancing solution supports it, and in some cases it even makes sense.
In the long run, however, affinity creates grief. Keeping session data in-process may be fast, but if the ASP.NET worker process recycles, all those sessions are dead. And worker processes recycle for a lot of reasons. Under high load, IIS might recycle the worker process of ASP.NET because it thinks it's stuck. In fact, by default in IIS 6.0 a worker process is recycled every 23 hours. You can adjust it, but either way, your users are vulnerable to losing their session data while it is in-process. When you're small, this isn't that big a deal, but as your site gets bigger and busier it becomes a more significant issue. And there's more.
If you're load balancing by IP address, one server is going to get hit by a megaproxy (like AOL) and be unable to service that entire load on its own. Plus, updating your servers with a new version of your application becomes more difficult; you must either wait for hours to let users to finish up on your site or annoy those users by knocking them out of their sessions. And your reliability becomes an issue: lose a server and you lose a lot of sessions.
Getting rid of affinity is a key goal of distribution. This requires moving session state data out of process, which means taking a performance decrease to provide a scalability increase. When you move session out of process, session data is recorded in a place where all the Web servers can access it—located either on SQL Server® or the ASP.NET State Server. This is configured in web.config.
There's also a coding effort needed to support out-of-process session. Any classes that will be stored in the Session object need to be marked with the Serializable attribute. That means that all data in the class needs to either be serializable or be marked as NonSerialized so it will be ignored. If you don't mark up your classes, when the serializer runs to store your session data out of process, you'll get errors.
Finally, moving session out of process is a great way to find out you have too much data in your session object, because you're now paying a price for shipping that great big blob of data back and forth across the network twice (once to retrieve it at the beginning of the page, once to return it at the end of the page) for every page request.
Once you nail down the Session object, go after other affinity issues like Membership and Role Manager. Each one has its own challenges for eliminating affinity. But for your ASP.NET application to really scale up, you'll need to hunt down every form of affinity you can find and eliminate it.
All of the strategies we've discussed thus far are applicable to practically every Web application that needs to scale. In fact, those strategies would apply to scaling virtually any application using any technology. Now let's look at some ASP.NET-specific techniques.
Minimizing Payload
Looking at the performance equation, you can see payload plays a significant role, especially when you're dealing with limited bandwidth. Reducing the size of your payload will improve your response time, you'll gain some scaling benefits from moving fewer bytes around, and you could even save some money on your bandwidth costs.
One of the simplest things you can do to decrease the size of your payload is to turn on compression. In IIS 6.0, you can specify whether to compress static files, dynamically generated responses (ASP.NET pages, for example), or both (see Figure 4).
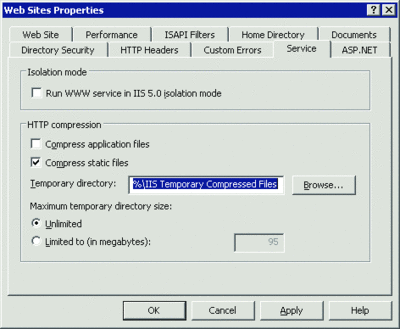
Figure 4** Configuring Compression Server-Wide in IIS 6.0 **(Click the image for a larger view)
IIS 6.0 compresses static files on demand, storing them in a compressed files cache that you specify. For dynamically generated responses, no copy is stored; they're compressed every time. IIS 7.0 is smarter about what it compresses, only compressing files that are used frequently.
Compression costs processor cycles, but you typically have plenty of extra processor capacity on a dedicated Web server. IIS 7.0 is further optimized, however, so that when the processor gets really busy, it will suspend compression efforts. There are also dedicated devices for doing compression independent of the Web server itself.
Another area ripe for payload reduction is ViewState. During development, it's quite easy for ViewState usage to get out of hand. Most Web controls use some ViewState, and on control-intensive pages, ViewState can grow to thousands of bytes. To reduce ViewState usage, turn it off on controls where it isn't needed. In some cases, developers will even eliminate controls to reduce the ViewState. But that's not always necessary. Most modern Web controls are sensitive to the problem of excessive ViewState and thus provide granular control over its size. There are also hardware devices that can remove and replace ViewState for you without altering your code or how your application runs.
One of the most effective technologies for reducing payload size is AJAX. Except that AJAX doesn't really reduce payload size—it simply reduces the perceived size of the payload while increasing the total number of bytes sent to the browser. Using AJAX, the parent page is smaller, so initial render times are faster. Individual elements in that page then make their own requests to the server to populate data.
Effectively, AJAX spreads the payload out over time, giving the user something to look at while other bits load. So using AJAX will improve your user experience overall, but refer back to the performance equation to measure the real costs of your effort. AJAX typically increases compute time on the client, sometimes dramatically, to the point that performance can be unacceptable.
If the AJAX round-trips to the server to populate individual elements are replacing entire page requests, you'll have a net decrease in round-trips. But in many cases, you'll find the total number of round-trips for a given user will increase. You just need to be diligent about your testing so you know whether AJAX has improved performance or reduced it.
Caching
Experts in scaling ASP.NET applications talk a great deal about caching. Fundamentally, caching is about moving data closer to the user. In a typical ASP.NET application, before any significant optimization work has been done, virtually all the data the user needs is in the database and retrieved from the database with every request. Caching changes that behavior. ASP.NET actually supports three forms of caching: page caching (also known as output caching), partial-page caching, and programmatic (also known as data) caching.
Page caching is by far the simplest form of caching. To use it, you add an @OutputCache directive to your ASP.NET page and include a rule for when to expire it. For example, you could specify that the page should be cached for 60 seconds. With that directive in place, the first request of that page will process normally, accessing the database and whatever other resources are needed to generate the page. After that, the page is held in memory on the Web server for 60 seconds and all requests during that time are served directly from memory.
Unfortunately, while this example is straightforward, it ignores a fundamental reality of page caching: virtually no ASP.NET page is so static that you can cache the entire thing for any length of time. That's where partial-page caching comes in. With partial-page caching, you're able to mark portions of an ASP.NET page as cachable so that only the parts of the page that do change regularly are computed. It's more complicated but effective.
Arguably, the most powerful (and most complex) form of caching is programmatic caching, which focuses on the objects used by the page. The most common use of programmatic caching is to store data retrieved from the database.
The most obvious problem with caching data is that the underlying data may have changed since you cached it. Expiration of caching is the biggest challenge you'll face in implementing caching of any form. But there's also memory to consider.
On a busy ASP.NET server, memory becomes a significant issue for a variety of reasons. Whenever an ASP.NET page is computed, it uses some memory. And the Microsoft® .NET Framework is set up to allocate memory very quickly but release it relatively slowly, through garbage collection. The discussion around garbage collection and .NET memory allocation is an article unto itself, one that has been written a number of times. But suffice it to say that on a busy Web server, the 2GB memory space available for your ASP.NET application is in high demand. Ideally, most of that memory usage is temporary, as it is allocated for variables and structures used in computing a Web page.
When it comes to persistent memory objects, however, like in-process session and cache objects, memory usage becomes much more problematic. And of course, these problems only surface when your application is really busy.
Consider this scenario: your Web site is hopping from some new marketing promotion, there are thousands of users hitting the site, and you're making loads of money. To maintain good response times, you're caching portions of pages and groups of data objects wherever possible. Each page request from a user consumes a bit of memory, so the bar of consumed memory keeps sliding upward. The more users, the faster that bar moves. There are also big jumps from the cache and session objects.
As the total memory used gets close to 90 percent of ASP.NET's default cache memory limit, a garbage collection event is called. The garbage collector works its way through the memory space, shuffling down persisted memory objects (like cache objects and session objects) and freeing up memory that's no longer used (the memory that was used to compute the Web pages). Freeing up unused memory is fast, but the shuffling of persisted objects is slow. So the more persisted objects you have, the harder time the garbage collector has doing its job. This type of problem can be identified in perform.exe by a high number of gen-2 collections.
And recall that while garbage collection is going on, no pages can be served by that ASP.NET server; everything is held in a queue, waiting for the garbage collection process to complete. And IIS is watching, too. If it thinks the process is taking too long and might be hung, it will recycle the worker thread. And while this frees up a lot of memory really quickly because all of those persisted memory objects are thrown out, you'll have some annoyed customers.
There is now a patch for ASP.NET that will automatically remove objects from the programmatic cache if you get low on memory, which sounds like a good idea on the surface. It's better than crashing. Just remember that every time you remove something from the cache, your code will eventually put it back.
The moment you cache something, you run the risk of it being wrong. Take, for example, a widgets database and corresponding order page. In the initial incarnation of the widget page, every rendering of that page will involve a request from the database for the number of widgets still in inventory. If you analyze those requests, you'll likely find that 99 percent of the time, you're retrieving the same number over and over again. So why not cache it?
A simple way to cache it would be over time. So you cache the inventory of the widgets for an hour. The drawback to this technique is that someone will buy a widget, then go back to the page and see that the inventory is still the same. You'll get complaints about that. But far more challenging is when someone goes to buy your widget and sees that the inventory is there, when it's actually sold out. You could build a backorder system, but either way, you're dealing with a disappointed customer.
Perhaps the problem is your expiration scheme: Time isn't good enough. You could cache the inventory count until someone buys a widget and then expire the cache object. That's more logical, but what happens if there is more than one ASP.NET server? Depending on which server you go to, you'll get different inventory counts for the widget. Consider that receiving new inventory (which adds to the count) doesn't even go through your Web application, and you have a whole new way to be wrong.
Synchronizing expirations among ASP.NET servers can be done, but you have to be careful. The amount of chatter you can generate among Web servers goes up geometrically as the number of cache objects and Web servers increases.
The impact of cache expiration on performance needs to be studied carefully, too. Under high load conditions, expiring a cache object can cause a lot of grief. For example, suppose you have an expensive query that takes 30 seconds to return from the database. You've cached that query to save that high expense because under load, that page is requested once every second.
The code for handling cache objects is pretty simple. Instead of retrieving the data from the database when needed, the application first checks to see if the cache object is populated. If it is, it uses the data from the cache object. If it is not, it executes the code to retrieve the data from the database and then populates the cache object with that data; code then continues to execute as normal.
The problem is that if you've got a query that takes 30 seconds and you're executing the page every second, in the time it takes to populate the cache item, 29 other requests will come in, all of which will attempt to populate the cache item with their own queries to the database. To solve this problem, you can add a thread lock to stop the other page executions from requesting the data from the database.
But run through the scenario again: the first request comes in, discovers the cache item is not populated, applies a lock to the code, and runs the query to populate the cache object. The second request arrives a second later while the first is still running, finds the cache object is not populated but the lock is in place, so it blocks. As does the next 28 requests. Then the first one finishes its processing, removes the lock, and continues. What happens to the other 29 requests? They're no longer blocked, so they continue executing as well. But they've already run through the check to see if the cache object is populated (and it wasn't at the time). So they'll try and grab a lock, and one will succeed and run the query again.
See the problem? Other requests that arrive after the first request completed populating the cache object will run normally, but those requests that come in while the query is running are in a tough spot. You have to write code to deal with this. If a request hits a lock, when the lock is lifted it should check again to see if the cache object is populated, as shown in Figure 5. Likely, the cache object will be populated now; that was why the lock was taken in the first place. Although it's possible that it isn't, because in the meantime some other chunk of code has expired the cache object again.
Figure 5 Checking, Locking, and Rechecking a Cache Object
// check for cached results
object cachedResults = ctx.Cache["PersonList"];
ArrayList results = new ArrayList();
if (cachedResults == null)
{
// lock this section of the code
// while we populate the list
lock(lockObject)
{
// only populate if list was not populated by
// another thread while this thread was waiting
if (cachedResults == null)
{
...
}
}
}
Writing caching code that works well is hard work, but the returns can be tremendous. Caching does add complexity, however, so use it judiciously. Make sure you're really going to benefit from the complexity. Always test your caching code for these complex scenarios. What happens on multiple simultaneous requests? What happens if expirations come quickly? You need to know the answers to these questions. You don't want your caching code to make your scaling problems worse.
Scaling Databases
The normal approach for scaling Web sites is to scale out, rather than up. This is largely due to ASP.NET thread and memory limitations combined with the short-term nature of Web requests.
When it comes to scaling databases, however, the normal practice is to scale up—one gigantic box, perhaps two in a cluster configuration (although only one is actually running the database at any given time). Eventually, though, in every large-scale Web application, a single database cannot handle the load. You have to scale out. It's possible; you just need to apply the same strategies applied to the Web application itself. The first step is always specialization—breaking the database into logical partitions. Those partitions could be datacentric, perhaps by region. So you would have multiple databases, each containing a portion of the whole database. One server would have East Coast data, for example, while the other has West Coast data.
Really large-scale Web applications, however, partition their databases into readers and writers (see Figure 6). The reader databases are read-only; they receive their data from the writer databases via replication. All data queries go to the reader databases, which are optimized for reading data as fast as possible. Reader databases are by their nature very distributable.
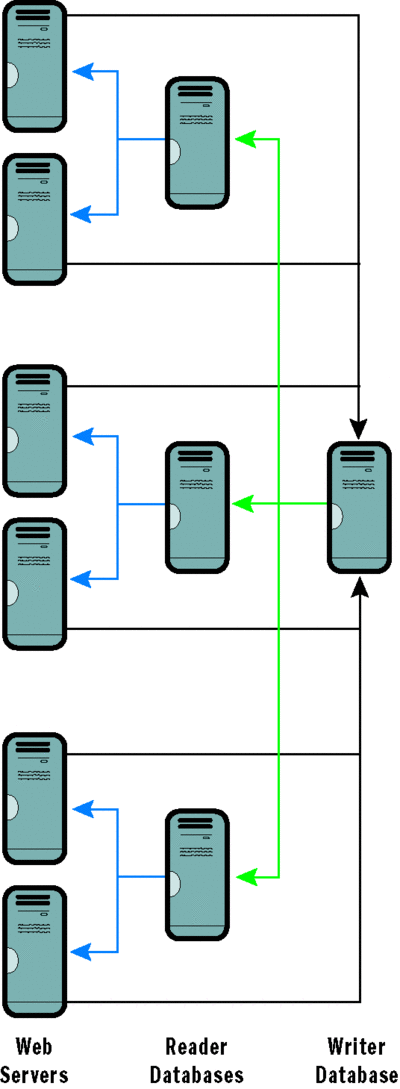
Figure 6** Distributed Database Architecture**
All data write requests are sent to the writer databases, which are partitioned and tuned to write efficiently. Replication moves the new data from the writer to the reader databases.
The consequence of creating such specialized databases is latency: a write is now going to take time to be distributed to the reader databases. But if you can deal with the latency, the scaling potential is huge.
The Endless Scaling Effort
As long as your application continues to grow, your efforts to scale it are going to continue to grow as well. The ASP.NET techniques that work effectively for 10,000 simultaneous users aren't as effective with 100,000 users, and the rules change again with 1 million users. Of course, performance can completely depend on your application; we've seen applications that had scaling challenges with less than a thousand users!
The key to effective scaling is to measure before you cut: Use testing to be sure you're spending effort where it's needed. Test your work to be sure that you've actually made an improvement, not just a change. Even at the end of a development cycle focused on optimizing for scalability, you should know where your slowest bits are. Hopefully, however, they're fast enough for the users today, so that you can work on what your users will need tomorrow.
Richard Campbell is a Microsoft Regional Director, MVP in ASP.NET, and the co-host of .NET Rocks, the Internet Audio Talkshow for .NET Developers (dotnetrocks.com). He has spent years consulting with companies on the performance and scaling of ASP.NET and is also one of the co-founders of Strangeloop Networks.
Kent Alstad is the CTO of Strangeloop Networks (strangeloopnetworks.com) and the principal or contributing author on all of Strangeloop's pending patents. Before helping to create Strangeloop, he built and consulted on many high-performance, high-scaling ASP.NET applications.