Roll Your Own
Create a Language Compiler for the .NET Framework
Joel Pobar
This article discusses:
|
This article uses the following technologies: .NET Framework |
Code download available at:CompilerWriting2008_02.exe(158 KB)
Contents
Language Definition
High-Level Architecture
The Scanner
The Parser
Targeting the .NET Framework
Tools for Getting Your IL Right
The Code Generator
Wrapping Up ... Almost
Dynamic Method Invocation
Using LCG to Perform Quick Late-Binding
The Dynamic Language Runtime
Compiler hackers are celebrities in the world of computer science. I've seen Anders Hejlsberg deliver a presentation at the Professional Developers Conference and then walk off stage to a herd of men and women asking him to sign books and pose for photographs. There's a certain intellectual mystique about individuals who dedicate their time to learning and understanding the ins and outs of lambda expressions, type systems, and assembly languages. Now, you too can share some of this glory by writing your own compiler for the Microsoft® .NET Framework.
There are hundreds of compilers for dozens of languages that target the .NET Framework. The .NET CLR wrangles these languages into the same sandpit to play and interact together peacefully. A ninja developer can take advantage of this when building large software systems, adding a bit of C# and a dabble of Python. Sure, these developers are impressive, but they don't compare to the true masters—the compiler hackers, for it is they who have a deep understanding of virtual machines, language design, and the nuts and bolts of these languages and compilers.
In this article, I will walk you through the code for a compiler written in C# (aptly called the "Good for Nothing" compiler), and along the way I will introduce you to the high-level architecture, theory, and .NET Framework APIs that are required to build your own .NET compiler. I will start with a language definition, explore compiler architecture, and then walk you through the code generation subsystem that spits out a .NET assembly. The goal is for you to understand the foundations of compiler development and get a firm, high-level understanding of how languages target the CLR efficiently. I won't be developing the equivalent of a C# 4.0 or an IronRuby, but this discussion will still offer enough meat to ignite your passion for the art of compiler development.
Language Definition
Software languages begin with a specific purpose. This purpose can be anything from expressiveness (such as Visual Basic®), to productivity (such as Python, which aims to get the most out of every line of code), to specialization (such as Verilog, which is a hardware description language used by processor manufacturers), to simply satisfying the author's personal preferences. (The creator of Boo, for instance, likes the .NET Framework but is not happy with any of the available languages.)
Once you've stated the purpose, you can design the language—think of this as the blueprint for the language. Computer languages must be very precise so that the programmer can accurately express exactly what is required and so that the compiler can accurately understand and generate executable code for exactly what's expressed. The blueprint of a language must be specified to remove ambiguity during a compiler's implementation. For this, you use a metasyntax, which is a syntax used to describe the syntax of languages. There are quite a few metasyntaxes around, so you can choose one according to your personal taste. I will specify the Good for Nothing language using a metasyntax called EBNF (Extended Backus-Naur Form).
It's worth mentioning that EBNF has very reputable roots: it's linked to John Backus, winner of the Turing Award and lead developer on FORTRAN. A deep discussion of EBNF is beyond the scope of the article, but I can explain the basic concepts.
The language definition for Good for Nothing is shown in Figure 1. According to my language definition, Statement (stmt) can be variable declarations, assignments, for loops, reading of integers from the command line, or printing to the screen—and they can be specified many times, separated by semicolons. Expressions (expr) can be strings, integers, arithmetic expressions, or identifiers. Identifiers (ident) can be named using an alphabetic character as the first letter, followed by characters or numbers. And so on. Quite simply, I've defined a language syntax that provides for basic arithmetic capabilities, a small type system, and simple, console-based user interaction.
Figure 1 Good for Nothing Language Definition
<stmt> := var <ident> = <expr> | <ident> = <expr> | for <ident> = <expr> to <expr> do <stmt> end | read_int <ident> | print <expr> | <stmt> ; <stmt> <expr> := <string> | <int> | <arith_expr> | <ident> <arith_expr> := <expr> <arith_op> <expr> <arith_op> := + | - | * | / <ident> := <char> <ident_rest>* <ident_rest> := <char> | <digit> <int> := <digit>+ <digit> := 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <string> := " <string_elem>* " <string_elem> := <any char other than ">
You might have noticed that this language definition is short on specificity. I haven't specified how big the number can be (such as if it can be bigger than a 32-bit integer) or even if the number can be negative. A true EBNF definition would precisely define these details, but, for the sake of conciseness, I will keep my example here simple.
Here is a sample Good for Nothing language program:
var ntimes = 0; print "How much do you love this company? (1-10) "; read_int ntimes; var x = 0; for x = 0 to ntimes do print "Developers!"; end; print "Who said sit down?!!!!!";
You can compare this simple program with the language definition to get a better understanding of how the grammar works. And with that, the language definition is done.
High-Level Architecture
A compiler's job is to translate high-level tasks created by the programmer into tasks that a computer processor can understand and execute. In other words, it will take a program written in the Good for Nothing language and translate it into something that the .NET CLR can execute. A compiler achieves this through a series of translation steps, breaking down the language into parts that we care about and throwing away the rest. Compilers follow common software design principles—loosely coupled components, called phases, plugged together to perform translation steps. Figure 2 illustrates the components that perform the phases of a compiler: the scanner, parser, and code generator. In each phase, the language is broken down further, and that information about the program's intention is served to the next phase.
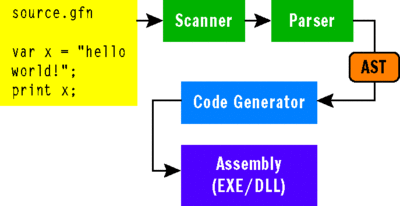
Figure 2** The Compiler's Phases **(Click the image for a larger view)
Compiler geeks often abstractly group the phases into front end and back end. The front end consists of scanning and parsing, while the back end typically consists of code generation. The front end's job is to discover the syntactic structure of a program and translate that from text into a high-level in-memory representation called an Abstract Syntax Tree (AST), which I will elaborate on shortly. The back end has the task of taking the AST and converting it into something that can be executed by a machine.
The three phases are usually divided into a front end and a back end because scanners and parsers are typically coupled together, while the code generator is usually tightly coupled to a target platform. This design allows a developer to replace the code generator for different platforms if the language needs to be cross-platform.
I've made the code for the Good for Nothing compiler available in the code download accompanying this article. You can follow along as I walk through the components of each phase and explore the implementation details.
The Scanner
A scanner's primary job is to break up text (a stream of characters in the source file) into chunks (called tokens) that the parser can consume. The scanner determines which tokens are ultimately sent to the parser and, therefore, is able to throw out things that are not defined in the grammar, like comments. As for my Good for Nothing language, the scanner cares about characters (A-Z and the usual symbols), numbers (0-9), characters that define operations (such as +, -, *, and /), quotation marks for string encapsulation, and semicolons.
A scanner groups together streams of related characters into tokens for the parser. For example, the stream of characters " h e l l o w o r l d ! " would be grouped into one token: "hello world!".
The Good for Nothing scanner is incredibly simple, requiring only a System.IO.TextReader on instantiation. This kicks off the scanning process, as shown here:
public Scanner(TextReader input) { this.result = new Collections.List<object>(); this.Scan(input); }
Figure 3 illustrates the Scan method, which has a simple while loop that walks over every character in the text stream and finds recognizable characters declared in the language definition. Each time a recognizable character or chunk of characters is found, the scanner creates a token and adds it to a List<object>. (In this case, I type it as object. However, I could have created a Token class or something similar to encapsulate more information about the token, such as line and column numbers.)
Figure 3 The Scanner's Scan Method
private void Scan(TextReader input) { while (input.Peek() != -1) { char ch = (char)input.Peek(); // Scan individual tokens if (char.IsWhiteSpace(ch)) { // eat the current char and skip ahead input.Read(); } else if (char.IsLetter(ch) || ch == '_') { StringBuilder accum = new StringBuilder(); input.Read(); // skip the '"' if (input.Peek() == -1) { throw new Exception("unterminated string literal"); } while ((ch = (char)input.Peek()) != '"') { accum.Append(ch); input.Read(); if (input.Peek() == -1) { throw new Exception("unterminated string literal"); } } // skip the terminating " input.Read(); this.result.Add(accum); } ... } }
You can see that when the code encounters a " character, it assumes this will encapsulate a string token; therefore, I consume the string and wrap it up in a StringBuilder instance and add it to the list. After scan builds the token list, the tokens go to the parser class through a property called Tokens.
The Parser
The parser is the heart of the compiler, and it comes in many shapes and sizes. The Good for Nothing parser has a number of jobs: it ensures that the source program conforms to the language definition, and it handles error output if there is a failure. It also creates the in-memory representation of the program syntax, which is consumed by the code generator, and, finally, the Good for Nothing parser figures out what runtime types to use.
The first thing I need to do is take a look at the in-memory representation of the program syntax, the AST. Then I'll take a look at the code that creates this tree from the scanner tokens. The AST format is quick, efficient, easy to code, and can be traversed many times over by the code generator. The AST for the Good for Nothing compiler is shown in Figure 4.
Figure 4 AST for the Good for Nothing Compiler
public abstract class Stmt { } // var <ident> = <expr> public class DeclareVar : Stmt { public string Ident; public Expr Expr; } // print <expr> public class Print : Stmt { public Expr Expr; } // <ident> = <expr> public class Assign : Stmt { public string Ident; public Expr Expr; } // for <ident> = <expr> to <expr> do <stmt> end public class ForLoop : Stmt { public string Ident; public Expr From; public Expr To; public Stmt Body; } // read_int <ident> public class ReadInt : Stmt { public string Ident; } // <stmt> ; <stmt> public class Sequence : Stmt { public Stmt First; public Stmt Second; } /* <expr> := <string> * | <int> * | <arith_expr> * | <ident> */ public abstract class Expr { } // <string> := " <string_elem>* " public class StringLiteral : Expr { public string Value; } // <int> := <digit>+ public class IntLiteral : Expr { public int Value; } // <ident> := <char> <ident_rest>* // <ident_rest> := <char> | <digit> public class Variable : Expr { public string Ident; } // <arith_expr> := <expr> <arith_op> <expr> public class ArithExpr : Expr { public Expr Left; public Expr Right; public BinOp Op; } // <arith_op> := + | - | * | / public enum ArithOp { Add, Sub, Mul, Div }
A quick glance at the Good for Nothing language definition shows that the AST loosely matches the language definition nodes from the EBNF grammar. It's best to think of the language definition as encapsulating the syntax, while the abstract syntax tree captures the structure of those elements.
There are many algorithms available for parsing, and exploring all of them is beyond the scope of this article. In general, they differ in how they walk the stream of tokens to create the AST. In my Good for Nothing compiler, I use what's called an LL (Left-to-right, Left-most derivation) top-down parser. This simply means that it reads text from left to right, constructing the AST based on the next available token of input.
The constructor for my parser class simply takes a list of tokens that was created by the scanner:
public Parser(IList<object> tokens) { this.tokens = tokens; this.index = 0; this.result = this.ParseStmt(); if (this.index != this.tokens.Count) throw new Exception("expected EOF"); }
The core of the parsing work is done by the ParseStmt method, as shown in Figure 5. It returns a Stmt node, which serves as the root node of the tree and matches the language syntax definition's top-level node. The parser traverses the list of tokens using an index as the current position while identifying tokens that are subservient to the Stmt node in the language syntax (variable declarations and assignments, for loops, read_ints, and prints). If a token can't be identified, an exception is thrown.
Figure 5 ParseStmt Method Identifies Tokens
private Stmt ParseStmt() { Stmt result; if (this.index == this.tokens.Count) { throw new Exception("expected statement, got EOF"); } if (this.tokens[this.index].Equals("print")) { this.index++; ... } else if (this.tokens[this.index].Equals("var")) { this.index++; ... } else if (this.tokens[this.index].Equals("read_int")) { this.index++; ... } else if (this.tokens[this.index].Equals("for")) { this.index++; ... } else if (this.tokens[this.index] is string) { this.index++; ... } else { throw new Exception("parse error at token " + this.index + ": " + this.tokens[this.index]); } ... }
When a token is identified, an AST node is created and any further parsing required by the node is performed. The code required for creating the print AST node is as follows:
// <stmt> := print <expr> if (this.tokens[this.index].Equals("print")) { this.index++; Print print = new Print(); print.Expr = this.ParseExpr(); result = print; }
Two things happen here. The print token is discarded by incrementing the index counter, and a call to the ParseExpr method is made to obtain an Expr node, since the language definition requires that the print token be followed by an expression.
Figure 6 shows the ParseExpr code. It traverses the list of tokens from the current index, identifying tokens that satisfy the language definition of an expression. In this case, the method simply looks for strings, integers, and variables (which were created by the scanner instance) and returns the appropriate AST nodes representing these expressions.
Figure 6 ParseExpr Performs Parsing of Expression Nodes
// <expr> := <string> // | <int> // | <ident> private Expr ParseExpr() { ... if (this.tokens[this.index] is StringBuilder) { string value = ((StringBuilder)this.tokens[this.index++]).ToString(); StringLiteral stringLiteral = new StringLiteral(); stringLiteral.Value = value; return stringLiteral; } else if (this.tokens[this.index] is int) { int intValue = (int)this.tokens[this.index++]; IntLiteral intLiteral = new IntLiteral(); intLiteral.Value = intValue; return intLiteral; } else if (this.tokens[this.index] is string) { string ident = (string)this.tokens[this.index++]; Variable var = new Variable(); var.Ident = ident; return var; } ... }
For string statements that satisfy the "<stmt> ; <stmt>" language syntax definition, the sequence AST node is used. This sequence node contains two pointers to stmt nodes and forms the basis of the AST tree structure. The following details the code used to deal with the sequence case:
if (this.index < this.tokens.Count && this.tokens[this.index] == Scanner.Semi) { this.index++; if (this.index < this.tokens.Count && !this.tokens[this.index].Equals("end")) { Sequence sequence = new Sequence(); sequence.First = result; sequence.Second = this.ParseStmt(); result = sequence; } }
The AST tree shown in Figure 7 is the result of the following snippet of Good for Nothing code:
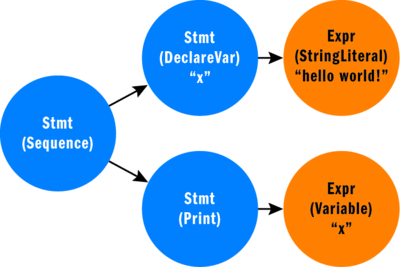
Figure 7** helloworld.gfn AST Tree and High-Level Trace **(Click the image for a larger view)
var x = "hello world!"; print x;
Targeting the .NET Framework
Before I get into the code that performs code generation, I should first step back and discuss my target. So here I will describe the compiler services that the .NET CLR provides, including the stack-based virtual machine, the type system, and the libraries used for .NET assembly creation. I'll also briefly touch on the tools that are required to identify and diagnose errors in compiler output.
The CLR is a virtual machine, meaning it is a piece of software that emulates a computer system. Like any computer, the CLR has a set of low-level operations it can perform, a set of memory services, and an assembly language to define executable programs. The CLR uses an abstract stack-based data structure to model code execution, and an assembly language, called Intermediate Language (IL), to define the operations you can perform on the stack.
When a computer program defined in IL is executed, the CLR simply simulates the operations specified against a stack, pushing and popping data to be executed by an instruction. Suppose you want to add two numbers using IL. Here's the code used to perform 10 + 20:
ldc.i4 10 ldc.i4 20 add
The first line (ldc.i4 10) pushes the integer 10 onto the stack. Then the second line (ldc.i4 20) pushes the integer 20 onto the stack. The third line (add) pops the two integers off the stack, adds them, and pushes the result onto the stack.
Simulation of the stack machine occurs by translating IL and the stack semantics to the underlying processor's machine language, either at run time through just-in-time (JIT) compilation or before hand through services like Native Image Generator (Ngen).
There are lots of IL instructions available for building your programs—they range from basic arithmetic to flow control to a variety of calling conventions. Details about all the IL instructions can be found in Partition III of the European Computer Manufacturers Association (ECMA) specification (available at msdn2.microsoft.com/aa569283).
The CLR's abstract stack performs operations on more than just integers. It has a rich type system, including strings, integers, booleans, floats, doubles, and so on. In order for my language to run safely on the CLR and interoperate with other .NET-compliant languages, I incorporate some of the CLR type system into my own program. Specifically, the Good for Nothing language defines two types—numbers and strings—which I map to System.Int32 and System.String.
The Good for Nothing compiler makes use of a Base Class Library (BCL) component called System.Reflection.Emit to deal with IL code generation and .NET assembly creation and packaging. It's a low-level library, which sticks close to the bare metal by providing simple code-generation abstractions over the IL language. The library is also used in other well-known BCL APIs, including System.Xml.XmlSerializer.
The high-level classes that are required to create a .NET assembly (shown in Figure 8) somewhat follow the builder software design pattern, with builder APIs for each logical .NET metadata abstraction. The AssemblyBuilder class is used to create the PE file and set up the necessary .NET assembly metadata elements like the manifest. The ModuleBuilder class is used to create modules within the assembly. TypeBuilder is used to create Types and their associated metadata. MethodBuilder and LocalBuilder deal with adding methods to types and locals to methods, respectively. The ILGenerator class is used to generate the IL code for methods, utilizing the OpCodes class, which is a big enumeration containing all possible IL instructions. All of these Reflection.Emit classes are used in the Good for Nothing code generator.
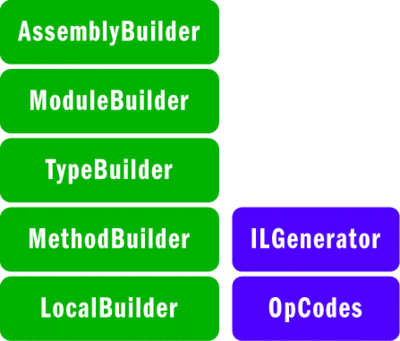
Figure 8** Reflection.Emit Libraries Used to Build a .NET Assembly **(Click the image for a larger view)
Tools for Getting Your IL Right
Even the most seasoned compiler hackers make mistakes at the code-generation level. The most common bug is bad IL code, which causes unbalance in the stack. The CLR will typically throw an exception when bad IL is found (either when the assembly is loaded or when the IL is JITed, depending on the trust level of the assembly). Diagnosing and repairing these errors is simple with an SDK tool called peverify.exe. It performs a verification of the IL, making sure the code is correct and safe to execute.
For example, here is some IL code that attempts to add the number 10 to the string "bad":
ldc.i4 10 ldstr "bad" add
Running peverify over an assembly that contains this bad IL will result in the following error:
[IL]: Error: [C:\MSDNMagazine\Sample.exe : Sample::Main][offset 0x0000002][found ref 'System .String'] Expected numeric type on the stack.
In this example, peverify reports that the add instruction expected two numeric types where it instead found an integer and a string.
ILASM (IL assembler) and ILDASM (IL disassembler) are two SDK tools you can use to compile text IL into .NET assemblies and decompile assemblies out to IL, respectively. ILASM allows for quick and easy testing of IL instruction streams that will be the basis of the compiler output. You simply create the test IL code in a text editor and feed it in to ILASM. Meanwhile, the ILDASM tool can quickly peek at the IL a compiler has generated for a particular code path. This includes the IL that commercial compilers emit, such as the C# compiler. It offers a great way to see the IL code for statements that are similar between languages; in other words, the IL flow control code generated for a C# for loop could be reused by other compilers that have similar constructs.
The Code Generator
The code generator for the Good for Nothing compiler relies heavily on the Reflection.Emit library to produce an executable .NET assembly. I will describe and analyze the important parts of the class; the other bits are left for you to peruse at your leisure.
The CodeGen constructor, which is shown in Figure 9, sets up the Reflection.Emit infrastructure, which is required before I can start emitting code. I begin by defining the assembly name and passing that to the assembly builder. In this example, I use the source file name as the assembly name. Next is the ModuleBuilder definition—for one module definition, this uses the same name as the assembly. I then define a TypeBuilder on the ModuleBuilder to hold the only type in the assembly. There are no types defined as first class citizens of the Good for Nothing language definition, but at least one type is necessary to hold the method, which will run on startup. The MethodBuilder defines a Main method to hold the IL that will be generated for the Good for Nothing code. I have to call SetEntryPoint on this MethodBuilder so it will run on startup when a user runs the executable. And I create the global ILGenerator (il) from the MethodBuilder using the GetILGenerator method.
Figure 9 CodeGen Constructor
Emit.ILGenerator il = null; Collections.Dictionary<string, Emit.LocalBuilder> symbolTable; public CodeGen(Stmt stmt, string moduleName) { if (Path.GetFileName(moduleName) != moduleName) { throw new Exception("can only output into current directory!"); } AssemblyName name = new AssemblyName(Path.GetFileNameWithoutExtension(moduleName)); Emit.AssemblyBuilder asmb = AppDomain.CurrentDomain.DefineDynamicAssembly(name, Emit.AssemblyBuilderAccess.Save); Emit.ModuleBuilder modb = asmb.DefineDynamicModule(moduleName); Emit.TypeBuilder typeBuilder = modb.DefineType("Foo"); Emit.MethodBuilder methb = typeBuilder.DefineMethod("Main", Reflect.MethodAttributes.Static, typeof(void), System.Type.EmptyTypes); // CodeGenerator this.il = methb.GetILGenerator(); this.symbolTable = new Dictionary<string, Emit.LocalBuilder>(); // Go Compile this.GenStmt(stmt); il.Emit(Emit.OpCodes.Ret); typeBuilder.CreateType(); modb.CreateGlobalFunctions(); asmb.SetEntryPoint(methb); asmb.Save(moduleName); this.symbolTable = null; this.il = null; }
Once the Reflection.Emit infrastructure is set up, the code generator calls the GenStmt method, which is used to walk the AST. This generates the necessary IL code through the global ILGenerator. Figure 10 shows a subset of the GenStmt method, which, at first invocation, starts with a Sequence node and proceeds to walk the AST switching on the current AST node type.
Figure 10 Subset of GenStmt Method
private void GenStmt(Stmt stmt) { if (stmt is Sequence) { Sequence seq = (Sequence)stmt; this.GenStmt(seq.First); this.GenStmt(seq.Second); } else if (stmt is DeclareVar) { ... } else if (stmt is Assign) { ... } else if (stmt is Print) { ... } }
The code for the DeclareVar (declaring a variable) AST node is as follows:
else if (stmt is DeclareVar) { // declare a local DeclareVar declare = (DeclareVar)stmt; this.symbolTable[declare.Ident] = this.il.DeclareLocal(this.TypeOfExpr(declare.Expr)); // set the initial value Assign assign = new Assign(); assign.Ident = declare.Ident; assign.Expr = declare.Expr; this.GenStmt(assign); }
The first thing I need to accomplish here is to add the variable to a symbol table. The symbol table is a core compiler data structure that is used to associate a symbolic identifier (in this case, the string-based variable name) with its type, location, and scope within a program. The Good for Nothing symbol table is simple, as all variable declarations are local to the Main method. So I associate a symbol with a LocalBuilder using a simple Dictionary<string, LocalBuilder>.
After adding the symbol to the symbol table, I translate the DeclareVar AST node to an Assign node to assign the variable declaration expression to the variable. I use the following code to generate Assignment statements:
else if (stmt is Assign) { Assign assign = (Assign)stmt; this.GenExpr(assign.Expr, this.TypeOfExpr(assign.Expr)); this.Store(assign.Ident, this.TypeOfExpr(assign.Expr)); }
Doing this generates the IL code to load an expression onto the stack and then emits IL to store the expression in the appropriate LocalBuilder.
The GenExpr code shown in Figure 11 takes an Expr AST node and emits the IL required to load the expression onto the stack machine. StringLiteral and IntLiteral are similar in that they both have direct IL instructions that load the respective strings and integers onto the stack: ldstr and ldc.i4.
Figure 11 GenExpr Method
private void GenExpr(Expr expr, System.Type expectedType) { System.Type deliveredType; if (expr is StringLiteral) { deliveredType = typeof(string); this.il.Emit(Emit.OpCodes.Ldstr, ((StringLiteral)expr).Value); } else if (expr is IntLiteral) { deliveredType = typeof(int); this.il.Emit(Emit.OpCodes.Ldc_I4, ((IntLiteral)expr).Value); } else if (expr is Variable) { string ident = ((Variable)expr).Ident; deliveredType = this.TypeOfExpr(expr); if (!this.symbolTable.ContainsKey(ident)) { throw new Exception("undeclared variable '" + ident + "'"); } this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[ident]); } else { throw new Exception("don't know how to generate " + expr.GetType().Name); } if (deliveredType != expectedType) { if (deliveredType == typeof(int) && expectedType == typeof(string)) { this.il.Emit(Emit.OpCodes.Box, typeof(int)); this.il.Emit(Emit.OpCodes.Callvirt, typeof(object).GetMethod("ToString")); } else { throw new Exception("can't coerce a " + deliveredType.Name + " to a " + expectedType.Name); } } }
Variable expressions simply load a method's local variable onto the stack by calling ldloc and passing in the respective LocalBuilder. The last section of code shown in Figure 11 deals with converting the expression type to the expected type (called type coercion). For instance, a type may need conversion in a call to the print method where an integer needs to be converted to a string so that print can be successful.
Figure 12 demonstrates how variables are assigned expressions in the Store method. The name is looked up via the symbol table and the respective LocalBuilder is then passed to the stloc IL instruction. This simply pops the current expression from the stack and assigns it to the local variable.
Figure 12 Store Expressions to a Variable
private void Store(string name, Type type) { if (this.symbolTable.ContainsKey(name)) { Emit.LocalBuilder locb = this.symbolTable[name]; if (locb.LocalType == type) { this.il.Emit(Emit.OpCodes.Stloc, this.symbolTable[name]); } else { throw new Exception("'" + name + "' is of type " + locb.LocalType.Name + " but attempted to store value of type " + type.Name); } } else { throw new Exception("undeclared variable '" + name + "'"); } }
The code that is utilized to generate the IL for the Print AST node is interesting because it calls in to a BCL method. The expression is generated onto the stack, and the IL call instruction is used to call the System.Console.WriteLine method. Reflection is used to obtain the WriteLine method handle that is needed to pass to the call instruction:
else if (stmt is Print) { this.GenExpr(((Print)stmt).Expr, typeof(string)); this.il.Emit(Emit.OpCodes.Call, typeof(System.Console).GetMethod("WriteLine", new Type[] { typeof(string) })); }
When a call to a method is performed, method arguments are popped off the stack last on, first in. In other words, the first argument of the method is the top stack item, the second argument the next item, and so on.
The most complex code here is the code that generates IL for my Good for Nothing for loops (see Figure 13). It is quite similar to how commercial compilers would generate this kind of code. However, the best way to explain the for loop code is to look at the IL that is generated, which is shown in Figure 14.
Figure 14 For Loop IL Code
// for x = 0 IL_0006: ldc.i4 0x0 IL_000b: stloc.0 // jump to the test IL_000c: br IL_0023 // execute the loop body IL_0011: ... // increment the x variable by 1 IL_001b: ldloc.0 IL_001c: ldc.i4 0x1 IL_0021: add IL_0022: stloc.0 // TEST // load x, load 100, branch if // x is less than 100 IL_0023: ldloc.0 IL_0024: ldc.i4 0x64 IL_0029: blt IL_0011
Figure 13 For Loop Code
else if (stmt is ForLoop) { // example: // var x = 0; // for x = 0 to 100 do // print "hello"; // end; // x = 0 ForLoop forLoop = (ForLoop)stmt; Assign assign = new Assign(); assign.Ident = forLoop.Ident; assign.Expr = forLoop.From; this.GenStmt(assign); // jump to the test Emit.Label test = this.il.DefineLabel(); this.il.Emit(Emit.OpCodes.Br, test); // statements in the body of the for loop Emit.Label body = this.il.DefineLabel(); this.il.MarkLabel(body); this.GenStmt(forLoop.Body); // to (increment the value of x) this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[forLoop.Ident]); this.il.Emit(Emit.OpCodes.Ldc_I4, 1); this.il.Emit(Emit.OpCodes.Add); this.Store(forLoop.Ident, typeof(int)); // **test** does x equal 100? (do the test) this.il.MarkLabel(test); this.il.Emit(Emit.OpCodes.Ldloc, this.symbolTable[forLoop.Ident]); this.GenExpr(forLoop.To, typeof(int)); this.il.Emit(Emit.OpCodes.Blt, body); }
The IL code starts with the initial for loop counter assignment and immediately jumps to the for loop test using the IL instruction br (branch). Labels like the ones listed to the left of the IL code are used to let the runtime know where to branch to the next instruction. The test code checks to see if the variable x is less than 100 using the blt (branch if less than) instruction. If this is true, the loop body is executed, the x variable is incremented, and the test is run again.
The for loop code in Figure 13 generates the code required to perform the assignment and increment operations on the counter variable. It also uses the MarkLabel method on ILGenerator to generate labels that the branch instructions can branch to.
Wrapping Up ... Almost
I've walked through the code base to a simple .NET compiler and explored some of the underlying theory. This article is intended to provide you with a foundation to the mysterious world of compiler construction. While you'll find valuable information online, there are some books you should also check out. I recommend picking up copies of: Compiling for the .NET Common Language Runtime by John Gough (Prentice Hall, 2001), Inside Microsoft IL Assembler by Serge Lidin (Microsoft Press®, 2002), Programming Language Pragmatics by Michael L. Scott (Morgan Kaufmann, 2000), and Compilers: Principles, Techniques, and Tools by Alfred V. Oho, Monica S. Lam, Ravi Sethi, and Jeffrey Ullman (Addison Wesley, 2006).
That pretty well covers the core of what you need to understand for writing your own language compiler; however, I'm not quite finished with this discussion. For the seriously hardcore, I'd like to look at some advanced topics for taking your efforts even further.
Dynamic Method Invocation
Method calls are the cornerstone of any computer language, but there's a spectrum of calls you can make. Newer languages, such as Python, delay the binding of a method and the invocation until the absolute last minute—this is called dynamic invocation. Popular dynamic languages, such as Ruby, JavaScript, Lua, and even Visual Basic, all share this pattern. In order for a compiler to emit code to perform a method invocation, the compiler must treat the method name as a symbol, passing it to a runtime library that will perform the binding and invocation operations as per the language semantics.
Suppose you turn off Option Strict in the Visual Basic 8.0 compiler. Method calls become late bound and the Visual Basic runtime will perform the binding and invocation at run time.
Rather than the Visual Basic compiler emitting an IL call instruction to the Method1 method, it instead emits a call instruction to the Visual Basic runtime method called CompilerServices.NewLateBinding.LateCall. In doing so, it passes in an object (obj) and the symbolic name of the method (Method1), along with any method arguments. The Visual Basic LateCall method then looks up the Method1 method on the object using Reflection and, if it is found, performs a Reflection-based method invocation:
Option Strict Off Dim obj obj.Method1() IL_0001: ldloc.0 IL_0003: ldstr "Method1" ... IL_0012: call object CompilerServices.NewLateBinding::LateCall(object, ... , string, ...)
Using LCG to Perform Quick Late-Binding
Reflection-based method invocation can be notoriously slow (see my article "Reflection: Dodge Common Performance Pitfalls to Craft Speedy Applications" at msdn.microsoft.com/msdnmag/issues/05/07/Reflection). Both the binding of the method and the method invocation are many orders of magnitude slower than a simple IL call instruction. The .NET Framework 2.0 CLR includes a feature called Lightweight Code Generation (LCG), which can be used to dynamically create code on the fly to bridge the call site to the method using the faster IL call instruction. This significantly speeds up method invocation. The lookup of the method on an object is still required, but once it's found, a DynamicMethod bridge can be created and cached for each repeating call.
Figure 15 shows a very simple version of a late binder that performs dynamic code generation of a bridge method. It first looks up the cache and checks to see if the call site has been seen before. If the call site is being run for the first time, it generates a DynamicMethod that returns an object and takes an object array as an argument. The object array argument contains the instance object and the arguments that are to be used for the final call to the method. IL code is generated to unpack the object array on to the stack, starting with the instance object and then the arguments. A call instruction is then emitted and the result of that call is returned to the callee.
The call to the LCG bridge method is performed through a delegate, which is very quick. I simply wrap the bridge method arguments up into an object array and then call. The first time this happens, the JIT compiler compiles the dynamic method and performs the execution of the IL, which, in turn, calls the final method.
This code is essentially what an early bound static compiler would generate. It pushes an instance object on the stack, then the arguments, and then calls the method using the call instruction. This is a slick way of delaying that semantic to the last possible minute, satisfying the late-bound calling semantics found in most dynamic languages.
The Dynamic Language Runtime
If you're serious about implementing a dynamic language on the CLR, then you must check out the Dynamic Language Runtime (DLR), which was announced by the CLR team in late April. It encompasses the tools and libraries you need to build great performing dynamic languages that interoperate with both the .NET Framework and the ecosystem of other .NET-compliant languages. The libraries provide everything that someone creating a dynamic language will want, including a high-performing implementation for common dynamic language abstractions (lightning-fast late-bound method calls, type system interoperability, and so on), a dynamic type system, a shared AST, support for Read Eval Print Loop (REPL), and more.
A deep look into the DLR is well beyond the scope of this article, but I do recommend you explore it on your own to see the services it provides to dynamic languages. More information about the DLR can be found on Jim Hugunin's blog (blogs.msdn.com/hugunin).
Joel Pobar is a former Program Manager on the CLR team at Microsoft. He now hangs out at the Gold Coast in Australia, hacking away on compilers, languages, and other fun stuff. Check out his latest .NET ramblings at callvirt.net/blog.