SQL Server
Uncover Hidden Data to Optimize Application Performance
Ian Stirk
Code download available at:DMVsinSQLServer2008_01.exe(155 KB)
This article discusses:
|
This article uses the following technologies: SQL Server |
Contents
Causes of Server Waits
Reads and Writes
Missing Indexes by Database
Costly Missing Indexes
Unused Indexes
Costly Used Indexes
Often-Used Indexes
Logically Fragmented Indexes
Costly Queries by I/O
Costly Queries by CPU
Costly CLR Queries
Most-Executed Queries
Queries Suffering from Blocking
Lowest Plan Reuse
Further Work
Many application performance problems can be traced to poorly performing database queries; however, there are many ways you can improve database performance. SQL ServerTM 2005 gathers a lot of information that you can use to identify the causes of such performance issues.
SQL Server 2005 collects data relating to running queries. This data, which is held in memory and starts accumulating after a server restart, can be used to identify numerous issues and metrics, including those surrounding table indexes, query performance, and server I/O. You can query this data via the SQL Server Dynamic Management Views (DMVs) and related Dynamic Management Functions (DMFs). These are system-based views and functions that present server state information that can be used to diagnose problems and tune database performance.
In this article, I will highlight areas where performance can be improved by using information that is already being gathered by SQL Server 2005. This approach is largely non-intrusive, as it collects and examines existing data, typically querying underlying system data.
I will demonstrate how to obtain this information, discuss the underlying DMVs, identify any caveats to be aware of when interpreting the data, and point you to additional areas where you might be able to realize performance improvements. To do this, I will present and examine a series of SQL scripts that detail the various aspects of the data collected by SQL Server 2005. A complete and fully commented version of this script can be downloaded from the MSDN® Magazine Web site.
Some of the steps I will discuss concentrate on the server as a whole, including all the databases hosted on a given server. When necessary, it is possible to concentrate on a given database by adding the appropriate filtering, such as adding its name to the query.
Conversely, some of the queries join to the sys.indexes DMV, which is a database-specific view that reports results only for the current database. In these cases, I amended the queries to iterate over all the databases on the server by using the system stored procedure sp_MSForEachDB, thus presenting server-wide results.
In order to target the most relevant records for a given performance metric, I will limit the number of records returned using the SQL TOP function.
Causes of Server Waits
A user typically experiences poor performance as a series of waits. Whenever a SQL query is able to run but is waiting on another resource, it records details about the cause of the wait. These details can be accessed using the sys.dm_os_wait_stats DMV. You can examine the accumulated cause of all the waits using the SQL script shown in Figure 1.
SELECT TOP 10 [Wait type] = wait_type, [Wait time (s)] = wait_time_ms / 1000,
[% waiting] = CONVERT(DECIMAL(12,2),
wait_time_ms * 100.0 / SUM(wait_time_ms) OVER())
FROM sys.dm_os_wait_stats
WHERE wait_type NOT LIKE '%SLEEP%'
ORDER BY wait_time_ms DESC;
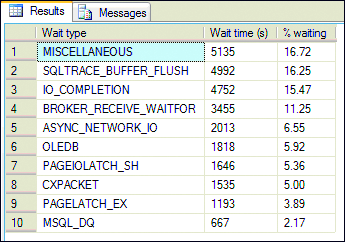
Figure 1** SQL Query Records Causes of Wait Times **
The result of running this script lists the wait type ordered by the total time spent waiting. In my sample results, you can see that I/O is ranked relatively high as a cause of waiting. Note that I am only interested in logical I/O (reading/writing data in memory), rather than physical I/O, since after the initial load the data is typically in memory.
Reads and Writes
High I/O usage can be an indicator of poor data access mechanisms. SQL Server 2005 keeps track of the total number of reads and writes that each query uses to fulfill its needs. You can sum these numbers to determine which databases perform the most overall reads and writes.
The sys.dm_exec_query_stats DMV contains aggregate performance statistics for cached query plans. This includes information about the number of logical reads and writes and the number of times the query has executed. When you join this DMV to the sys.dm_exec_sql_text DMF, you can sum the number of reads and writes by database. Notice that I use the new SQL Server 2005 CROSS APPLY operator to handle this join. The script I use to identify which databases are using the most reads and writes is shown in Figure 2.
SELECT TOP 10 [Total Reads] = SUM(total_logical_reads),
[Execution count] = SUM(qs.execution_count),
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
GROUP BY DB_NAME(qt.dbid)
ORDER BY [Total Reads] DESC;
SELECT TOP 10 [Total Writes] = SUM(total_logical_writes),
[Execution count] = SUM(qs.execution_count),
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
GROUP BY DB_NAME(qt.dbid)
ORDER BY [Total Writes] DESC;
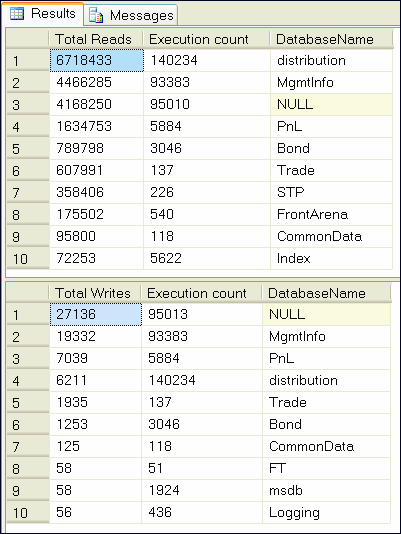
Figure 2** Identifying the Most Reads and Writes **
The results indicate which databases are reading and writing the most logical pages. The top set of data is sorted by Total Reads, while the bottom set is sorted by Total Writes.
As you can clearly see, DatabaseName is set to NULL in a couple of instances. This setting identifies ad hoc and prepared SQL statements. This detail is useful for identifying the degree of usage of native SQL—which in itself is a potential cause of many different problems. (For example, this indicates that query plans are not being reused, code is not being reused, and there is a potential concern in the area of security.)
A high value for tempdb may suggest excessive use of temporary tables, excessive recompiles, or an inefficient device. The results could be used to identify which databases are used primarily for reporting (lots of selecting of data) as opposed to transactional databases (lots of updates). Each database type, reporting or transactional, has different indexing needs. I will examine this in more detail in a moment.
Missing Indexes by Database
When SQL Server processes a query, the optimizer keeps a record of the indexes it attempts to use to satisfy the query. If these indexes are not found, SQL Server creates a record of the missing index. This information can be viewed using the sys.dm_db_missing_index_details DMV.
You can show which databases on a given server are missing indexes using the script shown in Figure 3. Discovering these missing indexes is important because the indexes will often provide an ideal path to retrieving query data. In turn, this can reduce I/O and improve overall performance. My script examines sys.dm_db_missing_index_details and sums up the number of missing indexes per database, making it easy to determine which databases need further investigation.
SELECT DatabaseName = DB_NAME(database_id) ,
[Number Indexes Missing] = count(*)
FROM sys.dm_db_missing_index_details
GROUP BY DB_NAME(database_id)
ORDER BY 2 DESC;
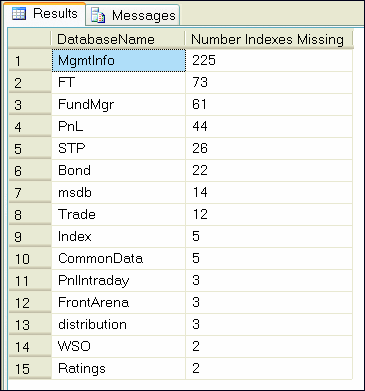
Figure 3** Identifying Missing Databases **
Databases are quite often divided into transactional and reporting-based systems. It should be a relatively easy operation for you to apply the suggested missing indexes to the reporting databases. The transactional databases, on the other hand, will typically require further investigation into the impact of the additional indexes on the underlying table data.
Costly Missing Indexes
Indexes will have varying levels of impact on query performance. You can drill down into the most costly missing indexes across all the databases on the server, finding out which missing indexes are likely to have the most significant positive impact on performance.
The sys.dm_db_missing_index_group_stats DMV notes the number of times SQL has attempted to use a particular missing index. The sys.dm_db_missing_index_details DMV details the missing index structure, such as the columns required by the query. These two DMVs are linked together via the sys.dm_db_missing_index_groups DMV. The cost of the missing index (the total cost column) is calculated as the product of the average total user cost and the average user impact multiplied by the sum of the user seeks and user scans.
You can use the script shown in Figure 4 to identify the most costly missing indexes. The results of this query, which are ordered by Total Cost, show the cost of the most important missing indexes along with details about the database/schema/table and the columns required in the missing indexes. Specifically, this script identifies which columns are used in equality and inequality SQL statements. Additionally, it reports which other columns should be used as included columns in a missing index. Included columns allow you to satisfy more covered queries without obtaining the data from the underlying page, thus using fewer I/O operations and improving performance.
SELECT TOP 10 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0) ,
avg_user_impact , TableName = statement , [EqualityUsage] = equality_columns ,
[InequalityUsage] = inequality_columns , [Include Cloumns] = included_columns
FROM sys.dm_db_missing_index_groups g
INNER JOIN sys.dm_db_missing_index_group_stats s ON s.group_handle = g.index_group_handle
INNER JOIN sys.dm_db_missing_index_details d ON d.index_handle = g.index_handle
ORDER BY [Total Cost] DESC;
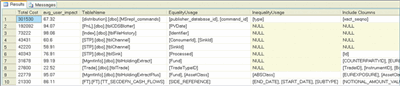
Figure 4** Cost of Missing Indexes **(Click the image for a larger view)
Note that the results do not specify the order in which the columns in the required index should be created. To determine this, you should inspect your collective SQL code base. As a general rule, the most selected columns should appear first in the index.
I should also point out that only the user columns (such as user_seeks and user_scans) are considered in calculating the cost of the missing index. This is because system columns tend to represent using statistics, Database Consistency Checking (DBCC), and Data Definition Language (DDL) commands, and these are less critical to fulfilling the business functionality (as opposed to the database admin functionality).
It is very important for you to remember that you need to take special consideration with regard to the potential cost of the additional index when any data modifications occur in the underlying table. For this reason, additional research into the underlying SQL code base should be undertaken.
If you find that numerous columns are recommended as columns to include, you should examine the underlying SQL since this may indicate that the catchall "SELECT *" statement is being used—if this turns out to indeed be the case, you should probably revise your select queries.
Unused Indexes
Unused indexes can have a negative impact on performance. This is because when the underlying table data is modified, the index may need to be updated also. This, of course, takes additional time and can even increase the probability of blocking.
When an index is used to satisfy a query and when it is updated as a result of updates applied to the underlying table data, SQL Server updates the corresponding index usage details. These usage details can be viewed to identify any unused indexes.
The sys.dm_db_index_usage_stats DMV tells how often and to what extent indexes are used. It is joined to the sys.indexes DMV, which contains information used in the creation of the index. You can inspect the various user columns for a value of 0 to identify unused indexes. The impact of the system columns is again ignored for the reasons discussed above. The script shown in Figure 5 will let you identify the most costly unused indexes.
-- Create required table structure only.
-- Note: this SQL must be the same as in the Database loop given in the following step.
SELECT TOP 1 DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name ,user_updates ,system_updates
-- Useful fields below:
--
, * INTO #TempUnusedIndexes FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], 'IsMsShipped') = 0
AND user_seeks = 0 AND user_scans = 0 AND user_lookups = 0 AND s.[object_id] = -999
-- Dummy value to get table structure.
;
-- Loop around all the databases on the server.
EXEC sp_MSForEachDB 'USE [?];
-- Table already exists.
INSERT INTO #TempUnusedIndexes SELECT TOP 10 DatabaseName = DB_NAME() ,
TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name ,user_updates ,system_updates
FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND user_seeks = 0 AND user_scans = 0 AND user_lookups = 0 AND i.name IS NOT NULL
-- Ignore HEAP indexes.
ORDER BY user_updates DESC ; '
-- Select records.
SELECT TOP 10 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC
-- Tidy up.
DROP TABLE #TempUnusedIndexes
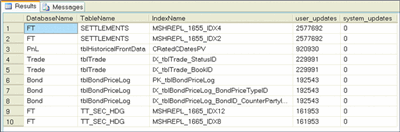
Figure 5** Identifying Most Costly Unused Indexes **(Click the image for a larger view)
The results of this query show the indexes that have not been used to retrieve data but have been updated as a result of changes in the underlying table. These updates are shown in the user_updates and system_updates columns. The results are sorted by the number of user updates that have been applied to the index.
You must collect enough information to ensure that the index is not used—you don't want to inadvertently remove an index that is perhaps critical for a query that is run only quarterly or annually. Also, note that some indexes are used to constrain the insertion of duplicate records or for ordering of data; these factors must also be considered before removing any unused indexes.
The basic form of the query is applied only to the current database, since it joins to the sys.indexes DMV, which is only concerned with the current database. You can extract results for all the databases on the server using the system stored procedure sp_MSForEachDB. The pattern I use to do this is explained in the sidebar "Looping through All Databases". I use this pattern in other sections of the script as well where I want to iterate over all the databases on the server. Additionally, I filtered out indexes that are of type heap, since these represent the native structure of a table without a formal index.
Costly Used Indexes
It can also be helpful to identify the indexes (among those that are used) that are most costly in terms of changes to the underlying tables. This cost has a negative impact on performance, but the index itself may be important for data retrieval.
The sys.dm_db_index_usage_stats DMV lets you see how often and to what extent indexes are used. This DMV is joined to the sys.indexes DMV, which contains details used in the creation of the index. Inspecting the user_updates and system_updates columns will show the indexes that are highest maintenance. Figure 6 provides the script used to identify the most costly indexes and shows the results.
-- Create required table structure only.
-- Note: this SQL must be the same as in the Database loop given in the following step.
SELECT TOP 1
[Maintenance cost] = (user_updates + system_updates),
[Retrieval usage] = (user_seeks + user_scans + user_lookups),
DatabaseName = DB_NAME(),
TableName = OBJECT_NAME(s.[object_id]),
IndexName = i.name INTO #TempMaintenanceCost
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i
ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
WHERE s.database_id = DB_ID()
AND OBJECTPROPERTY(s.[object_id],
'IsMsShipped') = 0
AND (user_updates + system_updates) > 0
-- Only report on active rows.
AND s.[object_id] = -999
-- Dummy value to get table structure.
;
-- Loop around all the databases on the server.
EXEC sp_MSForEachDB 'USE [?];
-- Table already exists.
INSERT INTO #TempMaintenanceCost SELECT TOP 10 [Maintenance cost] =
(user_updates + system_updates) ,[Retrieval usage] = (user_seeks + user_scans + user_lookups) ,
DatabaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,
IndexName = i.name FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i
ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
-- Ignore HEAP indexes.
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND (user_updates + system_updates) > 0
-- Only report on active rows.
ORDER BY [Maintenance cost] DESC ; '
-- Select records.
SELECT TOP 10
FROM #TempMaintenanceCost
ORDER BY [Maintenance cost] DESC
-- Tidy up.
DROP TABLE #TempMaintenanceCost
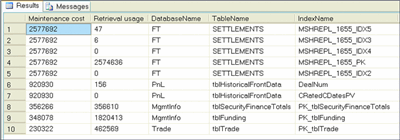
Figure 6** Identifying the Most Costly Indexes **(Click the image for a larger view)
The results reveal the most high-maintenance indexes along with details about the database/table involved. The Maintenance cost column is calculated as the sum of the user_updates and system_updates columns. The usefulness of the index (shown in the Retrieval usage column) is calculated as the sum of the various user_* columns. It is important that you consider an index's usefulness when deciding whether an index can be removed.
Where bulk modifications of the data are involved, these results can help you identify indexes that should be removed before applying updates. You can then reapply these indexes after all the updates have been made.
Often-Used Indexes
Looping through All Databases
The sys.indexes DMV is a database-specific view. Therefore, queries that join to sys.indexes report results only for the current database. You can, however, use the system stored procedure sp_MSForEachDB to iterate over all the databases on the server and thus present server-wide results. Here's the pattern I use in these cases.
- I create a temporary table with the required structure similar to the main body of code. I give it a record that does not exist (an object_id of -999) so that the temporary table structure can be created.
- The main body of code executes, looping around all the databases on the server. Note that the number of records retrieved for each database (using the TOP statement) should be the same as the number of records I want to display. Otherwise, the results may not be truly representative of the TOP n records across all the databases on the server.
- The records are extracted from the temporary table and ordered by the column that I am interested in (in this case, the user_updates column).
You can use DMVs to identify which indexes are used most often—these are the most common paths to underlying data. These are indexes that could provide significant overall performance improvements if they could themselves be improved or optimized.
The sys.dm_db_index_usage_stats DMV contains details about how often the indexes are used to retrieve data via seeks, scans, and lookups. This DMV is joined to the sys.indexes DMV, which contains details used in the creation of the index. The Usage column is calculated as the sum of all the user_* fields. This can be done using the script shown in Figure 7. The results of this query show the number of times the index has been used, sorted by Usage.
-- Create required table structure only.
-- Note: this SQL must be the same as in the Database loop given in the
-- following step.
SELECT TOP 1
[Usage]=(user_seeks+user_scans+user_lookups),DatabaseName=DB_NAME(),TableName=OBJECT_NAME(s.[object_id]),IndexName=i.name
INTO #TempUsage
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id]=i.[object_id] AND s.index_id=i.index_id
WHERE s.database_id=DB_ID() AND OBJECTPROPERTY(s.[object_id],'IsMsShipped')=0
AND (user_seeks+user_scans+user_lookups)>0 -- Only report on active rows.
AND s.[object_id]=-999 -- Dummy value to get table structure.
;
-- Loop around all the databases on the server.
EXEC sp_MSForEachDB 'USE [?];
-- Table already exists.
INSERT INTO #TempUsage SELECT TOP 10 [Usage] =
(user_seeks + user_scans + user_lookups) ,DatabaseName = DB_NAME() ,
TableName = OBJECT_NAME(s.[object_id]) ,IndexName = i.name
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
WHERE s.database_id = DB_ID() AND i.name IS NOT NULL
-- Ignore HEAP indexes.
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND (user_seeks + user_scans + user_lookups) > 0
-- Only report on active rows.
ORDER BY [Usage] DESC ; '
-- Select records.
SELECT TOP 10
FROM #TempUsage
ORDER BY [Usage] DESC
-- Tidy up.
DROP TABLE #TempUsage
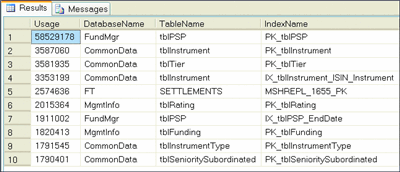
Figure 7** Identifying Most-Used Indexes **(Click the image for a larger view)
The most-used indexes represent the most important access routes to the underlying data. Obviously, you don't want to remove these indexes; however, they are worth examining to ensure they are optimal. For example, you should make sure index fragmentation is low (especially for data that is retrieved in sequence) and that underlying statistics are up to date. And you should remove any unused indexes on the tables.
Logically Fragmented Indexes
Logical index fragmentation indicates the percentage of entries in the index that are out of order. This is not the same as the page-fullness type of fragmentation. Logical fragmentation has an impact on any order scans that use an index. When possible, this fragmentation should be removed. This can be achieved with a rebuild or reorganization of the index.
You can identify the most logically fragmented indexes using the following DMVs. The sys.dm_db_index_physical_stats DMV lets you view details about the size and fragmentation of indexes. This is joined to the sys.indexes DMV, which contains details used in the creation of the index.
Figure 8 shows the script used to identify the most logically fragmented indexes. The results, which are sorted by the percent of fragmentation, show the most logically fragmented indexes across all databases, along with the database/table concerned. Note that this can take a while to run initially (several minutes), so I've commented it out in the script download.
-- Create required table structure only.
-- Note: this SQL must be the same as in the Database loop given in the
-- following step.
SELECT TOP 1
DatbaseName = DB_NAME(),
TableName = OBJECT_NAME(s.[object_id]),
IndexName = i.name,
[Fragmentation %] = ROUND(avg_fragmentation_in_percent, 2) INTO #TempFragmentation
FROM sys.DM_DB_INDEX_PHYSICAL_STATS(DB_ID(), NULL, NULL, NULL, NULL) s
INNER JOIN sys.indexes i
ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
WHERE s.[object_id] = -999 -- Dummy value just to get table structure.
;
-- Loop around all the databases on the server.
EXEC sp_MSForEachDB 'USE [?]; -- Table already exists. INSERT INTO #TempFragmentation
SELECT TOP 10 DatbaseName = DB_NAME() ,TableName = OBJECT_NAME(s.[object_id]) ,
IndexName = i.name ,[Fragmentation %] = ROUND(avg_fragmentation_in_percent,2)
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id
WHERE s.database_id = DB_ID() AND i.name IS NOT NULL
-- Ignore HEAP indexes.
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Fragmentation %] DESC ; '
-- Select records.
SELECT TOP 10
FROM #TempFragmentation
ORDER BY [Fragmentation %] DESC
-- Tidy up.
DROP TABLE #TempFragmentation
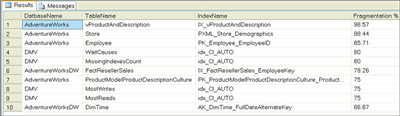
Figure 8** Identifying Logically Fragmented Indexes **(Click the image for a larger view)
Costly Queries by I/O
I/O is a measure of the number of reads/writes a query makes. This can be used as an indicator of how efficient a query is—queries that use a lot of I/O are often good subjects for performance improvements.
The sys.dm_exec_query_stats DMV provides aggregate performance statistics for cached query plans, including details about physical and logical reads/writes and the number of times the query has executed. It contains offsets used to extract the actual SQL from its contained parent SQL. This DMV is joined to the sys.dm_exec_sql_text DMF, which contains information about the SQL batch that the I/O relates to. The various offsets are applied to this batch to obtain the underlying individual SQL queries. The script is shown in Figure 9. The results, which are sorted by average I/O, show the average I/O, total I/O, individual query, parent query (if individual query is part of a batch), and the database name.
SELECT TOP 10
[Average IO] = (total_logical_reads + total_logical_writes) / qs.execution_count,
[Total IO] = (total_logical_reads + total_logical_writes),
[Execution count] = qs.execution_count,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
ORDER BY [Average IO] DESC;
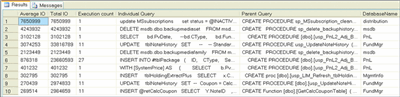
Figure 9** Identifying Most Costly Queries by I/O **(Click the image for a larger view)
Since I/O is a reflection of the amount of data, the query shown in the Individual Query column can help you determine areas where I/O can be reduced and performance improved. It is possible to feed the query into the Database Tuning Advisor to determine whether any indexes/statistics should be added to improve the query's performance. Statistics include details about the distribution and density of the underlying data. This is used by the query optimizer when determining an optimal query access plan.
It might also be useful to check to see if there is a link between the table in these queries and the indexes listed in the Missing Indexes section. (But note that it is important to investigate the impact of creating indexes on tables that experience many updates since any additional indexes will increase the time taken to update the underlying table data.)
The script could be altered to report only reads or only writes, which is useful for reporting databases or transactional databases, respectively. You might also want to report on the total or average value and sort accordingly. High values for reads can suggest missing or incomplete indexes or badly designed queries or tables.
Some caution should be taken when interpreting results that use the sys.dm_exec_query_stats DMV. For example, a query plan could be removed from the procedure cache at any time and not all queries get cached. While this will affect the results, the results should nonetheless be indicative of the most costly queries.
Costly Queries by CPU
Another rather useful approach that you can take is to analyze the most costly queries in terms of CPU usage. This approach can be very indicative of queries that are performing poorly. The DMVs that I will use here are the same as the ones I just used for examining queries in terms of I/O. The query that you see in Figure 10 allows you to identify the most costly queries as measured by CPU usage.
SELECT TOP 10
[Average CPU used] = total_worker_time / qs.execution_count,
[Total CPU used] = total_worker_time,
[Execution count] = qs.execution_count,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
ORDER BY [Average CPU used] DESC;
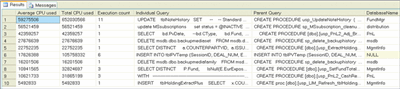
Figure 10** SQL Query Records Causes of Wait Times **(Click the image for a larger view)
This query returns the average CPU usage, the total CPU usage, the individual query and parent query (if the individual query is part of a batch), and the corresponding database name. And, as noted previously, it is probably worthwhile to run the Database Tuning Advisor on the query to determine if further improvements can be made.
Costly CLR Queries
SQL Server is increasingly making use of the CLR. Therefore, it can be helpful to determine which queries make the most use of the CLR, which includes include stored procedures, functions, and triggers.
The sys.dm_exec_query_stats DMV contains details about total_clr_time and the number of times the query has executed. It also contains offsets used to extract the actual query from its contained parent query. This DMV is joined to the sys.dm_exec_sql_text DMF, which contains information about the SQL batch. The various offsets are applied to obtain the underlying SQL. Figure 11 shows the query used to identify the most costly CLR queries.
SELECT TOP 10
[Average CLR Time] = total_clr_time / execution_count,
[Total CLR Time] = total_clr_time,
[Execution count] = qs.execution_count,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
WHERE total_clr_time <> 0
ORDER BY [Average CLR Time] DESC;

Figure 11** Identifying Most Costly CLR Queries **(Click the image for a larger view)
This returns the average CLR time, the total CLR time, the execution count, the individual query, the parent query, and the database name. Once again, it is worthwhile to run the Database Tuning Advisor on the query to determine if further improvements can be made.
Most-Executed Queries
You can modify the previous sample for costly CLR queries to identify the queries that are executed most often. Note that the same DMVs apply here. Improving the performance of a query that is executed very often can provide a more substantial performance improvement than optimizing a large query that is rarely run. (For a sanity check, this could be cross-checked by examining those queries that use the most accumulated CPU or I/O.) Another benefit of improving a frequently run query is that it also provides an opportunity to reduce the number of locks and transaction length. The end result is, of course, you've improved overall system responsiveness.
You can identify the queries that execute most often, using the query shown in Figure 12. Running this will display the execution count, individual query, parent query (if individual query is part of a batch), and the related database. Once again, it is worthwhile to run the query in the Database Tuning Advisor to determine if further improvements can be made.
SELECT TOP 10
[Execution count] = execution_count,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
ORDER BY [Execution count] DESC;
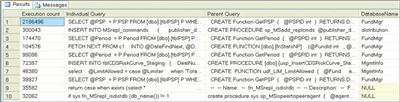
Figure 12** Identifying Queries that Execute Most Often **(Click the image for a larger view)
Queries Suffering from Blocking
Queries that suffer the most from blocking are typically long-running queries. After identifying these queries, you can analyze them to determine whether they can and should be rewritten to reduce blocking. Causes of blocking include using objects in an inconsistent order, conflicting transaction scopes, and updating of unused indexes.
The sys.dm_exec_query_stats DMV, which I've already discussed, contains columns that can be used to identify the queries that suffer the most from blocking. Average time blocked is calculated as the difference between total_elaspsed_time and total_worker_time, divided by the execution_count.
The sys.dm_exec_sql_text DMF contains details about the SQL batch that the blocking relates to. The various offsets are applied to this to obtain the underlying SQL.
Using the query shown in Figure 13, you can identify the queries that suffer the most from blocking. The results show the average time blocked, total time blocked, execution count, individual query, parent query, and related database. While these results are sorted by Average Time Blocked, sorting by Total Time Blocked can also be useful.
SELECT TOP 10
[Average Time Blocked] = (total_elapsed_time - total_worker_time) / qs.execution_count,
[Total Time Blocked] = total_elapsed_time - total_worker_time,
[Execution count] = qs.execution_count,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid)
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
ORDER BY [Average Time Blocked] DESC;
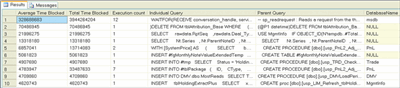
Figure 13** Identifying Queries Most Often Blocked **(Click the image for a larger view)
If you examine the query, you might find design problems (such as missing indexes), transaction problems (resources used out of order), and so on. The Database Tuning Advisor may also highlight possible improvements.
Lowest Plan Reuse
One of the advantages of using stored procedures is that the query plan is cached and can be reused without compiling the query. This saves time, resources, and improves performance. You can identify the query plans that have the lowest reuse to further investigate why the plans are not being reused. You may find that some can be rewritten to optimize reuse.
Figure 14 shows the script I've written to identify queries with the lowest plan reuse. This technique uses DMVs that I've already discussed, along with one I haven't yet mentioned: dm_exec_cached_plans. This DMV also contains details about query plans that have been cached by SQL Server. As you can see, the results provide the number of times a plan has been used (the Plan usage column), the individual query, the parent query, and the database name.
SELECT TOP 10
[Plan usage] = cp.usecounts,
[Individual Query] = SUBSTRING(qt.text, qs.statement_start_offset / 2, (CASE
WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset) / 2),
[Parent Query] = qt.text,
DatabaseName = DB_NAME(qt.dbid),
cp.cacheobjtype
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
INNER JOIN sys.dm_exec_cached_plans AS cp
ON qs.plan_handle = cp.plan_handle
WHERE cp.plan_handle = qs.plan_handle
ORDER BY [Plan usage] ASC;
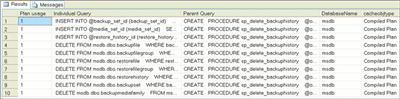
Figure 14** Identifying Queries with Lowest Plan Reuse **(Click the image for a larger view)
You can then examine the individual queries that come up in order to identify the reason for these plans not being reused more often, if at all. One possible reason is that the query is being recompiled each time it runs—this can occur if the query contains various SET statements or temporary tables. For a more detailed discussion about recompiles and plan caching, see the paper "Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005" (available at microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx).
Note that you should also ensure that the query has had ample opportunity to execute multiple times. You can use an associated SQL trace file to confirm this.
Further Work
Keep in mind that the metrics exposed by the various DMVs are not stored permanently but are only held in memory. When SQL Server 2005 restarts, these metrics are lost.
You could create tables regularly based on the output from the DMVs, storing the results with a timestamp. You could then inspect these tables in order of timestamp to identify the impact of any application changes or the impact of a given job or time-based processing. For instance, what is the impact of month-end processing procedures?
Similarly, you could correlate a given trace file workload with the changes in such tables to determine the impact of a given workload (such as daily or month-end) on missing indexes, most used queries, or so on. The script I've included can be edited to create these tables, running on a periodic basis as part of an ongoing maintenance task.
It is also possible to create custom reports with Visual Studio 2005 that use the script discussed in this article. These can be easily integrated into SQL Server Management Studio, providing a more pleasing representation of the data.
Wherever possible, you should attempt to integrate the methods I've described with other methodologies, such as tracing and ratio analysis. This will give you a more complete picture of the changes needed to improve your database performance.
I've demonstrated here the usefulness of the wealth of information that SQL Server 2005 accumulates during the normal course if its work. Querying this information provides positive leads that should prove useful in the ongoing endeavor to improve query performance. You may, for example, discover the cause of server waits, locate unused indexes that are having a negative impact on performance, and determine which are the most common queries and which queries are the most costly. The possibilities are numerous once you start exploring this hidden data. There is a lot more to learn about DMVs and I hope this article has whetted your appetite to investigate them further.
Ian Stirk has been working in IT as a developer, designer, and architect since 1987. He holds the following qualifications: M.Sc., MCSD, MCDBA, and SCJP. Ian is a freelance consultant working with Microsoft technologies in London, England. He can be contacted at Ian_Stirk@yahoo.com.