span.sup { vertical-align:text-top; }
Transactions
Build Scalable Systems That Handle Failure Without Losing Data
Udi Dahan
This article discusses:
|
This article uses the following technologies: WCF, MSMQ |
Contents
HTTP and Message Loss
Durable Messaging
Systems Consistency
Transactional Messaging
Transient Conditions
Deserialization Errors
Messages in the Error Queue
Time and Message Loss
TimetoBeReceived
Call Stack Problems
Large Messages
Small Messages from Large
Idempotent Messaging
Long-Running Processes
Learning from Mistakes
Designing distributed systems has never been easier. With the increasing power coming with every version of the CLR, the productivity of Visual Studio®, and the fine-grained control found in frameworks like Windows® Communication Foundation (WCF), developers have all the tools they need to build scalable systems. Unfortunately, it is not enough.
When working on a large-scale distributed system, my team found out that developing robust systems that handle failure scenarios without losing data is far from trivial. It's not a failing in the toolset, though; these tools need to be employed in very specific patterns to achieve systems that are both scalable and robust.
HTTP and Message Loss
The first challenge the team faced was message loss. When first designing our system, we had decided on HTTP as the transport for our WCF-based services. As a part of the message processing, our services would often write data to the database. Not to belabor the point, but many systems are designed this way.
Before taking our system to the staging environment, rigorous stress testing was done—the system was run under heavy load for a period of one week. The result of the stress testing showed that our system lost messages.
During the analysis of what had occurred, we identified that the messages lost were primarily those containing order information—not surprisingly since most of the load on the system had to do with order information. However, we were surprised that all of this message loss occurred during one 10-minute interval. After that, the system operated normally.
After going through various log files, we discovered that, during that week, a critical Windows patch was issued and the servers in the staging lab restarted themselves after automatically installing the patch. When considering the implications of this revelation—servers do restart every once in a while—we realized that we couldn't ignore this. The system would need to be operational for several years and needed to weather many server upgrades and restarts.
When processing a message over HTTP, a service would open a transaction against the database, attempt to write the data, and commit the transaction. Under regular circumstances this would succeed. If the message-processing server restarted mid-transaction, the database would detect the timeout of the transaction and roll back its changes, maintaining its consistent state. However, when the server would start up again, the data of the original message would be available neither in memory nor in the network processing stack of the server—that message would be lost.
For order processing systems, this would mean losing money. One can barely entertain the nightmarish thought of this scenario occurring in air-traffic control systems should the event "aircraft A and B are on a collision course" be lost.
Durable Messaging
After deciding to move from HTTP to a durable transport, we had to choose between Microsoft® Message Queue (MSMQ) and SQL Server® Service Broker. The advantage of Service Broker over MSMQ was that the messaging could be kept in the database, avoiding distributed transactions between the messaging layer and the database, thus resulting in potentially higher performance. The advantage of MSMQ over Service Broker was its availability on Windows directly (at no cost), the tight integration with WCF, and the ability to do peer-to-peer communication between servers without going through the already overloaded database. In the end, we decided on using private MSMQ queues on each of our servers.
Note that using MSMQ does not automatically cause every message to be written to disk—which is a good thing as it comes with a performance overhead. In order to define that a message be durable, when using MSMQ directly set the Recoverable property of the Message class to true or use NetMsmqBinding since by default it has the Durable property set to true.
When using NetMsmqBinding across an entire solution, make sure that messages not requiring durable messaging are transferred on separate endpoints. Configure those endpoints as non-transactional queues and set the Durable property to false in the <netMsmqBinding> section.
In order for the queue to roll back the message in case of failure, the Receive operation must be performed within a transaction. This is done quite simply by using the TransactionScopeRequired property of the OperationBehaviorAttribute—with a queued transport, the transaction used to dequeue the message is used to process the message.
Systems Consistency
As a result of processing a message, a service can reply with one or more messages as well as send any number of other messages to other systems. The flexibility gained by being able to have any code communicate via messaging at any point in the service is extremely valuable. However, doing this with HTTP, TCP, or any other non-transaction-aware technology is dangerous.
Since the transaction around processing a message may be rolled back as a result of a database deadlock, we may be sending other systems information that will be untrue once the transaction rolls back. Consider the scenario illustrated in Figure 1. Deadlocks can occur in databases where multiple threads work with data from the same tables. One thread successfully locks table 1 and attempts to lock table 2. At the same time, a different thread successfully locks table 2 and attempts to lock table 1. The database detects this deadlock, selects one thread as a victim, and aborts its transaction.
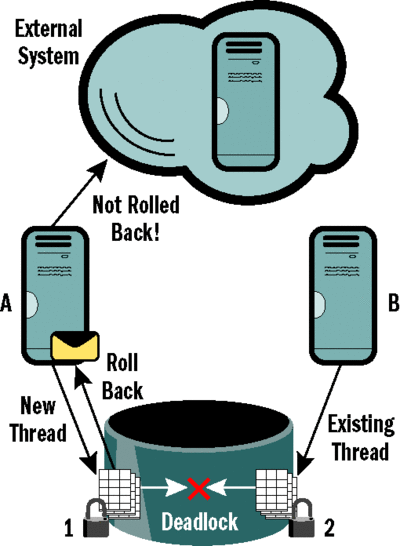
Figure 1 Transaction Encounters a Database Deadlock
The problem here is that we have notified system A about a change to data in table 1 that has been rolled back. This may, in turn, lead to system A changing its internal data and further propagating misinformation, ultimately leading to global inconsistency.
In the order-processing scenario, the behavior we witnessed was the following:
- Purchase Order arrives.
- Purchase Order table updated (status received).
- Warehouse System notified about pending order.
- Customer Relationship Management (CRM) database accessed to update value of customer.
- CRM database deadlock detected.
- Transaction rolled back.
When the transaction was retried, the customer data indicated that no business was to be done with that customer, as it had defaulted on its payments. Consequently, the ordering system was left in a consistent state, as was the CRM database.
Unfortunately, the warehouse system was not notified about the other databases rolling back—how could it have been? This resulted in produce being taken out of refrigeration and sitting on the loading docks for more than an hour until someone called and check what was going on with the order. The produce could not be sold at that point, and the time it took to replenish the inventory led to several other orders being delivered hours late.
The cost of that single incident brought down that week's profit by 30 percent and brought these down-in-the-weeds technical issues into the core business spotlight. When we transitioned to MSMQ, these problems were solved without any development effort on our part, as I'll explain next.
Transactional Messaging
When sending a message to a queue using MSMQ, the message is not sent when the method call returns. This is very different from the behavior HTTP and other connected technologies exhibit. When using MSMQ, before a message is sent it is stored locally on the same machine in an outgoing queue. When the message is sent within the context of a transaction, only after the transaction commits is the message released so that MSMQ can actually send it.
In the previous example, when the ordering system sent a message to the warehouse system notifying it about the new order, that message was not sent right then. Only when the entire message processing transaction committed could MSMQ send the message to the warehouse system. Should the transaction abort as the result of a database deadlock or for any other reason, the message to the warehouse system would have been deleted from the MSMQ outgoing queue. In other words, in order to prevent a total breakdown of system consistency, transactional messaging is needed.
Note that transactional messaging does not imply that both the sender of a message and the service processing that message share a transaction. The fact that a message arrives at a service for processing implies that a separate transaction at the sender committed successfully. However, the fact that transaction was committed says nothing about what may transpire when the receiving service handles that message.
At times, a message may arrive at a service where the processing of that message results in an exception. There are many possible root causes for this exception, and it's important to understand the differences between them and how to handle them. Sometimes an exception may occur only once or twice in the processing of a message; other times it appears that no matter how many times the service will try to process that message, it will always fail.
A message that is identified as belonging to the second group is called a poison message and requires special treatment. As I go through the various root causes, you'll see that a single simple solution is enough to handle them all effectively.
Transient Conditions
You've already seen that a well-formed message whose processing would otherwise succeed may result in an exception due to database deadlocks, or perhaps the database connection pool is maxed out handling other transactions. What is common to all these scenarios is that the exception results from transient environmental conditions.
Since the default behavior in transactional messaging when an exception bubbles up through the transaction scope is to roll everything back, the original message returns to the queue. At that point, a thread—possibly the same thread that had just been hit by the exception—can process it again. Since rolling back a transaction takes some time, there is a high likelihood that the previous environmental conditions have changed now allowing the message processing to transactionally complete successfully.
One often-overlooked case where message processing fails is quite simply that the database used by the service is unavailable—not all databases have five nines of availability. This problem is non-transient from the perspective of the code using the database—it is not known for how long the database will be unavailable. Simply rolling back the message and trying again will most likely result in the same exception.
The message itself may be perfectly valid and may contain very valuable data like, say, a million dollar purchase order that you wouldn't want to lose. Letting the message stay stuck in the processing-rollback loop is one way of keeping the message around, but it causes other problems.
Consider the case where the service logic makes use of more than one database or even makes use of more than one table. One database may be available while the other isn't. The data file backing one table may be available while the file backing the other table may be on a remote server that is down. Now consider that processing messages of type A only needs table A, and messages of type B only need table B. What will occur when table B (or database B) becomes unavailable?
Messages of type A will be processed successfully, but messages of type B will keep rolling back. This will continue until there are more messages of type B in the service's input queue than there are threads processing messages. At that point, the service effectively becomes unavailable even for messages of type A until all resources come back online. In other words, the service is only as available as its least available resource—a worrisome (and costly) proposition from a systems availability perspective.
The most intelligent thing that a service can do after a message has consistently failed to be processed multiple times is to move the message out of the input queue into some other queue—let's call that an error queue for now, yet there's nothing inherently different about that queue than any other queue. In this scenario, when one resource goes offline, messages of type B will be moved to the error queue after rolling back n times, but messages of type A will continue to be processed successfully. While the service's latency and throughput may be hurt by that resource going down, the service will continue to be available.
Deserialization Errors
When a bunch of bytes arrives at an endpoint, the service's underlying technology tries to turn those bytes into a regular object—a message. This deserialization process can fail for a number of reasons. It could be that the data type that the XML instructs the technology to create hasn't been deployed at that endpoint. It could be that the wrong version of that data type was deployed. Another more common situation is that an existing client is sending messages to an endpoint of a service that has been recently upgraded and that the new version of the data type isn't compatible with the previous version.
The problem is that although the service may have not been able to understand the message sent to it, there may be valuable data in that message and, as such, you don't want to throw the message away. You also wouldn't want it to clog up the service's input queue.
The solution in this case is quite similar to the one that is used for database unavailability: simply move the message to a different queue, possibly even the exact same error queue. The slight difference in this case is that there is no uncertainty as to the future result of processing this message—it will always result in an exception. Being such, it is unnecessary for you to wait until the message has rolled back n times before moving it to the error queue. A message that fails deserialization should just be moved directly to the error queue.
Messages in the Error Queue
From the scenarios described earlier you can see that various messages can be identified as poison messages in many circumstances. Some of these messages may indeed be garbage that is best thrown away, yet the only definitive way to make that decision is by having a human operator examine these messages.
In the case of a deserialization exception, the operator may route the message to an endpoint running a previous version of the software or possibly reformat the message to the new version and return it to the input queue.
Hopefully, operators would know about databases going offline, but if a single data file goes bad and only a few tables are affected, messages in the error queue, along with the corresponding log files, can raise a flag about these hidden issues so that they can be identified and resolved quickly.
What can be learned from the topic of poison messages is that the time it takes a service to respond to a message sent to it can be quite long. In fact, the issue of time becomes a primary concern in designing message-based systems—sometimes a late response might as well never have come at all.
Time and Message Loss
While you might think that by using durable and transactional messaging, message loss can be mitigated entirely, the reality, as always, is more complicated than that.
Let's consider a business-to-business scenario where our ordering system is communicating with an external shipping company to take care of the shipment of orders to customers. For every order we accept, a message needs to be sent to the shipping system. In order to prevent messages from getting lost if either system goes down, we use durable messaging along with transactional handling of messages to transfer the order information.
As we analyze the specifics of this scenario, we'll see that message loss is not only inevitable but cost effective. If we take an average message size of 1MB for each order sent, and our order system is processing 10 orders per second (nothing too heavy), and the shipping servers become unavailable, these messages will be durably stored in an outgoing queue. In terms of I/O usage, that's 10MB per second, or 600MB per minute.
This scenario was only noticed after a communication outage of three hours where our systems tried to write over 100GB of data to a partly full three-disk RAID 5 array of 36GB SCSI disk. Servers tend to lose stability when they aren't able to write to their hard drives anymore—not only that, it's almost impossible to bring them back up.
The three hours of backlogged orders, despite being the source of the problem, were not our main concern at that point. The fact that for the two hours that it took us to get the system back up we were losing orders to the tune of several hundred thousand dollars—well, that was enough to get serious management pressure to both solve the immediate problem and prevent it from occurring again. The lesson we learned was that durable messaging is no silver bullet and has an associated cost.
To maintain stability, our servers would need to throw away messages that had not yet been sent to their destination successfully. The difficulty was in deciding which messages should be kept and for how long.
TimetoBeReceived
The order system received requests from many other systems, published events, received events from other systems—each of these resulting in messages either in incoming queues or in outgoing queues. Some services made use of data coming in on a feed where the validity of the data was only a few minutes. It didn't make sense to keep those messages around for any longer than that—even if it took longer than that for all server processes (IIS, SQL Server, other Windows services) to come up. The same thing was true for data feeds that our systems were putting out—if a subscriber was offline for longer than the time the data in a message was valid, it didn't make sense for that message to take up space in our outgoing queues.
As we went through the various messages that made up each service's contract, we noticed that for those messages whose data didn't necessarily have a period of validity, the service had response time requirements as a part of its service-level agreement. In other words, if the service wasn't able to finish processing a message in a given period of time (including the time the message waited in a queue), that service was already malfunctioning from a business perspective.
This meant that a period of validity could be defined for each message type. This time needs to take into account time spent in the sender's outgoing queue, time in transit, and time spent in the receiver's queue. MSMQ allows us to define this value using the TimeToBeReceived property of the Message class (see the "Inside TimeToBeReceived" sidebar for some implementation details).
At this point it was clear the message loss was an unavoidable reality. From a client-side perspective, a message that is lost, a lost response, or just a slow server are indistinguishable from each other. If our service employs other services as clients as a part of our message processing, then to ensure appropriate response times as indicated by our service-level agreement, our service needs to protect itself. Our decision was to employ timeouts so that if responses don't arrive within a specified time, our service can at the very least respond with a message indicating that the request was received and that a response will be sent later, possibly via e-mail if we were interacting with a user.
Inside TimeToBeReceived
As we began looking at how programmers would be working with these APIs, we realized that the value of TimeToBeReceived would be defined as a part of the service's contract and that a framework could access this metadata when sending amessage, saving the programmer from specifying this every time he sent a message.
We defined a TimeToBeReceivedAttribute that could be placed on classes as a part of the message contract (though WCF data contracts are just as suitable). As a part of the implementation of the SendMessage method, the framework would access the type of the message object passed and loop over the custom attributes of that type using reflection. After getting the data from the attribute, the framework passed that data to the TimeToBeReceived property of the MSMQ message that was sent.
Call Stack Problems
Another technical issue that came up was the fact that we had the state of the interaction with the external system represented simply as the call stack of the thread managing the process, as shown in Figure 2.
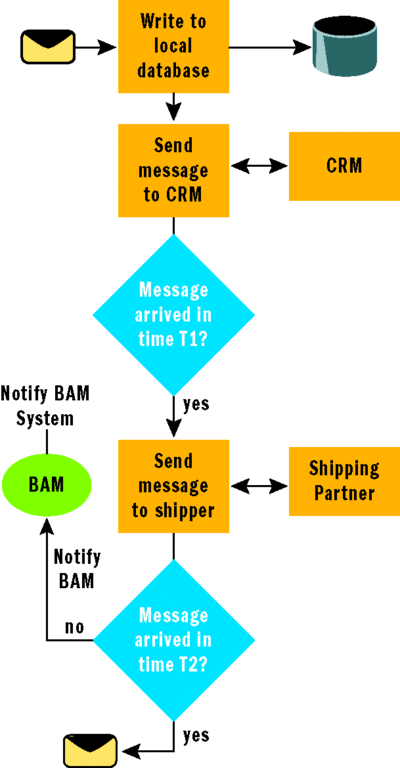
Figure 2 Interaction with External Systems
The technical problem had to do, once again, with servers restarting. If a thread was waiting for a response from either our internal CRM system or the external shipping partner system when the server restarted, that state would be lost. In other words, if the system was supposed to wait a maximum of five minutes for a response, and the server with the knowledge of how much time had elapsed restarted, and even got back to handling requests within that time window, the system would not know that it needed to notify the business activity monitoring (BAM) system.
Given that the reason a response may not have arrived may have been that the original request was lost or thrown away, this scenario would cause an occasional order to get stuck. The system could not proceed without a response from some other system, but forgot that it was waiting for a response because of a restart.
In retrospect, this didn't occur very often—at the time, we didn't know that it was happening at all. The BAM system wasn't showing anything problematic. However, when the COO shows up in the IT department, furious that an urgent order from a strategic partner wasn't delivered on time and that nobody even knew about it, well, we were in for another round of refactoring to solve that problem.
It turns out that making these kinds of inter-system integration processes robust requires joining state management, messaging, and time into one unified model.
Large Messages
Before discussing how long-running processes connect to the solution, it's important to understand the effect of large messages on system performance and availability.
One of the most difficult performance problems that we ran into was caused by messages received from strategic partners—our most profitable market segment. While the purchase orders received from most of our customers were fairly small, our strategic partners would send orders for many items and many kinds of each item. The difficulty was compounded by the requirement for item customization—something that our strategic partners did often. Together, this resulted in strategic partners sending us messages that could easily be between 20MB and 50MB of XML.
Just the deserialization of those quantities of XML was enough to tie up a Xeon core for up to a minute. We tried offloading the schema validation to hardware XML appliances, but that didn't solve the overall problem—these huge messages were processed orders of magnitude slower than the linear multiplication of corresponding small messages:
TimeToProcess(BigMessage) >> N x TimeToProcess(SmallMessage) where
Size(BigMessage) == N x Size(SmallMessage)
We had always thought about scalability in terms of the ability to scale to larger numbers of messages per second, and that's what we had tested for. It turned out that scaling to larger message sizes is a much more difficult problem.
Network congestion issues barely affect small messages, but large messages are much more susceptible. The same goes for writing this data to disk when using durable messaging. While its fairly easy to find a contiguous strip of free disk to write a small message, after the system has been running for a while without defragmenting a disk, writing a large message can take much longer. As users, we're familiar with the 99 percent done phenomenon when copying large files between machines. Servers suffer the same problems.
Obviously while all this would be going on, smaller messages would be affected as well. Although less of an issue from a percent-profitability perspective, handling 10 percent fewer orders due to throughput problems is an unacceptable hit to the bottom line. We needed some way to turn one large message into many smaller messages.
Small Messages from Large
The problem was that the data flowing in those messages had uniqueness requirements from a business perspective. We can't allow duplicate purchase order numbers. When designing banking systems, transaction numbers need to be sequential. Parallelism can't be handled on a purely technological level—business rules need to be designed around this as well.
After analyzing the data in these large purchase orders and speaking with the development teams at our strategic partners, we discovered that these large purchase orders were built up gradually over time and were only sent when completed. The most interesting thing we heard was that these large messages were problematic on the sender side as well and that there was universal interest in finding ways to break them up into multiple small messages.
The problem was that the current interface and processing logic tied a single purchase order number to a single message. If a solution could be found where that connection could be broken, it was clear that the other problems could then also be solved.
A simple solution was devised, though it turned our previously stateless architecture into a statefull one—a decision not to be taken lightly. Stateless architectures keep all state in the database. Although simple to build and having good tool support, these architectures exacerbate the load on the database.
After building a prototype and putting it through a bout of stress testing we found that latency, throughput, and overall resource usage was so much improved that we decided to move forward with the architecture.
In the new architecture, our partners could send us multiple messages with the same purchase order number. Those messages would only include changes to data already sent or additional data. When all the data from the purchase order had been sent, the partner system would set a Boolean field indicating that the current message was the last one in the purchase order. In terms of the message contract, the change was really quite small—just an additional field. However, the order processing logic needed to be fundamentally changed.
Instead of regular request/response semantics, our service was now supporting multiple-request/single-response semantics. The logic didn't know how many requests it was going to receive for a given purchase order. Further, those requests were not to be processed until a request arrived with the purchase order complete field set to true. However, the data from those requests needed to be stored until that last request arrived.
We separated out the storage of the data at this stage so as to not increase the load on the database any further. After analyzing the data access patterns of this state, we discovered there was no need for rolling up reports on all purchase orders at that point. In other words, the choice of a relational database for storing the data was overkill in terms of transactional consistency guarantees and too slow to handle the high write-to-read ratio of this kind of logic.
After moving to a distributed caching solution, performance greatly improved. (Distributed caching products keep data in memory on multiple servers for fault tolerance and high availability and offer a high-performance alternative to conventional database technologies.)
Although the static structure of the order processing contract did not change very much, on the other hand the dynamic behavior of its message exchange patterns was very different. Since our service could now accept the same purchase order in multiple messages, we could now leverage that enhanced protocol in infrastructure decision.
Idempotent Messaging
The original decision to use durable messaging for purchase orders from strategic partners hinged on preventing message loss. Unfortunately, we saw that the fact that a message was written to disk did not necessarily provide a 100 percent guarantee. However, with the new message protocol, if a partner sent us a purchase order message and did not get a message back from us in a reasonable period of time, they could just send the same message again.
Although we hadn't explicitly set out to create idempotent message contracts, their benefits were felt very quickly. (An idempotent message is one that can be sent multiple times to a service and the resulting service state is the same as if the message was processed just once.) Using durable messaging involved writing each message to disk. Even expensive high-performance disks are much slower than storing messages in memory. The performance gain was two-fold: not only were we sending and processing smaller messages, but the messages didn't need to be written to disk at all. The cost savings in terms of message storage can be significant.
There is an additional element of complexity that comes with idempotent messaging. Disregarding the difficulty in designing idempotent contracts, clients can no longer just fire-and-forget a message to a service. Clients need to manage timers on their end in order to send the same message again if a response does not come back from the server in time. In other words, not only do servers need to statefully process messages, but it is necessary for clients to statefully send messages.
Long-Running Processes
Another architectural shift that occurs when splitting up large messages into multiple smaller messages is that previously simple request/response semantics become long-running processes as well. A long-running process is one that handles multiple messages. Often, state from one message needs to be available to logic processing a subsequent message.
As previously discussed, the processing of a single message is a single transactional unit of work and includes changes to local state as well as sending out other messages. A long-running process handles multiple messages, each of which represents a transactional unit of work. When a response arrives from a previously sent request, it is handled in a unit of work all its own.
Between handling messages, though, there is no reason for the state of the long-running process to take up memory, so it is saved to some highly available store (typically a database or possibly a distributed cache). When a message containing the process ID arrives at an endpoint, the data from the highly available store is retrieved, and the long-running process is dispatched the message.
One other common requirement that leads to designing long-running processes is complying with response times while needing a response from an external system. As you've already seen, when communicating with an external system or even just processes on a different machine, there are many things that can go wrong—the machine may be down, the process may be down, the message may have been lost or thrown away.
Consider the previously described process of shipping an order to a customer. Our company may work with multiple shipping partners, yet one is usually a preferred partner. There are cases where our preferred partner's systems may be down, slow, or just not responding. In those cases, logic dictates that we should wait for up to five minutes for a response, and if no response arrives, to choose a different shipping partner. At times, we would ship only part of an order if certain products were unavailable, leaving our shipping process to continue processing the order when inventory would become available.
We previously introduced the problem with implementing these timers using regular in-memory constructs such as System.Threading.Timer. In the case of a server restart, the data about time elapsed would be lost. The challenge that we faced was to store the information about time in such a way that it would be highly available and fault tolerant. A related issue was how our process would be notified of a timeout event.
After realizing that a timeout event is just like any other business event in the system, and that business events were represented as messages arriving at our process, we decided to use messaging to handle the issue of time as well. Our long-running process would send a timeout message to a Timeout Manager Service. The message would contain the ID of the long running process and the date and time at which to be notified.
The Timeout Manager Service would maintain this data in some way, either in a database that it would poll at specific intervals or possibly just by keeping the message in a durable queue. When we reached the time specified in the message, the Timeout Manager Service would send that very same message back to the endpoint from which it came—the endpoint of the long-running process. The long-running process would handle that message just like any other—in its own unit of work. While handling the timeout message, the process would have all its state from all the previous interactions available.
When looking at this shipping process, the logic handling the timeout message would check whether a response had arrived from our preferred shipping partner. The reason for this check is that we may have received a response from the partner system just before the timeout had occurred, and now our process is waiting for the rest of the inventory to become available. In this manner, a timeout message is not necessarily an indication of something going wrong, but rather a wake-up call for our process. In a single process, we may make use of multiple timeouts each corresponding to a business requirement around response times and service-level agreements.
It is important to understand that these timeouts are not a technological phenomenon like those that arise from trying to contact a database or an HTTP Web service call timing out. These timeouts are business events that may well be days and weeks in the future.
After we began addressing time as a first-level concern in our interactions, we began to see that previously trivial synchronous, blocking request/response semantics became processes in their own right. Each interaction eventually had some restriction as to the maximum time it should take. Every time we thought that we had a simple request/response interaction on our hands, we asked ourselves, "What if it takes two days to get a response back? What if it takes two weeks? Would our system still comply with its service-level agreement?" The result was the always the same: time cannot be ignored.
Learning from Mistakes
Developing reliable services is not easy. The problems our team faced may have appeared to be a failing of the technology at first, but the solutions often came from re-examining the problem domain and taking into consideration the harsh realities systems face in a production environment. We iterated through the project, trying durable messaging technology, adding full unit-of-work transactional message handling, handling versioning issues and poison messages, splitting up large messages, and finally addressing time robustly using long-running process. One thing became clear; the core patterns were the same:
- Never assume that just because you sent a request you'll get a response.
- Time is a business event and like other events can be handled like any other messages.
- The handling of any message—a request from a client, a response back from another system, the arrival of a published message to which we had previously subscribed—is a single unit-of-work encompassing all local activities and the sending of messages as well.
The mindset that served us well at every decision point was "how could this fail?" This lead to good judgment around the choice of technologies and how to design service contracts for statefull interactions. Good judgment comes from experience, and experience comes from bad judgment. Only after we had been burned by our previous design decisions did our vision become clearer as to how our design-time decisions impacted runtime behavior.
Udi Dahan is The Software Simplist, an MVP and Connected Technologies Advisor working on WCF, WindowsWF, and "Oslo." He provides training, mentoring, and high-end architecture consulting services, specializing in service-oriented, scalable, and secure .NET architecture design. Udi can be contacted at www.udidahan.com.