span.sup { vertical-align:text-top; }
WCF P2P
How To Design State Sharing In A Peer Network
Kevin Hoffman
This article discusses:
|
This article uses the following technologies: WCF |
Code download available at:P2P2008_07.exe(171 KB)
Contents
Fixed State Server
Transient Elected State Server
Pure Peer Serverless Data Blast
Nearest Peer Synchronization
The WeSpend Sample Application
Next Steps
In recent years, people have started to discover the amazing power and functionality that can be provided by an application that communicates over a peer network. So-called peer applications cover the gamut from simple file sharing to instant messaging (IM) to full-on collaborative applications such as shared white boarding, Voice over IP (VoIP) calling and conferencing, social networking, and much more.
Think about how your Xbox 360® automatically detects the presence of another computer running Windows Media® Center and can immediately begin sharing audio and video with that computer, allowing you to play music from your computer on your Xbox®. Wouldn't it be great if business applications sported the same kind of peer awareness and capability? Think about how pleased your customers would be if someone created a new record from their desktop and everybody else within the organization using that application immediately saw that new record and you didn't have to install and configure a central server to make that happen.
This article is all about peer-enabling business applications by allowing them to share state in a serverless peer network. Before getting into the details of a sample app, I want to talk about some of the various ways that people typically try to share state in a peer network, as well as the pros and cons of those approaches. Finally, I'll show you a sample application called WeSpend, a tool for tracking your bank book ledger. This application automatically synchronizes data with all other instances of itself on your home network.
There are as many ways to implement a peer network as there are potential application ideas. Each implementation carries with it certain benefits and drawbacks. Some of those aspects are related to infrastructure, some are related to the ease with which the solution can be maintained over time, and yet others are related to how easily the solution can be developed initially. In this section I take a look at some of the most common ways people develop peer networks.
Fixed State Server
When many development teams get past the initial concept phase of their peer-enabled application and start looking at implementation, one of the first questions that arises is usually: how do we share state?
One of the simplest solutions is to create a hybrid peer network. This is where all broadcast and peer traffic takes place on the peer mesh, but there is a well-known central server that is maintaining state, often through a Web service or another Windows® Communication Foundation (WCF) service. This allows the peers on the network to be aware of the singleton state for the entire application, as well as being able to take advantage of optimized peer mesh communication.
The most common examples of this type of network are social networking and IM applications. IM applications often require a central server that is maintaining the list of who is logged in, their presence and availability, and the buddy lists for all of the registered users (see Figure 1). Communication between users on the network takes place in peer-to-peer fashion. There is an extremely useful and powerful split of functionality between classic client-server and peer-to-peer features.
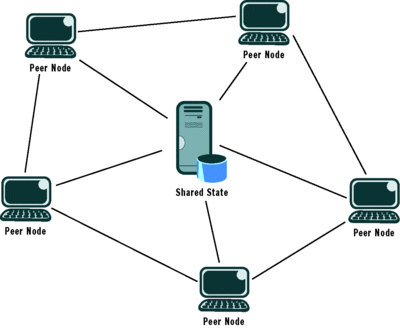
Figure 1 Central State Server in a Peer Network
The benefit of this pattern is that it is easy to implement. The peer networking component has low complexity, and communication with a central server has been made extremely easy in recent years with the Microsoft® .NET Framework and WCF.
The drawback is that the infrastructure requires a central server. The peer applications need to know the address of that server, which could cause a configuration and maintenance problem. Also, many application developers don't have the resources to deploy central state servers globally, and the requirement of a central state server is often something that cannot be accommodated by an application's specifications.
Transient Elected State Server
The next step in the evolution of shared state patterns is to alleviate the infrastructure concern from the previous pattern by electing one of the nodes in the peer mesh to be the state server. You often see this pattern in networked real-time strategy games where the person who initiated the game has the "one true copy" of game state, and everyone else has synchronized duplicates.
This pattern works by using an algorithm that elects a node to be the state server for the mesh. Once this node is the state server, all the other nodes in the mesh follow the same pattern as in the fixed state server scenario for updating and querying singleton state.
While this removes the problem of requiring a fixed central server, it trades that problem for the complexity of an elections system. To implement this peer network, you need to determine how you elect the state server. One really easy solution is to pick either the oldest node (the one in the mesh longest) or the youngest node. The problem arises when nodes leave the mesh. What happens if your elected state server goes offline? If the mesh is aware of it being offline, the peers can elect a new state server. But what happens if the state server is just really slow, hasn't gone offline, and the mesh hasn't decided to re-elect?
As you can see, the drawback of this solution is that you are trading the infrastructure requirement of a central server for the potentially project-halting complexity of building an elections system that not only picks the best candidate to be state server but is resilient enough to deal with the state server becoming a black hole (messages come in but don't come out, which is slightly different from simply being offline) or the state server going offline.
If the complexity of the election system is actually handled well, this can be an powerful and versatile system. If the election system is done poorly, this kind of network will fail miserably and cause untold problems with state sharing.
Pure Peer Serverless Data Blast
The first two scenarios attempt to provide a solution in which there is one and only one authoritative copy of state. Whether the location of the state server is fixed or elected, the means by which peers query and manipulate state remains the same: contact with a single remote server.
A popular alternative to the central state server is what I call the "data blast" network. In this scenario, peers broadcast copies of their data to all other peers in the mesh each time a new peer joins the mesh or when a peer specifically asks for a data update. Each time a peer receives a broadcast of state data, they compare the contents of the broadcast with local state and update accordingly.
There are two rather significant downsides to this approach. The first is that the amount of redundant data being sent across the network can become extremely large. The more computers on the peer network, the more bandwidth will be wasted. In fact, the amount of redundant data transmission in this scenario actually grows exponentially as the number of nodes in the mesh increases.
The other downside to this approach is that, since each application is broadcasting a copy of its own data, the reception of a broadcast piece of data must now perform a synchronization operation to compare the received data against local data and reconcile the differences. As the size of the peer network increases, it could reach a point where it takes longer to process a state broadcast than it does for the next message to arrive, creating a bottleneck and potentially degrading the performance of the application itself. Data sent in broadcasts must have some way of being identified as unique, because each node in the peer mesh will need to check to see if the data is duplicated.
The trade-off for the somewhat wasteful use of network resources is that there is no central state server and you don't incur the complexity penalty that an election pattern carries with it. In some situations, especially when the number of nodes is known to never grow above a certain size, the duplicate data transmissions are worth the reduced implementation effort.
Nearest Peer Synchronization
When researching the various ways in which an election scenario might be implemented, I discovered that there is an attribute in WCF that allows you to indicate the maximum number of hops that a particular message will travel. After seeing this, it became obvious that there was a means for sharing state in a peer network that not only required no central server, but was resilient to node drop-off and did not require election. I call it Nearest Peer Synchronization.
The route any message takes between any two nodes in a peer mesh is entirely dictated by WCF. This allows WCF to optimize the communication paths in the network. Knowing this, and knowing that you can limit the distance a message travels to only one hop, it's possible to implement a neighbor synchronization pattern for state sharing.
First, after joining a mesh, the newly joined node will send out a one-hop message requesting a list of unique record identifiers for shared state records. All nodes in the mesh that are one hop away will receive this message. These nodes will then use the callback contract to reply directly to the mesh. The reply contains a list of the unique IDs for all records of data being maintained by that node. The first one to reply wins and all of the other replies are ignored. Keep in mind that you have to write the code that ignores duplicate messages. WCF won't do that for you.
The newly joined node then compares that list of unique IDs with its own list of unique IDs (because it has probably maintained offline state on disk and has a partial view of shared state). The unique IDs received in the reply that are not contained in local state are then sent out to the mesh in a one-hop message. The first node to reply to that message (again, using the callback contract) replies with the details for each of those unique IDs. The details are usually a fully constituted, serializable object.
The beauty of this pattern is that it is automatically able to correct for the disappearance of faulty nodes. If a node in the mesh crashes, it will not respond to requests for data. All other one-hop nodes then have a chance to reply to that data. If the mesh is organized such that the newly joining node only communicated with the one node that failed, WCF now considers nodes that used to be two hops away to be one hop away. There is no election logic required, and automatic failover is taken care of directly in the WCF peer channel layer without you having to write any additional code. Because each neighbor is guaranteed to be synchronized with each neighbor's state, state propagates automatically among all peers in the mesh. Figure 2 is an illustration of a pure, serverless peer mesh in which nodes auto-sync with neighbors.
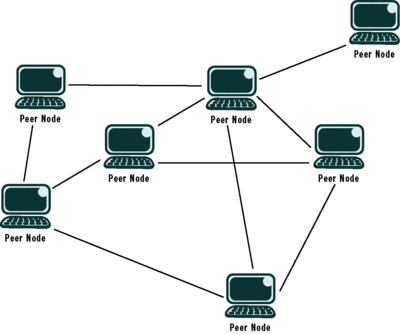
Figure 2 A Peer Mesh with No State Server
The WeSpend Sample Application
To put these ideas into action, let's look at a simulation of a personal finance manager. It allows the user to keep track of financial transactions such as checks written or debit transactions made against a checking account.
WeSpend is a collaborative peer application because any other copy of the application running on the network automatically shares its state with other copies. The user-perceived effect of this is that when a family member downstairs enters a transaction in WeSpend, another family member upstairs immediately sees the new transaction. When a third person in the same home starts a fresh copy of WeSpend, he automatically receives transactions created when his application was not active. Adding this kind of peer awareness and collaborative capability could make the difference between a fantastic, popular application and a simply mediocre application.
WeSpend uses the nearest-neighbor synchronization shared state pattern. There are several key technological components of WCF that make this application possible. The first, which has already been mentioned, is an attribute called PeerHopCount that allows the contents of a message to only be transmitted a fixed number of times before being dropped. This attribute can turn a property of a data message into something very similar to the IP concept of time to live (TTL).
Here is a sample of a WCF message contract in the WeSpend application that includes a field controlling the peer hop count. It is important to note here that the peer hop count attribute is only used by the NetPeerTcpBinding protocol binding. The attribute is ignored by all other bindings:
[MessageContract]
public class TransactionIdRequest {
[MessageBodyMember]
public string Requester;
[PeerHopCount]
public int Hops;
public TransactionIdRequest() {
Hops = 1;
}
}
When you put this message out onto the mesh, you don't get the normal flood behavior that sends the message to every node available. Instead, the message is sent out and delivered once and then the message ceases to exist. This allows you to request a list of transaction IDs only from the closest neighbor in the mesh.
Another key component that makes this scenario possible is the use of callback contracts. When a method is invoked on a WCF peer by another peer, the target code can call back to the peer mesh that initiated the method call. This allows a single node to reply to a neighbor request and obviates the need to host separate WCF services on every peer node. Here is a sample of the code that replies to a request for transaction IDs using a callback contract:
public void RequestTransactionIds(TransactionIdRequest request) {
List<Guid> outboundIds = new List<Guid>();
foreach (Transaction tx in ModelRoot.Current.Transactions) {
outboundIds.Add(tx.TransactionID);
}
CallbackChannel.TransactionIdsReply(new TransactionIdReply() {
ReplyFrom = AppController.Current.Username,
TransactionIDs = outboundIds
});
}
Here the callback channel is being used to reply to the peer that initiated the method call RequestTransactionIds. Remember that the TransactionIdRequest message is limited to one hop only, so the initiating peer will not be inundated with replies even in the largest of peer networks.
When a peer node receives a list of transaction IDs (by having its TransactionIdsReply method invoked), it uses the callback contract again to request details for those IDs that it does not already have in local storage, as shown in Figure 3.
Figure 3 Requesting Transaction Details
public void TransactionIdsReply(TransactionIdReply reply)
{
// Compare the list of TX IDs with the list of IDs in local storage
// for each item that is "missing" from local storage, put that item
// in the request for details.
List<Guid> output = new List<Guid>();
foreach (Guid id in reply.TransactionIDs)
{
if (!ModelRoot.Current.Transactions.Any(
tx => tx.TransactionID.Equals(id)))
{
output.Add(id);
Console.WriteLine("[LTS] Need to request detail for TX " +
id.ToString());
}
}
CallbackChannel.RequestTransactionDetails(output);
}
When the other half of the synchronizing pair has its RequestTransactionDetails method invoked, it too uses the callback contract to reply to the mesh, as shown in Figure 4.
Figure 4 Replying with the Details
public void RequestTransactionDetails(List<Guid> transactionIds)
{
List<LedgerTransaction> output = new List<LedgerTransaction>();
foreach (Guid id in transactionIds)
{
Transaction tx = (from Transaction lt in
ModelRoot.Current.Transactions
where lt.TransactionID.Equals(id)
select lt).FirstOrDefault();
if (tx != null)
output.Add(tx.ToLedgerTransaction());
}
CallbackChannel.TransactionDetailsAck(new TransactionDetailReply()
{
ReplyFrom = AppController.Current.Username,
Transactions = output
});
}
The property that has been used in the previous code listings, CallbackChannel, is defined as follows on the implementation of the WCF peer service contract:
protected ILedgerTransactionServiceChannel CallbackChannel {
get {
return OperationContext.Current.GetCallbackChannel<
ILedgerTransactionServiceChannel>();
}
}
Figure 5 illustrates the flow of messages between the peer that just joined the mesh and the closest neighbor to answer the call to initiate a synchronization operation.
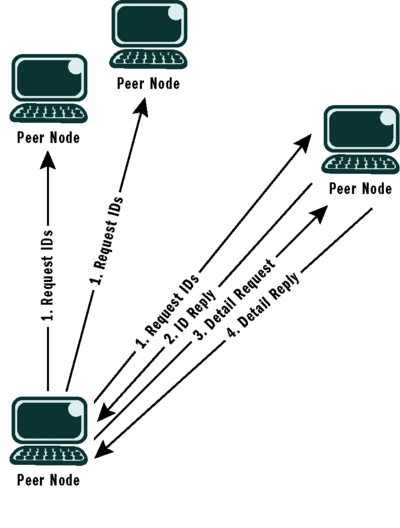
Figure 5 Nearest-Neighbor Synchronization Order
One thing that is missing from the preceding method implementations is a barrier against re-entrant execution. In other words, if multiple peers want to start a synchronization operation at the same time, production code would need to guard against that. Also note that the code makes heavy use of the callback contract for the synchronization operations. The peer node will need to guarantee that no other peer nodes can synchronize at the same time, but this can be accomplished with a simple semaphore.
Adding peer networking capabilities to an application can dramatically improve the experience your customers have with your software. All too often, however, the perceived complexity of doing so is a barrier that can result in having peer networking features taken out of the product's design. Some implementations quickly become such maintenance nightmares that people remove peer networking from their specifications—the complexity simply spirals out of control.
The goal of this article is to show you that not only is peer networking possible and easy to implement, but you can even implement a serverless state sharing system that is efficient, fault tolerant, and easy to code. Also keep in mind that there is a nearly infinite supply of variations on the patterns discussed here.
I suggest you download the code sample and start experimenting with it. It works best when you have two computers and you modify the app.config to simulate two different user names. After launching one instance with the txhost application setting set to true (this means it creates a few sample transactions), launch the second instance with txhost set to false (doesn't automatically create transactions). You will see the transactions from the first instance automatically propagated to the second instance. When you click the button to create a new transaction, you will see that transaction appear on both running instances of the sample application. To see the synchronization effect even more clearly, quit the second instance and then restart it. When you restart the second instance, all of the transactions will show up. Depending on how Peer Name Resolution Protocol (PNRP) is working on your computer, it could take up to 30 seconds for the sample applications to start communicating for the first time.
Kevin Hoffman is a Research Developer at Liquidnet Holdings, Inc. He has always been passionate about networking, communications, and distributed application architecture. He has been working with WCF since the early days when it was still known by the codename "Indigo."