Paradigm Shift
Design Considerations For Parallel Programming
David Callahan
This article is based on a prerelease of Visual Studio tools. All information herein is subject to change.
This article discusses:
|
This article uses the following technologies: Multithreading |
Contents
Concurrency and Parallelism
Structured Multithreading
Data Parallelism
Data Flow
Streaming Parallelism
Single-Program, Multiple-Data
Concurrent Data Structures
Wrap-Up
From about 1986 to 2002, the performance of microprocessors improved at the rate of 52% per year. This astounding technology advance was the result of a combination of the ever-shrinking cost of transistors, as per Moore's Law, and the engineering excellence of processor vendors. This combination has been referred to as "Moore's Dividend" by Microsoft Researcher Jim Larus, who reflects on how this dividend has paid for the creation of the modern software industry and allowed computers to become as pervasive as they are (see go.microsoft.com/fwlink/?LinkId=124628 ).
On the software side, this phenomenon is called the "free lunch"—application performance improving simply by upgrading the hardware on which it runs. (For more on this, see "A Fundamental Turn Toward Concurrency in Software" at ddj.com/184405990 .)
But the model is changing; today, performance is improved by the addition of processors. So-called multicore systems are now ubiquitous. Of course, the multicore approach improves performance only when software can perform multiple activities at the same time. Functions that perform perfectly well using sequential techniques must be written to allow multiple processors to be used if they are to realize the performance gains promised by the multiprocessor machines.
Concurrency and Parallelism
For some time now, programmers have had to think about a programming challenge related to parallelism—concurrency. In order to maintain responsiveness, there needed to be some way to offload long-latency activities from the thread that reacts to input events. Most of the activities to be offloaded had, in the past, been related to file I/O, but more and more often now they are related to conversations with Web services.
The Microsoft .NET Framework provides the asynchronous programming model and notions of background workers to facilitate this common programming concern. While many of the complexities of parallel programming have analogues in concurrent programming, the basic patterns and goals are different. Multicore processors will not alleviate the need for concurrent programming but rather will be a technique used to optimize the background activities and other computations performed in the system with the goal of improved performance.
Another familiar form of concurrency applies to server applications. Applications such as Web servers are presented streams of independent requests. These programs attempt to improve system throughput by executing many requests at the same time, typically using a separate thread for each request but then sequentially processing each request. This overlapping increases requests served per second but does not improve the latency (seconds per request) of individual requests.
These applications have also been enjoying a free lunch, one that will continue a bit longer as multi-core processing provides additional cost reduction and throughput benefits. However, any request that is sensitive to latency, even in a server environment, will eventually need to use parallel programming techniques to achieve acceptable performance.
Concurrent programming is notoriously difficult, even for experts. When logically independent requests share various resources (dictionaries, buffer pools, database connections, and so forth), the programmer must orchestrate the sharing, introducing new problems. These problems—data races, deadlocks, livelocks, and so forth—generally derive from a variety of uncertainties that arise when concurrent tasks attempt to manipulate the same data objects in a program. These problems make the basic software development tasks of testing and debugging extremely difficult, as recently outlined in "Tools and Techniques to Identify Concurrency Issues" by Rahul Patil and Boby George ( MSDN Magazine , June 2008, msdn.microsoft.com/magazine/cc546569 ).
Parallel programming differs from concurrent programming in that you must take what is logically a single task—expressible using familiar sequential constructs supported by all major languages—and introduce opportunities for concurrent execution. (Later in this article, I will describe broad approaches to such opportunities.) However, when concurrency opportunities are introduced with subtasks that share data objects, you have to worry about locking and races. Thus, parallel programming has all of the correctness and security challenges of sequential programs plus all of the difficulties of parallelism and concurrent access to shared resources.
The combination of extra concepts, new failure modes, and testing difficulty should give every developer pause. Is this something you really want to bite off? Clearly, the answer is no! However, many will be forced into this swamp in order to deliver the necessary performance. Microsoft is actively developing solutions to some of the core problems, but high-productivity solution stacks are not yet available.
Last year, Microsoft announced its Parallel Computing Initiative ( go.microsoft.com/fwlink/?LinkId=124050 ) to look at not only how to build and efficiently execute parallel programs but also to encourage creation of a new generation of applications that turn Moore's Dividend into customer value. I will soon examine some approaches to thinking about parallelism. Stephen Toub and Hazim Shafi’s article in this issue, “ Improved Support For Parallelism In The Next Version Of Visual Studio ,” describes some of the libraries and tools that we are providing to support these approaches. Joe Duffy’s article, “ Solving 11 Likely Problems in Your Multithreaded Code ”, also in this issue, discusses techniques and approaches to improving the safety of concurrent applications.
References
The Future Evolution of High-Performance Microprocessors, a lecture by Norman Jouppi, Stanford University
stanford.edu/class/ee380/Abstracts/060927.html
Thousand Core Chips: A Technology Perspective, a lecture by Shekhar Borkar
videos.dac.com/44th/papers/42_1.pdf
Previously, I used the phrase "opportunities for concurrent execution," which draws a further distinction between parallel and concurrent programming. When a developer uses asynchronous programming patterns or background workers, or handles concurrent requests in a server, there is an expectation that all the various threads make forward progress. The operating system scheduler will make sure every thread gets a fair share of resources. This, however, is not useful for parallel programming. It is particularly not valuable when you are interested in writing applications that will scale to new hardware systems.
If you want a return of the free lunch where software just gets better with hardware upgrades, then you need to provide the opportunity for more parallelism today in ways that can be used tomorrow. Here I will use the term "tasks" rather than "threads" to emphasize this shift in the implementation of parallelism and how I think about it: developers that tackle parallel programming will be encouraged to decompose problems into many more tasks than are needed today.
The implementation of parallel programming systems will need to deal with mapping those tasks onto system threads and processors on an as-needed basis. Visible to only a few programmers, there are deep changes in the way in which system resources are acquired from the operating system and managed within a process to execute parallel programs efficiently. This is like a thread pool on steroids, but one that is focused on matching opportunities for parallelism in an application to the available resources in the current hardware rather than simply managing threads as specified by the parallel programmer.
In concurrent programming, especially for servers, much of the difficulty arises from coordinating accesses to shared variables by long-running threads using tools such as locks. As we shift to parallel programming with tasks, a new concept can be used. I can talk about a task B running after a task A and provide coordination primitives to express this. This allows a programmer to think about the schedule of work. Typically this schedule will fit naturally into the algorithmic structure of the program and emerge from structured use of parallel programming abstractions. Good fits between program abstractions and parallel algorithms will greatly reduce the need for traditional concurrency mechanisms, such as locks and events, and avoid, but not eliminate, many of the risks of concurrent programming.
Next, I'll describe some major approaches to parallel programming and illustrate their use through abstractions that are under development. In particular, I will illustrate both the C++ Parallel Pattern Library (PPL) and the Parallel Extensions to .NET (available at go.microsoft.com/fwlink/?LinkId=124621 ) using C#.
Structured Multithreading
The problem-solving pattern humans use most often is divide and conquer: take a big problem, divide it into smaller problems with well-defined interactions that can be separately tackled, and then combine the results to solve the original problem. This technique is used to solve problems ranging from large corporate ventures to neighborhood potlucks. Not surprisingly, the recursive application of this idea is also a cornerstone of parallel programming.
Structured multithreading refers to providing parallel forms of key block-structured sequential statements. For example, a compound statement { A; B; } with sequential semantics where A is evaluated and then B is evaluated is made into a parallel statement by allowing A and B to be evaluated concurrently. The whole construct, however, does not complete, and control continues to the next construct until both subtasks have finished. This is an old concept and historically taught as a cobegin statement. It is sometimes referred to as "fork-join parallelism" to emphasize the structure. The same basic idea can be applied to loops where each iteration defines a task that may be evaluated concurrently with all the other iterations. Such a parallel loop completes when all iteration tasks complete.
A familiar example of the divide-and-conquer concept is the famous QuickSort algorithm. Here I'll illustrate a straightforward parallelization of this algorithm using C++ constructs. The basic algorithm takes an array of data, uses the first element as a key, partitions the data into two pieces, and updates the array so that all values less than the key occur before all values that are greater than the key. This step is then applied recursively to sort the data. Typically there is some cutoff where a non-recursive algorithm, such as insertion sort, is used to reduce the overhead near the leaves.
Figure 1 illustrates two features that are in development at Microsoft. The first feature demonstrated is the new C++ lambda syntax that makes it extremely convenient to capture an expression or statement list as a function object. The following syntax creates a function object that, when it's invoked, will evaluate the code between the braces:
[=] { ParQuickSort(data, mid); }
Figure 1 Quick Sort
// C++ using the Parallel Pattern Library
template<class T>
void ParQuickSort(T * data, int length, T* scratch) {
if(length < Threshold) InsertionSort(data,length)
else {
int mid = ParPartition(data[0], data,
length, scratch, /*inplace*/true);
parallel_invoke(
[=] { ParQuickSort(data, mid); },
[=] { ParQuickSort(data+mid, length-mid); });
}
}
The leading [=] marks the lambda and indicates that any variables in outer scopes referenced in the expression should be copied into the object and that references to those variables in the body of the lambda will refer to those copies.
The parallel_invoke is a template algorithm that, in this case, takes two such function objects and evaluates each one as a separate task so that those tasks may run concurrently. When both tasks complete and, in this case, both of the recursive sorts have been completed, the parallel_invoke returns and the sort is then complete.
Note that parallelism in this example comes from the recursive application of divide-and-conquer parallelism. While at each level you only get two child tasks, toward the leaves of the computation you end up with a number of tasks proportional to the size of the data you are sorting. I have expressed all of the concurrency, and such a program is ready to scale to bigger problems or more cores. For a fixed-sized problem, there are always limits to the scalability on any real machine that has overheads. This is a consequence of the famous Amdahl's Law. A key engineering goal for platform vendors then is to drive down these overheads continually, which means that choosing values like Threshold (in Figure 1 ) can be hard to do and even harder to predict over time as systems change. They need to be big enough so that you don't pay excessive overhead but not so big as to limit future scaling.
This template algorithm is part of our PPL described in this issue by Stephen Toub and Hazim Shafi. In addition to parallel_invoke, there is also a parallel_for_each similar to the Standard Template Library's (STL) for_each. In the case of the parallel_for_each, the semantics are that every iteration is a separate task that may run concurrently with the other iteration tasks, and the parallel_for_each returns when they have all completed. There are also less structured techniques to create individual tasks that are associated with a common task group and then wait for them all to complete. This provides the same basic functionality as the Cilk spawn primitive (supertech.csail.mit.edu/cilk) but is built on standard C++ features.
A use of parallel loops might be code to perform a ray-tracing problem. Such a problem is trivially parallel over each output pixel and can be captured in code that might look like Figure 2 . This is expressed using the Parallel.For method from the Parallel Extensions to .NET, which includes the same basic patterns for managed developers as are supported by the PPL for C++ developers. Here I use simple, nested loops to describe the space of tasks corresponding to each pixel on a rectangular screen. This code assumes that the various methods invoked in the body of a loop are safe for concurrent execution.
Figure 2 Parallel Loops
// C# using Parallel Extensions to the .NET Framework
public void RenderParallel(Scene scene, Int32[] rgb)
{
Parallel.For(0, screenHeight, y =>
{
Parallel.For (0, screenWidth, x =>
{
Color color = TraceRay(new Ray(camera.Pos,
GetPoint(x, y, scene.Camera)), scene, 0);
rgb[x + y*screenWidth] = color.ToInt32();
});
});
}
Again, see Joe Duffy's article on concurrency safety. In these early days of parallel programming, developers will bear the burden of these concerns. Caveat emptor.
Structured multithreading is ideal for working with parallelism where there is a natural, perhaps recursive, possibly irregular, data structure where the parallelism reflects that structure. This is true even if there is some data flow across the problem. The following example traverses a graph in a topological order so that I don't visit a node before I have seen all predecessors. I maintain a count field on each node, which is initialized to the number of predecessors. After visiting a node, I decrement the counts of successors (careful to make this a safe operation since multiple predecessor tasks may attempt it at once). When I see a count go to zero, I can then visit that node:
// C++
void topsort(Graph * g, void (*action)(Node*)) {
g->forall_nodes([=] (Node *n) {
n->count = n->num_predecessors();
n->root = (n->count == 0);
});
g->forall_nodes([=] (Node *n) {
if(n->root) visit(n, action);
});
}
I assume the graph exports a method that is parameterized by a function object and traverses all nodes in the graph in parallel and applies the function. That function will use the PPL internally to implement that concurrency. You then have two phases: the first counts predecessors and identifies root nodes; the second starts a depth-first search from each root that decrements and ultimately visits successors. That function looks like Figure 3 .
Figure 3 Depth-First Search
// C++ using the Parallel Pattern Library
// Assumes all predecessors have been visited.
void visit(Node *n, void (*action)(Node*)) {
(*action)(n);
// assume n->successors is some kind of STL container
parallel_for_each(n->successors.begin(),
n->successors.end(),
[=](Node *s) {
if(atomic_decrement(s->count) == 0) // safely does "-- s->count"
visit(s, action);
});
}
The parallel_for_each method traverses the list of successors, applies a function object to each, and allows those operations to be done in parallel. Not shown is the assumed atomic_decrement function that uses some strategy for arbitrating concurrent accesses. Note that here you start to see more traditional concurrency concerns sneak into our otherwise parallel algorithm, and these concerns get worse as the elemental operations become more complex, like in the ray-tracing example.
The structure of this algorithm guarantees that "action" is given exclusive access to its parameter so no additional locking is needed if action updates those fields. Further, there are guarantees that all predecessors have been updated and are not changing, and that no successor has been updated and will not change until this action completes. The ability to reason about what state is stable and what state might be concurrently updated are key issues in building correct parallel algorithms.
The strength of the structured multithreading is that the parallel opportunities, including those over partially ordered computations, are convenient to express without the need to obfuscate the basic algorithm with a lot of mechanisms for mapping the work to worker threads. This provides a stronger compositional mode, as illustrated here, where a data structure can provide some basic parallel traversal methods (such as Graph::forall_nodes) that can then be reused to build more sophisticated parallel algorithms. Furthermore, it is convenient to describe all of the parallelism rather than trying to find just enough for two or four processors. Not only is this easier, it provides natural scaling opportunities for next year's machines that may have eight processors—the return of the free lunch.
Data Parallelism
Data parallelism refers to the application of some common operation over an aggregate of data either to produce a new data aggregate or to reduce the aggregate to a scalar value. The parallelism comes from doing the same logical operation to each element independent of the surrounding elements. There have been many languages with various levels of support for aggregate operations, but by far the most successful has been the one used with databases—SQL. LINQ provides direct support in both C# and Visual Basic for SQL-style operators, and the queries expressed with LINQ can be handed off to a data provider, such as ADO.NET, or can be evaluated against in-memory collections of objects or even XML documents.
Part of Parallel Extensions to .NET is an implementation of LINQ to Objects and LINQ to XML that includes parallel evaluation of the query. This implementation is called PLINQ and can be used to work conveniently with data aggregates. The following example illustrates the kernel of the standard K-means algorithm for statistical clustering: at each step you have K points in space that are your candidate cluster centers. Map every point to the nearest cluster and then, for all points mapped to the same cluster, recompute the center of that cluster by averaging the location of points in the cluster. This continues until a convergence condition is met where the positions of the cluster centers become stable. The central loop of this algorithm description is translated fairly directly into PLINQ, as shown in Figure 4 .
Figure 4 Find Center
// C# using PLINQ
var q = from p in points.AsParallel()
let center = nearestCenter(p, clusters)
// "index" of nearest cluster to p
group p by center into g
select new
{
index = g.Key,
count = g.Count(),
position = g.Aggregate(new Vector(0, 0, 0),
(accumulated, element) => accumulated + element,
(accumulated1, accumulated2) =>
accumulated1 + accumulated2,
(accumulated) => accumulated
) / g.Count()
};
var newclusters = q.ToList();
The difference between LINQ and PLINQ is the AsParallel method on the data-collection points. This example also illustrates that LINQ includes the core map-reduce pattern but with clean integration into mainstream languages. One subtle point in this example is the behavior of the Aggregate operator. The third parameter is a delegate that provides a mechanism to combine partial sums. When this method is provided, the implementation is done in a parallel style by blocking the input into chunks, reducing each chunk in parallel, and then combining the partial results.
The great strength of data parallelism is that suitable algorithms are typically expressed much more cleanly and readably than if I had applied a structured multithreading approach where data structure assumptions can become entangled. Furthermore, the more abstract description allows the system greater opportunity to optimize in ways that would completely obscure the algorithm if done by hand. Finally, this high-level representation allows greater flexibility with the execution target: multicore CPU, GPU, or scale out to cluster. And as long as the leaf functions, for example, nearestCenter has no side effects—you don't face any of the concerns of data races or deadlocks of thread-oriented programming.
A common technique for exploiting parallelism is through the use of pipelining. Using this model, a data item flows between various stages of the pipeline where it is examined and transformed before being passed on to the next stage. Data flow is the generalization of the idea where data values flow between nodes in a graph, and computation is triggered based on the availability of input data. Parallelism is exploited both by having distinct nodes executing concurrently and by having one node activated multiple times on different input data.
Parallel Extensions to .NET supports the ability to explicitly create individual tasks (of type Task, the underlying mechanism for implementing structured multitasking) and then to identify a second task that begins execution when the first completes. The concept of a future is used as a bridge between the worlds of imperative programming and data-flow programming. A future is the name of a value that will eventually be produced by a computation. This separation allows me to define what to do with a value before I know that value.
The continueWith method on a future is parameterized by a delegate that will be used to create a task that will be executed when the future value is available. The result of a call to continueWith is a new future that identifies the result of the delegate parameter. Often in imperative programming, tasks are evaluated for side effects, so continueWith is also available as a method on Task.
As an example of this style, consider the parallelism within the Strassen matrix multiplication algorithm. This is a block-oriented version of the basic matrix multiplication algorithm. The two input matrices are each divided into four sub-blocks that are then algebraically combined to form the sub-blocks of the output matrix. (For details, see the Wikipedia article on the Strassen algorithm at wikipedia.org/wiki/Strassen_algorithm .)
One of these tasks might look like this:
// C# using Parallel Extensions to the .NET Framework
var m1 = Future.StartNew(() => (A(1,1)+B(1,1))*(A(2,2)+B(2,2));
For clarity I have used mathematical notation inside the delegate rather than code to express the computation. A and B are the input matrices and A(1,1) is the upper-left subblock of the A matrix. Addition is standard for matrices, and multiplication is a recursive application of the Strassen algorithm. The output is a temporary matrix corresponding to the results of this expression.
The first seven of the subtasks are independent, but the last four depend on the first seven as inputs. The basic data-flow graph would look like Figure 5 . Here, the task labeled c11 depends on the results of tasks m2 and m3. I want that task to become eligible for execution when its inputs are available. In C# this can be expressed as:
var c11 = Task.ContinueWhenAll(delegate { ... }, m2, m3);
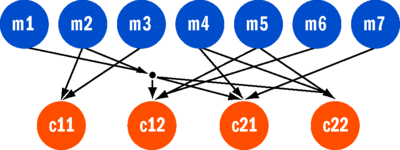
Figure 5 Subtasks
This illustrates what might be called medium-grain data flow where the units of computation are a few hundred to a few thousand operations in contrast with fine-grain data flow where each operation might be a single arithmetic operation. A few convenience methods to handle the "when all" and "when any" concepts make this more readable, but they can be implemented on top of the basic mechanisms as discussed by Stephen Toub (see blogs.msdn.com/pfxteam/archive/2008/07/23/8768673.aspx ).
As with structured multithreading, I have identified opportunities for parallelism, and if you have only a single processor, then it is fine to serially execute the subtasks in the order in which they are created. But with additional resources, you have the chance to benefit from them by having captured the execution order constraints among the subtasks. Unlike structured multithreading, it is convenient to allow one task basically to enumerate the data-flow graph and keep the individual subtasks ignorant of how their results are used and combined—a different surface to a common set of mechanisms to handling parallel algorithms.
Frequently, data is streamed into an application and I wish to process it as it flows by. In this case, the paths that the data traverse are fairly stable. And rather than associate a task with the completion of other tasks, I want to associate a task with the availability of the next data item. One domain where this is a particularly valuable model is in robotics where algorithmic decision making sits at the confluence of various streams of sensor data that may arrive at different rates.
The Microsoft Robotics SDK ( go.microsoft.com/fwlink/?LinkId=124622 ) takes this approach where the central concepts involve streams of data (called ports) and the binding of tasks that, among other ways, are activated on the arrival of data (messages). Of course, I have now circled around to a class of problems that are not motivated by the shift to multicore but rather, like Web servers, have concurrency as core characteristics that must be addressed as part of the overall architecture of the application. Similar concerns apply to distributed applications outside of the robotics domain, but these are beyond the scope of this discussion.
Streaming Parallelism
Beyond multiple cores, a second important feature of computer architecture is the multiple layers of memory hierarchy: registers, one or more levels of on-chip cache, DRAM memory, and, finally, demand paging to disk. Most programmers are blissfully unfamiliar (or at least unconcerned) with this aspect of system architecture because their programs are modest in size and fit well enough in the cache to which most references to memory are quickly returned. However, if a data value is not in the on-chip cache, it can take hundreds of cycles to fetch it from DRAM. The latency of providing this data makes the program appear to run slower since the processor spends a large fraction of the time waiting for data.
Some processor architectures support multiple logical processors per physical processing core. This is usually called (hardware) multithreading, and modest amounts of this have been used in mainstream processors (for example, Intel has called this hyper-threading in some of its products). A motivation for multithreading is to tolerate the latency of memory access; when one logical hardware thread is waiting on memory, instructions can be issued from the other hardware threads. This technique is also used on modern GPUs, but more aggressively.
As the number of processing cores grows, the number of requests it can make on a memory system increases and a different problem emerges, one of bandwidth limitations. A processor will be able to support only so many transfers per second to or from DRAM memory. When this limit is reached, there is no chance to get any gains through further use of parallelism; additional threads will just generate additional memory requests that will simply queue up behind earlier requests and wait to be serviced by memory controllers. GPUs typically have memory subsystems that support higher aggregate bandwidth (measured in gigabytes per second) because they support (and expect to have) a lot more parallelism and can benefit from the additional bandwidth.
Current multicore chip architectures are able to increase the number of cores faster than memory bandwidth, so for most problems where the data set does not fit in memory, using the memory hierarchy is an important concern. This imbalance gives rise to a style of programming called stream processing where the focus is to stage blocks of data into the on-chip cache (or perhaps private memory) and then perform as many operations against that data as possible before displacing it with the next block. Those operations may be internally parallel to use the multiple cores or they may be pipelined in a data flow style, but the key issue is to do as much work on the data in the cache while it is there.
While there have been proposals for special purpose languages to allow streaming algorithms to be specified and their execution carefully planned, it is also possible to achieve this in many cases by careful scheduling. For instance, you can apply this technique to the QuickSort example. If the size of the data set you are sorting is so large that it does not fit in the cache, the straightforward work-stealing approach will tend to schedule the largest and coarsest subproblems onto different cores, which then work on independent data sets and lose the benefit of a shared on-chip cache.
If, however, you modify the algorithm to use only parallelism on data sets that fit in the cache, you gain the benefits of streaming, as Figure 6 illustrates. In this example, you still break large problems into smaller problems (and use parallelism in the partitioning step), but if both sub-problems won't fit in the cache at the same time, then we'll do them sequentially. This means that once you get a small data set in the cache, you finish sorting it completely using all available resources while it is in the cache without it being pushed out to memory before you start the next data set.
Figure 6 Use Parallelism on Smaller Data Sets
// C++ using the Parallel Pattern Library
template<class T>
void ParQuickSort(T * data, int length, T* scratch, int cache_size) {
if(length < Threshold) InsertionSort(data,length)
else {
int mid = ParPartition(data[0], data,
length, scratch, /*inplace*/true);
if(sizeof(*data)*length < cache_size)
parallel_invoke(
[=]{ ParQuickSort(data, mid, cache_size); },
[=]{ ParQuickSort(data+mid, length-mid, cache_size);});
else {
ParQuickSort(data, mid, cache_size);
ParQuickSort(data+mid, length-mid, cache_size);
}
}
}
Note that you have had to explicitly parameterize this code with the size of the cache, which is an implementation-specific feature. This is unfortunate and is also a problem if this computation is sharing the system with other jobs or other tasks within the same job. But it illustrates one of the difficulties in getting performance out of complex parallel systems. Not every problem will have this issue, but good performance on multicore chips requires developers to think carefully about the interaction of parallelism and the memory hierarchy in some cases.
Single-Program, Multiple-Data
In the high-performance computing arena, parallelism has been used in technical and scientific applications for some time, based on a lot of work done in the 1980s. The kinds of problems are dominated by parallel loops over arrays of data where the bodies of the loops typically have a fairly simple code structure.
The earlier ray-tracing fragment is an example. The dominant parallelism model that emerged was called single-program, multiple-data, frequently abbreviated as SPMD. This term alludes to the classic Michael Flynn taxonomy of computer architecture that includes single-instruction, multiple-data (SIMD) and multiple-instruction, multiple-data (MIMD). In this model, programmers think about the behavior of each processor (worker, thread) as a set of processors that logically participate in a single problem but share the work. Typically the work is separate iterations of a loop that work with different parts of arrays.
The notion of work sharing in an SPMD style is at the heart of the OpenMP ( openmp.org ) set of extensions to C, C++, and Fortran. The core concept here is a parallel region where a single thread of activity forks into a team of threads that then cooperatively execute shared loops. A barrier synchronization mechanism is used to coordinate this team so that the entire team moves as a group from one loop nest to the next to insure that data values are not read before they have been computed by teammates. At the end of the region, the team comes back together, and the single original thread continues on until the next parallel region.
This style of parallel programming can also be used in non-shared memory systems where inter-node communication built on top of message passing is used to copy data around to where it is needed at phase boundaries. This technique is used to apply thousands of processor nodes to achieve the extreme performance that is needed for problems such as climate modeling and pharmaceutical design.
As in structured multithreading, an OpenMP parallel region may be inside a function, and so the caller of that function need not be aware of the use of parallelism in the implementation. However, the SPMD model requires careful attention to how the work of the problem is mapped down onto the workers in a team.
A load imbalance where one worker has a longer task than its teammates implies those teammates may end up waiting, twiddling their silicon thumbs for the one worker to complete. Similarly, in an environment where system resources may be shared with other jobs, if a worker is interrupted by the OS to perform some other task, the rest of the workers will be impacted by this artificial imbalance.
Future hardware systems may have different kinds of processor cores—some big cores that use a lot of power but are fast for a single thread mixed with little cores that use less power and are optimized for parallel operations. Such an environment is very difficult for an SPMD model because it makes the strategy for mapping work to workers very complex. These are problems that are nicely avoided by the structured multithreading approach but at the cost of small increases in scheduling overhead and possibly loss of control over the memory hierarchy for code where OpenMP is well suited.
Concurrent Data Structures
The previous discussion has focused almost entirely on control parallelism—how to identify and describe separate tasks that can be mapped down to the multiple cores that may be available. There is also a data side related to parallelism. If the effect of a task is to update a data structure, say insert a value into a Hashtable, that operation may be logically independent of concurrently executing tasks.
Standard implementations of data structures do not support concurrent access and may break in a variety of ways that are cryptic, unpredictable, and difficult to reproduce. Simply putting a single lock around the whole data structure may create a bottleneck in the program where all of the tasks serialize, resulting in a loss of parallelism because too few data locations are concurrently in use.
It is thus important to create, in addition to the parallel control abstractions, new concurrent versions of common data structures—Hashtables, stacks, queues, various kinds of set representations. These versions have defined semantics for the supported methods that may be invoked concurrently, and they are engineered to avoid bottlenecks when accessed by multiple tasks.
As an example, consider a standard approach to finding the connected components of a graph in parallel. The basic strategy is to start a number of depth-first traversals of the graph, identify nodes where they collide, and form a reduced graph. The top-level function would have the basic structure illustrated in Figure 7 .
Figure 7 Depth-First Traversals
// C++
// assign to each Node::component a representative node in
// the connected component containing that node
void components(Graph * g) {
g->forall_nodes([=] (Node * n) {
n->component = UNASSIGNED;
});
Roots roots;
EdgeTable edges;
g->forall_nodes([&roots, &edges] (Node * n) {
if(atomic_claim(n, n)) {
roots.add(n);
component_search(n,n, &edges);
}
});
// recusively combine reduced graph (roots, edges)
...
}
We will represent the components implicitly by having each node point to a representative element. The input is a graph, and I assume that graph supports a forall_nodes method that can be used to traverse the graph using structured multithreading techniques. It is parameterized by a function object to be applied to each node. This interface insulates the parallel algorithm from the structural details of the graph but retains the key property of structured multithreading, that the concurrency is internal to method and can be highly structured.
First, initialize the component fields to a distinguished value, and then start parallel depth-first searches, logically from every node. Each search begins by claiming the start node. Since the node might be reached by some other search, this claim is basically an atomic test to determine which search reaches the node first. That function might look like this:
// C++
// atomically set n->commponent to component if it is UNASSIGNED
// return true if and only this transition was made.
bool atomic_claim(Node * n, Node * component) {
n->lock();
Node * c = n->component;
if(c == UNASSINGED) n->component = n;
n->unlock();
return c == UNASSIGNED;
}
I have assumed a lock per node, but in this simple example I might have used the Windows primitive to perform an interlocked compare and exchange on pointer values. The key issue is that a single global lock to protect the concurrent access from multiple tasks would foil our attempt at parallelism by eliminating the data parallelism even if I have lots of control parallelism.
You don't specifically need one lock per node. Instead, you could map the nodes down to a smaller set of locks, but you must be wary of introducing a scaling bottleneck by using a specific number related to today's processor counts. Rather than using explicit locks at all, research into the use of "transactional memory" by Jim Larus aims to allow developers to simply declare code intervals that should be isolated from concurrently executed code where the implementation introduces locking as needed in order to guarantee these semantics.
Once you have identified a new root component, add it to the shared data structure roots. This is logically a set of all the root components found in this first step of the algorithm. Again, while there is logically only one instance of this container, you need its implementation to be optimized for concurrent additions. As part of the PPL and Parallel Extensions to .NET, Microsoft will provide suitable implementations of vectors, queues, and Hashtables that can be used as building blocks.
The depth-first search from a node iterates over adjacent nodes and attempts to claim each into its component. If this is successful, it recurses into that node (see Figure 8 ).
Figure 8 Recursive Search
// C++ using the Parallel Pattern Library
// a depth first search from "n" through currently
// unassigned nodes which are
// set to refer to "component". Record inter-component edges in "edges"
void component_search(Node * n, Node * component, EdgeTable * edges) {
parallel_for_each(n->adjacents.begin(),
n->adjacents.end(),
[=] (Node * adj) {
if(atomic_claim(adj, component)
component_search(adj, component, edges);
else if(adj->component != component) {
edges->insert(adj->component, component);
}
});
}
If the claim fails, meaning that this or some other task reached this node first, you should look to see if it was added to a different component. If so, record the two components in the shared data structure, EdgeTable. This table might be created using a concurrent Hashtable to avoid duplicate information. Again, this is a logically shared structure where you must insure you have adequate support for concurrent access in order to avoid contention and loss of effective parallelism.
The two structures, roots, and edges form a logical graph that records connectivity between the initial component estimates. To complete the algorithm, find connected components on this logical graph and then update that node level information with final representatives (not shown).
Wrap-Up
A loss of data concurrency is, of course, just one of many performance surprises associated with parallel programming. You should not be surprised if your first attempts at this new problem either break mysteriously (because you forgot to use locks, for example) or actually slow down compared to sequential execution (tasks too small, too much locking, loss of cache effectiveness, not enough memory bandwidth, data contention, and so on).
As Microsoft continues to invest in parallel programming, abstractions will steadily improve as well as tools to help diagnose and avoid the associated problems. Indeed, expect the hardware itself to improve and to incorporate features to reduce various costs, but that will take time.
The shift to parallelism is an inflection point for the software industry where new techniques must be adopted. Developers must embrace parallelism for those portions of their applications that are time sensitive today or that are expected to run on larger data sets tomorrow. I have described different ways to think about and use parallelism in applications, and I have illustrated them with new tools being developed at Microsoft as part of our broad Parallel Computing Initiative.
Insights: Toward the Next 100X
Since 1975, microprocessor performance has improved 100X/decade, powered by exponential growth in clock frequencies (3,000X) and transistor counts (300,000X). Instruction "potency" has grown 8X-100X—compare an 8-bit ADD to an SSE4.1 DPPS "dot-product of packed-4-SP-float-vectors"—and on-die caches are now as large as early hard disks. As an industry, we have spent each 100X to deliver wave after wave of compelling new experiences. It's the wind in our sails.
However, we will have to sail a different tack deliver the next 100X. We can still look forward to the Moore's Law Dividend of four more doublings in transistors per die (the 32, 22, 16, 11 nm nodes), at a two-year cadence. But we now find ourselves in the asymptotic diminishing returns corners of several growth curves, notably voltage scaling and power dissipation (power wall), instruction-level parallelism (complexity wall), and memory latency (memory wall).
The Power Wall The dynamic power of a microprocessor is proportional to NCV2f, the number of transistors switching × switching capacitance × voltage squared × frequency. With each lithography node shrink, transistors/die potentially doubles (↑N) and transistors get smaller (↓C) and use lower voltage switching (↓V). Supply voltage has fallen from 15V down to 1V today, reducing switching energy by more than 100X. Unfortunately, the CMOS minimum threshold voltage is 0.7 V, so we have, at most, an additional (1.0/0.7)2=2X savings to come. Despite these savings, as we have increased the complexity (↑N) and frequency (↑f) of microprocessors, die power dissipation has grown from 1 W to 100 W in a few square centimeters of silicon, now at the limit of practical cooling solutions. There is little headroom left; power is a zero-sum game going forward. Clock frequencies will never again scale up as fast as they used to. We won't find our next 100X here.
The Complexity Wall High-performance microprocessors use heroic out-of-order execution to exploit instruction-level parallelism within a thread. But there are practical limits to further big gains from this approach. The serial code itself and its data dependences limit the parallelism that can be mined. In the hardware you may need up to N2 more circuitry sometimes to complete N operations in parallel. The up-front design and verification costs grow proportionally. Most important, assuming parallel software arrives, the power wall dictates that more energy-efficient microarchitectures are better architectures—results/joule trumps results/nanosecond.
The Memory Wall DRAM access latency (delay) improves relatively slowly; therefore CPUs use caches to avoid DRAM entirely. But caches are an expensive proposition—today a full-cache miss can cost 300 clock cycles. A rule of thumb is you halve the miss rate by quadrupling the cache size. And much of the complexity in a CPU core is dedicated to tolerating long and unpredictable memory accesses. However, it is easier to scale memory bandwidth. Then you can apply memory-level parallelism—parallel software threads issuing many concurrent memory accesses simultaneously. Each thread may still wait a long time for its access, but the overall throughput of the parallel computation is very high.
Serial processor performance will continue to improve but much more slowly in the next decade. Clever CPU designers and compiler writers will still find ways to squeeze out 5% or 10% here and there. This is a good thing because a lot of valuable software is serial and governed by Amdahl's Law. But this will not deliver the next 100X we need. That will require software that exploits parallelism. If and when sufficiently compelling software appears, processor vendors stand ready to deliver parallel processors with dozens of cores and high bandwidth memory solutions. If we come, they will build it.
—Jan Gray, Software Architect, Microsoft Parallel Computing Platform Team
David Callahan is the Distinguished Engineer and lead architect of the Parallel Computing Platform Team within Visual Studio. He came to Microsoft from supercomputer manufacturer Cray Inc. with a background in parallelizing compilers and parallel algorithms, architectures, and languages.